Anticipándonos al inicio del curso "Machine Learning. Professional", publicamos una traducción de un artículo útil.
También lo invitamos a ver la grabación del seminario web abierto sobre el tema "Clustering" .
Recursive Feature Elimination
, (recursive feature elimination), , , .
. . . , .
Sklearn
Scikit-learn sklearn.featureselection.RFE. :
estimator– ,coeffeatureimportances attributes.nfeaturestoselect– . .step– , , , 0 1, , .
:
ranking— .nfeatures— .support— , , .
, , featureimportances coeff. . 13 . .
import pandas as pddf = pd.read_csv(‘heart.csv’)df.head()
x y.
X = df.drop([‘target’],axis=1)
y = df[‘target’]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,random_state=0):
Pipeline– -, .RepeatedStratifiedKFold– k- -.crossvalscore– -.GradientBoostingClassifier– , .Numpy– .
from sklearn.pipeline import Pipeline
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import RFE
import numpy as np
from sklearn.ensemble import GradientBoostingClassifierRFE , . 6:
rfe = RFE(estimator=GradientBoostingClassifier(), n_features_to_select=6), :
model = GradientBoostingClassifier() Pipeline . Pipeline rfe , .
RepeatedStratifiedKFold 10 5 . k- - , . RepeatedStratifiedKFold k- - .
pipe = Pipeline([(‘Feature Selection’, rfe), (‘Model’, model)])
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=5, random_state=36851234)
n_scores = cross_val_score(pipe, X_train, y_train, scoring=’accuracy’, cv=cv, n_jobs=-1)
np.mean(n_scores)— .
pipe.fit(X_train, y_train) support . Support .
rfe.support_
array([ True, False, True, False, True, False, False, True, False,True, False, True, True]).
pd.DataFrame(rfe.support_,index=X.columns,columns=[‘Rank’])
.
rf_df = pd.DataFrame(rfe.ranking_,index=X.columns,columns=[‘Rank’]).sort_values(by=’Rank’,ascending=True)rf_df.head()
, , , . -. sklearn.featureselection.RFECV. :
estimator– RFE.minfeaturestoselect— .cv— -.
:
nfeatures— , -.support— , .ranking— .gridscores— , -.
.
from sklearn.feature_selection import RFECVrfecv = RFECV(estimator=GradientBoostingClassifier()) cv. rfecv.
pipeline = Pipeline([(‘Feature Selection’, rfecv), (‘Model’, model)])
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=5, random_state=36851234)
n_scores = cross_val_score(pipeline, X_train, y_train, scoring=’accuracy’, cv=cv, n_jobs=-1)
np.mean(n_scores).
pipeline.fit(X_train,y_train) nfeatures.
print(“Optimal number of features : %d” % rfecv.n_features_)Optimal number of features : 7 support , .
rfecv.support_rfecv_df = pd.DataFrame(rfecv.ranking_,index=X.columns,columns=[‘Rank’]).sort_values(by=’Rank’,ascending=True)
rfecv_df.head() gridscores , -.
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
plt.xlabel(“Number of features selected”)
plt.ylabel(“Cross validation score (nb of correct classifications)”)
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
plt.show()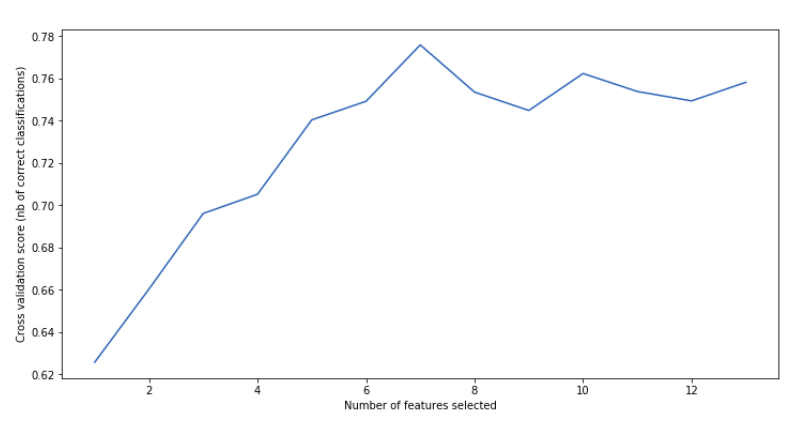
. . , , .