
Por ejemplo, tiene una biblioteca de documentos de SharePoint. Cuando agrega un archivo a esta biblioteca, a menudo también proporciona al archivo ciertos metadatos. Cree varios campos y escriba alguna información en ellos para clasificar los archivos que se encuentran en esta biblioteca. Pero esto se hace manualmente y para cada archivo debe ingresar datos una y otra vez. SharePoint Syntex está diseñado para automatizar este proceso extrayendo datos clave de un archivo de acuerdo con un modelo personalizado y guardando estos datos en los campos de la biblioteca. Eso suena bien. ¿Vamos a ver cómo funciona?
¿Cómo activo SharePoint Syntex?
Dado que SharePoint Syntex viene bajo una licencia separada, necesitamos obtener esta licencia. Vaya al sitio web de Microsoft, busque el producto SharePoint Syntex y haga clic en "Prueba gratuita".

Después de ingresar a su cuenta de Microsoft 365 y confirmar la activación de la licencia de prueba, vaya al centro de administración de Microsoft 365. A continuación, vaya a la sección "Configuración" en el menú de la izquierda y seleccione el elemento Automatizar la comprensión del contenido. En el caso de la configuración regional rusa, como la mía, sonará como "Automatización de comprensión de contenido".
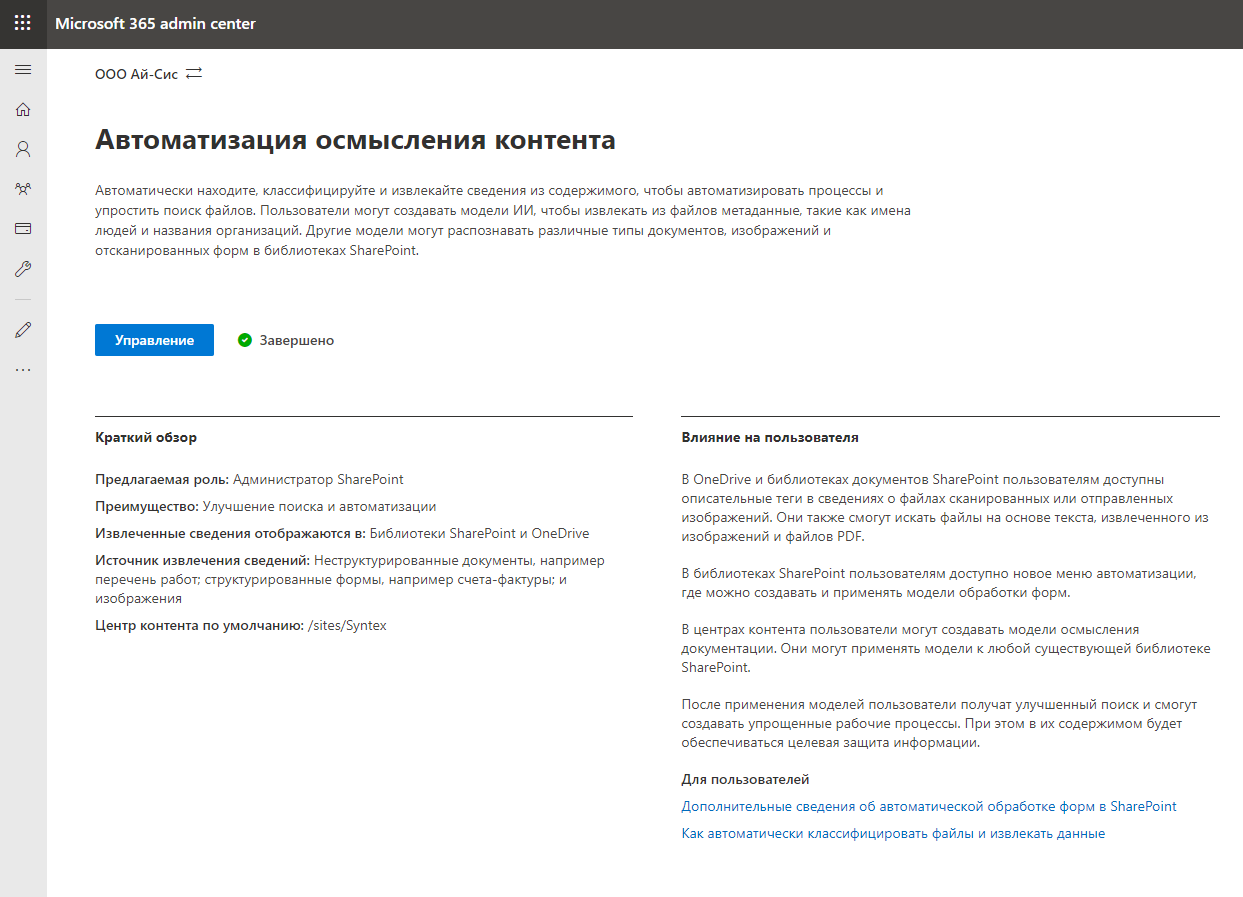
Pasamos a "Gestión" y procedemos a configurar el servicio. En primer lugar, es necesario indicar qué bibliotecas admitirán las capacidades de SharePoint Syntex. Puede seleccionar bibliotecas específicas o permitir todas las bibliotecas. Vamos a por todas.
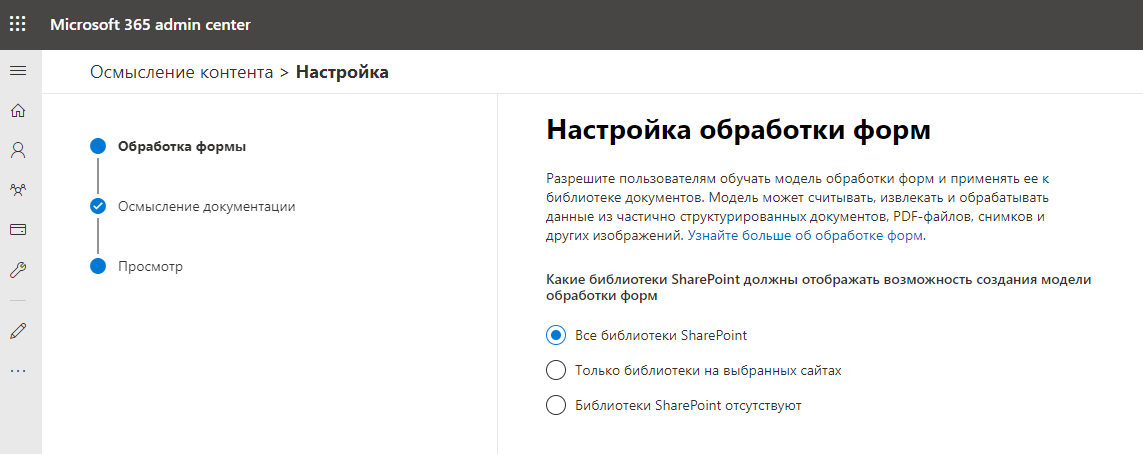
A continuación, indicamos el nombre y la dirección del sitio, que será el centro de contenido y almacenará los modelos de datos entrenados. Parece que se está creando un nuevo sitio de colección de SharePoint Online. Sin embargo, esto es exactamente lo que está sucediendo.
Se necesitan unos minutos para crear un sitio del centro de contenido. Me tomó unos 5 minutos, solo logré servirme un poco de té. Vengo, y aquí ya está activada la comprensión del contenido, bueno, guau.
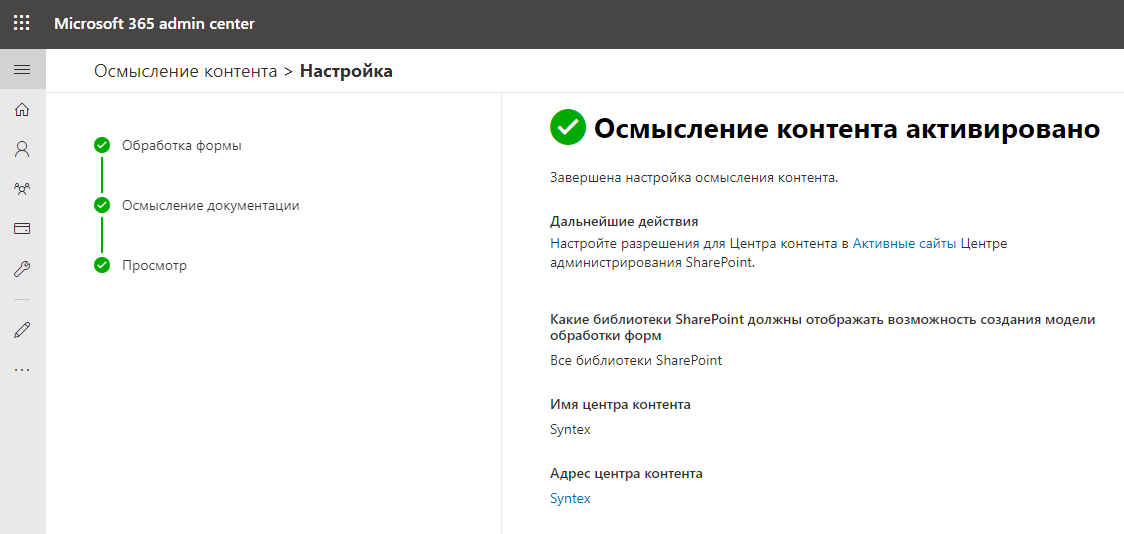
Configuración de SharePoint Syntex
Vaya al sitio de SharePoint Syntex. Exteriormente, parece un sitio regular de SharePoint Online, pero esto es solo a primera vista. En este sitio, configuraremos y entrenaremos modelos de análisis y procesamiento de datos.
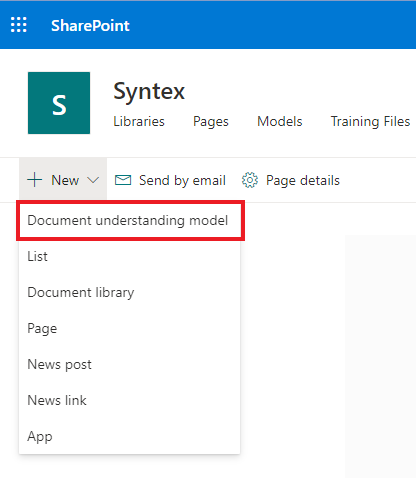
Es hora de comenzar a configurar el modelo. Haga clic en "Nuevo" y seleccione el elemento "Modelo de comprensión del documento".
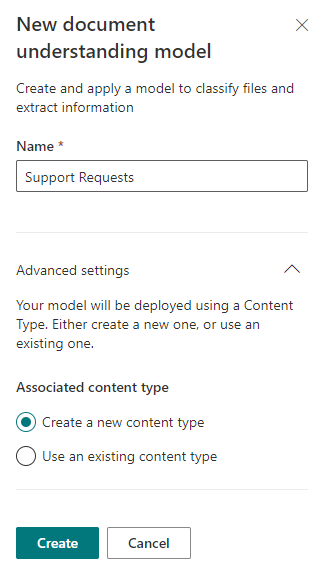
Escribimos el nombre de nuestro modelo futuro e indicamos la necesidad de crear un nuevo tipo de contenido para él. Ya he elegido el caso, que probablemente le resulte familiar por artículos anteriores, con la aplicación de soporte técnico. No desaparezca el mismo conjunto de plantillas para este tipo de apelaciones.
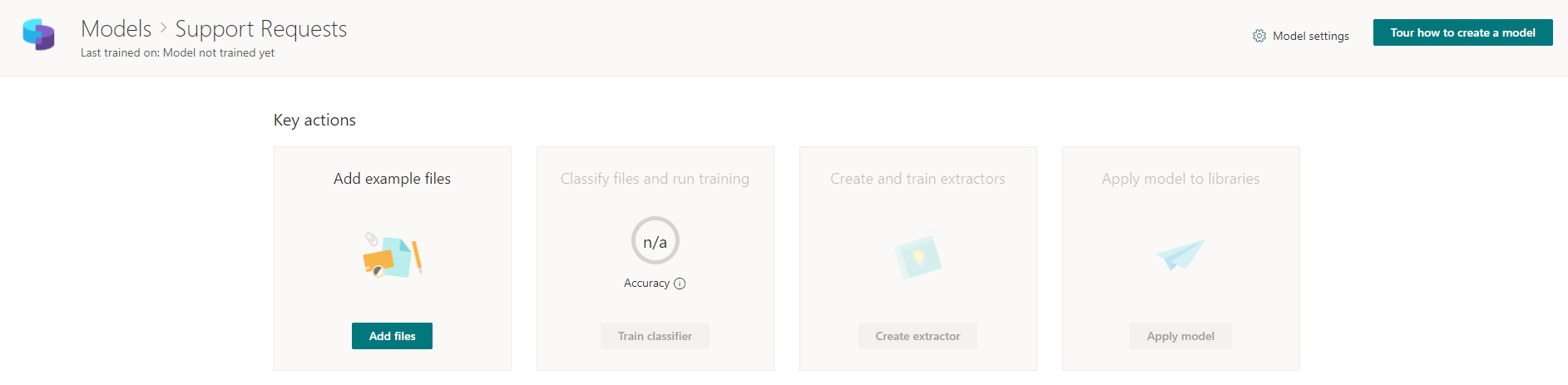
A continuación, nos recibe una página con instrucciones paso a paso que describen lo que debemos hacer para que el modelo futuro funcione, e idealmente funcione correctamente. Por lo tanto, primero debe cargar varios archivos (se recomiendan al menos 5), ayudar a SharePoint Syntex a clasificarlos según sea necesario y configurar los llamados "Extractores", plantillas para extraer datos de archivos. Una vez que haya recorrido todo el camino, puede aplicar este modelo a las bibliotecas de SharePoint necesarias.
Agregamos archivos de plantilla preparados que se utilizarán para clasificar futuros archivos reales.
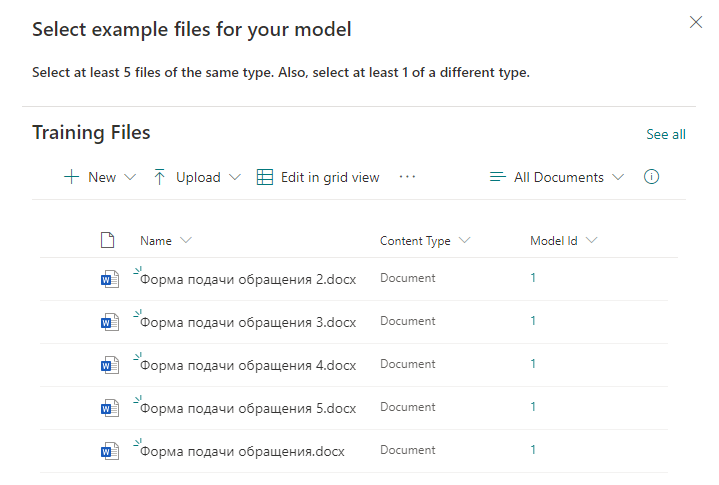
Luego indicamos las palabras clave por las que se realizará la búsqueda de información en el documento. En cada línea, indicamos una nueva palabra o frase que se utilizará para la búsqueda.
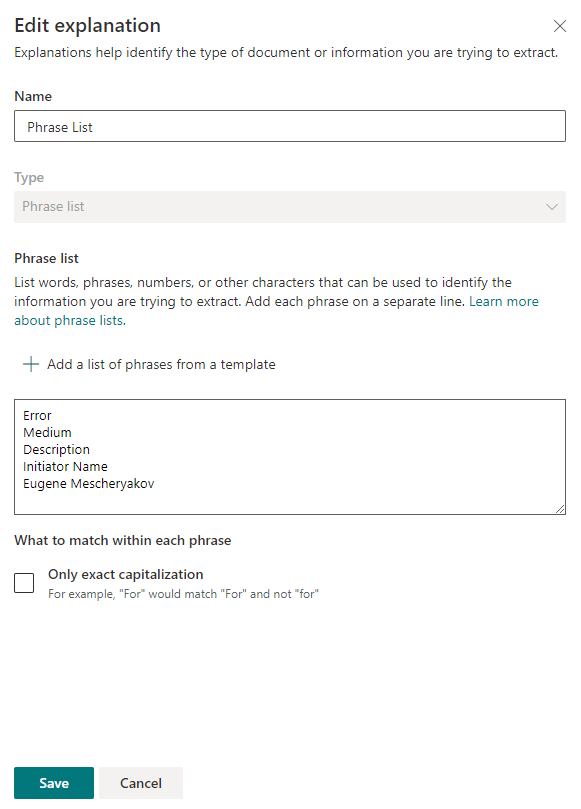
Después de guardar la configuración, puede intentar escanear los archivos existentes en busca de frases clave. Si se encuentra una coincidencia, al lado del archivo aparecerá "Coincidencia".
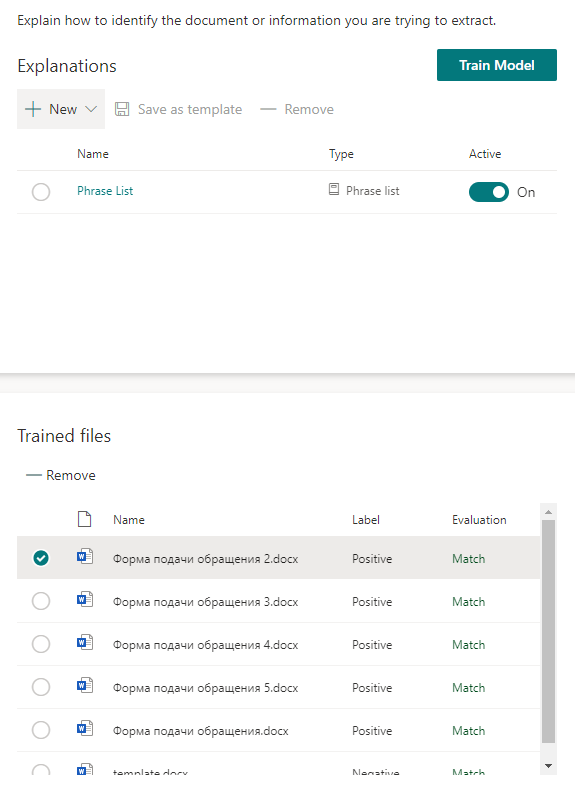
Empezamos a entrenar al modelo y vamos a servir el té. Tomará un poco de tiempo.
Una vez entrenado el modelo, es necesario configurar los "Extractores" - modelos de extracción de datos. Cada extractor es esencialmente un tipo específico de campo de SharePoint que se generará automáticamente en la biblioteca de destino. Después de agregar un archivo a esta biblioteca, la información extraída del archivo se escribirá en este campo.
Al crear un extractor, debe especificar su nombre y tipo. Actualmente, se admiten 4 tipos:
- Texto de una sola línea
- Texto de varias líneas
- fecha y hora
- Número
También puede usar campos existentes en una biblioteca de SharePoint.
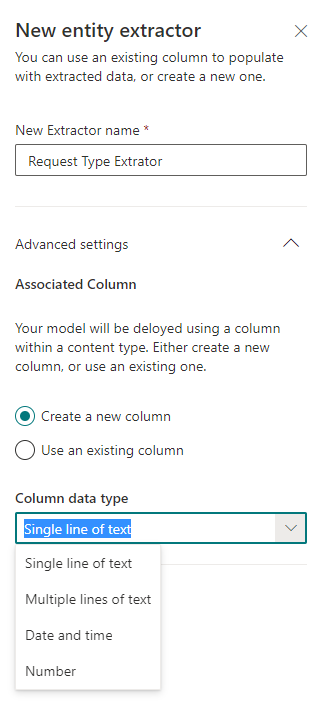
Al configurar el extractor en la plantilla del archivo subido, hacemos doble clic en la información que queremos extraer, reconocida en el paso anterior.
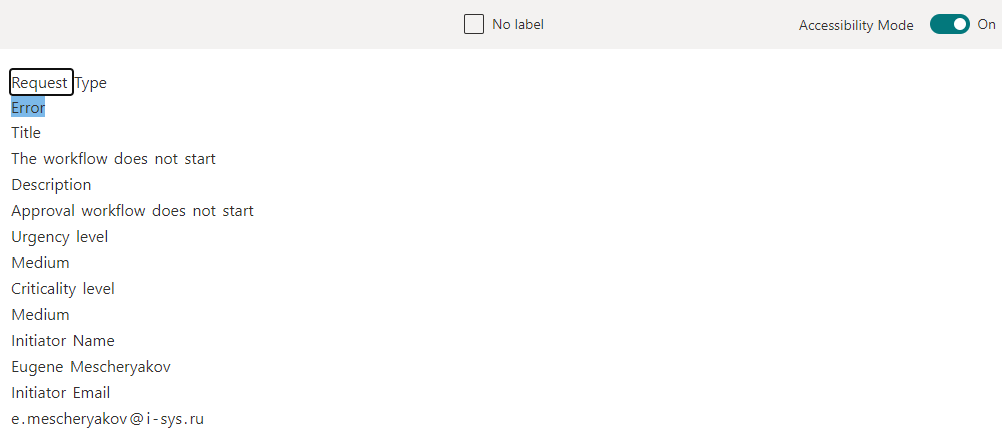
Creamos varios extractores de este tipo, marcamos los datos necesarios y, después de eso, pasamos a la parte final: aplicamos el modelo entrenado a la biblioteca de SharePoint y verificamos si todo funciona.

Seleccione el sitio de SharePoint requerido y especifique la biblioteca de destino. Creé la biblioteca de solicitudes de HelpDesk con anticipación y no realicé ningún cambio en ella, dejándola en su forma original. Guardamos la configuración y vamos a la biblioteca. Después de guardar la configuración de SharePoint Syntex, aparecen nuevos campos de SharePoint en la biblioteca, correspondientes por nombre y tipo a los extractores creados.
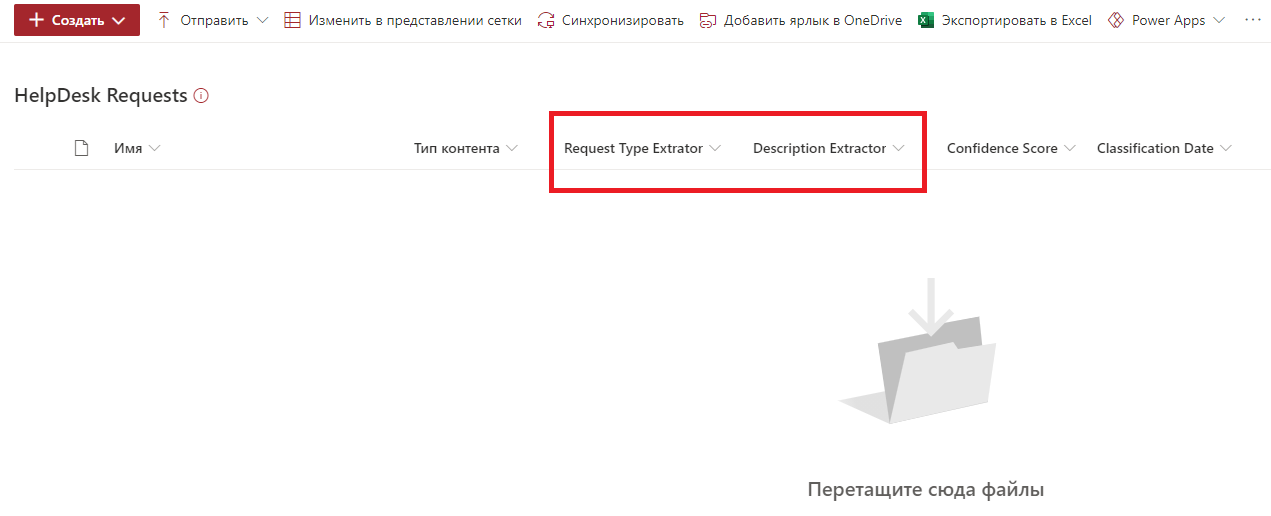
Queda por agregar el archivo a la biblioteca y verificarlo. Agregue otro archivo de plantilla de solicitud.

SharePoint Syntex reconoció el tipo de caso y la descripción. Los datos se almacenan en los campos. Todo parece estar en orden.
Total
La configuración del modelo de datos de SharePoint Syntex me llevó muy poco tiempo, todo es bastante intuitivo y fácil de configurar y usar. En el lado positivo, veo una capacidad realmente útil para extraer automáticamente información clave del contenido del archivo y escribirla en los campos de SharePoint. Esta función puede acelerar significativamente el trabajo y eliminar etapas innecesarias del trabajo del usuario, cuando, después de agregar un archivo, aún es necesario completar manualmente una serie de requisitos en la biblioteca. Contras: me gustaría más tipos de campos para extractores y una integración más cercana con Microsoft Power Platform. Pero estoy seguro de que esto se agregará pronto como parte de las próximas actualizaciones.
Además, SharePoint Syntex requiere una licencia separada ($ 5 por usuario por mes) y, por el momento, no está incluida en las licencias Enterprise de Microsoft 365. Pero en el futuro, esto puede cambiar y quizás SharePoint Syntex se convierta en parte de los servicios básicos de Microsoft 365. Intente activar la versión de prueba durante un mes y vea las capacidades de este servicio. ¡Que tengan un buen día todos!