Tensorflow, aunque pierde terreno en el entorno de investigación, sigue siendo popular en el desarrollo práctico. Uno de los puntos fuertes de TF que lo mantiene a flote es la capacidad de optimizar modelos para su implementación en entornos con recursos limitados. Hay marcos especiales para esto: Tensorflow Lite para dispositivos móviles y Tensorflow Servingpara uso industrial. Hay suficientes tutoriales sobre su uso en la Web (e incluso en Habré). En este artículo, hemos recopilado nuestra experiencia en la optimización de modelos sin utilizar estos marcos. Analizaremos algunos de los métodos y bibliotecas que realizan la tarea en cuestión, describiremos cómo puede ahorrar espacio en disco y RAM, las fortalezas y debilidades de cada enfoque y algunos efectos inesperados que encontramos.
En que condiciones trabajamos
Una de las tareas clásicas de la PNL es la clasificación temática de textos breves. Los clasificadores están representados por muchas arquitecturas diferentes, que van desde métodos clásicos como SVC hasta arquitecturas de transformadores como BERT y sus derivados. Examinaremos CNN: modelos convolucionales.
Una limitación importante para nosotros es la necesidad de entrenar y usar modelos (como parte del producto) en máquinas sin GPU. Esto afecta principalmente a la velocidad del aprendizaje y la inferencia.
Otra condición es que los modelos de clasificación estén entrenados y utilizados en conjuntos de varias piezas. Un conjunto de modelos, incluso los más simples, puede usar muchos recursos, especialmente RAM. Usamos nuestra propia solución para servir modelos; sin embargo, si necesita operar con conjuntos de modelos, eche un vistazo a Tensorflow Serving .
Nos enfrentamos a la necesidad de optimizar el modelo en TF versión 1.x, que ahora se considera oficialmente obsoleto. Para TF 2.x, muchas de las técnicas discutidas son irrelevantes o están integradas en la API estándar y, por lo tanto, el proceso de optimización es bastante simple.
Veamos primero la estructura de nuestro modelo.
Cómo funciona el modelo TF
Considere la llamada CNN superficial , una red con una capa convolucional y varios filtros. Este modelo ha funcionado bastante bien para la clasificación de texto sobre representaciones de palabras vectoriales.

Para simplificar, usaremos un conjunto fijo previamente entrenado de representaciones vectoriales de dimensión v x k , donde v es el tamaño del diccionario, k es la dimensión de las incrustaciones.
:
- Embedding-, .
- w x k. , (1, 1, 2, 3) 4 , 1 , 2 3 , .
- Max-pooling .
- , dropout- softmax- .
Adam, .
: .
, , 128 c w = 2 k = 300 () [filter_height, filter_width, in_channels, output_channels] — , 2*300*1*128 = 76800 float32, , 76800*(32/8) = 307200 .
? ( 220 . ) 300 265 . , .
TF . ( ), , , — ( ), . (). :
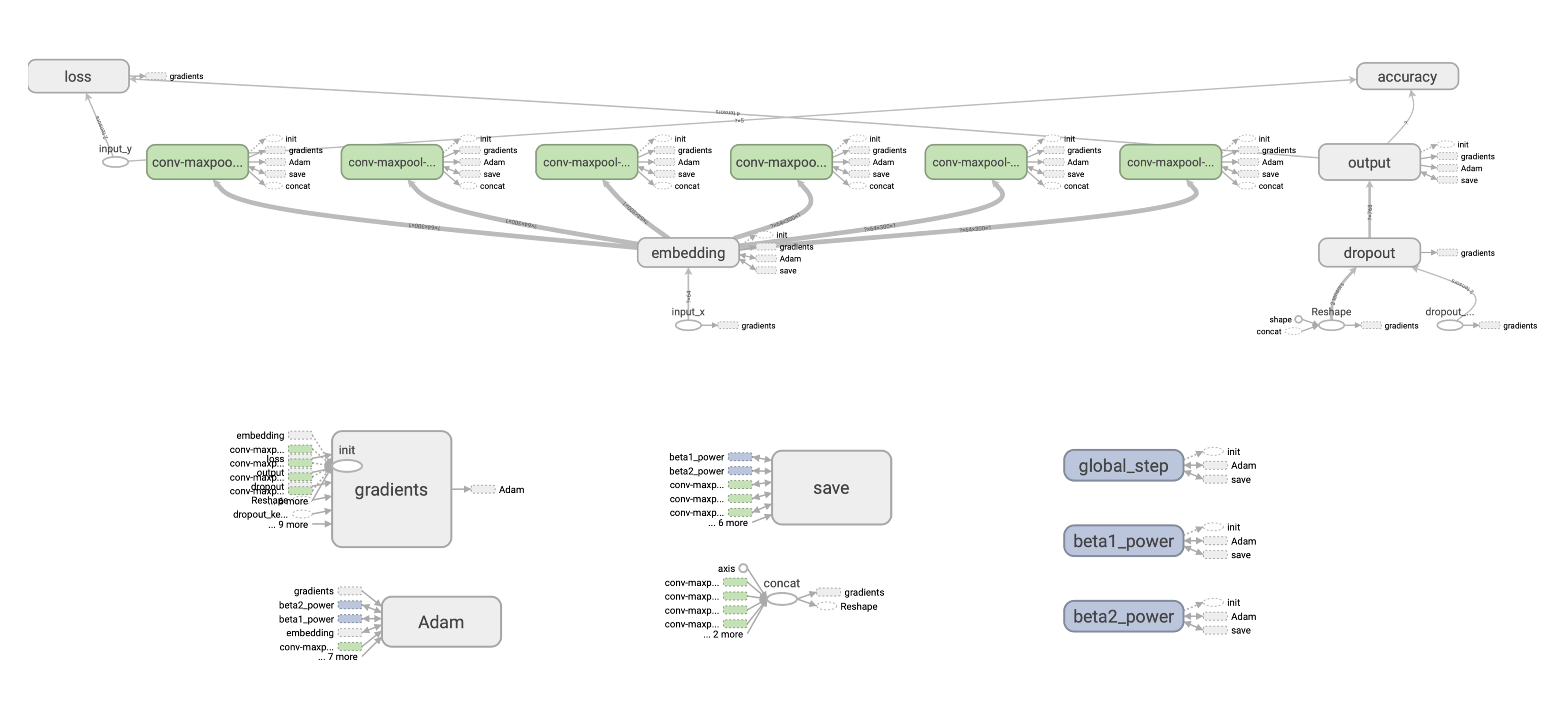
. , : SavedModel. , .
Checkpoint
, Saver API:
saver = tf.train.Saver(save_relative_paths=True)
ckpt_filepath = saver.save(sess, "cnn.ckpt"), global_step=0)global_step , , — cnn-ckpt-0.
<model_path>/cnn_ckpt :

checkpoint — . , TF . , .
.data , . , — 800 . , (≈265 ). ( ). , .
.index .
.meta — , (, , ), GraphDef, . , . — .meta , ? , TF - embedding-. , , , , , . , , :
with tf.Session() as sess:
saver = tf.train.import_meta_graph('models/ckpt_model/cnn_ckpt/cnn.ckpt-0.meta') # load meta
for n in tf.get_default_graph().as_graph_def().node:
print(n.name, n['attr'].shape)SavedModel
, . . API tf.saved_model. tf.saved_model, TF- (TFLite, TensorFlow.js, TensorFlow Serving, TensorFlow Hub).
:
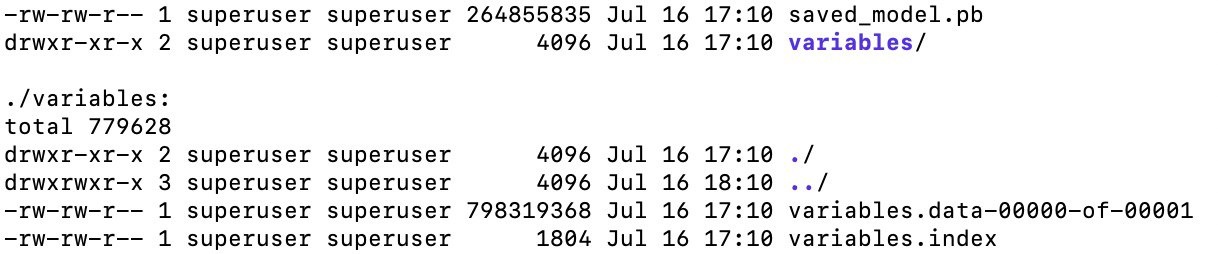
saved_model.pb, , , .meta , (, ), API, ( CLI, ).
SavedModel — , . “” . , , - — , .
, CNN-, TF 1.x, . .
, 1 , :
-
. , , ( tools.optimize_for_inference ). -
. , , — , tf.trainable_variables(). -
, . , (. BERT). -
. , . .
, , . , forward pass, . , . 1 265 .
TF 1.x , .
( ) GraphDef:
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def() . : tf.python.tools.freeze_graph tf.graph_util.convert_variables_to_constants. ( ) (, ['output/predictions']), , , . .
output_graph_def = graph_util.convert_variables_to_constants(self.sess, input_graph_def, output_node_names), .
freeze_graph() ( , , ). graph_util.convert_variables_to_constants() :
with tf.io.gfile.GFile('graph.pb', 'wb') as f:
f.write(output_graph_def.SerializeToString())266 , :
# GraphDef
with tf.io.gfile.GFile(graph_filepath, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
#
self.input_x = tf.placeholder(tf.int32, [None, self.properties.max_len], name="input_x")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# graph_def
input_map = {'input_x': self.input_x, 'dropout_keep_prob': self.dropout_keep_prob}
tf.import_graph_def(graph_def, input_map), import:
predictions = graph.get_tensor_by_name('import/output/predictions:0'):
feed_dict = {self.input_x: encode_sentence(sentence), self.dropout_keep_prob: 1.}
sess.run(self.predictions, feed_dict), :
- . ,
sess.run(...). , CPU 20 ms, ~2700 ms. , . SavedModel . - RAM. RAM, . ~265 , . , TF GraphDef .
- – RAM TF . 1.15, TF 1.x, 118 MiB, 1.14 – 3 MiB.
, . ? / TF- tf.train.Saver. , , , :
- MetaGraph
tf.train.Saver . , :
saver = tf.train.Saver(var_list=tf.trainable_variables())MetaGraph . , meta . MetaGraph save:
ckpt_filepath = saver.save(self.sess, filepath, write_meta_graph=False)1014 M 265 M ( , ).
, TF 1.x:
- Grappler: c tensorflow
- Pruning API: google-research
- Graph Transform Tool:
, — tensorflow, Grappler. Grappler . , set_experimental_options. , zip . , zip , . Grappler .
google-research mask threshold, . . , , mask threshold, , , . .
Grappler, . : ? , ? , 0.99 . , mc, hex :

, , . . -, . -, , , , . , .
CNN. .
, . Graph transform tool.
quantize_weights 8 . , 8- . , , - .
quantize_nodes 8- . .
, - . quantize_weights - , 4 .
, , TensorFlow Lite, .
— , . 64 (32) , .
RAM Ubuntu ( numpy int64) . 220 , int32, int16. .

tf-. float16. , , ( 10%), ( 10 ). , , epsilon learning_rate . , , .
RAM
, . , .
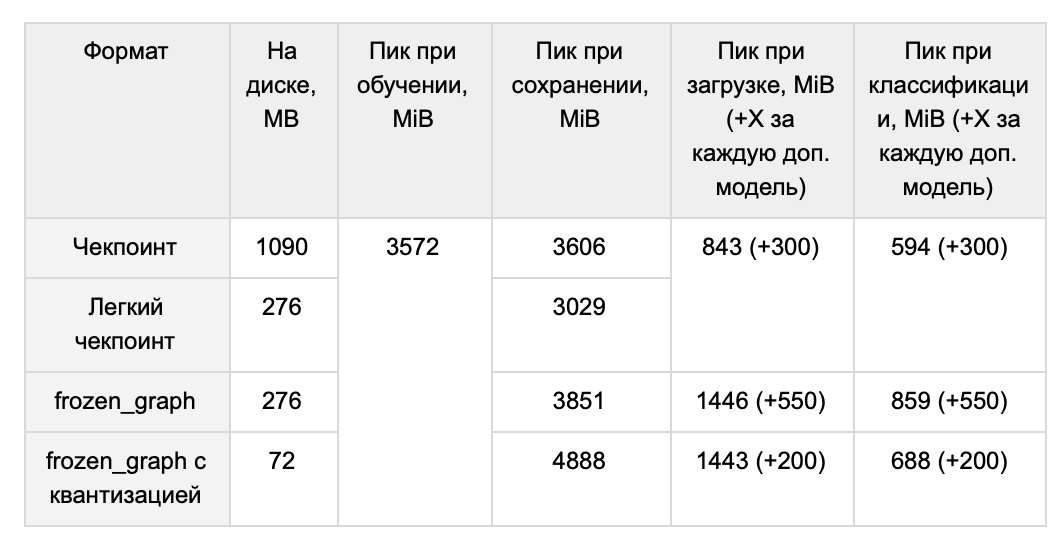
, . . .
QA-
Q: -, - ?
A: , . word2vec. ( , , min count, learning rate), 220 ( — 265 MB) CNN, 439 (510 MB).
- , , , - . , ( ). , . YouTokenToMe, , , .. , .., . . , , , . 30 (37 MB) , 3.7 CPU 2.6 GPU. ( ), OOV-.
Q: , , ?
A: , .
:
1. :
with tf.gfile.GFile(path_to_pb, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, name='')
return graph2. "" :
sess.run(restored_variable_names) 3. , .
4. , , :
tf.Variable(tensors_to_restore["output/W:0"], name="W"), .
, , .
No intentamos reentrenar los modelos comprimidos por el resto de los métodos descritos, pero teóricamente no debería haber ningún problema con esto.
P: ¿Existen otras formas de reducir la optimización que no haya considerado?
R: Tenemos varias ideas que nunca llegamos a realizar. En primer lugar, el plegado constante es un "plegado" de un subconjunto de nodos de gráfico, cálculo previo del valor de las partes del gráfico que dependen débilmente de los datos de entrada. En segundo lugar, en nuestro modelo, parece una buena solución aplicar la poda de incrustaciones.