Este artículo apareció por varias razones.
Primero, en la abrumadora mayoría de libros, recursos de Internet y lecciones sobre ciencia de datos, los matices, las fallas de los diferentes tipos de normalización de datos y sus razones no se consideran en absoluto, o se mencionan solo de pasada y sin revelar la esencia.
En segundo lugar, existe un uso "ciego", por ejemplo, de la estandarización para conjuntos con una gran cantidad de características, "para que sea igual para todos". Especialmente para principiantes (él mismo era el mismo). A primera vista, está bien. Pero tras un examen más detenido, puede resultar que algunos signos se colocaron inconscientemente en una posición privilegiada y comenzaron a influir en el resultado mucho más fuerte de lo que deberían.
Y, en tercer lugar, siempre quise obtener un método universal que tenga en cuenta las áreas problemáticas.
La repetición es la madre del aprendizaje
La normalización es la conversión de datos a ciertas unidades adimensionales. A veces, dentro de un rango determinado, por ejemplo, [0..1] o [-1..1]. A veces, con alguna propiedad determinada, como, por ejemplo, una desviación estándar de 1.
El objetivo clave de la normalización es traer varios datos en una amplia variedad de unidades y rangos de valores en una sola forma que le permitirá compararlos entre sí o usarlos para calcular la similitud de objetos. En la práctica, esto es necesario, por ejemplo, para la agrupación en clústeres y en algunos algoritmos de aprendizaje automático.
Analíticamente, cualquier normalización se reduce a la fórmula
Dónde - valor presente,
- el valor de los valores de compensación,
- el tamaño del intervalo que se va a convertir en "uno"
De hecho, todo se reduce al hecho de que el conjunto de valores original se cambia primero y luego se escala.
Ejemplos:
Minimax (MinMax) . El objetivo es convertir el conjunto original al rango [0..1]. Para él:
= , .
= — , .. “” .
. — 0 1.
= , .
— .
, .
, , “” . .
, - . , . , , . , . , — . , , , , *
* — , , ( ), , .
, — .
1 —
— .. , , 0 “” .
? « » . .
№ 1 — , .
, “ ” , , — , . ( ). ( ) .
, , .
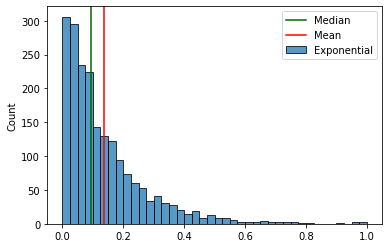
:
. “” .
, , , . .
2 —
. .
. , , [-1..1], . [-1..1], — [-1..100], , . .
. . , “”.
( ):

( ) , .
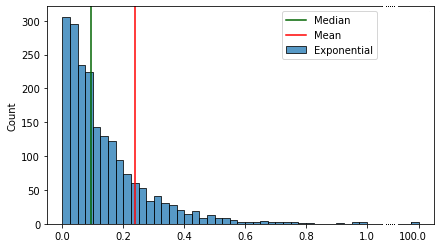
, () “”, .

— ( ). , “” .
75- 25- — . .. , “” 50% . “” / .
— “”, “” .
№ 2 — “” .
— .
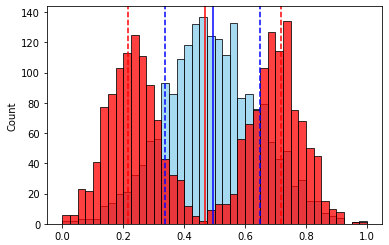
( ).

- “” . , , “”.
. .. . — 1.
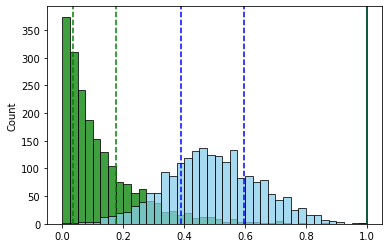
, , , № 3 — . ( ) .
, , . 2-
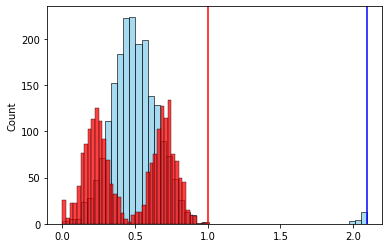
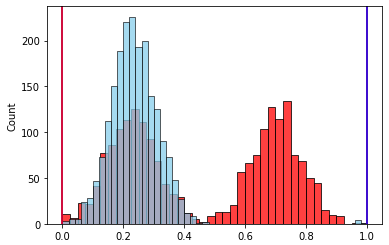
, , . .
, “-”. — .
— , . , . , , , , ? .
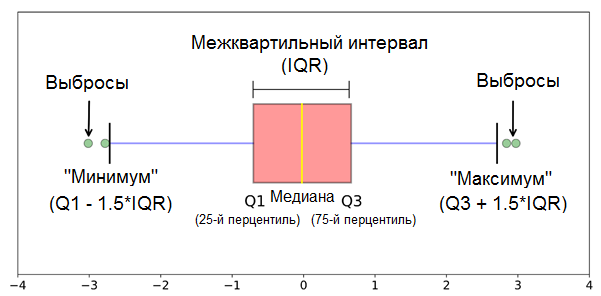
, . , “” , 1,5 (IQR) .*
* — ( .) 1,5 3 — .
.
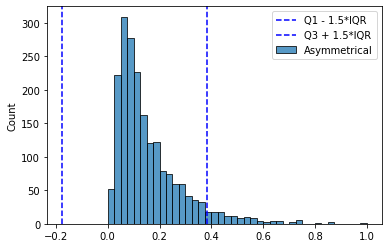
— - , .
. (, , ) “” — 7%. (3 * IQR) — . . .. .
, . “ ” (1,5 * IQR) , . , - “” .
(Mia Hubert and Ellen Vandervieren) 2007 . “An Adjusted Boxplot for Skewed Distributions”.
“ ” , 1,5 * IQR.
“ ” medcouple (MC), :
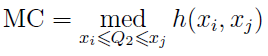
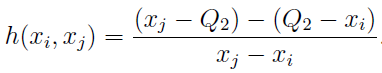
“ ” , , , 1,5 * IQR — 0,7%
:
:

:
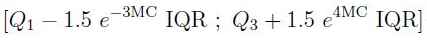
. .
, , :
- , , .
- .
- () — , , [0..1]
… — Mia Hubert Ellen Vandervieren
. .
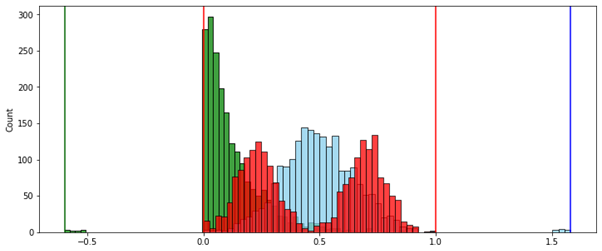
, ( ) (MinMax — ).
№ 1 — . . , “” .
:
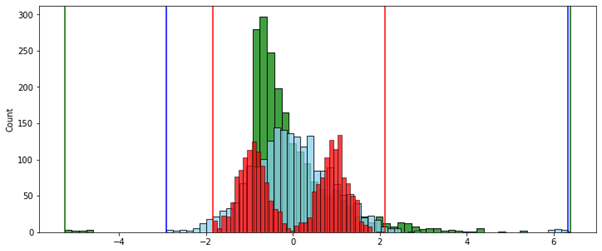
( ):

:

, — , , .
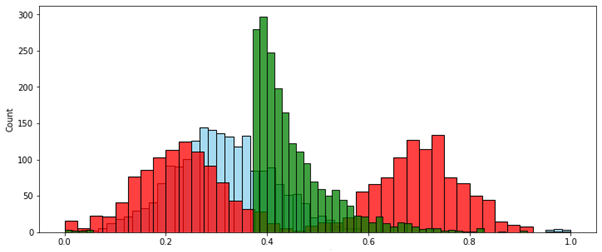
№ 2 — . [0..1]. , , .
MinMax ( ):
:
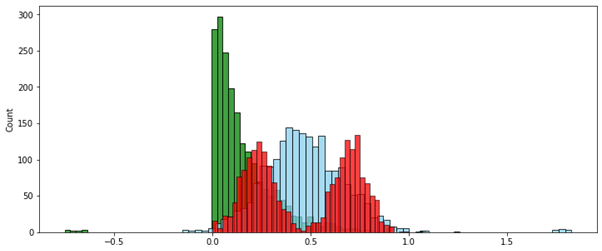
. -, , — .. 0 1.
, “” [0..1], , — , , , . .
* * *
Finalmente, para tener la oportunidad de sentir este método con sus manos, puede probar mi clase de demostración AdjustedScaler desde aquí .
No está optimizado para trabajar con una gran cantidad de datos y solo funciona con pandas DataFrame, pero para prueba, experimentación o incluso un espacio en blanco para algo más serio, es bastante adecuado. Intentalo.