Uno de estos aspectos secundarios del desarrollo de software es la concesión de licencias de código. Para algunos desarrolladores, la concesión de licencias parece ser un bosque algo oscuro, intentan no meterse en él y no entienden las diferencias y las reglas de licencia en general, o las conocen de manera bastante superficial, por lo que pueden cometer varios tipos de violaciones. La violación más frecuente es la copia (reutilización) y la modificación del código en violación de los derechos de su autor.
Cualquier ayuda para las personas comienza con la investigación de la situación actual: en primer lugar, la recopilación de datos es necesaria para la posibilidad de una mayor automatización y, en segundo lugar, su análisis nos permitirá descubrir qué es exactamente lo que la gente está haciendo mal. En este artículo, describiré un estudio de este tipo: le presentaré los principales tipos de licencias de software (así como algunas raras pero notables), hablaré sobre el análisis de código y la búsqueda de préstamos en una gran cantidad de datos, y daré consejos sobre cómo manejar correctamente las licencias en el código. y evitar errores comunes.
Introducción a las licencias de código
En Internet, e incluso en Habré , ya existen descripciones detalladas de las licencias, por lo que nos limitaremos a una breve descripción del tema necesaria para comprender la esencia del estudio.
Solo hablaremos de licencias de software de código abierto. En primer lugar, esto se debe al hecho de que es en este paradigma donde podemos encontrar fácilmente una gran cantidad de datos disponibles, y en segundo lugar, el mismo término "software de código abierto"puede ser engañoso. Cuando descarga e instala un programa propietario común del sitio web de la empresa, se le solicita que acepte los términos de la licencia. Por supuesto, normalmente no los lee, pero en general comprende que se trata de propiedad intelectual de alguien. Al mismo tiempo, cuando los desarrolladores ingresan a un proyecto en GitHub y ven todos los archivos fuente, la actitud hacia ellos es completamente diferente: sí, hay algún tipo de licencia allí, pero es de código abierto , y el software es de código abierto , lo que significa que puede tomar y haz lo que quieras, verdad? Desafortunadamente, no todo es tan sencillo.
¿Cómo funcionan las licencias? Comencemos con la división de derechos más general:
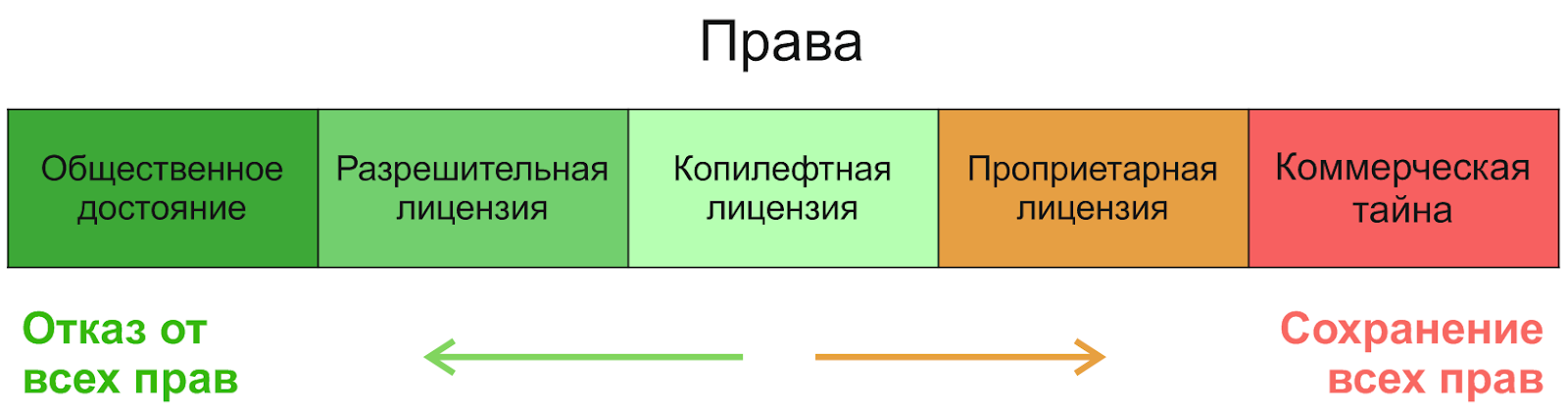
Si va de derecha a izquierda, entonces el primero será un secreto comercial, seguido de licencias propietarias; no las consideraremos. En el campo del software de código abierto se pueden distinguir tres categorías (según el grado de incremento de las libertades): licencias restrictivas ( copyleft ), licencias no restrictivas ( permisivas , permisivas) y el dominio público.(que no es una licencia, sino una forma de otorgar derechos). Para comprender la diferencia entre ellos, es útil saber por qué aparecieron. El concepto de dominio público es tan antiguo como el mundo: el creador rechaza completamente cualquier derecho y le permite hacer lo que quiera con su producto. Sin embargo, curiosamente, de esta libertad nace la falta de libertad; después de todo, otra persona puede tomar tal creación, cambiarla ligeramente y hacer “cualquier cosa” con ella, incluso cerrarla y venderla. Las licencias de código abierto copyleft se crearon precisamente para proteger la libertad; desde su posición en la imagen se puede ver que están destinadas a mantener un equilibrio: permitir el uso, cambio y distribución del producto, pero no bloquearlo, dejarlo libre. Además, incluso si al escritor no le importa el escenario de cerrar y vender,los conceptos de dominio público difieren de un país a otro y, por lo tanto, pueden crear complicaciones legales. Para evitarlos, se utilizan licencias permisivas simples.
Entonces, ¿cuál es la diferencia entre licencias permisivas y copyleft? Como todo lo demás en nuestro tema, esta pregunta es bastante específica y hay excepciones, pero si simplifica, las licencias permisivas no imponen restricciones a la licencia del producto modificado. Es decir, puede tomar un producto de este tipo, cambiarlo y ponerlo en un proyecto con una licencia diferente, incluso propietaria. La principal diferencia con el dominio público aquí es, con mayor frecuencia, la obligación de preservar la autoría y la mención del autor original. Las licencias permisivas más famosas son las licencias MIT, BSD y Apache .... Muchos estudios apuntan al MIT como la licencia de código abierto más utilizada en general, y también señalan el crecimiento significativo en popularidad de la licencia Apache-2.0 desde su inicio en 2004 (por ejemplo, el estudio para Java ).
Las licencias copyleft imponen con mayor frecuencia restricciones a la distribución y modificación de subproductos: obtiene un producto con ciertos derechos y debe "ejecutarlo más", otorgando a todos los usuarios los mismos derechos. Esto generalmente significa la obligación de redistribuir el software bajo la misma licencia y brindar acceso al código fuente. Basado en esta filosofía, Richard Stallman creó la primera y más popular licencia copyleft, la GNU General Public License (GPL). Es ella quien brinda la máxima protección de libertad para futuros usuarios y desarrolladores. Recomiendo leer la historia del movimiento Richard Stallman por el software libre, es muy interesante.
Existe una dificultad con las licencias copyleft: tradicionalmente se dividen en copyleft fuerte y débil . Un copyleft fuerte es exactamente lo que se describe arriba, mientras que un copyleft débil proporciona varias concesiones y excepciones para los desarrolladores. El ejemplo más famoso de dicha licencia es la GNU Lesser General Public License (LGPL): al igual que su versión anterior, le permite cambiar y redistribuir el código solo si mantiene esta licencia, pero cuando se vincula dinámicamente (usándolo como una biblioteca en una aplicación), este requisito puede omitirse. En otras palabras, si desea tomar prestado el código fuente de aquí o cambiar algo, observe el copyleft, pero si solo desea usarlo como una biblioteca de enlaces dinámicos, puede hacerlo en cualquier lugar.
Ahora que hemos averiguado las licencias en sí, deberíamos hablar de su compatibilidad , porque es en él (o más bien, en su ausencia) donde se encuentran las infracciones que queremos evitar. Cualquiera que alguna vez se haya interesado en este tema debería haberse encontrado con esquemas de compatibilidad de licencias como este:

De un vistazo a este esquema, cualquier deseo de comprender las licencias puede desaparecer. De hecho, hay muchas licencias de código abierto ; por ejemplo, aquí se puede encontrar una lista bastante exhaustiva . Al mismo tiempo, como verás a continuación en los resultados de nuestro estudio, necesitas conocer una cantidad muy limitada (debido a su distribución extremadamente desigual), y aún menos reglas que deban recordarse para cumplir con todas sus condiciones. El vector general de este esquema es bastante simple: en la fuente de todo está el dominio público, detrás de él hay licencias permisivas, luego un copyleft débil y, finalmente, un copyleft fuerte, y las licencias son compatibles "derecho": en un proyecto copyleft, puede reutilizar el código bajo una licencia permisiva, pero no al revés - todo es lógico.
Aquí puede surgir la pregunta: ¿y si el código no tiene licencia? ¿Qué reglas seguir entonces? ¿Se puede copiar este código? En realidad, esta es una pregunta muy importante. Probablemente, si el código está escrito en una cerca, entonces puede considerarse de dominio público, y si está escrito en papel en una botella, que fue clavada en una isla desierta (sin derechos de autor), entonces simplemente se puede tomar y usar. Cuando se trata de plataformas grandes y establecidas como GitHub o StackOverflow, las cosas no son tan simples, porque con solo usarlas, automáticamente acepta sus términos de uso. Por ahora, dejemos una nota al respecto en nuestra cabeza y volvamos a ella más tarde. Al final, ¿tal vez esto sea una rareza y prácticamente no hay código sin una licencia?
Enunciado del problema y metodología
Entonces, ahora que conocemos el significado de todos los términos, aclaremos lo que queremos saber.
- ¿Qué tan común es la copia de código en software de código abierto? ¿Hay muchos clones en el código entre los proyectos de código abierto ?
- ¿Qué licencias hay bajo? ¿Cuáles son las licencias más comunes? ¿El archivo contiene varias licencias a la vez?
- ¿Cuáles son los préstamos posibles más comunes, es decir, transiciones de código de una licencia a otra?
- ¿Cuáles son las posibles violaciones más comunes, es decir, transiciones de código prohibidas por los términos de la licencia original o receptora?
- ¿Cuál es el posible origen de fragmentos de código individuales? ¿Cuál es la probabilidad de que este fragmento de código se haya copiado en violación?
Para realizar tal análisis, necesitamos:
- Recopile un conjunto de datos de una gran cantidad de proyectos de código abierto.
- Encuentra clones de fragmentos de código entre ellos.
- Identifique los clones que realmente se pueden tomar prestados.
- Para cada fragmento de código, determine dos parámetros: su licencia y la hora de su última modificación, que es necesaria para averiguar qué fragmento en un par de clones es más antiguo y cuál es más joven y, por lo tanto, quién podría potencialmente copiar de quién.
- Determine qué posibles transiciones entre licencias están permitidas y cuáles no.
- Analizar todos los datos obtenidos para dar respuesta a las preguntas anteriores.
Ahora echemos un vistazo más de cerca a cada paso.
Recopilación de datos
Es muy conveniente para nosotros que hoy en día sea fácil acceder a una gran cantidad de código abierto usando GitHub. Contiene no solo el código en sí, sino también el historial de sus cambios, lo cual es muy importante para este estudio: para saber quién podría copiar el código de quién, es necesario saber cuándo se agregó cada fragmento al proyecto.
Para recopilar datos, debe decidir el lenguaje de programación estudiado. El hecho es que los clones se buscan dentro del marco de un lenguaje de programación: hablando de una infracción de licencia, es más difícil evaluar la reescritura de un algoritmo existente en otro lenguaje. Conceptos tan complejos están protegidos por patentes, mientras que en nuestra investigación estamos hablando de copias y modificaciones más típicas. Elegimos Java porque es uno de los lenguajes más utilizados y es particularmente popular en el desarrollo de software comercial, en cuyo caso las posibles violaciones de licencias son especialmente importantes.
Como base, tomamos el Archivo Público de Git existente, que a principios de 2018 reunía todos los proyectos en GitHub que tenían más de 50 estrellas. Hemos seleccionado todos los proyectos que tienen al menos una línea en Java y los hemos descargado con un historial completo de cambios. Después de filtrar los proyectos que se han movido o que ya no están disponibles, hay 23.378 proyectos que ocupan aproximadamente 1,25 TB de espacio en el disco duro.
Además, para cada proyecto, descargamos la lista de bifurcaciones y encontramos pares de bifurcaciones dentro de nuestro conjunto de datos; esto es necesario para un mayor filtrado, ya que no estamos interesados en clones entre bifurcaciones. Había 324 proyectos en total con bifurcaciones dentro del conjunto de datos.
Encontrar clones
Para encontrar clones, es decir, piezas de código similares, también es necesario tomar algunas decisiones. Primero, debemos decidir cuánto y en qué capacidad estamos interesados en un código similar. Tradicionalmente, existen 4 tipos de clones (del más preciso al menos preciso):
- Los clones idénticos son exactamente los mismos fragmentos de código que solo pueden diferir en decisiones estilísticas, como sangrías, líneas en blanco y comentarios.
- Los clones renombrados incluyen el primer tipo, pero además pueden diferir en los nombres de variable y objeto.
- Los clones cercanos incluyen todo lo anterior, pero pueden contener cambios más significativos, como agregar, eliminar o mover expresiones, en las que los fragmentos siguen siendo similares.
- , — , ( ), ().
Estamos interesados en copiar y modificar, por lo que solo consideramos clones de los tres primeros tipos.
La segunda decisión importante es qué tamaño de clones buscar. Se pueden buscar fragmentos de código idénticos entre archivos, clases, métodos, expresiones individuales ... En nuestro trabajo, tomamos el método como base , ya que esta es la granularidad de búsqueda más equilibrada: a menudo la gente copia el código no en archivos completos, sino en pequeños fragmentos, pero al mismo tiempo el método - sigue siendo una unidad lógica completa.
Basándonos en las soluciones seleccionadas, para encontrar clones, utilizamos SourcererCC , una herramienta que busca clones utilizando el método de la bolsa de palabras.: cada método se representa como una lista de frecuencia de tokens (palabras clave, nombres y literales), después de lo cual dichos conjuntos se comparan, y si más de una cierta proporción de tokens en dos métodos coinciden (esta proporción se llama umbral de similitud), entonces dicho par se considera un clon. A pesar de la sencillez de este método (existen métodos mucho más complejos basados en el análisis de árboles sintácticos de métodos e incluso sus gráficos de dependencia de programas), su principal ventaja es la escalabilidad : con una cantidad de código tan enorme, como el nuestro, es importante que la búsqueda de clones se realice de forma muy rápida ...
Usamos diferentes umbrales de similitud para encontrar diferentes clones y también realizamos una búsqueda por separado con un umbral de similitud del 100%, en la que solo se identificaron clones idénticos. Además, se estableció un tamaño mínimo de método investigado para descartar fragmentos de código triviales y genéricos que podrían no ser prestados.
Esta búsqueda tomó hasta 66 días de cálculos continuos, se identificaron 38,6 millones de métodos, de los cuales solo 11,7 millones pasaron el umbral de tamaño mínimo y de los cuales 7,6 millones participaron en la clonación. Se encontraron un total de 1.200 millones de pares de clones.
Hora de la última modificación
Para un análisis más detallado, seleccionamos solo pares de clones entre proyectos , es decir, pares de fragmentos de código similares que se encuentran en diferentes proyectos. Desde el punto de vista de las licencias, no nos interesan mucho los fragmentos de código dentro del mismo proyecto: se considera una mala práctica repetir su propio código, pero no está prohibido. En total, hubo aproximadamente 561 millones de pares entre proyectos, es decir, aproximadamente la mitad de todos los pares. Estos pares incluyeron 3,8 millones de métodos, para lo cual fue necesario determinar el momento de la última modificación. Para ello, se aplicó el comando git blame a cada archivo (que resultó ser 898 mil, porque puede haber más de un método en los archivos) , lo que da la hora de la última modificación para cada línea del archivo.
Entonces, tenemos el tiempo de última modificación para cada línea en el método, pero ¿cómo determinamos el tiempo de última modificación de todo el método? Esto parece ser obvio: toma la hora más reciente y úsala: después de todo, realmente muestra cuándo se cambió el método por última vez. Sin embargo, para nuestra tarea, tal definición no es ideal. Consideremos un ejemplo:
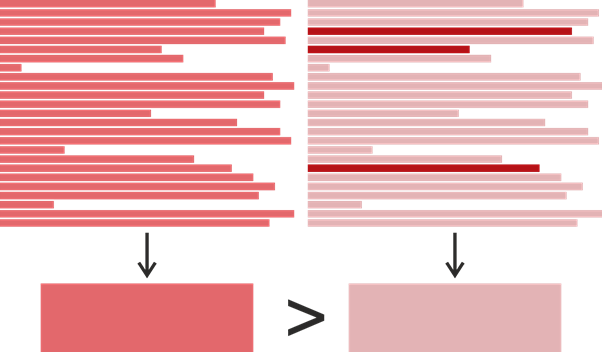
Supongamos que encontramos un clon en forma de un par de fragmentos, cada uno con 25 líneas. Un color más saturado aquí significa un tiempo de modificación posterior. Digamos que el fragmento de la izquierda se escribió en un momento en 2017, y en el fragmento de la derecha se escribieron 22 líneas en 2015, y tres se modificaron en 2019. Resulta que el fragmento de la derecha se modificó más tarde, pero si quisiéramos determinar quién podía copiar de quién, Sería más lógico suponer lo contrario: el fragmento de la izquierda tomó prestado el de la derecha y el de la derecha cambió ligeramente más tarde. En base a esto, definimos el momento de la última modificación de un fragmento de código como el momento más frecuente de la última modificación de sus líneas individuales. Si de repente hubo varias de esas ocasiones, se eligió una posterior.
Curiosamente, el fragmento de código más antiguo de nuestro conjunto de datos se escribió en abril de 1997, en los albores de Java, ¡y encontró un clon creado en 2019!
Definición de licencias
El segundo y más importante paso es determinar la licencia para cada fragmento. Para ello, utilizamos el siguiente esquema. Para empezar, utilizando la herramienta Ninka , se determinó la licencia especificada directamente en el encabezado del archivo. Si hay una, entonces se considera una licencia para cada método en ella (Ninka puede reconocer varias licencias al mismo tiempo). Si no se especifica nada en el archivo o no hay información suficiente (por ejemplo, solo derechos de autor), entonces se utilizó la licencia de todo el proyecto al que pertenece el archivo. Los datos al respecto estaban contenidos en el Archivo Público de Git original, sobre cuya base recopilamos el conjunto de datos, y se determinaron utilizando otra herramienta: Go License Detector . Si la licencia no está en el archivo o en el proyecto, dichos métodos se marcaron comoGitHub , ya que luego están sujetos a los Términos de servicio de GitHub (que es donde se descargaron todos nuestros datos).
Habiendo definido todas las licencias de esta manera, finalmente podemos responder a la pregunta de qué licencias son las más populares. Encontramos 94 licencias diferentes en total . Proporcionaremos estadísticas para los archivos aquí para compensar posibles problemas debido a archivos muy grandes con muchos métodos.
La característica principal de este programa es la distribución desigual más fuerte de licencias. En el gráfico se pueden ver tres áreas: dos “licencias” con más de 100 mil archivos, otras diez con 10-100 mil archivos y una larga cola de licencias con menos de 10 mil archivos.
Consideremos primero las más populares, para las cuales presentamos las dos primeras áreas en una escala lineal:
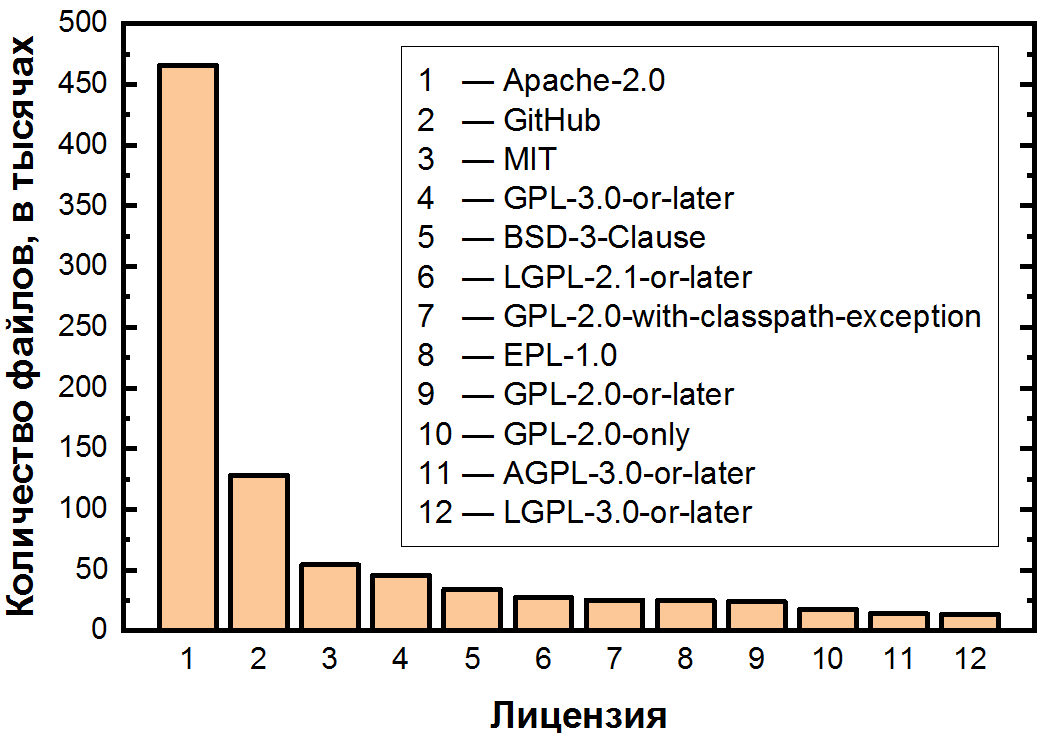
Se pueden ver desniveles incluso entre las licencias más populares. Apache-2.0 está en primer lugar por un gran margen: la más equilibrada de todas las licencias permisivas, cubre poco más de la mitad de todos los archivos.
Le sigue la notoria falta de licencia, y todavía tenemos que analizarla con más detalle, ya que esta situación es tan común incluso entre repositorios medianos y grandes (más de 50 estrellas). Esta circunstancia es muy importante, ya que con solo subir el código a GitHub no se abre.- y si hay algo práctico y necesitas recordar de este artículo, entonces es esto. Al cargar su código en GitHub, acepta los términos de uso, que establecen que su código se puede ver y bifurcar. Sin embargo, con la excepción de esto, todos los derechos sobre el código permanecen con el autor, por lo tanto, la distribución, modificación e incluso el uso requieren permiso explícito. Resulta que no solo no todo el código abierto es completamente gratuito, ¡ni siquiera todo el código en GitHub es completamente de código abierto! Y dado que existe una gran cantidad de código de este tipo (14% de los archivos, y entre los proyectos menos populares que no están incluidos en el conjunto de datos, probablemente incluso más), esto puede ser la causa de una cantidad significativa de violaciones.
Entre los cinco primeros, también vemos las licencias permisivas ya mencionadas de MIT y BSD, así como copyleft GPL-3.0-o posterior. Las licencias de la familia GPL difieren no solo en un número significativo de versiones (no tan malas), sino también en la posdata "o posterior", que permite al usuario utilizar los términos de esta licencia o sus versiones posteriores. Esto lleva a otra pregunta: entre estas 94 licencias, hay "familias" claramente similares, ¿cuáles de ellas son las más grandes?
En tercer lugar están las licencias GPL: hay 8 tipos de ellas en la lista. Esta familia es la más significativa, porque juntas cubren el 12,6% de los archivos, solo superada por Apache-2.0 y la falta de licencia. En segundo lugar, inesperadamente, BSD. Además de la versión tradicional de 3 párrafos e incluso las versiones de 2 y 4 párrafos, hay muylicencias específicas - solo 11 piezas. Estos incluyen, por ejemplo, BSD 3-Clause No Nuclear License , que es un BSD regular con 3 cláusulas, a la que se indica a continuación que este software no debe usarse para crear u operar nada nuclear:
Usted reconoce que este software no está diseñado, autorizado o destinado a ser utilizado en el diseño, construcción, operación o mantenimiento de cualquier instalación nuclear.
La más diversa es la familia de licencias Creative Commons, sobre la que puede leer aquí . Hubo hasta 13 de ellos, y también vale la pena revisarlos al menos por una razón importante: todo el código en StackOverflow tiene licencia CC-BY-SA.
Entre las licencias más raras, hay algunas notables, por ejemplo,Haga lo que el F * ck que desee con la licencia pública (WTFPL) , que cubre 529 archivos y le permite hacer exactamente lo que dice el nombre con el código. También existe, por ejemplo, la Beerware License , que también le permite hacer cualquier cosa y alienta al autor a comprar una cerveza al reunirse. En nuestro conjunto de datos, también encontramos una variación de esta licencia, que no hemos encontrado en ningún otro lugar: la Licencia Sushiware . En consecuencia, anima al autor a comprar sushi.
Otra situación curiosa es cuando se encuentran varias licencias en un archivo (es decir, en el archivo). En nuestro conjunto de datos, solo hay un 0,9% de dichos archivos. 7,4 mil archivos están cubiertos por dos licencias a la vez, y se encontraron un total de 74 pares diferentes de dichas licencias. 419 archivos están cubiertos por hasta tres licencias, y hay 8 de esos tripletes. Y, finalmente,un archivo de nuestro conjunto de datos menciona cuatro licencias diferentes en el encabezado.
Posibles préstamos
Ahora que hemos hablado de licencias, podemos discutir la relación entre ellas. Lo primero que debe hacer es eliminar los clones que no sean posibles préstamos . Permítanme recordarles que en este momento intentamos tener esto en cuenta de dos maneras: el tamaño mínimo de los fragmentos de código y la exclusión de clones dentro de un proyecto. Ahora filtraremos tres tipos más de pares:
- No nos interesan los pares entre la bifurcación y el original (así como, por ejemplo, entre dos bifurcaciones del mismo proyecto), para ello los recopilamos.
- Tampoco estamos interesados en clones entre diferentes proyectos pertenecientes a la misma organización o usuario (ya que asumimos que los derechos de autor se comparten dentro de la misma organización).
- Finalmente, al verificar manualmente una cantidad anormalmente grande de clones entre dos proyectos, encontramos espejos significativos (también son bifurcaciones indirectas), es decir, proyectos idénticos cargados en repositorios no relacionados.
Curiosamente, hasta el 11,7% de los pares restantes son clones idénticos con un umbral de similitud del 100%; tal vez intuitivamente parece que debería haber menos código absolutamente idéntico en GitHub.
Procesamos todos los pares restantes después de este filtrado de la siguiente manera:
- Comparamos el tiempo de la última modificación de dos métodos en un par.
- , : .
- , «» «» . , 2015 MIT, 2018 — Apache-2.0, MIT → Apache-2.0.
Al final, resumimos el número de pares para cada préstamo potencial y los clasificamos en orden descendente:
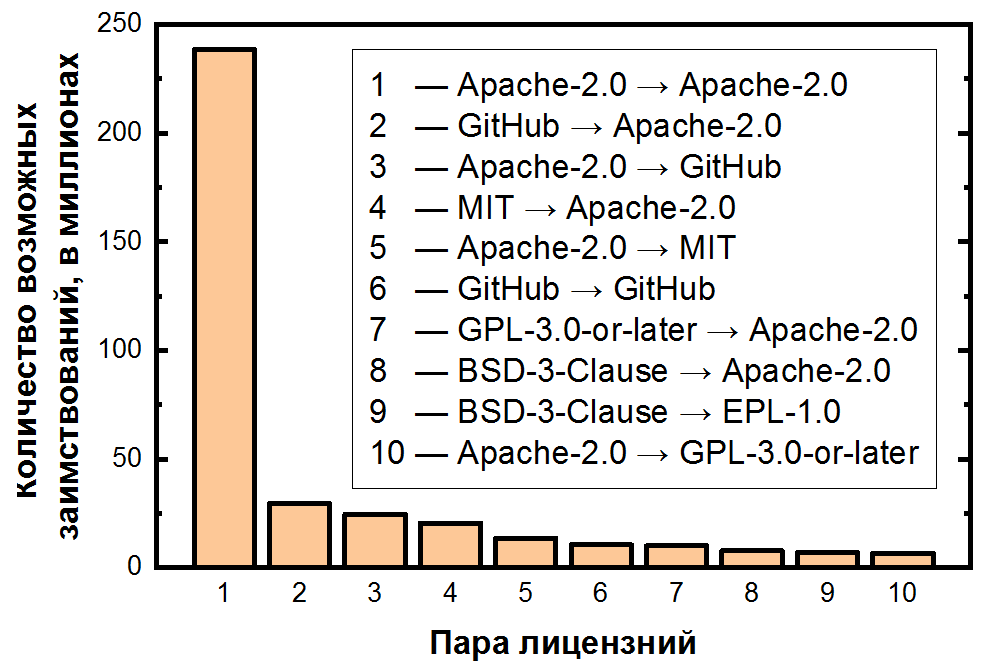
Aquí la dependencia es aún más extrema: el posible préstamo de código dentro de Apache-2.0 representa más de la mitad de todos los pares de clones, y los primeros 10 pares de licencias ya cubren más del 80% de los clones. También es importante tener en cuenta que el segundo y tercer par más frecuentes tratan con archivos sin licencia, lo que también es una clara consecuencia de su frecuencia. Para las cinco licencias más populares, puede mostrar las transiciones como un mapa de calor:
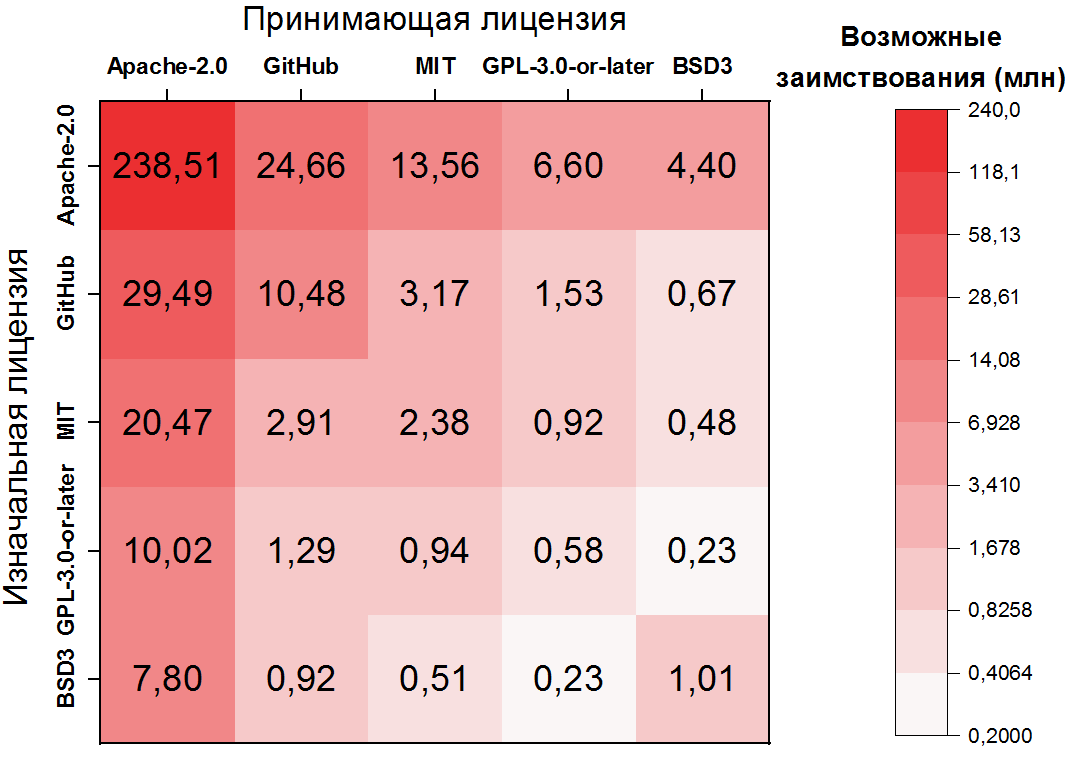
Posibles violaciones de licencias
El siguiente paso en nuestra investigación es identificar pares de clones que son posibles violaciones , es decir, préstamos que violan los términos de las licencias original y de host. Para hacer esto, debe marcar los pares de licencias mencionados anteriormente como transiciones permitidas o prohibidas . Entonces, por ejemplo, la transición más popular ( Apache-2.0 → Apache-2.0 ) está, por supuesto, permitida, pero la segunda ( GitHub → Apache-2.0 ) está prohibida. Pero hay muchísimos, hay miles de esos pares.
Para hacer frente a esto, recuerde que los primeros 10 pares de licencias renderizados cubren el 80% de todos los pares de clones. Debido a este desnivel, resultó suficiente marcar manualmente sólo 176 pares de licencias para cubrir el 99% de los pares de clones, lo que nos pareció una precisión bastante aceptable. Entre estas parejas, consideramos prohibidos cuatro tipos de parejas:
- Copia de archivos sin licencia (GitHub). Como ya se mencionó, dicha copia requiere el permiso directo del autor del código, y asumimos que en la gran mayoría de los casos no lo es.
- También está prohibido copiar a archivos sin una licencia, porque esto esencialmente es borrar, quitar licencias. Las licencias permisivas como Apache-2.0 o BSD permiten que el código se reutilice en otras licencias (incluidas las propietarias), pero incluso estas requieren que la licencia original se mantenga en el archivo.
- .
- (, Apache-2.0 → GPL-2.0).
Todos los demás pares raros de licencias que cubren el 1% de los clones se marcaron como permisivos (para no culpar a nadie innecesariamente), excepto aquellos en los que aparece código sin licencias (que nunca se puede copiar).
Como resultado, después del margen de beneficio, resultó que el 72,8% de los préstamos son préstamos permitidos y el 27,2% están prohibidos. Las siguientes tablas muestran los más violados y la mayoría violen licencias.

A la izquierda están las licencias más violadas, es decir, las fuentes de la mayor cantidad de posibles violaciones. Entre ellos, el primer lugar lo ocupan los archivos sin licencias, lo cual es una nota práctica importante: debe monitorear especialmente de cerca los archivos sin licencias.... Uno podría preguntarse qué hace la licencia permisiva de Apache-2.0 en esta lista. Sin embargo, como puede ver en el mapa de calor anterior, ~ 25 millones de préstamos prohibidos son préstamos a un archivo sin licencia, por lo que esto es una consecuencia de su popularidad.
A la derecha están las licencias que se copian con violaciones, y aquí la mayoría son las mismas Apache-2.0 y GitHub.
Origen de los métodos individuales
Finalmente, llegamos al último punto de nuestra investigación. Todo este tiempo hablamos de parejas de clones, como es habitual en este tipo de estudios. Sin embargo, uno debe comprender cierta parcialidad, incompletitud de tales juicios. El hecho es que si, por ejemplo, un fragmento de código tiene 20 hermanos "mayores" (o "padres", quién sabe), entonces los 20 pares se considerarán préstamos potenciales. Es por eso que estamos hablando de préstamos "potenciales" y "posibles"; es poco probable que el autor de un método en particular lo haya tomado prestado de 20 lugares diferentes. A pesar de esto, este razonamiento puede verse como un razonamiento sobre clones entre diferentes licencias.
Para evitar juicios tan incompletos, puede mirar la misma imagen desde un ángulo diferente. La imagen de clonación es en realidad un gráfico dirigido: todos los métodos son vértices en él, que están conectados por bordes dirigidos desde el más antiguo al más joven (si no tiene en cuenta los métodos fechados el mismo día). En las dos secciones anteriores, miramos este gráfico desde el punto de vista de los bordes: tomamos cada borde y estudiamos sus vértices (obteniendo esos mismos pares de licencias). Ahora veámoslo desde el punto de vista de los vértices. Cada vértice (método) en el gráfico tiene ancestros (clones "mayores") y descendientes (clones "menores"). Los vínculos entre ellos también se pueden dividir en "permitidos" y "prohibidos".
En base a esto, cada método se puede atribuir a una de las siguientes categorías, cuyos gráficos se muestran en la imagen (aquí las líneas continuas indican préstamos prohibidos y las líneas punteadas, permitidas):

Dos de las configuraciones presentadas pueden constituir una violación de las condiciones de licencia:
- Una violación grave significa que el método tiene ancestros y todas las transiciones de ellos están prohibidas. Esto significa que si el desarrollador realmente copió el código, lo hizo en violación de las licencias.
- Una violación débil significa que el método tiene antepasados, y solo algunos de ellos están detrás de transiciones prohibidas. Esto significa que el desarrollador puede haber copiado el código en violación de la licencia.
Otras configuraciones no son violaciones:
- , , .
- — , — , .
- , , — , . , , — , . : , , , , ( , , ).
Entonces, ¿cómo se distribuyen los métodos en nuestro conjunto de datos?

Puede ver que aproximadamente un tercio de los métodos no tienen clones en absoluto, y otro tercio tiene clones solo en proyectos vinculados. Por otro lado, el 5,4% de los métodos representan "infracción leve" y el 4% - "infracción grave". Aunque estos números pueden no parecer muy grandes, todavía hay cientos de miles de métodos en proyectos más o menos grandes.
TL; DR
Teniendo en cuenta que este artículo contiene una gran cantidad de figuras y gráficos empíricos, repitamos nuestros principales hallazgos:
- Hay millones de métodos que tienen clones y hay más de mil millones de pares entre ellos.
- , Java- 50 , 94 , : Apache-2.0 . Apache-2.0 .
- , 27,2%, .
- 35,4% , 5,4% «» , 4% «» .
?
En conclusión, me gustaría hablar sobre por qué se necesita todo lo anterior. Tengo al menos tres respuestas.
Primero, es interesante . La concesión de licencias es tan diversa como todos los demás aspectos de la programación. La lista de licencias en sí es bastante curiosa debido a la especificidad y rareza de algunas licencias, la gente escribe y trabaja con ellas de diferentes maneras. Sin duda, esto también se aplica a los clones en el código y la similitud del código en general. Hay métodos con miles de clones, y hay métodos sin uno solo, mientras que de un vistazo no siempre es fácil notar la diferencia fundamental entre ellos.
En segundo lugar, un análisis detallado de nuestros hallazgos nos permite formular varios consejos prácticos :
- - . Apache-2.0, MIT, BSD-3-Clause, GPL LGPL.
- : . - , , .
- GitHub, . . — , . : - , , , , . , .
Para obtener descripciones claras de las licencias, así como consejos sobre cómo elegir una licencia para su nuevo proyecto, puede recurrir a servicios como tldrlegal o choosealicense .
Finalmente, los datos obtenidos se pueden utilizar para crear herramientas . En este momento, nuestros colegas están desarrollando una forma de determinar rápidamente las licencias utilizando métodos de aprendizaje automático (para los cuales solo necesita muchas licencias específicas) y un complemento IDE que permitirá a los desarrolladores rastrear las dependencias en sus proyectos y notar posibles incompatibilidades con anticipación.
Con suerte, ha aprendido algo nuevo de este artículo. El cumplimiento de los términos básicos de la licencia no es tan engorroso y puede hacer todo de acuerdo con las reglas con un mínimo de esfuerzo. ¡Eduquemos juntos, eduquemos a otros y acerquémonos al sueño del software de código abierto "correcto"!