Debo señalar que un mes después de familiarizarme con esta tecnología, comencé a usar antidepresivos. No se sabe con certeza si NiFi fue el detonante o la gota que colmó el vaso, así como su participación en este hecho. Pero, como me comprometí a delinear todo lo que le espera a un potencial principiante en este camino, debo ser lo más franco posible.
En un momento en el que, técnicamente, Apache NiFi es un vínculo poderoso entre varios servicios (intercambia datos entre ellos, lo que permite enriquecerlos y modificarlos en el camino), lo miro desde el punto de vista de un analista . Esto se debe a que NiFi es una herramienta ETL muy útil. En particular, como equipo, nos enfocamos en construir su arquitectura SaaS.
La experiencia de automatizar uno de mis flujos de trabajo, es decir, la formación y distribución de informes semanales en Jira Software , quiero divulgarla en este artículo. Por cierto, también describiré y publicaré la metodología de análisis del rastreador de tareas, que responde claramente a la pregunta: ¿qué están haciendo los empleados? También describiré y publicaré en un futuro próximo.
A pesar de la dedicación de este artículo a los principiantes, creo que es correcto y útil que los arquitectos más experimentados (gurús, por así decirlo) lo revisen en crommentions o compartan sus casos de uso de NiFi en varios campos de actividad. Muchos chicos, incluido yo, se lo agradecerán.
Resumen del concepto Apache NiFi.
Apache NiFi es un producto de código abierto para la automatización y el control del flujo de datos entre sistemas. Para empezar, es importante darse cuenta inmediatamente de dos cosas.
La primera es la zona Low Code. ¿Lo que quiero decir? Se supone que todas las manipulaciones con datos desde el momento en que ingresan a NiFi hasta la extracción se pueden realizar utilizando herramientas estándar (procesadores). Para casos especiales, hay un procesador para ejecutar scripts desde bash.
Esto sugiere que hacer algo en NiFi está mal, es bastante difícil (¡pero lo logré! - ese es el segundo punto). Difícil porque cualquier procesador lo pateará de inmediato. ¿Dónde enviar errores? Qué hacer con ellos? ¿Cuánto hay que esperar? ¡Y aquí me diste un poco de espacio! ¿Ha leído la documentación detenidamente? etc.

La segunda (clave) es el concepto de programación en streaming y nada más. Aquí, personalmente, no lo entendí de inmediato (por favor, no juzgue). Teniendo experiencia en programación funcional en R, sin saberlo formé funciones en NiFi. En última instancia, rehacer, mis colegas me dijeron cuando vieron mis inútiles intentos de hacer amigos de estas "funciones".
Creo que la teoría es suficiente por hoy, aprendamos mejor todo de la práctica. Formulemos una especificación técnica similar para los análisis semanales de Jira.
- Obtenga el registro de trabajo y el historial de cambios de la grasa de la semana.
- Muestre las estadísticas básicas para este período y responda la pregunta: ¿qué estaba haciendo el equipo?
- Envíe informe al jefe y colegas.
Con el fin de brindar más beneficios al mundo, no me detuve en un período semanal y desarrollé un proceso con la capacidad de descargar una cantidad mucho mayor de datos.
Vamos a averiguarlo.
Los primeros pasos. Obteniendo datos de la API
Apache NiFi no tiene un proyecto separado. Solo tenemos un espacio de trabajo común y la capacidad de formar grupos de procesos en él. Esto es suficiente.
Busque el Grupo de procesos en la barra de herramientas y cree el grupo Jira_report. Vaya al grupo y comience a construir el flujo de trabajo. La mayoría de los procesadores desde los que se puede ensamblar requieren una conexión ascendente. En palabras simples, este es un disparador sobre el que disparará el procesador. Por lo tanto, es lógico que todo el flujo comience con un disparador regular; en NiFi, este es el procesador GenerateFlowFile. Qué él ha hecho. Crea un archivo de transmisión que consta de un conjunto de atributos y contenido. Los atributos son pares clave / valor de cadena que están asociados con el contenido.
El contenido es un archivo normal, un conjunto de bytes. Imagina que el contenido es un archivo adjunto a un FlowFile.
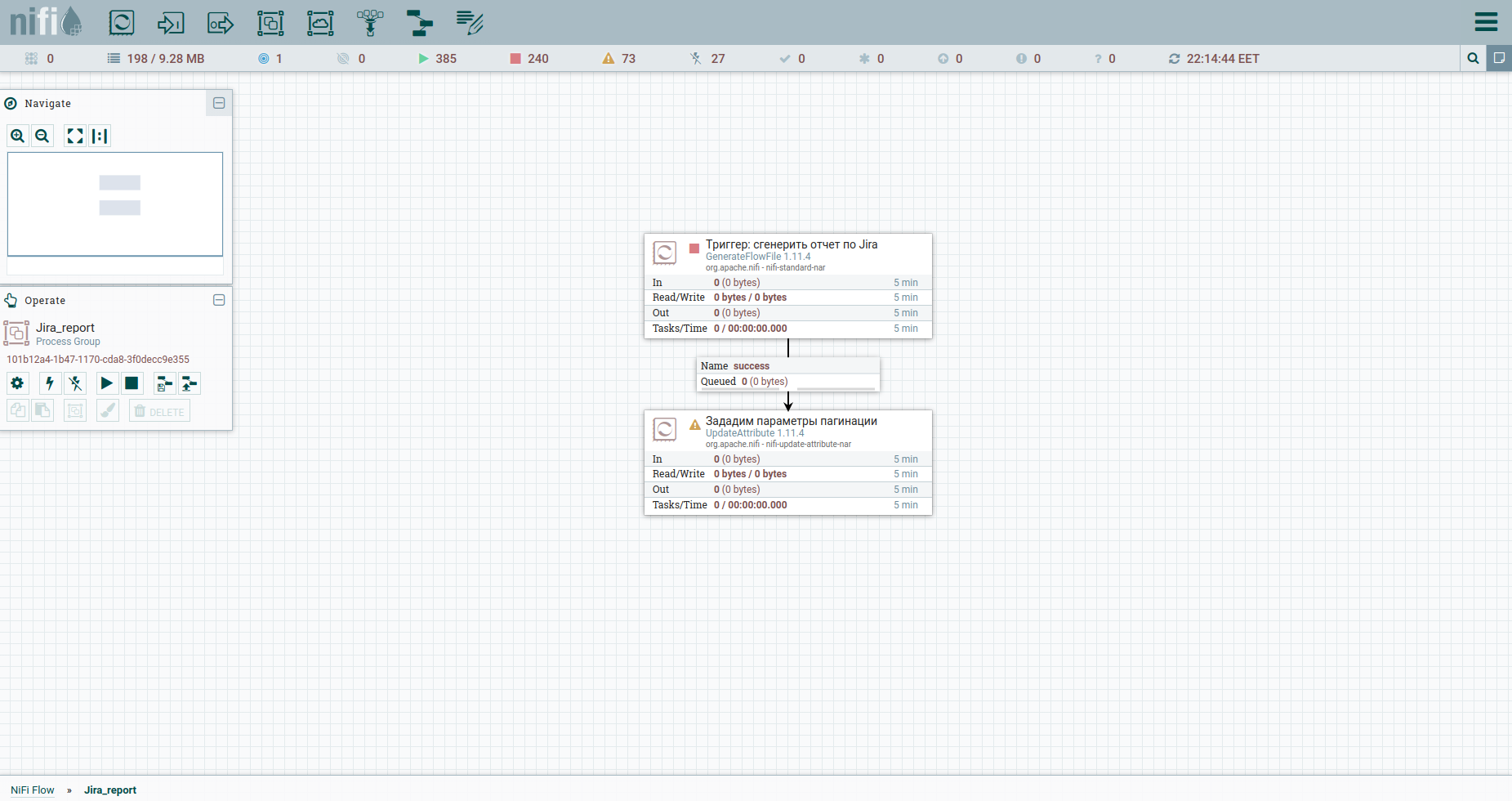
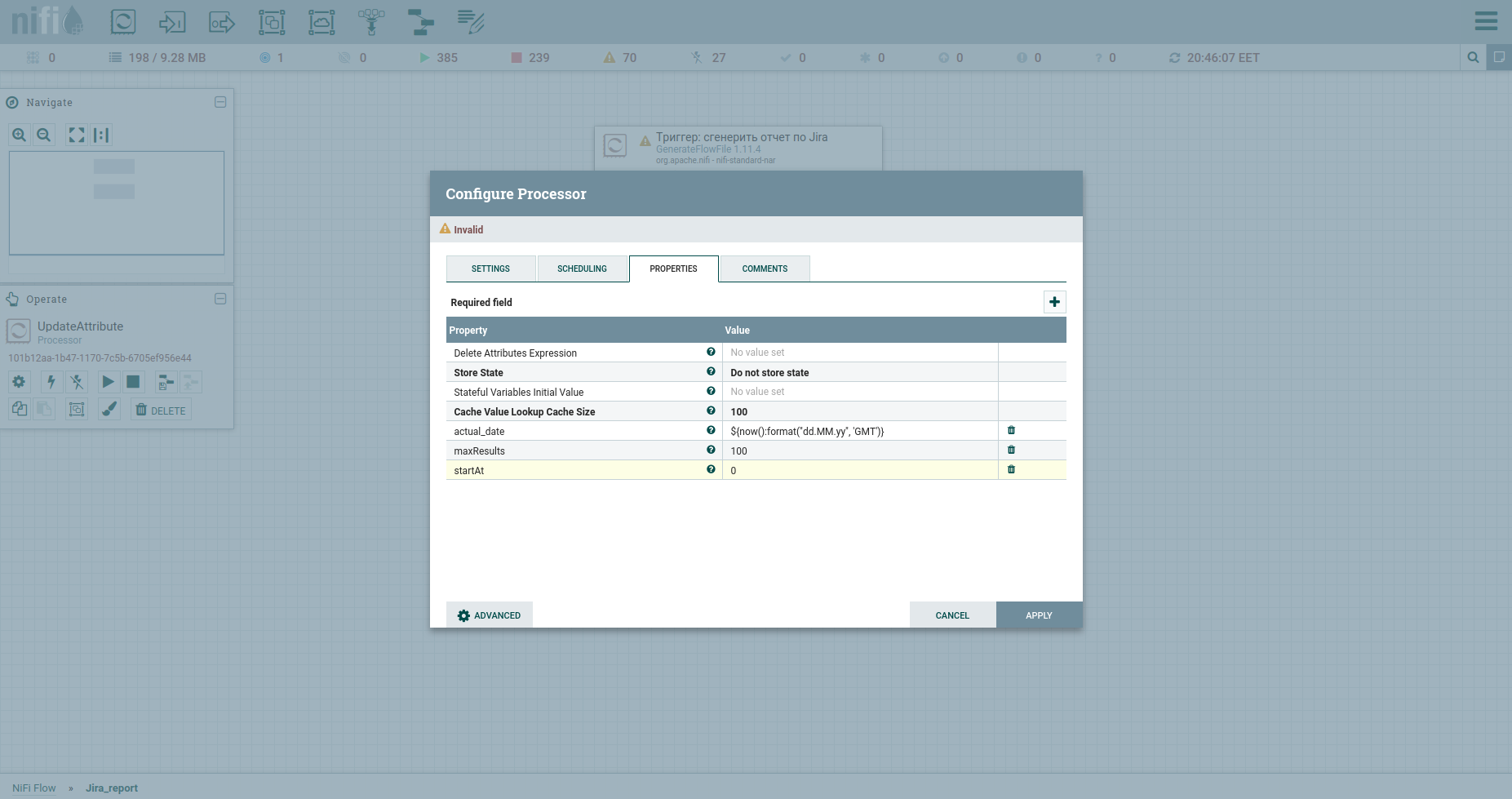
Agregamos Procesador → GenerateFlowFile. En la configuración, en primer lugar, recomiendo encarecidamente configurar el nombre del procesador (este es un buen tono): la pestaña Configuración. Otro punto: de forma predeterminada, GenerateFlowFile genera archivos continuos de forma continua. Es poco probable que alguna vez lo necesite. Inmediatamente aumentamos el programa de ejecución, por ejemplo, hasta 60 segundos, la pestaña Programación. Además, en la pestaña Propiedades, indicaremos la fecha de inicio del período del informe, el atributo report_from con un valor en el formato aaaa / mm / dd. De acuerdo con la documentación de la API de Jira, tenemos un límite de problemas de descarga, no más de 1000. Por lo tanto, para obtener todas las tareas, tendremos que formar una solicitud JQL, que especifica los parámetros de paginación: startAt y maxResults.

Vamos a configurarlos con atributos usando el procesador UpdateAttribute. Al mismo tiempo, fijaremos la fecha de generación del informe. Lo necesitaremos más tarde. Probablemente haya notado el atributo actual_date. Su valor se establece mediante Expression Language. Coge una hoja de trucos genial en él. Eso es todo, podemos formar JQL a fat: indicaremos los parámetros de paginación y los campos obligatorios. Posteriormente, será el cuerpo de la solicitud HTTP, por lo tanto, lo enviaremos al contenido. Para hacer esto, usamos el procesador ReplaceText y especificamos su Valor de Reemplazo algo como esto:
{"startAt": ${startAt}, "maxResults": ${maxResults}, "jql": "updated >= '2020/11/02'", "fields":["summary", "project", "issuetype", "timespent", "priority", "created", "resolutiondate", "status", "customfield_10100", "aggregatetimespent", "timeoriginalestimate", "description", "assignee", "parent", "components"]}Observe cómo se escriben los enlaces de atributos.
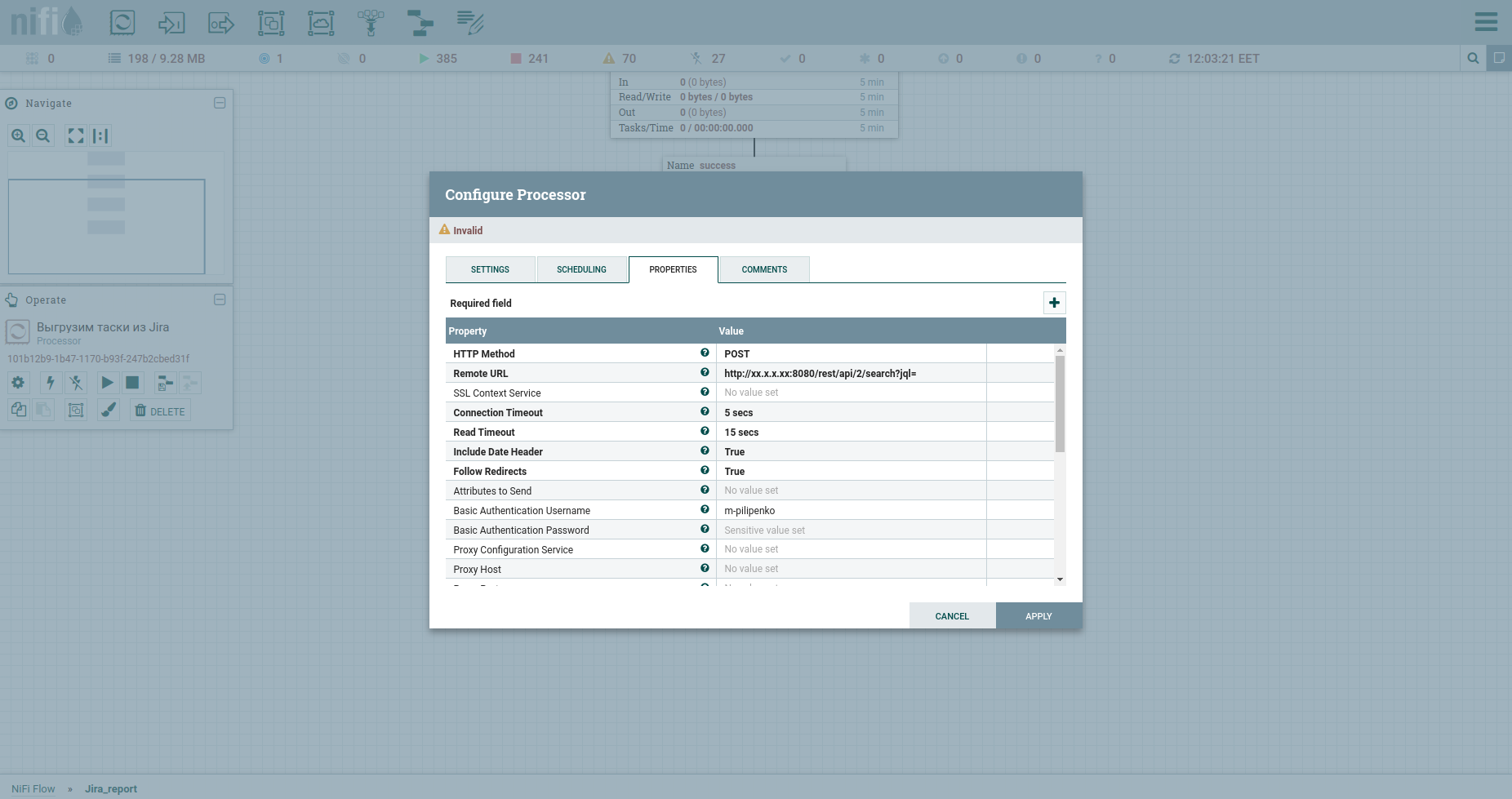
Felicitaciones, estamos listos para realizar una solicitud HTTP. El procesador InvokeHTTP encajará aquí. Por cierto, puede hacer cualquier cosa ... Me refiero a los métodos GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS. Modifiquemos sus propiedades de la siguiente manera:
Método HTTP tenemos POST.
La URL remota de nuestro fat incluye IP, puerto y / rest / api / 2 / search? Jql =.
El nombre de usuario de autenticación básica y la contraseña de autenticación básica son credenciales a fat.
Cambie el tipo de contenido a application / json b puesto verdadero en el cuerpo del mensaje de envío, lo que significa enviar JSON que vendrá del procesador anterior en el cuerpo de la solicitud.
APLICAR.
La respuesta del apish será un archivo JSON que se incluirá en el contenido. Estamos interesados en dos cosas: el campo total que contiene el número total de tareas en el sistema y la matriz de problemas, que ya contiene algunas de ellas. Analicemos la respuesta y familiaricémonos con el procesador EvaluateJsonPath.
Si JsonPath apunta a un objeto, el resultado del análisis se escribirá en el atributo del archivo de flujo. Aquí hay un ejemplo: el campo total y la siguiente pantalla. En el caso de que JsonPath apunte a una matriz de objetos, como resultado del análisis, el archivo de flujo se dividirá en un conjunto con el contenido correspondiente a cada objeto. Aquí tienes un ejemplo: el campo de problema. Ponemos otro EvaluateJsonPath y escribimos: Property - issue, Value - $ .issue.

Ahora nuestra secuencia ahora consistirá no en un archivo, sino en muchos. El contenido de cada uno de ellos contendrá JSON con información sobre una tarea específica.
Siga adelante. ¿Recuerda que configuramos maxResults en 100? Después del paso anterior, tendremos cien primeras tareas. Consigamos más e implementemos la paginación.
Para hacer esto, aumentemos el número de tarea de inicio en maxResults. Usemos UpdateAttribute nuevamente: indicaremos el atributo startAt y le asignaremos un nuevo valor $ {startAt: plus ($ {maxResults})}.
Bueno, no podemos prescindir de una verificación para alcanzar el número máximo de tareas: el procesador RouteOnAttribute. Los ajustes son los siguientes: Y bucle. En total, el ciclo se ejecutará siempre que el número de tarea inicial sea menor que el número total de tareas. A la salida de él, una corriente de tareas. Así es como se ve el proceso ahora:
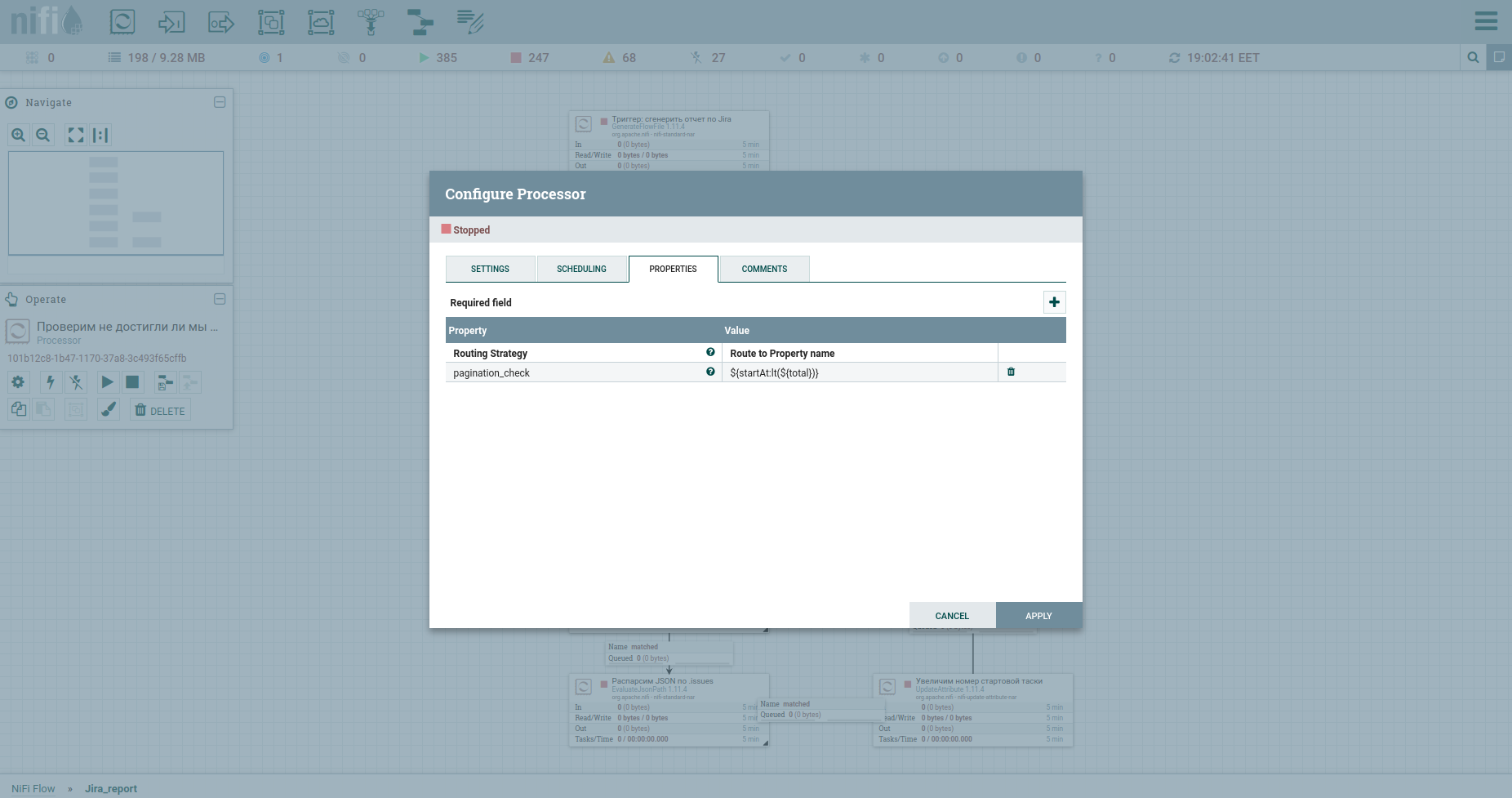

Sí, amigos, lo sé, están cansados de leer mis comentarios en cada cuadro. Quieres comprender el principio en sí. Yo no tengo nada contra ello.
Esta sección debería facilitar que un principiante absoluto ingrese a NiFi. Entonces, teniendo en la mano una plantilla generosamente presentada por mí, no será difícil ahondar en los detalles.
Galope por Europa. Cargar un registro de trabajo, etc.
Bueno, aceleremos. Como dicen, encuentre las diferencias: para una percepción más fácil, moví el proceso de descargar el registro de trabajo y el historial de cambios a un grupo separado. Aquí está: Para sortear las limitaciones al descargar automáticamente un registro de trabajo de Jira, es recomendable referirse a cada tarea por separado. Por eso necesitamos sus llaves. La primera columna simplemente convierte el flujo de tareas en un flujo de claves. A continuación, nos dirigimos al apish y guardamos la respuesta. Nos resultará conveniente organizar el registro de trabajo y el registro de cambios para todas las tareas en forma de documentos separados. Por lo tanto, usaremos el procesador MergeContent y pegaremos el contenido de todos los archivos de flujo con él.
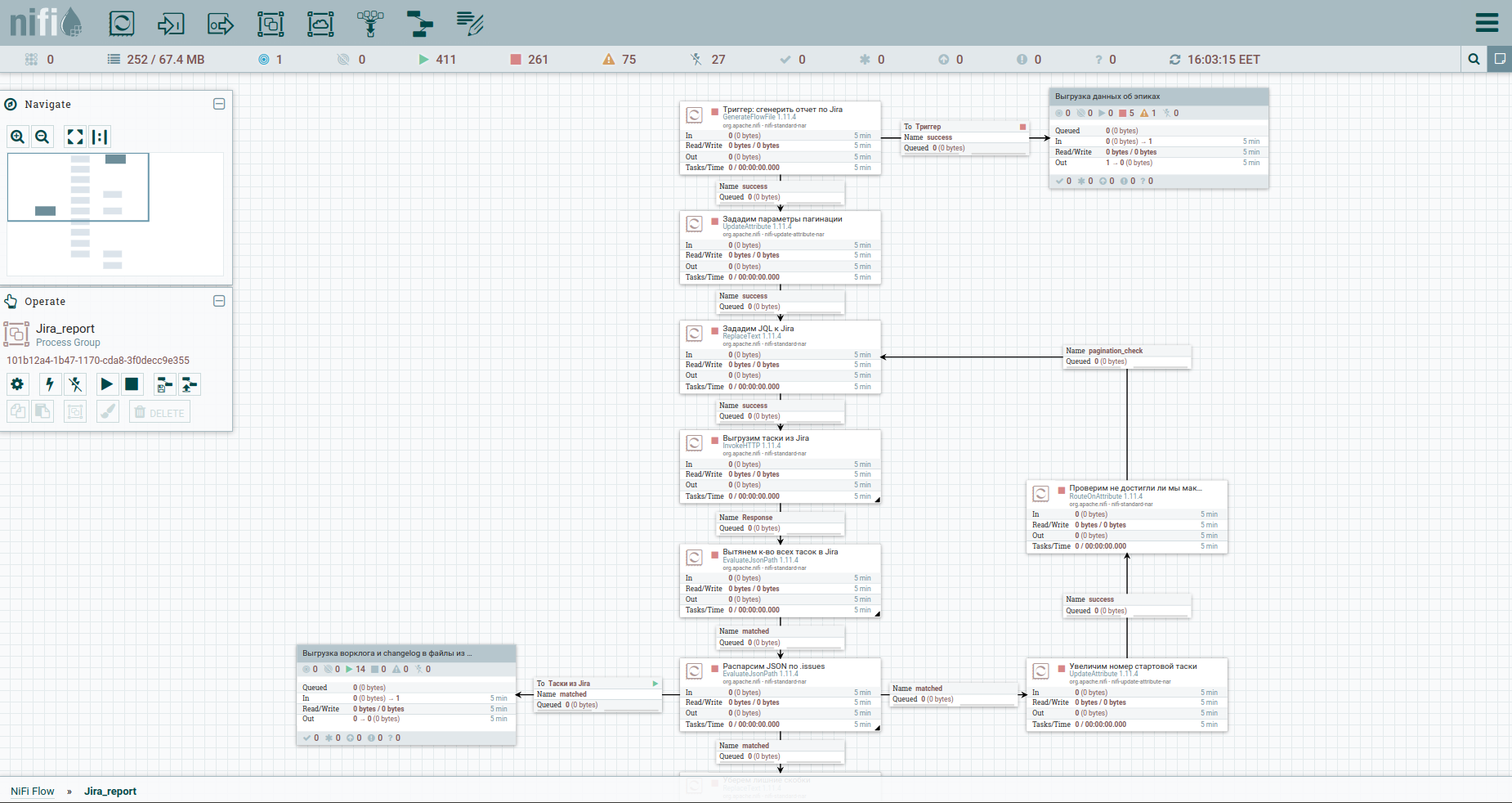
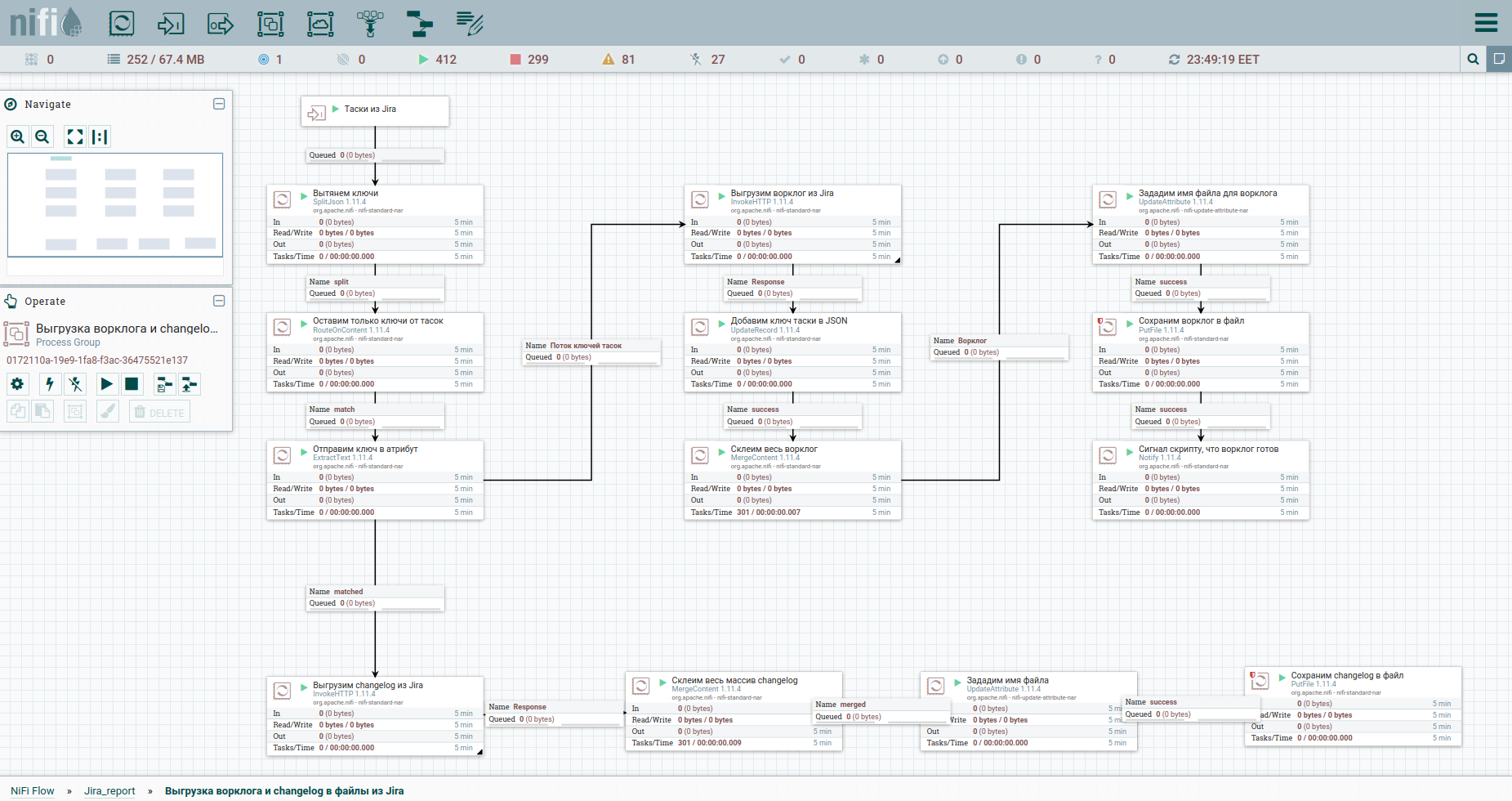
También en la plantilla notarás un grupo para descargar datos por épicos. Una epopeya en Jira es una tarea común a la que muchos otros se unen. Este grupo será útil en el caso de que solo se mida una parte de las tareas, para no perder información sobre las epopeyas de algunas de ellas.
La etapa final. Generación de informes y envío por correo electrónico
Bueno. Todos los puntos se descargaron y se enviaron de dos maneras: al grupo para descargar el registro de trabajo y al script para generar el informe. Por lo último, tenemos un STDIN, por lo que debemos reunir todas las tareas en una pila. Haremos esto en MergeContent, pero antes corregiremos ligeramente el contenido para que el json final sea correcto. Un interesante procesador Wait está presente delante del cuadro de generación de scripts (ExecuteStreamCommand). Espera una señal del procesador Notify, que está en el grupo de descarga del registro de trabajo, de que todo está listo allí y puede continuar. A continuación, ejecutamos el script desde bash-a - ExecuteStreamCommand. Y enviamos el informe usando PutEmail a todo el equipo.

Les contaré en detalle sobre el guión, así como sobre la experiencia de implementar la analítica de Jira Software en nuestra empresa en un artículo aparte, que estará listo el otro día.
En resumen, los informes que hemos desarrollado proporcionan una visión estratégica de lo que está haciendo una unidad o equipo. Y esto es invaluable para cualquier jefe, debes estar de acuerdo.
Epílogo
¿Por qué agotarse si puede hacer todo esto con un guión a la vez? Sí, estoy de acuerdo, pero parcialmente.
Apache NiFi no simplifica el proceso de desarrollo, simplifica la operación. Podemos detener cualquier hilo en cualquier momento, hacer una edición y empezar de nuevo.
Además, NiFi nos da una visión de arriba hacia abajo de los procesos por los que vive la empresa. En el siguiente grupo, tendré otro guión. Otro será el juicio de mi colega. Lo entiendes, ¿verdad? Arquitectura en la palma de tu mano. Como bromea nuestro jefe, estamos implementando Apache NiFi para poder despedirlos a todos más tarde, y yo era el único que presionaba los botones. Pero esto es una broma.
Bueno, en este ejemplo, los bollos en forma de una tarea programada para generar informes y enviar cartas también son muy, muy agradables.
Lo confieso, estaba planeando derramar mi alma y contarles sobre el rastrillo que pisé en el proceso de estudiar tecnología, cuántos de ellos. Pero aquí ya se ha leído mucho. Si el tema es interesante, hágamelo saber. Mientras tanto amigos, gracias y espero en los comentarios.
Enlaces útiles
Un artículo ingenioso que cubre Apache NiFi directamente en tus dedos y con letras.
Una breve guía en ruso.
Una interesante hoja de trucos sobre el lenguaje de expresión.
La comunidad Apache NiFi de habla inglesa está abierta a preguntas.
La comunidad Apache NiFi de habla rusa en Telegram está más viva que todos los seres vivos, entra.