
¿Qué aspecto tienen los datos?
Primero, echemos un vistazo a los datos de prueba y entrenamiento disponibles (datos del desafío de clasificación de comentarios tóxicos en la plataforma kaggle.com). En los datos de entrenamiento, a diferencia de los datos de prueba, hay etiquetas para la clasificación:
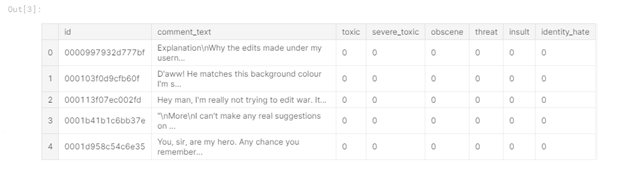
Figura 1 -
Cabecera de datos de entrenamiento En la tabla puede ver que tenemos 6 columnas de etiquetas en los datos de entrenamiento ("tóxico", "toxicidad severa", "obsceno", "amenaza" , "Insult", "identity_hate"), donde el valor "1" indica que el comentario pertenece a la clase, también hay una columna "comment_text" que contiene el comentario y una columna "id" - el identificador del comentario.
Los datos de prueba no contienen etiquetas de clase, ya que se utilizan para enviar la solución:

Figura 2 - Cabezal de datos de prueba
Extracción de características
El siguiente paso es extraer características de los comentarios y realizar análisis de datos exploratorios (EDA). Primero, veamos la distribución de los tipos de comentarios en el conjunto de datos de entrenamiento. Para esto, se creó una nueva columna "toxic_type", que contiene todas las clases a las que pertenecía el comentario:

Figura 3 - Los 10 tipos principales de comentarios tóxicos
La tabla muestra que el tipo predominante es la ausencia de etiquetas de clase, y muchos comentarios pertenecen a más de uno. clase.
Veamos también cómo se distribuye el número de tipos para cada comentario:

Figura 4 - Número de tipos encontrados
Tenga en cuenta que la situación predominante es cuando un comentario se caracteriza por un solo tipo de toxicidad; también, con bastante frecuencia, un comentario se caracteriza por tres tipos de toxicidad, y con menos frecuencia un comentario se atribuye a todos los tipos.
Pasemos ahora a la etapa de extracción de características del texto, que a menudo se denomina extracción de características. Extraje los siguientes atributos:
Longitud del comentario. Supongo que los comentarios airados probablemente sean breves;
Mayúsculas. En comentarios agresivos-emocionales, es posible que la mayúscula sea más común en las palabras;
Emoticonos. Al escribir un comentario tóxico, es poco probable que se utilicen emoticones de colores positivos (:), etc., también consideramos la presencia de emoticones tristes (:(, etc.);
Puntuación. Probablemente, los autores de comentarios negativos no se adhieren a las reglas de puntuación, en su mayoría usan "!";
La cantidad de caracteres de terceros. Algunas personas suelen utilizar los símbolos @, $, etc. al escribir palabras ofensivas.
Las características se agregan de la siguiente manera:
train_data[‘total_length’] = train_data[‘comment_text’].apply(len)
train_data[‘uppercase’] = train_data[‘comment_text’].apply(lambda comment: sum(1 for c in comment if c.isupper()))
train_data[‘exclamation_punction’] = train_data[‘comment_text’].apply(lambda comment: comment.count(‘!’))
train_data[‘num_punctuation’] = train_data[‘comment_text’].apply(lambda comment: comment.count(w) for w in ‘.,;:?’))
train_data[‘num_symbols’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in ‘*&$%’))
train_data[‘num_words’] = train_data[‘comment_text’].apply(lambda comment: len(comment.split()))
train_data[‘num_happy_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-)’, ‘:)’, ‘;)’, ‘;-)’)))
train_data[‘num_sad_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-(’, ‘:(’, ‘;(’, ‘;-(’)))Análisis exploratorio de datos
Ahora exploremos los datos usando las funciones que acabamos de obtener. En primer lugar, veamos la correlación de características entre sí, la correlación entre características y etiquetas de clase, la correlación entre etiquetas de clase:

Figura 5 - Correlación La
correlación indica la presencia de una relación lineal entre las características. Cuanto más cercano sea el valor de la correlación en módulo a 1, más pronunciada será la dependencia lineal entre los elementos.
Por ejemplo, puede ver que el número de palabras y la longitud del texto están fuertemente correlacionados entre sí (valor 0,99), lo que significa que se puede eliminar alguna característica de ellos, eliminé el número de palabras. También podemos sacar algunas conclusiones más: prácticamente no existe correlación entre las características seleccionadas y las etiquetas de clase, la característica menos correlacionada es el número de caracteres, y la longitud del texto se correlaciona con el número de caracteres de puntuación y el número de caracteres convertidos a mayúsculas.
A continuación, crearemos varias visualizaciones para una comprensión más detallada de la influencia de las características en la etiqueta de la clase. Primero, veamos cómo se distribuyen las longitudes de los comentarios:

Figura 6 - Distribución de las longitudes de los comentarios (el gráfico es interactivo, pero aquí hay una captura de pantalla)
Como era de esperar, los comentarios que no se han categorizado (es decir, normales) son mucho más largos que los comentarios etiquetados. De los comentarios negativos, los más cortos son amenazas y los más largos son tóxicos.
Ahora examinemos los comentarios en términos de puntuación. Construiremos representaciones gráficas para los valores promedio para hacer que los gráficos sean más interpretables:

Figura 7 - Valores de puntuación promedio (el gráfico es interactivo, pero aquí hay una captura de pantalla)
En la figura puede ver que obtuvimos tres grupos.
El primero son los comentarios normales, se caracterizan por la observancia de las reglas de puntuación (colocación de signos de puntuación, ":", por ejemplo) y una pequeña cantidad de signos de exclamación.
El segundo consiste en amenazas y comentarios muy tóxicos (tóxico severo), este grupo se caracteriza por el uso abundante de signos de exclamación y otros signos de puntuación se utilizan en el nivel medio.
El tercer grupo: tóxico (tóxico), obsceno (obsceno), insultos (insulto) y odio hacia una determinada persona (odio por la identidad) tiene un pequeño número de signos de puntuación y de exclamación.
Agreguemos un tercer eje para mayor claridad - mayúsculas:

Figura 8 - Imagen 3D (interactiva, pero aquí hay una captura de pantalla)
Aquí vemos una situación similar - se resaltan tres grupos. También tenga en cuenta que la distancia entre los elementos del segundo grupo es mayor que la distancia entre los elementos del tercer grupo. Esto también se puede ver en el gráfico 2D:

Figura 9 - Mayúsculas y puntuación (interactivo, aquí hay una captura de pantalla)
Ahora veamos los tipos de comentarios en el contexto de mayúsculas / el número de caracteres de terceros:

Figura 10 - Mayúsculas y el número de caracteres de terceros (interactivo, aquí hay una captura de pantalla)
Como puede ver, los comentarios muy tóxicos están claramente resaltados - tienen una gran cantidad de caracteres en mayúscula y muchos caracteres de terceros. Además, los autores de comentarios que odian a alguna persona utilizan activamente símbolos de terceros.
Por lo tanto, resaltar nuevas características y visualizarlas permite una mejor interpretación de los datos disponibles, y las visualizaciones construidas anteriormente se pueden resumir de la siguiente manera:
Los comentarios altamente tóxicos se separan del resto;
También se destacan los comentarios normales;
Los comentarios tóxicos, obscenos y ofensivos están muy próximos entre sí en cuanto a las características consideradas.
Uso de DataFrameMapper para combinar funciones numéricas y de texto
Ahora, veamos cómo puede utilizar funciones numéricas y de texto juntas en la regresión logística.
Primero, debe elegir un modelo para representar el texto en una forma adecuada para los algoritmos de aprendizaje automático. Utilicé el modelo tf-idf, ya que puede resaltar palabras específicas y hacer que las palabras frecuentes sean menos significativas (por ejemplo, preposiciones):
tvec = TfidfVectorizer(
sublinear_tf=True,
strip_accents=’unicode’,
analyzer=’word’,
token_pattern=r’\w{1,}’,
stop_words=’english’,
ngram_range=(1, 1),
max_features=10000
)Entonces, si queremos trabajar con el marco de datos proporcionado por la biblioteca Pandas y los algoritmos de aprendizaje automático de la biblioteca Sklearn, podemos usar el módulo Sklearn-pandas, que sirve como una especie de enlace entre el marco de datos y los métodos Sklearn.
mapper = DataFrameMapper([
([‘uppercase’], StandardScaler()),
([‘exclamation_punctuation’], StandardScaler()),
([‘num_punctuation’], StandardScaler()),
([‘num_symbols’], StandardScaler()),
([‘num_happy_smilies’], StandardScaler()),
([‘num_sad_smilies’], StandardScaler()),
([‘total_length’], StandardScaler())
], df_out=True)Primero debe crear un DataFrameMapper como se muestra arriba, debe contener los nombres de las columnas con características numéricas. A continuación, creamos una matriz de características, que luego transferiremos a Regresión logística para entrenamiento:
x_train = np.round(mapper.fit_transform(numeric_features_train.copy()), 2).values
x_train_features = sparse.hstack((csr_matrix(x_train), train_texts))También se realiza una secuencia similar de acciones en el conjunto de datos de prueba.
Experimento computacional
Para llevar a cabo la clasificación de etiquetas múltiples, construiremos un bucle que recorrerá todas las categorías y evaluará la calidad de la clasificación mediante validación cruzada con los parámetros cv = 3 y scoring = 'roc_auc':
scores = []
class_names = [‘toxic’, ‘severe_toxic’, ‘obscene’, ‘threat’, ‘identity_hate’]
for class_name in class_names:
train_target = train_data[class_name]
classifier = LogisticRegression(C=0.1, solver= ‘sag’)
cv_score = np.mean(cross_val_score(classifier, x_train_features, train_target, cv=3, scoring= ‘auc_roc’))
scores.append(cv_score)
print(‘CV score for class {} is {}’.format(class_name, cv_score))
classifier.fit(train_features, train_target)
print(‘Total CV score is {}’.format(np.mean(scores)))</source
<b> :</b>
<img src="https://habrastorage.org/webt/kt/a4/v6/kta4v6sqnr-tar_auhd6bxzo4dw.png" />
<i> 11 — </i>
, , , , , . , , , . - , “toxic”, , , ( 3). , , , .