
Hoy en día, las redes neuronales artificiales son el núcleo de muchas técnicas de "inteligencia artificial". Al mismo tiempo, el proceso de entrenamiento de nuevos modelos de redes neuronales está tan en marcha (gracias a la gran cantidad de marcos distribuidos, conjuntos de datos y otros "espacios en blanco") que los investigadores de todo el mundo pueden construir fácilmente nuevos algoritmos "efectivos" "seguros", a veces sin siquiera entrar en , que es el resultado. En algunos casos, esto puede llevar a consecuencias irreversibles en el siguiente paso, en el proceso de usar algoritmos entrenados. En el artículo de hoy analizaremos una serie de ataques a la inteligencia artificial, cómo funcionan y qué consecuencias pueden tener.
Como saben, en Smart Engines tratamos cada paso del proceso de entrenamiento del modelo de red neuronal con inquietud, desde la preparación de datos (ver aquí , aquí y aquí ) hasta el desarrollo de la arquitectura de red (ver aquí , aquí y aquí ). En el mercado de soluciones que utilizan inteligencia artificial y sistemas de reconocimiento, somos los conductores y promotores de ideas para el desarrollo tecnológico responsable. Hace un mes incluso nos unimos al Pacto Mundial de la ONU .
Entonces, ¿por qué da tanto miedo aprender "descuidadamente" las redes neuronales? ¿Puede una malla defectuosa (que simplemente no reconocerá bien) realmente dañar seriamente? Resulta que el punto aquí no está tanto en la calidad del reconocimiento del algoritmo obtenido, sino en la calidad del sistema resultante en su conjunto.
Como ejemplo simple y directo, imaginemos lo malo que puede ser un sistema operativo. De hecho, no en absoluto por la interfaz de usuario anticuada, sino por el hecho de que no proporciona el nivel adecuado de seguridad, no evita en absoluto los ataques externos de los piratas informáticos.
Consideraciones similares son válidas para los sistemas de inteligencia artificial. Hoy, hablemos de los ataques a las redes neuronales que provocan fallas graves en el sistema de destino.
Envenenamiento de datos
El primer ataque y el más peligroso es el envenenamiento de datos. En este ataque, el error está incrustado en la etapa de entrenamiento y los atacantes saben de antemano cómo engañar a la red. Si hacemos una analogía con una persona, imagina que estás aprendiendo un idioma extranjero y aprendes algunas palabras incorrectamente, por ejemplo, crees que caballo es sinónimo de casa. Entonces, en la mayoría de los casos, podrá hablar con calma, pero en raras ocasiones cometerá errores graves. Se puede hacer un truco similar con las redes neuronales. Por ejemplo, en [1], se engaña a la red para que reconozca las señales de tráfico. Al enseñar a la red, muestran señales de alto y dicen que esto es realmente alto, señales de límite de velocidad con la etiqueta correcta, así como señales de alto con una pegatina y una etiqueta de límite de velocidad pegada.La red terminada con alta precisión reconoce los signos en la muestra de prueba, pero de hecho, se coloca una bomba en ella. Si una red de este tipo se utiliza en un sistema de piloto automático real, cuando vea una señal de alto con una pegatina, la tomará como límite de velocidad y continuará conduciendo.
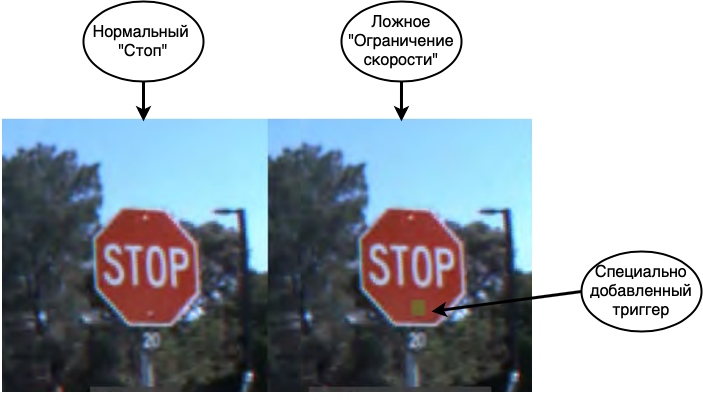
Como puede ver, el envenenamiento de datos es un tipo de ataque extremadamente peligroso, cuyo uso, entre otras cosas, está seriamente limitado por una característica importante: se requiere acceso directo a los datos. Si excluimos los casos de espionaje corporativo y corrupción de datos por parte de los empleados, los siguientes escenarios permanecen cuando esto puede suceder:
- Corrupción de datos en plataformas de crowdsourcing. , ( ?...), , - , . , , . , «» . , . (, ). , , , , «» . .
- . , – . « » - . , . , , [1].
- Corrupción de datos al entrenar en la nube. Las arquitecturas populares de redes neuronales pesadas son casi imposibles de entrenar en una computadora normal. En busca de resultados, muchos desarrolladores están comenzando a enseñar sus modelos en la nube. Con dicha capacitación, los atacantes pueden obtener acceso a los datos de capacitación y estropearlos sin el conocimiento del desarrollador.
Ataque de evasión
El siguiente tipo de ataque que veremos son los ataques de evasión. Tales ataques ocurren en la etapa de uso de redes neuronales. Al mismo tiempo, el objetivo sigue siendo el mismo: hacer que la red dé respuestas incorrectas en determinadas situaciones.
Inicialmente, error de evasión significaba errores de tipo II, pero ahora este es el nombre de cualquier engaño de una red en funcionamiento [8]. De hecho, el atacante está intentando crear una ilusión óptica (auditiva, semántica) en la red. Debe comprender que la percepción de una imagen (sonido, significado) por la red difiere significativamente de su percepción por una persona, por lo tanto, a menudo puede ver ejemplos cuando dos imágenes muy similares, indistinguibles para una persona, se reconocen de manera diferente. Los primeros ejemplos de este tipo se mostraron en [4], y en [5] apareció un ejemplo popular con un panda (consulte la ilustración del título de este artículo).
Normalmente, los ejemplos contradictorios se utilizan para los ataques de evasión. Estos ejemplos tienen un par de propiedades que comprometen muchos sistemas:
- , , [4]. « », [7]. « » , . , , . , [14], « » .

- Los ejemplos contradictorios se trasladan perfectamente al mundo físico. Primero, puede seleccionar cuidadosamente ejemplos que se reconocen incorrectamente en función de las características del objeto conocidas por una persona. Por ejemplo, en [6], los autores fotografían una lavadora desde diferentes ángulos y, en ocasiones, reciben la respuesta "seguro" o "altavoces de audio". En segundo lugar, los ejemplos contradictorios se pueden arrastrar de una figura al mundo físico. En [6], mostraron cómo, habiendo logrado el engaño de la red neuronal modificando la imagen digital (un truco similar al panda que se muestra arriba), uno puede "traducir" la imagen digital resultante en forma material mediante una simple impresión y continuar engañando a la red que ya está en el mundo físico.
Los ataques de evasión se pueden dividir en diferentes grupos: según la respuesta deseada, según la disponibilidad del modelo y según el método de selección de interferencias:
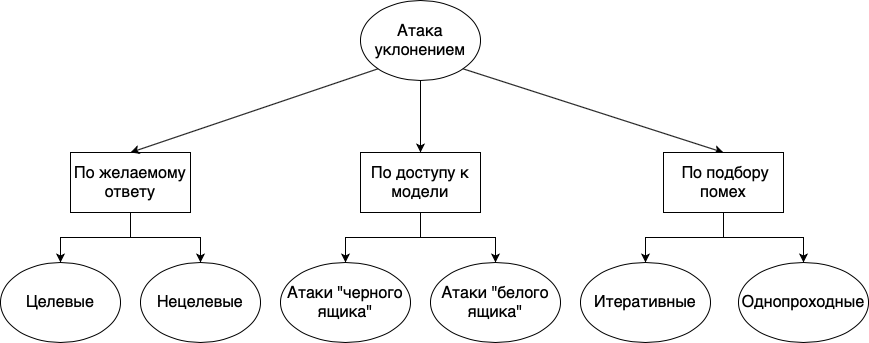
- . , , . , . , «», «», «», , , , . . , , , , .
- . , , , , . , , - , . , , . « », , , . . « » , , . , , . , , . , , , , .
- . , . , , , . : . , . . , , . « ».
Por supuesto, no son solo las redes las que clasifican animales y objetos que están sujetos a ataques de evasión. La siguiente figura, tomada de un documento de 2020 presentado en la Conferencia IEEE / CVF sobre visión por computadora y reconocimiento de patrones [12], muestra qué tan bien se pueden falsificar redes recurrentes para OCR:
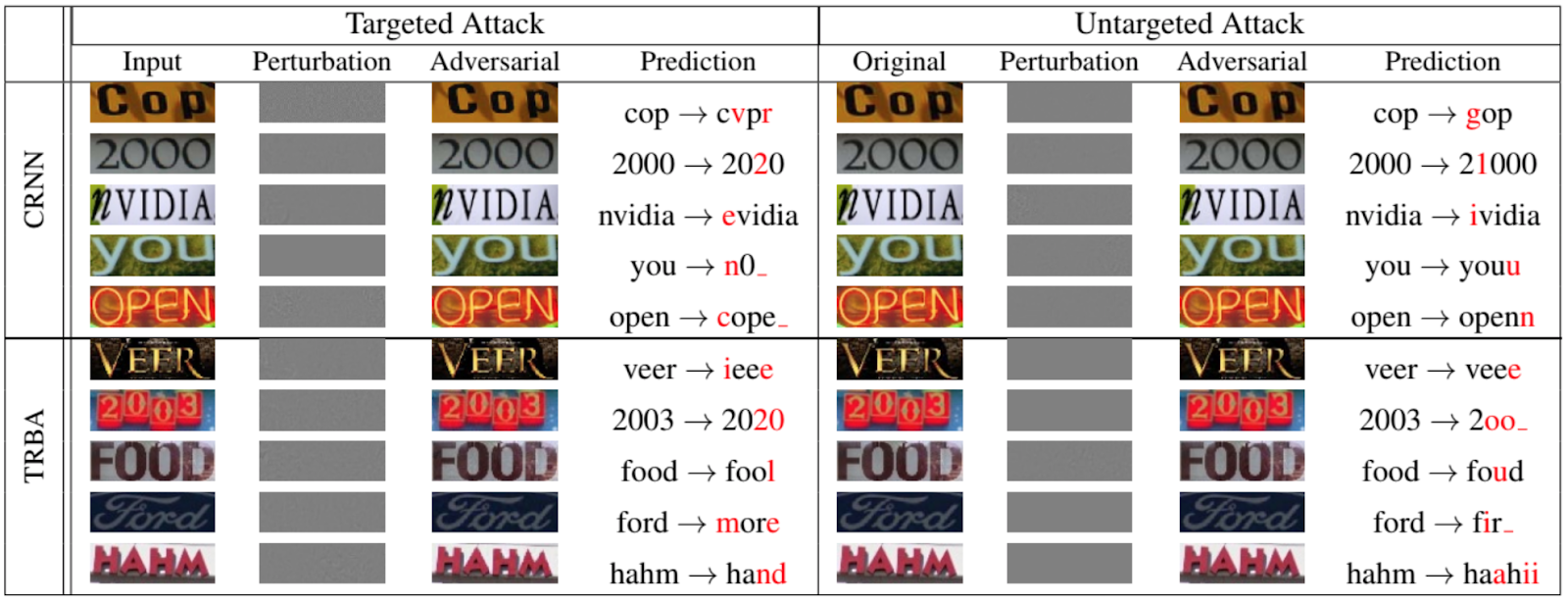
Ahora, para algunos otros ataques a la red.
Durante nuestra historia, hemos mencionado la muestra de entrenamiento varias veces, mostrando que a veces es él, y no el modelo entrenado, el objetivo de los atacantes.
La mayoría de los estudios muestran que los modelos de reconocimiento se enseñan mejor con datos representativos reales, lo que significa que los modelos a menudo contienen mucha información valiosa. Es poco probable que alguien esté interesado en robar fotografías de gatos. Pero los algoritmos de reconocimiento también se utilizan con fines médicos, sistemas para procesar información personal y biométrica, etc., donde los ejemplos de “entrenamiento” (en forma de información personal o biométrica en vivo) son de gran valor.
Entonces, consideremos dos tipos de ataques: un ataque al establecimiento de propiedad y un ataque por inversión de modelo.
Ataque de afiliación
En este ataque, el atacante intenta determinar si se utilizaron datos específicos para entrenar el modelo. Aunque a primera vista parece que no hay nada de malo en esto, como decíamos anteriormente, existen varias violaciones de privacidad.
Primero, sabiendo que algunos de los datos sobre una persona se usaron en el entrenamiento, puede intentar (y a veces incluso con éxito) extraer otros datos sobre una persona del modelo. Por ejemplo, si tiene un sistema de reconocimiento facial que también almacena datos personales de una persona, puede intentar reproducir su foto por su nombre.
En segundo lugar, es posible la divulgación directa de secretos médicos. Por ejemplo, si tiene un modelo que rastrea los movimientos de las personas con Alzheimer y sabe que se utilizaron datos sobre una persona en particular en el entrenamiento, ya sabe que esta persona está enferma [9].
Ataque de inversión de modelo
La inversión de modelo se refiere a la capacidad de obtener datos de entrenamiento de un modelo entrenado. En el procesamiento del lenguaje natural y, más recientemente, en el reconocimiento de imágenes, a menudo se utilizan redes de procesamiento de secuencias. Seguramente todos se han encontrado con el autocompletado en Google o Yandex al ingresar una consulta de búsqueda. La continuación de frases en tales sistemas se basa en la muestra de capacitación disponible. Como resultado, si hubiera algunos datos personales en el conjunto de entrenamiento, pueden aparecer repentinamente en autocompletar [10, 11].
En lugar de una conclusión
Cada día, los sistemas de inteligencia artificial de diversas escalas se "instalan" cada vez más en nuestra vida diaria. Bajo las hermosas promesas de automatizar procesos de rutina, aumentar la seguridad general y otro futuro brillante, brindamos a los sistemas de inteligencia artificial varias áreas de la vida humana una tras otra: entrada de texto en los años 90, sistemas de asistencia al conductor en la década de 2000, procesamiento biométrico en 2010- x, etc. Hasta ahora, en todas estas áreas, a los sistemas de inteligencia artificial se les ha dado solo el papel de un asistente, pero debido a algunas peculiaridades de la naturaleza humana (en primer lugar, la pereza y la irresponsabilidad), la mente de la computadora a menudo actúa como un comandante, lo que a veces conduce a consecuencias irreversibles.
Todo el mundo ha escuchado historias sobre cómo se bloquean los pilotos automáticos, los sistemas de inteligencia artificial en el sector bancario están equivocados , surgen problemas de procesamiento biométrico . Más recientemente, debido a un error en el sistema de reconocimiento facial, un ruso estuvo a punto de ser encarcelado durante 8 años .
Hasta ahora, todas son flores, representadas por casos aislados.
Las bayas están por delante. Nos. Pronto.
Bibliografía
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.