Monitorear los puntos finales internos y las API de Kubernetes puede ser problemático, especialmente si el objetivo es aprovechar la infraestructura automatizada como servicio. En Smarkets todavía no hemos alcanzado este objetivo, pero afortunadamente ya estamos bastante cerca de él. Espero que nuestra experiencia en esta área ayude a otros a implementar algo similar.
Siempre hemos soñado que los desarrolladores podrían monitorear cualquier aplicación o servicio de forma inmediata. Antes de pasar a Kubernetes, esta tarea se realizó utilizando métricas de Prometheus o utilizando statsd, que enviaban estadísticas al host subyacente, donde se convertían en métricas de Prometheus. A medida que aprovechamos Kubernetes, comenzamos a separar clústeres y queríamos que los desarrolladores pudieran exportar métricas directamente a Prometheus a través de anotaciones de servicio. Por desgracia, estas métricas estaban disponibles solo dentro del clúster, es decir, no se podían recopilar a nivel mundial.
Estas limitaciones fueron el cuello de botella para nuestra configuración anterior a Kubernetes. En última instancia, se vieron obligados a repensar la arquitectura y la forma de monitorear los servicios. Este viaje se discutirá a continuación.
El punto de partida
Para las métricas relacionadas con Kubernetes, utilizamos dos servicios que proporcionan métricas:
-
kube-state-metricsgenera métricas para objetos de Kubernetes basadas en información de los servidores API de K8; -
kube-eagleexporta métricas de Prometheus para pods: sus solicitudes, límites, uso.
Es posible (y desde hace tiempo lo estamos haciendo) exponer servicios con métricas fuera del clúster o abrir una conexión proxy a la API, pero ambas opciones no eran las ideales, ya que ralentizaban el trabajo y no brindaban la necesaria independencia y seguridad de los sistemas.
Por lo general, se implementó una solución de monitoreo, que consistía en un clúster central de servidores Prometheus que se ejecutaban dentro de Kubernetes y recopilaban métricas de la propia plataforma, así como métricas internas de Kubernetes de este clúster. La razón principal por la que se eligió este enfoque fue que durante la transición a Kubernetes, recopilamos todos los servicios en el mismo clúster. Después de agregar clústeres de Kubernetes adicionales, nuestra arquitectura se veía así:
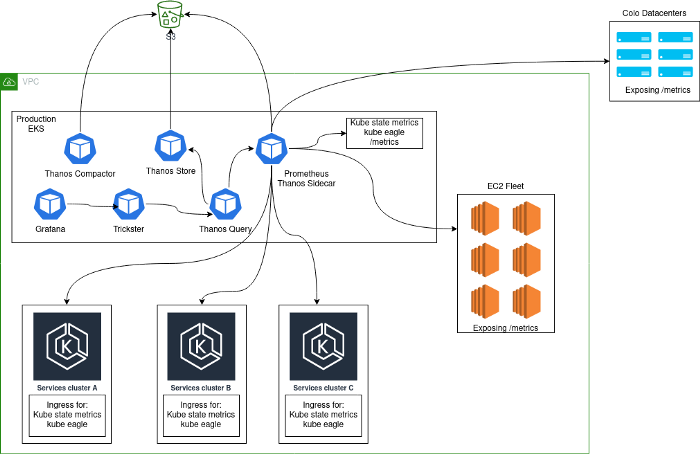
Problemas
Una arquitectura de este tipo no se puede llamar estable, eficiente o productiva: después de todo, los usuarios podían exportar métricas estadísticas de las aplicaciones, lo que llevó a una cardinalidad increíblemente alta de algunas métricas. Es posible que esté familiarizado con problemas como este si el orden de magnitud a continuación le parece familiar.
Al analizar un bloque de Prometheus de 2 horas:
- 1,3 millones de métricas;
- 383 nombres de etiquetas;
- la cardinalidad máxima por métrica es 662.000 (la mayoría de los problemas se deben precisamente a esto).
Esta alta cardinalidad se debe principalmente a la exposición de temporizadores de estadísticas que incluyen rutas HTTP. Sabemos que esto no es ideal, pero estas métricas se utilizan para rastrear errores críticos en implementaciones de Canary.
En tiempos tranquilos, se recopilaron alrededor de 40.000 métricas por segundo, pero su número podría aumentar a 180.000 en ausencia de problemas.
Algunas consultas específicas para métricas de cardinalidad alta hicieron que Prometheus (como era de esperar) se quedara sin memoria, una situación muy frustrante cuando se usa Prometheus para alertar y evaluar implementaciones de canary.
Otro problema fue que con tres meses de datos almacenados en cada instancia de Prometheus, el tiempo de inicio (reproducción de WAL) era muy alto, y esto generalmente daría como resultado que la misma solicitud se enrutara a una segunda instancia de Prometheus y " ya lo dejó.
Para solucionar estos problemas, hemos implementado Thanos y Trickster:
- Thanos permitió que se almacenaran menos datos en Prometheus y redujo la cantidad de incidentes causados por el uso excesivo de memoria. Junto al contenedor, Prometheus Thanos ejecuta un contenedor sidecar que almacena bloques de datos en S3, donde luego son comprimidos por thanos-compact. Por lo tanto, con la ayuda de Thanos, se implementó el almacenamiento de datos a largo plazo fuera de Prometheus.
- Trickster, por su parte, actúa como proxy inverso y caché para las bases de datos de series temporales. Nos permitió almacenar en caché hasta el 99,53% de todas las solicitudes. La mayoría de las solicitudes provienen de paneles que se ejecutan en estaciones de trabajo / televisores, de usuarios con paneles de control abiertos y de alertas. Un proxy capaz de mostrar solo delta en series de tiempo es ideal para este tipo de carga de trabajo.
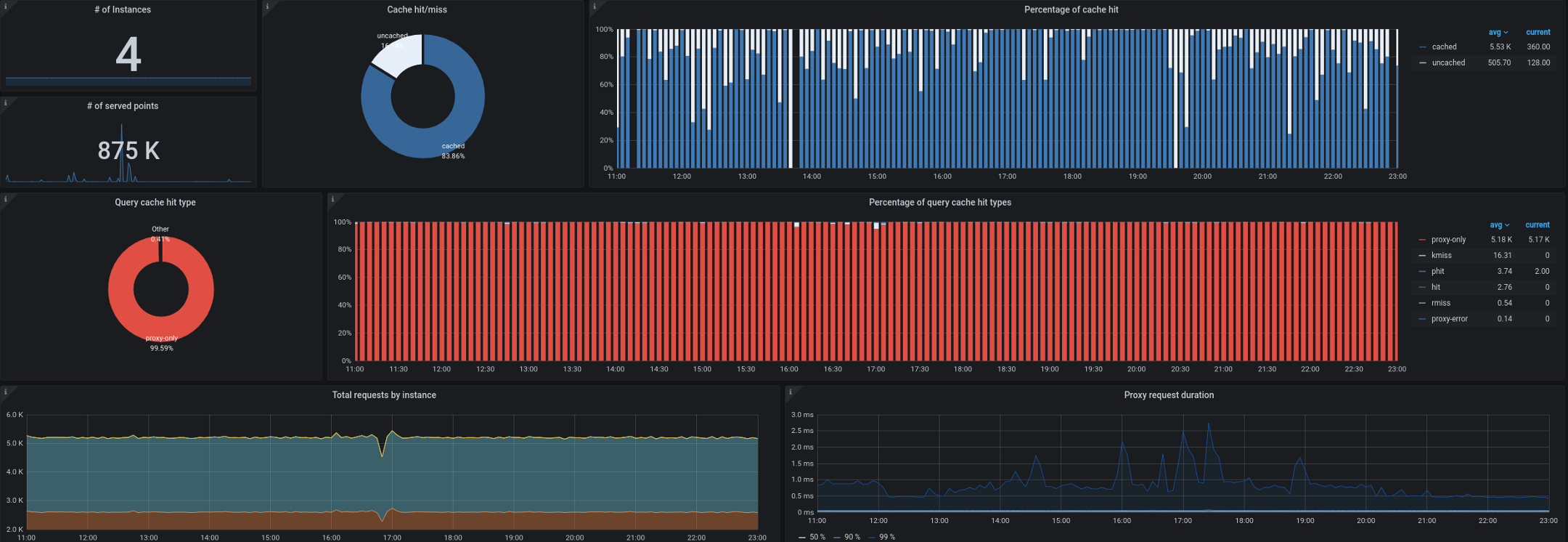
También comenzamos a tener problemas para recopilar métricas de estado de kube desde fuera del clúster. Como recordará, a menudo teníamos que procesar hasta 180.000 métricas por segundo, y la recopilación se ralentizó incluso cuando se establecieron 40.000 métricas en una única métrica kube-state-metrics de entrada. Tenemos un intervalo objetivo de 10 segundos para recopilar métricas, y durante períodos de alta carga, este SLA a menudo se violaba mediante la recopilación remota de métricas de kube-state o kube-eagle.
Opciones
Mientras pensábamos en cómo mejorar la arquitectura, analizamos tres opciones diferentes:
- Prometheus + Cortex ( https://github.com/cortexproject/cortex );
- Prometheus + Thanos Receive ( https://thanos.io );
- Prometheus + VictoriaMetrics ( https://github.com/VictoriaMetrics/VictoriaMetrics ).
En Internet se puede encontrar información detallada sobre ellos y comparación de características. En nuestro caso particular (y después de las pruebas con datos con alta cardinalidad) VictoriaMetrics fue el claro ganador.
Decisión
Prometeo
En un esfuerzo por mejorar la arquitectura descrita anteriormente, decidimos aislar cada clúster de Kubernetes como una entidad separada y hacer que Prometheus forme parte de él. Ahora, cualquier clúster nuevo viene con monitoreo incluido "listo para usar" y métricas disponibles en cuadros de mando globales (Grafana). Para ello, los servicios kube-eagle, kube-state-metrics y Prometheus se han integrado en los clústeres de Kubernetes. Luego, Prometheus se configuró con etiquetas externas para identificar el clúster y se
remote_writeseñaló inserten VictoriaMetrics (ver más abajo).
VictoriaMetrics
VictoriaMetrics Time Series Database implementa los protocolos Graphite, Prometheus, OpenTSDB e Influx. No solo es compatible con PromQL, sino que también le agrega nuevas funciones y plantillas, evitando la refactorización de las consultas de Grafana. Además, su rendimiento es asombroso.
Implementamos VictoriaMetrics en modo de clúster y lo dividimos en tres componentes separados:
1. Almacenamiento VictoriaMetrics (vmstorage)
Este componente es responsable de almacenar los datos importados
vminsert. Nos limitamos a tres réplicas de este componente, combinadas en un StatefulSet Kubernetes.
./vmstorage-prod \
-retentionPeriod 3 \
-storageDataPath /data \
-http.shutdownDelay 30s \
-dedup.minScrapeInterval 10s \
-http.maxGracefulShutdownDuration 30s
Inserción de VictoriaMetrics (vminsert)
Este componente recibe datos de implementaciones con Prometheus y los reenvía a
vmstorage. El parámetro replicationFactor=2replica los datos en dos de los tres servidores. Por lo tanto, si una de las instancias vmstorageexperimenta problemas o se reinicia, todavía hay una copia disponible de los datos.
./vminsert-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-replicationFactor=2
VictoriaMetrics select (vmselect)
Acepta solicitudes PromQL de Grafana (Trickster) y solicita datos sin procesar de
vmstorage. Actualmente, hemos deshabilitado cache ( search.disableCache), ya que la arquitectura contiene Trickster, que es responsable del almacenamiento en caché; por lo tanto, vmselectsiempre debe obtener los datos completos más recientes.
/vmselect-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-dedup.minScrapeInterval=10s \
-search.disableCache \
-search.maxQueryDuration 30s
El panorama
La implementación actual tiene este aspecto:
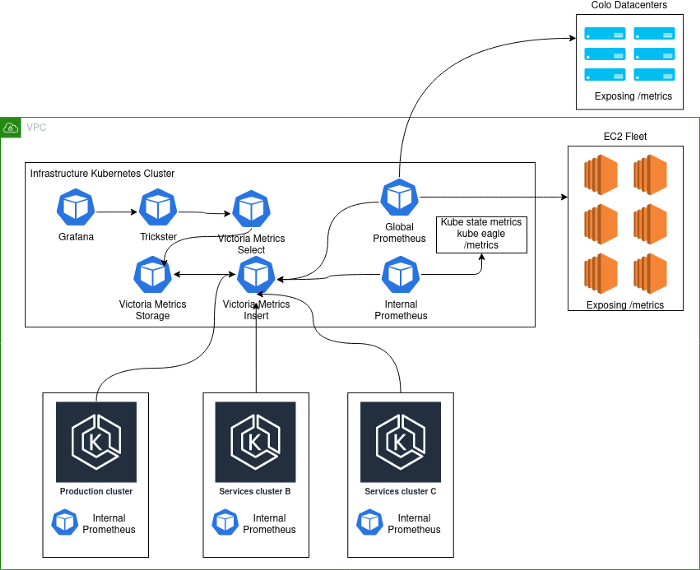
Notas de esquema:
- Production- . , K8s . - , . .
- deployment K8s Prometheus', VictoriaMetrics insert Kubernetes.
- Kubernetes deployment' Prometheus, . , , Kubernetes , . Global Prometheus EC2, colocation- -Kubernetes-.
A continuación se muestran las métricas que actualmente está procesando VictoriaMetrics (totales de dos semanas, los gráficos muestran una brecha de dos días): La nueva arquitectura funcionó bien después de ser transferida a producción. En la configuración anterior, teníamos dos o tres "explosiones" de cardinalidad cada dos semanas, en la nueva su número se redujo a cero. Este es un gran indicador, pero hay algunas cosas más que planeamos mejorar en los próximos meses:
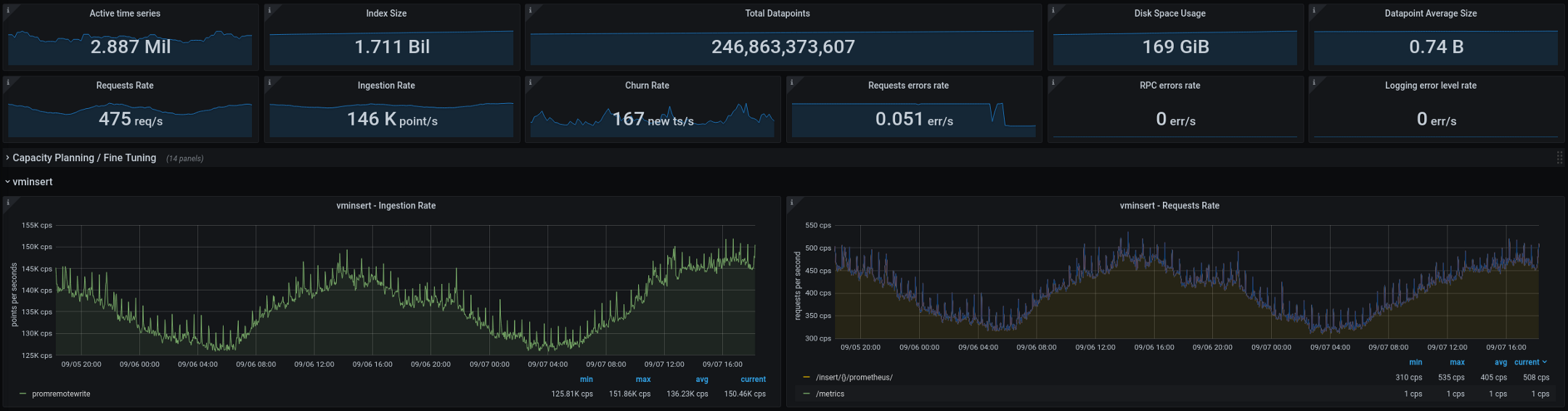
- Reduzca la cardinalidad de las métricas mejorando la integración de estadísticas.
- Compare el almacenamiento en caché en Trickster y VictoriaMetrics: debe evaluar el impacto de cada solución en la eficiencia y el rendimiento. Existe la sospecha de que Trickster puede abandonarse por completo sin perder nada.
- Prometheus stateless- — stateful, . , StatefulSet', ( pod disruption budgets).
-
vmagent— VictoriaMetrics Prometheus- exporter'. , Prometheus , .vmagentPrometheus ( !).
Si tiene alguna sugerencia o idea para las mejoras descritas anteriormente, comuníquese con nosotros . Si está trabajando para mejorar la supervisión de Kubernetes, esperamos que este artículo, que describe nuestro difícil viaje, haya sido útil.
PD del traductor
Lea también en nuestro blog:
- " El futuro de Prometheus y el ecosistema del proyecto (2020) ";
- " Monitoreo y Kubernetes " (informe de revisión y video);
- " El dispositivo y el mecanismo del operador Prometheus en Kubernetes ".