¿Cuál fue el propósito de este estudio? Quería saber:
- En que aplicaciones se usa Python
- Qué conocimientos se requieren: bases de datos, bibliotecas, marcos
- Cuánta demanda de especialistas en cada área
- Que sueldos se ofrecen

Cargando datos
Puestos de trabajo descargado desde el sitio hh.ru , mediante la API: dev.hh.ru . A pedido de "Python", se subieron 1994 vacantes (región de Moscú), que se dividieron en suites de capacitación y pruebas, en la proporción de 80% y 20% . El tamaño del conjunto de entrenamiento es 1595 , el tamaño del conjunto de prueba es 399 . El conjunto de prueba solo se utilizará en las secciones de habilidades Top / Antitop y Clasificación de puestos.
Señales
Según el texto de las vacantes subidas, se formaron dos grupos de los n-gramas de palabras más comunes :
- 2 gramos en cirílico y latino
- 1 gramo en latín
En las vacantes de TI, las habilidades y tecnologías clave generalmente se escriben en inglés, por lo que el segundo grupo incluyó palabras solo en latín.
Después de seleccionar n-gramos, el primer grupo contenía 81 2 gramos y el segundo 98 1 gramos:
| No. | norte | n-gramo | Peso | Vacantes |
| 1 | 2 | en python | ocho | 258 |
| 2 | 2 | ci cd | ocho | 230 |
| 3 | 2 | comprensión de los principios | ocho | 221 |
| 4 | 2 | conocimiento de sql | ocho | 178 |
| cinco | 2 | desarrollo y | nueve | 174 |
| ... | ... | ... | ... | ... |
| 82 | 1 | sql | cinco | 490 |
| 83 | 1 | linux | 6 | 462 |
| 84 | 1 | postgresql | cinco | 362 |
| 85 | 1 | estibador | 7 | 358 |
| 86 | 1 | Java | nueve | 297 |
| ... | ... | ... | ... | ... |
Se decidió dividir las vacantes en grupos de acuerdo con los siguientes criterios en orden de prioridad:
| Una prioridad | Criterio | Peso |
| 1 | Campo (dirección aplicada), puesto, experiencia
n-grama: "aprendizaje automático", "administración de Linux", "conocimiento excelente" |
7-9 |
| 2 | Herramientas, tecnologías, software.
n-gramos: "sql", "linux os", "pytest" |
4-6 |
| 3 | Otras habilidades de
n-gramas: "educación técnica", "inglés", "tareas interesantes" |
1-3 |
La determinación de a qué grupo de criterios pertenece el n-grama, y qué peso asignarle, ocurrió en un nivel intuitivo. Aquí hay un par de ejemplos:
- A primera vista, "Docker" se puede atribuir al segundo grupo de criterios con una ponderación de 4 a 6. Pero la mención de "Docker" en la vacante probablemente significa que la vacante será para el puesto de "ingeniero DevOps". Por lo tanto, "Docker" cayó en el primer grupo y recibió un peso de 7.
- «Java» , .. «Java» Java- « Python». «-». , , , «Java» 9.
n- — .
Para los cálculos, cada vacante se transformó en un vector con una dimensión de 179 (el número de características seleccionadas) de números enteros de 0 a 9, donde 0 significa que el i-ésimo n-gramo está ausente en la vacante, y los números del 1 al 9 significan la presencia del i-ésimo n - gramos y su peso. Más adelante en el texto, un punto se entiende como una vacante representada por dicho vector.
Ejemplo:
digamos que una lista de n-gramos contiene solo tres valores:
No. norte n-gramo Peso Vacantes 1 2 en python ocho 258 2 2 comprensión de los principios ocho 221 3 1 sql cinco 490
Luego, para una vacante con texto.
Requisitos:
- Más de 3 años de experiencia en el desarrollo de Python .
- Buen conocimiento de sql
el vector es igual a [8, 0, 5].
Métrica
Para trabajar con datos, es necesario que los comprenda. En nuestro caso, me gustaría ver si hay grupos de puntos, que consideraremos como grupos. Para hacer esto, utilicé el algoritmo t-SNE para traducir todos los vectores al espacio 2D.
La esencia del método es reducir la dimensión de los datos, manteniendo al máximo las proporciones de las distancias entre los puntos del conjunto. Es bastante difícil entender cómo funciona t-SNE a partir de las fórmulas. Pero me gustó un ejemplo que se encuentra en algún lugar de Internet: digamos que tenemos bolas en un espacio tridimensional. Conectamos cada bola con todas las demás bolas mediante resortes invisibles que no se cruzan de ninguna manera y no interfieren entre sí al cruzar. Los resortes actúan en dos direcciones, es decir resisten tanto la distancia como el acercamiento de las bolas entre sí. El sistema está en un estado estable, las bolas están estacionarias. Si tomamos una de las bolas y la tiramos hacia atrás, y luego la soltamos, volverá a su estado original debido a la fuerza de los resortes. A continuación, tomamos dos platos grandes y exprimimos las bolas en una capa delgada,sin interferir con las bolas para moverse en el plano entre las dos placas. Las fuerzas de los resortes comienzan a actuar, las bolas se mueven y finalmente se detienen cuando las fuerzas de todos los resortes se equilibran. Los resortes actuarán de manera que las bolas que estaban cerca una de la otra permanecerán relativamente juntas y planas. También con las bolas eliminadas, se eliminarán entre sí. Con la ayuda de resortes y placas, convertimos el espacio tridimensional en bidimensional, ¡conservando la distancia entre los puntos de alguna forma!También con las bolas eliminadas, se eliminarán entre sí. Con la ayuda de resortes y placas, convertimos el espacio tridimensional en bidimensional, ¡conservando la distancia entre los puntos de alguna forma!También con las bolas eliminadas, se eliminarán entre sí. Con la ayuda de resortes y placas, convertimos el espacio tridimensional en bidimensional, ¡preservando la distancia entre los puntos de alguna forma!
Utilicé el algoritmo t-SNE solo para visualizar un conjunto de puntos. Ayudó a elegir una métrica, así como a seleccionar los pesos para las características.
Si usamos la métrica euclidiana que usamos en nuestra vida diaria, entonces la ubicación de las vacantes se verá así:

La figura muestra que la mayoría de los puntos se concentran en el centro y hay pequeñas ramas a los lados. Con este enfoque, los algoritmos de agrupación en clúster que utilizan las distancias entre puntos no producirán nada bueno.
Hay muchas métricas (formas de determinar la distancia entre dos puntos) que funcionarán bien con los datos que está explorando. Elegí la distancia Jaccard como medida , teniendo en cuenta los pesos de n-gramos. La medida de Jaccard es fácil de entender, pero funciona bien para resolver el problema en consideración.
:
1 n-: « python», «sql», «docker»
2 n-: « python», «sql», «php»
:
« python» — 8
«sql» — 5
«docker» — 7
«php» — 9
(n- 1- 2- ): « python», «sql» = 8 + 5 = 13
( n- 1- 2- ): « python», «sql», «docker», «php» = 8 + 5 + 7 + 9 = 29
=1 — ( / ) = 1 — (13 / 29) = 0.55
Se calculó la matriz de distancias entre todos los pares de puntos, el tamaño de la matriz es 1595 x 1595. En total, 1,271,215 distancias entre pares únicos. La distancia media resultó ser 0,96, entre 619 659 la distancia es 1 (es decir, no hay ninguna similitud). El siguiente gráfico muestra que, en general, hay poca similitud entre los trabajos:
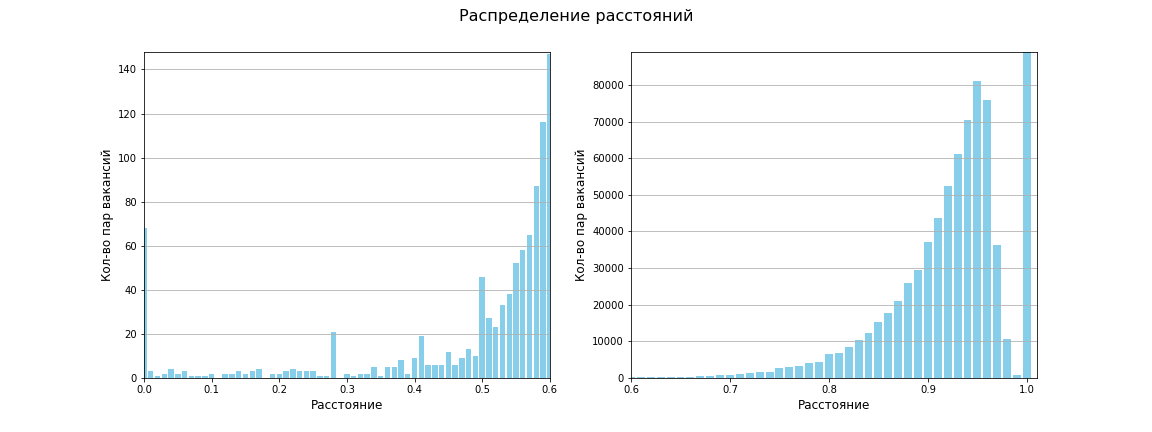
Usando la métrica de Jaccard, nuestro espacio ahora se ve así:

Aparecieron cuatro áreas de densidad distintas y dos pequeños grupos con baja densidad. ¡Al menos así ven mis ojos!
Clustering
Se eligió el modelo de mezcla gaussiana (GMM) como algoritmo de agrupación . El algoritmo recibe datos en forma de vectores como entrada, y el parámetro n_components es el número de grupos en los que se debe dividir el conjunto. Puedes ver cómo funciona el algoritmo aquí (en inglés). Usé una implementación de GMM lista para usar de la biblioteca scikit-learn: sklearn.mixture.GaussianMixture .
Tenga en cuenta que GMM no usa una métrica, sino que separa los datos solo por un conjunto de características y sus pesos. En el artículo, la distancia de Jaccard se utiliza para visualizar datos, calcular la compacidad de los grupos (tomé la distancia promedio entre los puntos del grupo para determinar la compacidad) y determinarel punto central del grupo (vacante típica) - el punto con la distancia promedio más pequeña a otros puntos del grupo. Muchos algoritmos de agrupación utilizan exactamente la distancia entre puntos. La sección Otros métodos discutirá otros tipos de agrupamiento que se basan en métricas y también dan buenos resultados.
En la sección anterior, se determinó visualmente que lo más probable es que haya seis grupos. Así es como se ven los resultados del agrupamiento con n_components = 6:

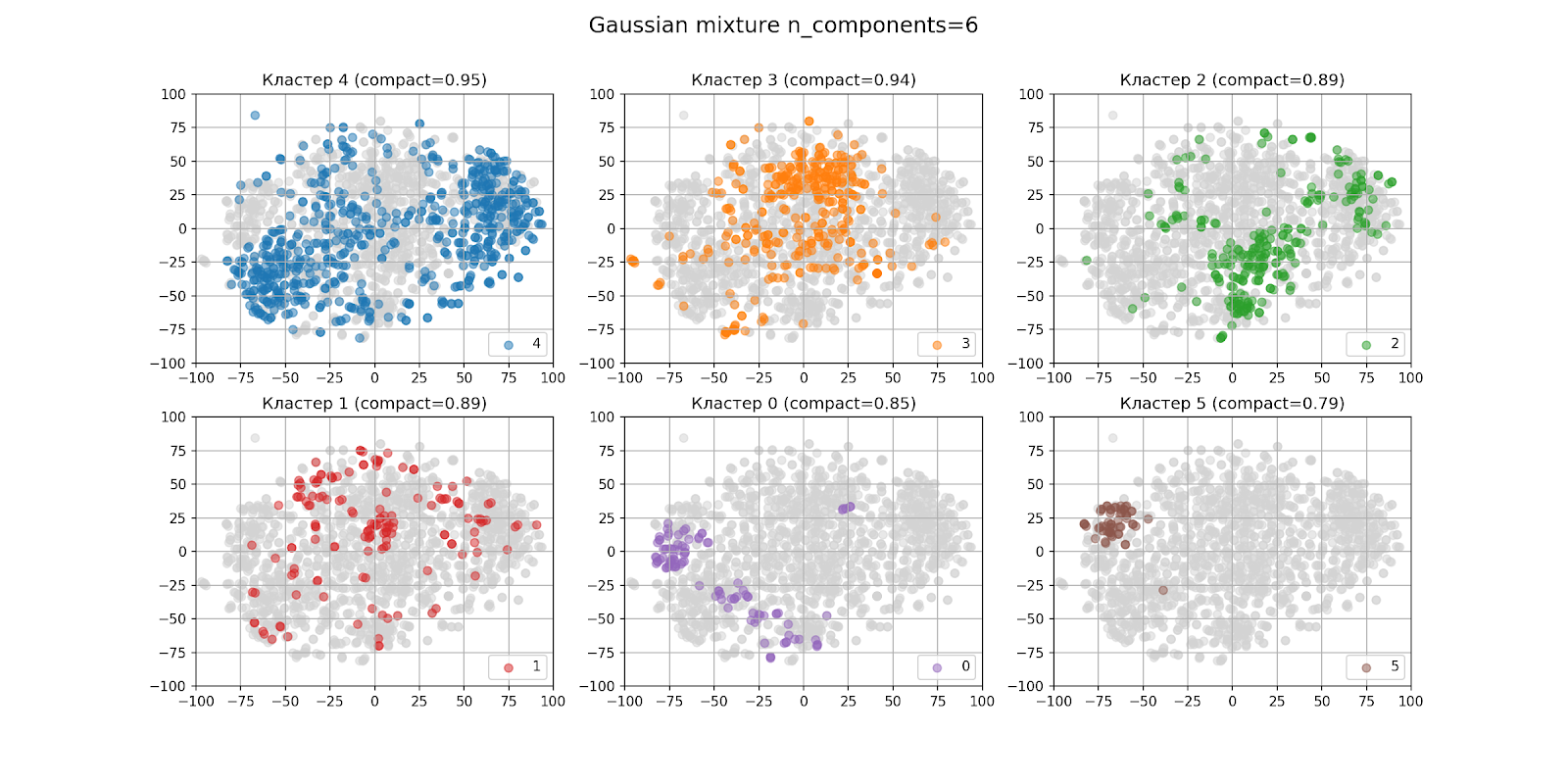
En la figura con la salida de los conglomerados por separado, los conglomerados están ordenados en orden descendente del número de puntos de izquierda a derecha, de arriba a abajo: el conglomerado 4 es el más grande, el 5 es el más pequeño. La compacidad de cada grupo se indica entre paréntesis.
En apariencia, la agrupación resultó no ser muy buena, incluso si consideramos que el algoritmo t-SNE no es perfecto. Al analizar los conglomerados, el resultado tampoco fue alentador.
Para encontrar el número óptimo de clústeres n_componentes, usaremos los criterios AIC y BIC, sobre los que puede leer aquí . El cálculo de estos criterios está integrado en el método sklearn.mixture.GaussianMixture . Así es como se ve el gráfico de criterios:

Cuando n_components = 12, el criterio BIC tiene el valor más bajo (mejor), el criterio AIC también tiene un valor cercano al mínimo (mínimo cuando n_components = 23). Dividamos las vacantes en 12 grupos:


Los clústeres son ahora más compactos, tanto en apariencia como en términos numéricos. Durante el análisis manual, las vacantes se dividieron en grupos característicos para comprender a una persona. La figura muestra los nombres de los grupos. Los clústeres numerados 11 y 4 están etiquetados como <Papelera 2>:
- En el grupo 11, todas las características tienen aproximadamente los mismos pesos totales.
- El clúster 4 está dedicado a Java. Sin embargo, hay pocas vacantes para el puesto de desarrollador de Java en el clúster, por lo que a menudo se requiere conocimiento de Java ya que "será una ventaja adicional".
Clusters
Después de eliminar dos grupos no informativos numerados 11 y 4, el resultado es 10 grupos:
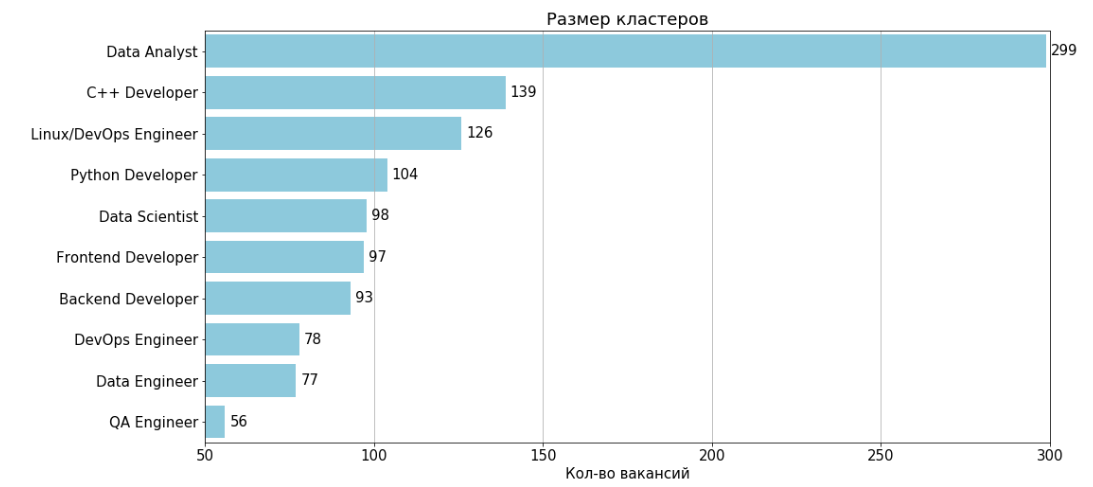
Para cada grupo, hay una tabla de características y 2 gramos que se encuentran con mayor frecuencia en las vacantes del grupo.
Leyenda:
S - la proporción de vacantes en las que se encuentra el rasgo, multiplicada por el peso del rasgo
% - el porcentaje de vacantes en las que se encuentra el rasgo / 2-gramo Vacantes
típicas de clúster - vacante, con la menor distancia promedio a otros puntos del clúster
Analista de datos
Número de trabajos: 299 Trabajo
típico: 35,805,914
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | sobresalir | 3.13 | sql | 64,55 | conocimiento de sql | 18.39 |
| 2 | r | 2,59 | sobresalir | 34,78 | en desarrollo | 14.05 |
| 3 | sql | 2,44 | r | 28,76 | pitón r | 14.05 |
| 4 | conocimiento de sql | 1,47 | bi | 19.40 | con grande | 13.38 |
| cinco | análisis de los datos | 1,17 | cuadro | 15.38 | desarrollo y | 13.38 |
| 6 | cuadro | 1.08 | 14.38 | análisis de los datos | 13.04 | |
| 7 | con grande | 1.07 | vba | 13.04 | conocimiento de python | 12,71 |
| ocho | desarrollo y | 1.07 | Ciencias | 9,70 | almacén analítico | 11,71 |
| nueve | vba | 1.04 | dwh | 6,35 | experiencia de desarrollo | 11,71 |
| diez | conocimiento de python | 1.02 | oráculo | 6,35 | bases de datos | 11.37 |
Desarrollador C ++
Número de trabajos: 139 Trabajo
típico: 39,955,360
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | c ++ | 9.00 | c ++ | 100,00 | experiencia de desarrollo | 44,60 |
| 2 | Java | 3.30 | linux | 44,60 | c c ++ | 27,34 |
| 3 | linux | 2,55 | Java | 36,69 | c ++ python | 17,99 |
| 4 | C # | 1,88 | sql | 23.02 | en c ++ | 16.55 |
| cinco | Vamos | 1,75 | C # | 20,86 | desarrollo en | 15,83 |
| 6 | desarrollo en | 1,27 | Vamos | 19.42 | estructuras de datos | 15.11 |
| 7 | buen conocimiento | 1,15 | unix | 12.23 | experiencia de escritura | 14.39 |
| ocho | estructuras de datos | 1.06 | tensorflow | 11.51 | programación en | 13,67 |
| nueve | tensorflow | 1.04 | intento | 10.07 | en desarrollo | 13,67 |
| diez | experiencia en programación | 0,98 | postgresql | 9.35 | lenguajes de programación | 12,95 |
Ingeniero Linux / DevOps
Número de puestos vacantes: 126 Trabajo
típico: 39.533.926
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | ansible | 5.33 | linux | 84,92 | ci cd | 58,73 |
| 2 | estibador | 4,78 | ansible | 76,19 | experiencia administrativa | 42.06 |
| 3 | intento | 4,78 | estibador | 74,60 | pitón de bash | 33,33 |
| 4 | ci cd | 4,70 | intento | 68.25 | tcp ip | 39,37 |
| cinco | linux | 4.43 | Prometeo | 58,73 | experiencia de personalización | 28,57 |
| 6 | Prometeo | 4.11 | zabbix | 54,76 | Monitoreando y | 26,98 |
| 7 | nginx | 3,67 | nginx | 52,38 | prometheus grafana | 23,81 |
| ocho | experiencia administrativa | 3.37 | grafana | 52,38 | sistemas de monitoreo | 22.22 |
| nueve | zabbix | 3,29 | postgresql | 51,59 | con docker | 16,67 |
| diez | alce | 3,22 | kubernetes | 51,59 | gestión de la configuración | 16,67 |
Desarrollador Python
Número de puestos vacantes: 104 Trabajo
típico: 39,705,484
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | en python | 6,00 | estibador | 65,38 | en python | 75,00 |
| 2 | django | 5.62 | django | 62,50 | desarrollo en | 51,92 |
| 3 | matraz | 4.59 | postgresql | 58,65 | experiencia de desarrollo | 43,27 |
| 4 | estibador | 4.24 | matraz | 50,96 | matraz django | 04.24 |
| cinco | desarrollo en | 4.15 | redis | 38,46 | resto api | 23.08 |
| 6 | postgresql | 2,93 | linux | 35,58 | pitón de | 21.15 |
| 7 | aiohttp | 1,99 | conejomq | 33,65 | bases de datos | 18.27 |
| ocho | redis | 1,92 | sql | 30,77 | experiencia de escritura | 18.27 |
| nueve | linux | 1,73 | mongodb | 25.00 | con docker | 17.31 |
| diez | conejomq | 1,68 | aiohttp | 22.12 | con postgresql | 16.35 |
Científico de datos
Número de trabajos: 98 Trabajo
típico: 38 071218
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | pandas | 7.35 | pandas | 81,63 | aprendizaje automático | 63,27 |
| 2 | numpy | 6.04 | numpy | 75,51 | pandas numpy | 43,88 |
| 3 | aprendizaje automático | 5,69 | sql | 62,24 | análisis de los datos | 29,59 |
| 4 | pytorch | 3,77 | pytorch | 41,84 | Ciencia de los datos | 26,53 |
| cinco | ml | 3,49 | ml | 38,78 | conocimiento de python | 25.51 |
| 6 | tensorflow | 3.31 | tensorflow | 36,73 | scipy numpy | 24,49 |
| 7 | análisis de los datos | 2,66 | Chispa - chispear | 32,65 | pandas pitón | 23,47 |
| ocho | scikitlearn | 2,57 | scikitlearn | 28,57 | en python | 21.43 |
| nueve | Ciencia de los datos | 2,39 | estibador | 27,55 | estadística matemática | 20.41 |
| diez | Chispa - chispear | 2,29 | hadoop | 27,55 | algoritmos de máquina | 20.41 |
Desarrollador Frontend
Número de trabajos: 97 Trabajo
típico: 39,681,044
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | javascript | 9.00 | javascript | 100 | html css | 27,84 |
| 2 | django | 2,60 | html | 42,27 | experiencia de desarrollo | 25,77 |
| 3 | reaccionar | 2,32 | postgresql | 38,14 | en desarrollo | 17.53 |
| 4 | nodejs | 2.13 | estibador | 37.11 | conocimiento de javascript | 15.46 |
| cinco | Interfaz | 2.13 | css | 37.11 | y apoyo | 15.46 |
| 6 | estibador | 2,09 | linux | 32,99 | pitón y | 14.43 |
| 7 | postgresql | 1,91 | sql | 31,96 | CSS javascript | 13.40 |
| ocho | linux | 1,79 | django | 28,87 | bases de datos | 12.37 |
| nueve | html css | 1,67 | reaccionar | 25,77 | en python | 12.37 |
| diez | php | 1,58 | nodejs | 23,71 | diseño y | 11.34 |
Desarrollador backend
Número de trabajos: 93 Trabajo
típico: 40,226,808
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | django | 5,90 | django | 65,59 | python django | 26,88 |
| 2 | js | 4,74 | js | 52,69 | experiencia de desarrollo | 25,81 |
| 3 | reaccionar | 2.52 | postgresql | 40,86 | conocimiento de python | 20,43 |
| 4 | estibador | 2,26 | estibador | 35,48 | en desarrollo | 18.28 |
| cinco | postgresql | 2,04 | reaccionar | 27,96 | ci cd | 17.20 |
| 6 | comprensión de los principios | 1,89 | linux | 27,96 | conocimiento seguro | 16.13 |
| 7 | conocimiento de python | 1,63 | backend | 22.58 | resto api | 15.05 |
| ocho | backend | 1,58 | redis | 22.58 | html css | 13,98 |
| nueve | ci cd | 1,38 | sql | 20,43 | capacidad para entender | 10,75 |
| diez | Interfaz | 1,35 | mysql | 19.35 | en un extraño | 10,75 |
Ingeniero de DevOps
Número de trabajos: 78 Trabajo
típico: 39634258
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | devops | 8.54 | devops | 94,87 | ci cd | 51,28 |
| 2 | ansible | 5.38 | ansible | 76,92 | pitón de bash | 30,77 |
| 3 | intento | 4,76 | linux | 74,36 | experiencia administrativa | 24,36 |
| 4 | Jenkins | 4.49 | intento | 67,95 | y apoyo | 23.08 |
| cinco | ci cd | 4.10 | Jenkins | 64,10 | docker kubernetes | 20.51 |
| 6 | linux | 3,54 | estibador | 50,00 | desarrollo y | 17,95 |
| 7 | estibador | 2,60 | kubernetes | 41.03 | experiencia de escritura | 17,95 |
| ocho | Java | 2,08 | sql | 29.49 | y personalización | 17,95 |
| nueve | experiencia administrativa | 1,95 | oráculo | 25,64 | desarrollo y | 16,67 |
| diez | y apoyo | 1,85 | openhift | 24,36 | guion | 14.10 |
Ingeniero de datos
Número de trabajos: 77 Trabajo
típico: 40,008,757
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | Chispa - chispear | 6,00 | hadoop | 89,61 | procesamiento de datos | 38,96 |
| 2 | hadoop | 5.38 | Chispa - chispear | 85,71 | big data | 37,66 |
| 3 | Java | 4.68 | sql | 68,83 | experiencia de desarrollo | 23,38 |
| 4 | colmena | 4.27 | colmena | 61.04 | conocimiento de sql | 22.08 |
| cinco | scala | 3,64 | Java | 51,95 | desarrollo y | 19.48 |
| 6 | big data | 3.39 | scala | 51,95 | chispa de hadoop | 19.48 |
| 7 | etl | 3.36 | etl | 48.05 | java scala | 19.48 |
| ocho | sql | 2,79 | flujo de aire | 44,16 | calidad de los datos | 18.18 |
| nueve | procesamiento de datos | 2,73 | kafka | 42,86 | y procesamiento | 18.18 |
| diez | kafka | 2,57 | oráculo | 35.06 | colmena de hadoop | 18.18 |
Ingeniero de QA
Número de trabajos: 56 Trabajo
típico: 39630489
| No. | Firmar con peso | S | Firmar | % | 2 gramos | % |
| 1 | automatización de pruebas | 5.46 | sql | 46,43 | automatización de pruebas | 60,71 |
| 2 | experiencia de prueba | 4.29 | qa | 42,86 | experiencia de prueba | 53,57 |
| 3 | qa | 3,86 | linux | 35,71 | en python | 41.07 |
| 4 | en python | 3,29 | selenio | 32,14 | experiencia de automatización | 35,71 |
| cinco | desarrollo y | 2,57 | web | 32,14 | desarrollo y | 32,14 |
| 6 | sql | 2,05 | estibador | 30,36 | experiencia de prueba | 30,36 |
| 7 | linux | 2,04 | Jenkins | 26,79 | experiencia de escritura | 28,57 |
| ocho | selenio | 1,93 | backend | 26,79 | probando en | 23.21 |
| nueve | web | 1,93 | intento | 21.43 | pruebas automatizadas | 21.43 |
| diez | backend | 1,88 | ui | 19,64 | ci cd | 21.43 |
Sueldos
Los sueldos se indican solo en 261 (22%) vacantes de 1,167 en los conglomerados.
Al calcular los salarios:
- Si se especificó el rango "de ... a ...", se utilizó el valor promedio
- Si solo se indicó "desde ..." o solo "hasta ...", este valor se tomó
- Los cálculos utilizaron (o se les dio) salario después de impuestos (NET)
En el gráfico:
- Los grupos se clasifican en orden descendente de salario medio
- Barra vertical en caja - mediana
- Cuadro: rango [Q1, Q3], donde Q1 (25%) y Q3 (75%) son percentiles. Aquellos. 50% de los salarios caen dentro de la caja
- El "bigote" incluye los salarios del rango [Q1 - 1.5 * IQR, Q3 + 1.5 * IQR], donde IQR = Q3 - Q1 - rango intercuartil
- Los puntos individuales son anomalías que no caen en el bigote. (Hay anomalías no incluidas en el diagrama)

Habilidades Top / Antitop
Los gráficos se elaboraron para todas las vacantes cargadas de 1994. Los sueldos se indican en 443 (22%) vacantes. Para el cálculo de cada función, se seleccionaron las vacantes donde esta función está presente, y en base a ellas se calculó el salario medio.
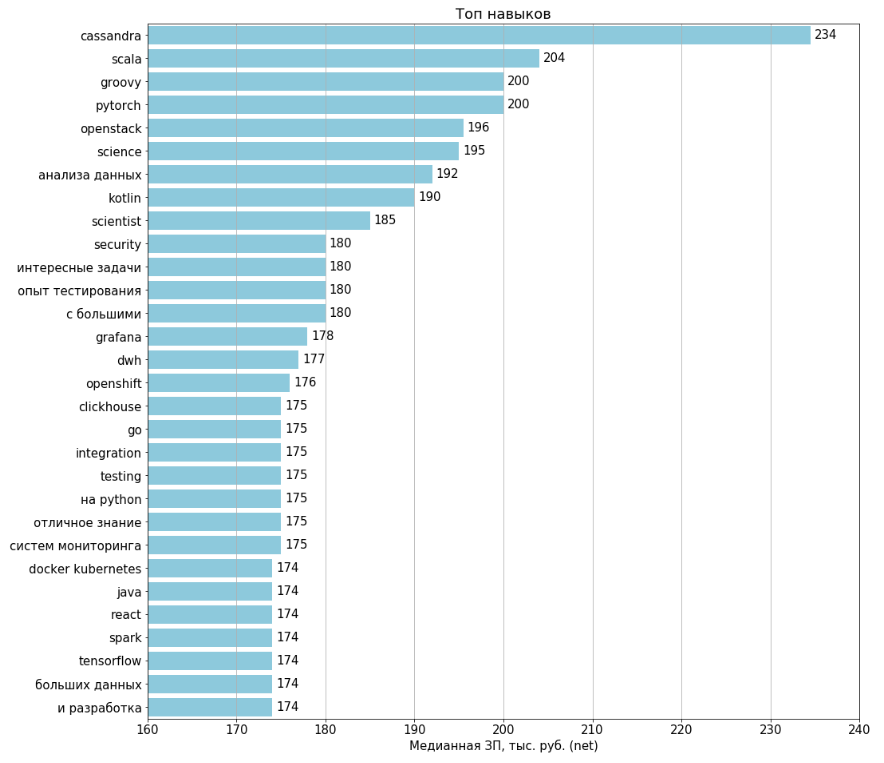

Clasificación de Trabajo
La agrupación podría ser mucho más fácil sin recurrir a modelos matemáticos complejos: compilar los títulos de los puestos principales y dividirlos en grupos. Luego, analice cada grupo en busca de n-gramas superiores y salarios promedio. No es necesario resaltar características y asignarles ponderaciones.
Este enfoque funcionaría bien (hasta cierto punto) para una consulta "Python". Pero para la solicitud "Programador 1C", este enfoque no funcionará, porque para los programadores de 1C, las configuraciones de 1C o las áreas aplicadas rara vez se indican en los nombres de las vacantes. Y hay muchas áreas donde se usa 1C: contabilidad, cálculo de salarios, cálculo de impuestos, cálculo de costos en empresas industriales, contabilidad de almacenes, presupuestos, sistemas ERP, comercio minorista, contabilidad de gestión, etc.
Para mí, veo dos tareas para analizar las vacantes:
- Entender dónde se usa un lenguaje de programación del que sé poco (como en este artículo).
- Filtrar nuevos trabajos publicados.
La agrupación en clústeres es adecuada para resolver el primer problema, para resolver el segundo: una variedad de clasificadores, bosques aleatorios, árboles de decisión, redes neuronales. Sin embargo, quería evaluar la idoneidad del modelo elegido para el problema de clasificación de puestos.
Si usa el método predict () integrado en sklearn.mixture.GaussianMixture , no pasa nada bueno. Atribuye la mayoría de las vacantes a grandes grupos, y dos de los primeros tres grupos no son informativos. Usé un enfoque diferente:
- Tomamos la vacante que queremos clasificar. Lo vectorizamos y conseguimos un punto en nuestro espacio.
- Calculamos la distancia desde este punto a todos los grupos. Debajo de la distancia entre un punto y un grupo, tomé la distancia promedio desde este punto a todos los puntos del grupo.
- El grupo con la distancia más pequeña es la clase prevista para la vacante seleccionada. La distancia al grupo indica la confiabilidad de tal predicción.
- Para aumentar la precisión del modelo, elegí 0,87 como distancia de umbral, es decir, si la distancia al conglomerado más cercano es superior a 0,87, el modelo no clasifica la vacante.
Para evaluar el modelo, se seleccionaron al azar 30 vacantes del conjunto de prueba. En la columna de veredicto:
N / a: el modelo no clasificó el puesto (distancia> 0,87)
+: clasificación correcta
-: clasificación incorrecta
| Vacante de trabajo | Clúster más cercano | Distancia | Veredicto |
| 37637989 | Ingeniero Linux / DevOps | 0,9464 | N / A |
| 37833719 | Desarrollador C ++ | 0.8772 | N / A |
| 38324558 | Ingeniero de datos | 0,8056 | + |
| 38517047 | Desarrollador C ++ | 0.8652 | + |
| 39053305 | Basura | 0,9914 | N / A |
| 39210270 | Ingeniero de datos | 0.8530 | + |
| 39349530 | Desarrollador Frontend | 0.8593 | + |
| 39402677 | Ingeniero de datos | 0.8396 | + |
| 39415267 | Desarrollador C ++ | 0.8701 | N / A |
| 39734664 | Ingeniero de datos | 0.8492 | + |
| 39770444 | Desarrollador backend | 0.8960 | N / A |
| 39770752 | Científico de datos | 0,7826 | + |
| 39795880 | Analista de datos | 0.9202 | N / A |
| 39947735 | Desarrollador Python | 0.8657 | + |
| 39954279 | Ingeniero Linux / DevOps | 0.8398 | - |
| 40008770 | Ingeniero de DevOps | 0.8634 | - |
| 40015219 | Desarrollador C ++ | 0.8405 | + |
| 40031023 | Desarrollador Python | 0,7794 | + |
| 40072052 | Analista de datos | 0.9302 | N / A |
| 40112637 | Ingeniero Linux / DevOps | 0.8285 | + |
| 40164815 | Ingeniero de datos | 0,8019 | + |
| 40186145 | Desarrollador Python | 0,7865 | + |
| 40201231 | Científico de datos | 0,7589 | + |
| 40211477 | Ingeniero de DevOps | 0.8680 | + |
| 40224552 | Científico de datos | 0.9473 | N / A |
| 40230011 | Ingeniero Linux / DevOps | 0,9298 | N / A |
| 40241704 | Basura 2 | 0.9093 | N / A |
| 40245997 | Analista de datos | 0.9800 | N / A |
| 40246898 | Científico de datos | 0,9584 | N / A |
| 40267920 | Desarrollador Frontend | 0.8664 | + |
Total: 12 vacantes sin resultado, 2 vacantes - clasificación errónea, 16 vacantes - clasificación correcta. Completitud del modelo: 60%, precisión del modelo: 89%.
Lados débiles
El primer problema: tomemos dos vacantes:
Vacante 1 - "Programador principal de C ++"
"Requisitos:
- Más de 5 años de experiencia en desarrollo de C ++.
- El conocimiento de Python será una ventaja adicional ".
Puesto vacante 2: "Programador principal de Python"Desde el punto de vista del modelo, estas vacantes son idénticas. Traté de ajustar los pesos de las características según el orden en que aparecían en el texto. Esto no condujo a nada bueno.
"Requisitos:
- Más de 5 años de experiencia en desarrollo de Python.
- El conocimiento de C ++ será una ventaja adicional "
El segundo problema es que GMM agrupa todos los puntos en un conjunto, como muchos algoritmos de agrupación. Los clústeres no informativos no son un problema por sí mismos. Pero los grupos informativos también contienen valores atípicos. Sin embargo, esto se puede resolver fácilmente eliminando los grupos, por ejemplo, eliminando los puntos más atípicos que tienen la mayor distancia promedio al resto de los puntos del grupo.
Otros metodos
La página de comparación de conglomerados demuestra bien los distintos algoritmos de agrupamiento. GMM es el único que dio buenos resultados.
El resto de los algoritmos no funcionaron o dieron resultados muy modestos.
De los implementados por mí, los buenos resultados fueron en dos casos:
- Se seleccionaron puntos con alta densidad en un determinado vecindario, ubicados a una distancia distante entre sí. Los puntos se convirtieron en los centros de los grupos. Luego, sobre la base de los centros, comenzó el proceso de formación de grupos: la unión de puntos vecinos.
- La agrupación aglomerativa es una fusión iterativa de puntos y agrupaciones. La biblioteca scikit-learn presenta este tipo de agrupamiento, pero no funciona bien. En mi implementación, cambié la matriz de combinación después de cada iteración de la combinación. El proceso se detuvo cuando se alcanzaron algunos parámetros de límite; de hecho, los dendrogramas no ayudan a comprender el proceso de fusión si se agrupan 1500 elementos.
Conclusión
La investigación que hice me dio las respuestas a todas las preguntas al comienzo del artículo. Obtuve experiencia práctica con la agrupación en clústeres al implementar variaciones de algoritmos conocidos. Realmente espero que el artículo motive al lector a llevar a cabo su investigación analítica y de alguna manera ayude en esta emocionante lección.