Introducción
La tecnología de aprendizaje automático ha evolucionado a un ritmo increíble durante el año pasado. Cada vez más empresas comparten sus mejores prácticas, lo que abre nuevas posibilidades para la creación de asistentes digitales inteligentes.
Como parte de este artículo, quiero compartir mi experiencia en la implementación de un asistente de voz y ofrecerles algunas ideas para que sea aún más inteligente y útil.

?
| offline- | ||
| pip install PyAudio ( )
pip install pyttsx3 ( ) :
|
||
| pip install pyowm (OpenWeatherMap) | ||
| Google ( ) | pip install google | |
| YouTube | - | |
| Wikipedia c | pip install wikipedia-api | |
| Traducir frases del idioma de destino al idioma nativo del usuario y viceversa | No soportado | pip install googletrans (Traductor de Google) |
| Busca una persona por nombre y apellido en las redes sociales | No soportado | - |
| "Lanza una moneda" | Soportado | - |
| Saludar y decir adiós (después del adiós finaliza la aplicación) | Soportado | - |
| Cambie la configuración del idioma de síntesis y reconocimiento de voz sobre la marcha | Soportado | - |
| TODO mucho más ... | ||
Paso 1. Procesamiento de la entrada de voz
Comencemos por aprender a manejar la entrada de voz. Necesitamos un micrófono y un par de bibliotecas instaladas: PyAudio y SpeechRecognition.
Preparemos las herramientas básicas para el reconocimiento de voz:
import speech_recognition
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
voice_input = record_and_recognize_audio()
print(voice_input)
Ahora creemos una función para grabar y reconocer el habla. Para el reconocimiento en línea, necesitamos Google, ya que tiene una alta calidad de reconocimiento en una gran cantidad de idiomas.
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
except speech_recognition.RequestError:
print("Check your Internet Connection, please")
return recognized_data
¿Qué pasa si no hay acceso a Internet? Puede utilizar soluciones para el reconocimiento sin conexión. Personalmente, me gustó mucho el proyecto Vosk .
De hecho, no necesita implementar una opción fuera de línea si no la necesita. Solo quería mostrar ambos métodos en el marco del artículo, y ya elige en función de los requisitos de su sistema (por ejemplo, Google es sin duda el líder en la cantidad de idiomas de reconocimiento disponibles).Ahora, habiendo implementado una solución fuera de línea y agregando los modelos de idioma necesarios al proyecto, si no hay acceso a la red, automáticamente cambiaremos al reconocimiento fuera de línea.
Tenga en cuenta que para no tener que repetir la misma frase dos veces, decidí grabar el audio del micrófono en un archivo WAV temporal que se eliminará después de cada reconocimiento.
Por lo tanto, el código resultante se ve así:
Código completo para que funcione el reconocimiento de voz
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import wave # wav
import json # json- json-
import os #
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
Es posible que se pregunte "¿Por qué admitir las funciones sin conexión?"
En mi opinión, siempre vale la pena considerar que el usuario puede quedar desconectado de la red. En este caso, el asistente de voz aún puede ser útil si lo usa como un bot conversacional o para resolver una serie de tareas simples, por ejemplo, contar algo, recomendar una película, ayudar a elegir una cocina, jugar un juego, etc.
Paso 2. Configurar el asistente de voz
Dado que nuestro asistente de voz puede tener un género, un idioma de habla y, según los clásicos, un nombre, seleccionemos una clase separada para estos datos, con la que trabajaremos en el futuro.
Para pedirle una voz a nuestro asistente, usaremos la biblioteca de síntesis de voz sin conexión pyttsx3. Automáticamente encontrará las voces disponibles para síntesis en nuestro equipo, dependiendo de la configuración del sistema operativo (por lo tanto, es posible que tenga otras voces disponibles y necesitará diferentes índices).
También agregaremos a la función principal la inicialización de la síntesis de voz y una función separada para reproducirla. Para asegurarnos de que todo funciona, hagamos una pequeña comprobación de que el usuario nos ha saludado y le devolvemos el saludo del asistente:
Código completo para el marco del asistente de voz (síntesis y reconocimiento de voz)
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import pyttsx3 # (Text-To-Speech)
import wave # wav
import json # json- json-
import os #
class VoiceAssistant:
"""
, , ,
"""
name = ""
sex = ""
speech_language = ""
recognition_language = ""
def setup_assistant_voice():
"""
(
)
"""
voices = ttsEngine.getProperty("voices")
if assistant.speech_language == "en":
assistant.recognition_language = "en-US"
if assistant.sex == "female":
# Microsoft Zira Desktop - English (United States)
ttsEngine.setProperty("voice", voices[1].id)
else:
# Microsoft David Desktop - English (United States)
ttsEngine.setProperty("voice", voices[2].id)
else:
assistant.recognition_language = "ru-RU"
# Microsoft Irina Desktop - Russian
ttsEngine.setProperty("voice", voices[0].id)
def play_voice_assistant_speech(text_to_speech):
"""
( )
:param text_to_speech: ,
"""
ttsEngine.say(str(text_to_speech))
ttsEngine.runAndWait()
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
# ( )
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
#
ttsEngine = pyttsx3.init()
#
assistant = VoiceAssistant()
assistant.name = "Alice"
assistant.sex = "female"
assistant.speech_language = "ru"
#
setup_assistant_voice()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
if command == "":
play_voice_assistant_speech("")
De hecho, aquí me gustaría aprender a escribir un sintetizador de voz por mi cuenta, pero mis conocimientos aquí no serán suficientes. Si puede sugerir buena literatura, un curso o una solución documentada interesante que lo ayudará a comprender este tema en profundidad, escriba en los comentarios.
Paso 3. Procesamiento de comandos
Ahora que hemos "aprendido" a reconocer y sintetizar el habla con la ayuda de los desarrollos simplemente divinos de nuestros colegas, podemos comenzar a reinventar nuestra rueda para procesar los comandos de voz del usuario: D
En mi caso, uso opciones multilingües para almacenar comandos, ya que no tengo tantos eventos, y estoy satisfecho con la precisión de la definición de uno u otro comando. Sin embargo, para proyectos grandes, recomiendo separar las configuraciones por idioma.
Puedo ofrecer dos formas de almacenar comandos.
1 vía
Puede usar un hermoso objeto similar a JSON en el que almacenar intenciones, escenarios de desarrollo, respuestas en caso de intentos fallidos (estos a menudo se usan para bots de chat). Se parece a esto:
config = {
"intents": {
"greeting": {
"examples": ["", "", " ",
"hello", "good morning"],
"responses": play_greetings
},
"farewell": {
"examples": ["", " ", "", " ",
"goodbye", "bye", "see you soon"],
"responses": play_farewell_and_quit
},
"google_search": {
"examples": [" ",
"search on google", "google", "find on google"],
"responses": search_for_term_on_google
},
},
"failure_phrases": play_failure_phrase
}
Esta opción es adecuada para quienes desean capacitar a un asistente para responder a frases difíciles. Además, aquí puede aplicar el enfoque NLU y crear la capacidad de predecir la intención del usuario, comparándola con las que ya están en la configuración.
Consideraremos este método en detalle en el paso 5 de este artículo. Mientras tanto, llamaré su atención sobre una opción más simple.
2 vías
Puede tomar un diccionario simplificado, que tendrá la tupla de tipo hash como claves (ya que los diccionarios usan hash para almacenar y recuperar elementos rápidamente), y los nombres de las funciones que se ejecutarán estarán en forma de valores. Para comandos cortos, la siguiente opción es adecuada:
commands = {
("hello", "hi", "morning", ""): play_greetings,
("bye", "goodbye", "quit", "exit", "stop", ""): play_farewell_and_quit,
("search", "google", "find", ""): search_for_term_on_google,
("video", "youtube", "watch", ""): search_for_video_on_youtube,
("wikipedia", "definition", "about", "", ""): search_for_definition_on_wikipedia,
("translate", "interpretation", "translation", "", "", ""): get_translation,
("language", ""): change_language,
("weather", "forecast", "", ""): get_weather_forecast,
}
Para procesarlo, debemos agregar el código de la siguiente manera:
def execute_command_with_name(command_name: str, *args: list):
"""
:param command_name:
:param args: ,
:return:
"""
for key in commands.keys():
if command_name in key:
commands[key](*args)
else:
pass # print("Command not found")
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
command_options = [str(input_part) for input_part in voice_input[1:len(voice_input)]]
execute_command_with_name(command, command_options)
Se pasarán argumentos adicionales a la función después de la palabra de comando. Es decir, si dices la frase "los videos son gatos lindos ", el comando " video " llamará a la función search_for_video_on_youtube () con el argumento " gatos lindos " y dará el siguiente resultado:
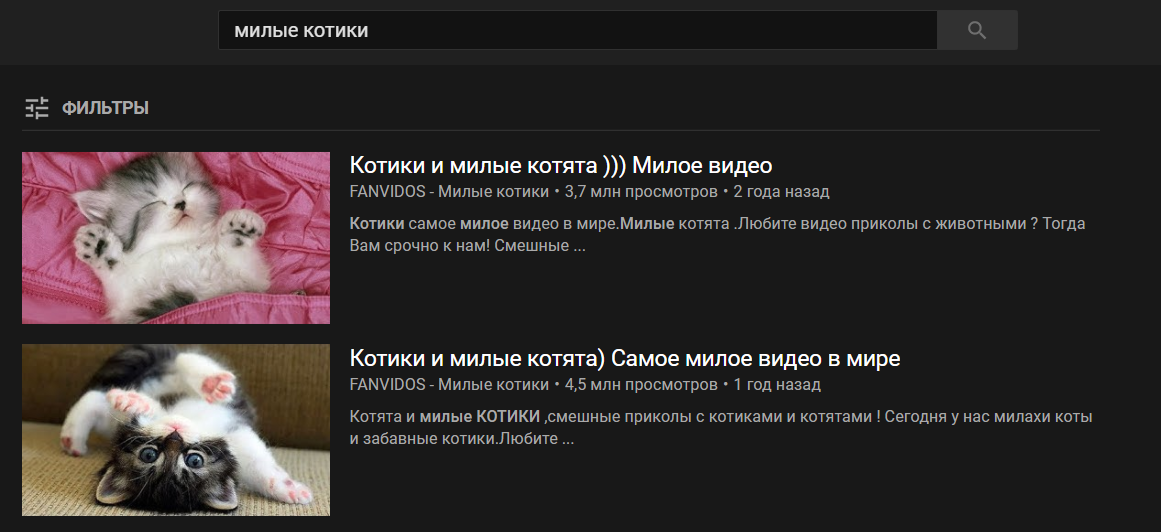
Un ejemplo de una función de este tipo con procesamiento de argumentos entrantes:
def search_for_video_on_youtube(*args: tuple):
"""
YouTube
:param args:
"""
if not args[0]: return
search_term = " ".join(args[0])
url = "https://www.youtube.com/results?search_query=" + search_term
webbrowser.get().open(url)
#
# , JSON-
play_voice_assistant_speech("Here is what I found for " + search_term + "on youtube")
¡Eso es! La funcionalidad principal del bot está lista. Entonces puedes mejorarlo infinitamente de varias maneras. Mi implementación con comentarios detallados está disponible en mi GitHub .
A continuación, veremos una serie de mejoras para que nuestro asistente sea aún más inteligente.
Paso 4. Incorporación del multilingüismo
Para enseñar a nuestro asistente a trabajar con múltiples modelos de idiomas, será más conveniente organizar un pequeño archivo JSON con una estructura simple:
{
"Can you check if your microphone is on, please?": {
"ru": ", , ",
"en": "Can you check if your microphone is on, please?"
},
"What did you say again?": {
"ru": ", ",
"en": "What did you say again?"
},
}
En mi caso, utilizo el cambio entre ruso e inglés, ya que tengo disponibles modelos de reconocimiento de voz y voz para síntesis de voz. El idioma se seleccionará en función del idioma del habla del propio asistente de voz.
Para recibir la traducción, podemos crear una clase separada con un método que nos devolverá una cadena con la traducción:
class Translation:
"""
"""
with open("translations.json", "r", encoding="UTF-8") as file:
translations = json.load(file)
def get(self, text: str):
"""
( )
:param text: ,
:return:
"""
if text in self.translations:
return self.translations[text][assistant.speech_language]
else:
#
#
print(colored("Not translated phrase: {}".format(text), "red"))
return text
En la función principal antes del bucle, declaramos nuestro traductor de la siguiente manera: traductor = Traducción ()
Ahora, al reproducir el discurso del asistente, podemos obtener la traducción de la siguiente manera:
play_voice_assistant_speech(translator.get(
"Here is what I found for {} on Wikipedia").format(search_term))
Como puede ver en el ejemplo anterior, esto funciona incluso para aquellas líneas que requieren la inserción de argumentos adicionales. Por lo tanto, puede traducir los conjuntos de frases "estándar" para sus asistentes.
Paso 5. Un poco de aprendizaje automático
Ahora volvamos al objeto JSON para almacenar comandos de varias palabras, que es típico de la mayoría de los chatbots, que mencioné en el párrafo 3. Es adecuado para aquellos que no quieren usar comandos estrictos y planean expandir su comprensión de la intención del usuario usando NLU -métodos.
A grandes rasgos, en este caso se considerarán equivalentes las frases " buenas tardes ", " buenas noches " y " buenos días ". El asistente entenderá que en los tres casos, la intención del usuario era saludar a su asistente de voz.
Con este método, también puede crear un bot conversacional para chats o un modo conversacional para su asistente de voz (para casos en los que necesite un interlocutor).
Para implementar tal posibilidad, necesitaremos agregar un par de funciones:
def prepare_corpus():
"""
"""
corpus = []
target_vector = []
for intent_name, intent_data in config["intents"].items():
for example in intent_data["examples"]:
corpus.append(example)
target_vector.append(intent_name)
training_vector = vectorizer.fit_transform(corpus)
classifier_probability.fit(training_vector, target_vector)
classifier.fit(training_vector, target_vector)
def get_intent(request):
"""
:param request:
:return:
"""
best_intent = classifier.predict(vectorizer.transform([request]))[0]
index_of_best_intent = list(classifier_probability.classes_).index(best_intent)
probabilities = classifier_probability.predict_proba(vectorizer.transform([request]))[0]
best_intent_probability = probabilities[index_of_best_intent]
#
if best_intent_probability > 0.57:
return best_intent
Y también modificar levemente la función principal agregando inicialización de variables para preparar el modelo y cambiando el bucle a la versión correspondiente a la nueva configuración:
#
# ( )
vectorizer = TfidfVectorizer(analyzer="char", ngram_range=(2, 3))
classifier_probability = LogisticRegression()
classifier = LinearSVC()
prepare_corpus()
while True:
#
#
voice_input = record_and_recognize_audio()
if os.path.exists("microphone-results.wav"):
os.remove("microphone-results.wav")
print(colored(voice_input, "blue"))
# ()
if voice_input:
voice_input_parts = voice_input.split(" ")
# -
#
if len(voice_input_parts) == 1:
intent = get_intent(voice_input)
if intent:
config["intents"][intent]["responses"]()
else:
config["failure_phrases"]()
# -
# ,
#
if len(voice_input_parts) > 1:
for guess in range(len(voice_input_parts)):
intent = get_intent((" ".join(voice_input_parts[0:guess])).strip())
if intent:
command_options = [voice_input_parts[guess:len(voice_input_parts)]]
config["intents"][intent]["responses"](*command_options)
break
if not intent and guess == len(voice_input_parts)-1:
config["failure_phrases"]()
Sin embargo, este método es más difícil de controlar: requiere una verificación constante de que el sistema todavía identifica correctamente esta o aquella frase como parte de tal o cual intención. Por lo tanto, este método debe usarse con cuidado (o experimentar con el modelo en sí).
Conclusión
Con esto concluye mi pequeño tutorial.
Estaré encantado si comparte conmigo en los comentarios las soluciones de código abierto que sabe que se pueden implementar en este proyecto, así como sus ideas sobre qué otras funciones en línea y fuera de línea se pueden implementar.
Las fuentes documentadas de mi asistente de voz en dos versiones se pueden encontrar aquí .
PD: la solución funciona en Windows, Linux y MacOS con pequeñas diferencias al instalar las bibliotecas PyAudio y Google.