Procesar incluso un par de gigabytes de datos en una computadora portátil solo puede ser una tarea abrumadora si no tiene mucha RAM y una buena potencia de procesamiento.
A pesar de esto, los científicos de datos todavía tienen que encontrar soluciones alternativas a este problema. Hay opciones para configurar Pandas para manejar grandes conjuntos de datos, comprar GPU o comprar potencia de computación en la nube. En este artículo, veremos cómo usar Dask para grandes conjuntos de datos en su máquina local.
Dask y Python
Dask es una biblioteca de computación paralela de Python flexible. Funciona bien con otros proyectos de código abierto como NumPy, Pandas y scikit-learn. Dask tiene una estructura de matriz que es equivalente a las matrices NumPy, los marcos de datos de Dask son similares a los marcos de datos de Pandas y Dask-ML es scikit-learn.
Estas similitudes facilitan la integración de Dask en su trabajo. La ventaja de usar Dask es que puede escalar los cálculos a múltiples núcleos en su computadora. De esta forma, tiene la oportunidad de trabajar con grandes cantidades de datos que no caben en la memoria. También puede acelerar los cálculos que suelen ocupar mucho espacio.
Fuente
Dask DataFrame
Cuando se carga una gran cantidad de datos, Dask suele leer una muestra de los datos para reconocer los tipos de datos. Esto a menudo conduce a errores, ya que puede haber diferentes tipos de datos en la misma columna. Se recomienda que declare los tipos con anticipación para evitar errores. Dask puede descargar archivos enormes dividiéndolos en bloques definidos por el parámetro
blocksize.
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )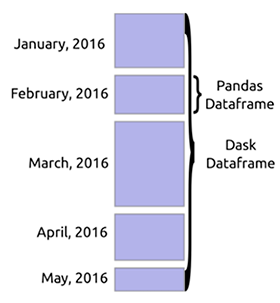
Los
comandos de origen en Dask DataFrame son similares a los comandos de Pandas. Por ejemplo, conseguir
headytail trama de datos es similar:
df.head()
df.tail()Las funciones en el DataFrame son perezosas. Es decir, no se evalúan hasta que se llama a la función
compute.
df.isnull().sum().compute()Debido a que los datos se cargan en trozos, algunas funciones de Pandas, como
sort_values()fallarán. Pero puedes usar la funciónnlargest().
Clústeres en Dask
La computación en paralelo es clave en Dask porque le permite leer en múltiples núcleos al mismo tiempo. Dask proporciona
machine schedulerque se ejecuta en una sola máquina. No escala. También hay uno distributed schedulerque le permite escalar a varias máquinas.
El uso
dask.distributedrequiere la configuración del cliente. Esto es lo primero que debe hacer si planea usarlo dask.distributed en su análisis. Proporciona baja latencia, localidad de datos, comunicación de trabajador a trabajador y es fácil de configurar.
from dask.distributed import Client
client = Client()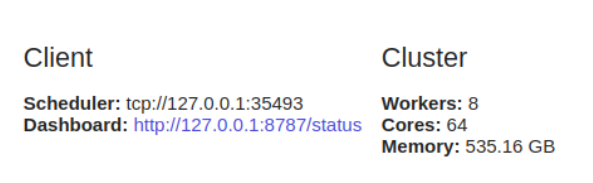
Es
dask.distributedbeneficioso usarlo incluso en una sola máquina, ya que ofrece funciones de diagnóstico a través de un tablero.
Si no lo configura
Client, de forma predeterminada utilizará el programador de la máquina para una máquina. Proporcionará simultaneidad en una sola computadora usando procesos e hilos.
Dask ML
Dask también permite el entrenamiento y la previsión de modelos paralelos. El objetivo
dask-mles ofrecer aprendizaje automático escalable. Cuando declara n_jobs = -1 scikit-learn, puede ejecutar cálculos en paralelo. Dask utiliza esta función para permitirle realizar cálculos en un clúster. Puede hacer esto con el paquete joblib , que permite el paralelismo y la canalización en Python. Con Dask ML, puede usar modelos de scikit-learn y otras bibliotecas como XGboost.
Una implementación simple se vería así.
Primero, importe
train_test_splitpara dividir sus datos en casos de prueba y entrenamiento.
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Luego, importe el modelo que desea usar y cree una instancia.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)Luego, debe importar
joblibpara habilitar la computación paralela.
import joblibLuego comience a entrenar y pronosticar con el backend paralelo.
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)Límites y uso de memoria
Las tareas individuales en Dask no se pueden ejecutar en paralelo. Los trabajadores son procesos de Python que heredan las ventajas y desventajas de la computación de Python. Además, cuando se trabaja en un entorno distribuido, se debe tener cuidado para garantizar la seguridad y privacidad de sus datos.
Dask tiene un programador central que monitorea los datos en los nodos trabajadores y en el clúster. También gestiona la liberación de datos del clúster. Cuando la tarea esté completa, la eliminará inmediatamente de la memoria para dejar espacio para otras tareas. Pero si un cliente específico necesita algo o es importante para los cálculos actuales, se almacenará en la memoria.
Otra limitación de Dask es que no implementa todas las funciones de Pandas. La interfaz de Pandas es muy grande, por lo que Dask no la cubre por completo. Es decir, realizar algunas de estas operaciones en Dask puede ser un desafío. Además, las operaciones lentas de Pandas también serán lentas en Dask.
Cuando no necesita un Dask DataFrame
En las siguientes situaciones, Dask puede no ser la opción adecuada para usted:
- Cuando Pandas tiene funciones que necesita, pero Dask no las ha implementado.
- Cuando sus datos encajan perfectamente en la memoria de su computadora.
- Cuando sus datos no están en forma tabular. Si es así, pruebe con dask.bag o disk.array .
Pensamientos finales
En este artículo, analizamos cómo puede usar Dask para trabajar de forma distribuida con enormes conjuntos de datos en su computadora local. Vimos que podemos usar Dask ya que su sintaxis ya nos es familiar. Además, Dask puede escalar a miles de núcleos.
También vimos que podemos usarlo en el aprendizaje automático para la predicción y el entrenamiento. Si desea saber más, consulte estos materiales en la documentación .
