
A principios de este año, Tenzor celebró una reunión en la ciudad de Ivanovo, en la que hice una presentación sobre experimentos con pruebas de fuzzing de la interfaz. Aquí hay una transcripción de este informe.
¿Cuándo reemplazarán los monos a todos los controles de calidad? ¿Es posible abandonar las pruebas manuales y las pruebas automáticas de la interfaz de usuario y reemplazarlas con fuzzing? ¿Cómo sería un diagrama de estado y transición completo para una aplicación TODO simple? Un ejemplo de implementación y cómo funciona tal fuzzing más abajo del corte.
¡Hola! Mi nombre es Sergey Dokuchaev. Durante los últimos 7 años he estado haciendo pruebas en todas sus formas en Tenzor.

Contamos con más de 400 personas responsables de la calidad de nuestros productos. 60 de ellos están dedicados a la automatización, la seguridad y las pruebas de rendimiento. Para admitir decenas de miles de pruebas E2E, monitorear indicadores de rendimiento de cientos de páginas e identificar vulnerabilidades a escala industrial, debe utilizar herramientas y métodos que se hayan probado con el tiempo y se hayan probado en batalla.

Y, por regla general, hablan de tales casos en conferencias. Pero además de esto, hay muchas cosas interesantes que aún son difíciles de aplicar a escala industrial. Eso es interesante y hablemos de ello.

En la película "The Matrix" en una de las escenas Morpheus le ofrece a Neo elegir una pastilla roja o azul. Thomas Anderson trabajó como programador y recordamos la elección que tomó. Si fuera un probador notorio, habría devorado ambas tabletas para ver cómo se comportaría el sistema en condiciones no estándar.
La combinación de pruebas manuales y autotest se ha convertido en algo casi estándar. Los desarrolladores saben mejor cómo funciona su código y escriben pruebas unitarias, los probadores funcionales verifican las funciones nuevas o que cambian con frecuencia, y toda la regresión va a varias pruebas automáticas.
Sin embargo, al crear y mantener autotests, de repente no hay mucho trabajo automático y mucho trabajo manual:
- Necesita averiguar qué y cómo probar.
- Necesita encontrar los elementos en la página, introducir los localizadores necesarios en Objetos de página.
- Escribe y depura el código.
- — . / , , ROI .
Afortunadamente, no hay dos o tres tabletas en el mundo de las pruebas. Y toda una dispersión: pruebas semánticas, métodos formales, pruebas de fuzzing, soluciones basadas en IA. E incluso más combinaciones.

La afirmación de que cualquier mono que escriba en una máquina de escribir durante un tiempo infinitamente largo podrá escribir cualquier texto dado por adelantado se ha quedado en prueba. Suena bien, podemos hacer que un programa haga clic sin cesar en la pantalla en lugares aleatorios y eventualmente podemos encontrar todos los errores.
Digamos que hicimos tal TODO y queremos probarlo. Tomamos un servicio o herramienta adecuada y vemos a los monos en acción:
por el mismo principio, mi gato de alguna manera, acostado en el teclado, rompió irrevocablemente la presentación y tuvo que volver a hacerlo:

Es conveniente cuando, después de 10 acciones, la aplicación lanza una excepción. Aquí nuestro mono entiende inmediatamente que ha ocurrido un error, y podemos entender de los registros al menos aproximadamente cómo se repite. ¿Qué pasa si el error se produjo después de 100.000 clics aleatorios y parece una respuesta válida? La única ventaja significativa de este enfoque es la máxima simplicidad: presionas un botón y listo.

Lo opuesto a este enfoque son los métodos formales.

Esta es una fotografía de Nueva York en 2003. Uno de los lugares más brillantes y concurridos del planeta, Times Square, está iluminado solo por los faros de los automóviles que pasan. Ese año, millones de personas en Canadá y Estados Unidos se encontraron en la Edad de Piedra durante tres días debido al cierre de una planta de energía en cascada. Una de las razones clave del incidente fue un error de condición de carrera en el software.
Los sistemas críticos para errores requieren un enfoque especial. Los métodos que no se basan en la intuición y las habilidades, sino en las matemáticas, se denominan formales. Y a diferencia de las pruebas, le permiten probar que no hay errores en el código. Los modelos son mucho más difíciles de crear que de escribir el código que se supone que deben probar. Y su uso se parece más a demostrar un teorema en una conferencia sobre cálculo.

La diapositiva muestra una parte del modelo del algoritmo de apretón de manos escrito en el lenguaje TLA +. Creo que es obvio para todos que usar estas herramientas al revisar moldes en el sitio es comparable a construir un Boeing 787 para probar las propiedades aerodinámicas de una planta de maíz.

Incluso en las industrias médica, aeroespacial y bancaria tradicionalmente propensas a errores, este tipo de pruebas es muy poco común. Pero el enfoque en sí mismo es insustituible si el costo de cualquier error se calcula en millones de dólares o en vidas humanas.
Las pruebas difusas se ven ahora con mayor frecuencia en el contexto de las pruebas de seguridad. Y tomaremos un esquema típico que demuestra este enfoque de la guía OWASP :

Aquí tenemos un sitio que necesita ser probado, hay una base de datos con datos de prueba y herramientas con las que enviaremos los datos especificados al sitio. Los vectores son cadenas ordinarias que se obtuvieron empíricamente. Es más probable que estas cadenas conduzcan al descubrimiento de una vulnerabilidad. Es como las comillas que muchas personas colocan automáticamente en lugar de los números en la URL de la barra de direcciones.
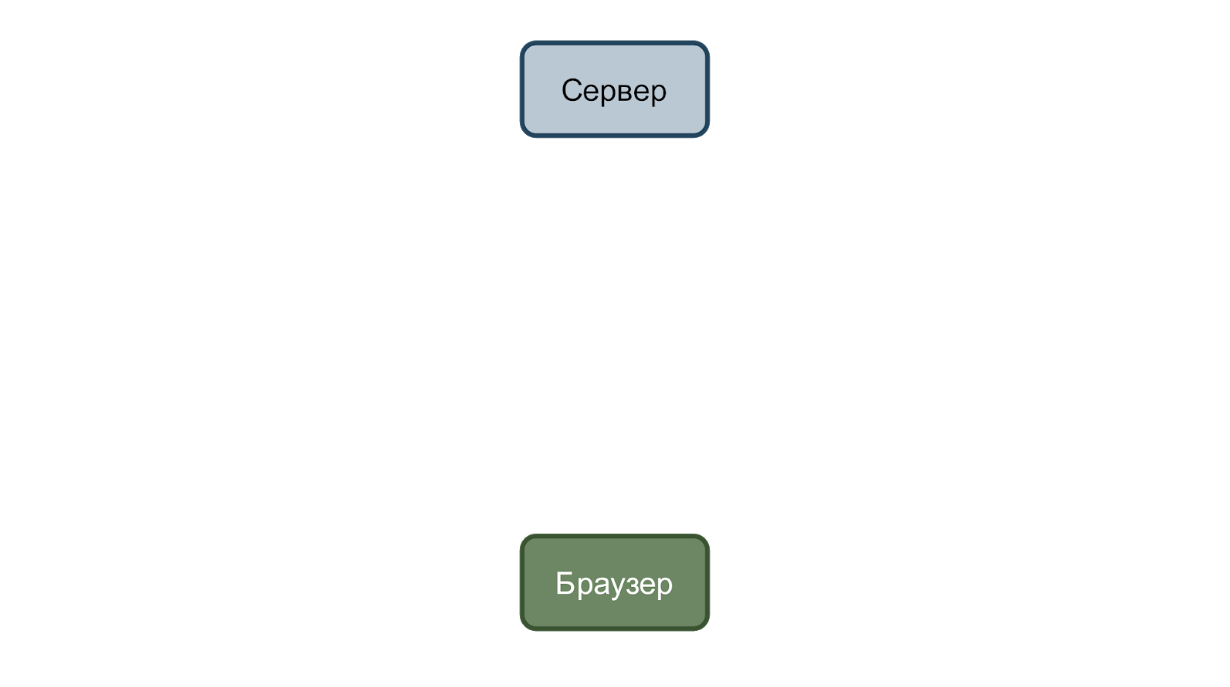
En el caso más simple, tenemos un servicio que acepta solicitudes y un navegador que las envía. Considere un caso con el cambio de la fecha de nacimiento del usuario.

El usuario ingresa una nueva fecha y hace clic en el botón "Guardar". Se envía una solicitud al servidor con datos en formato json.
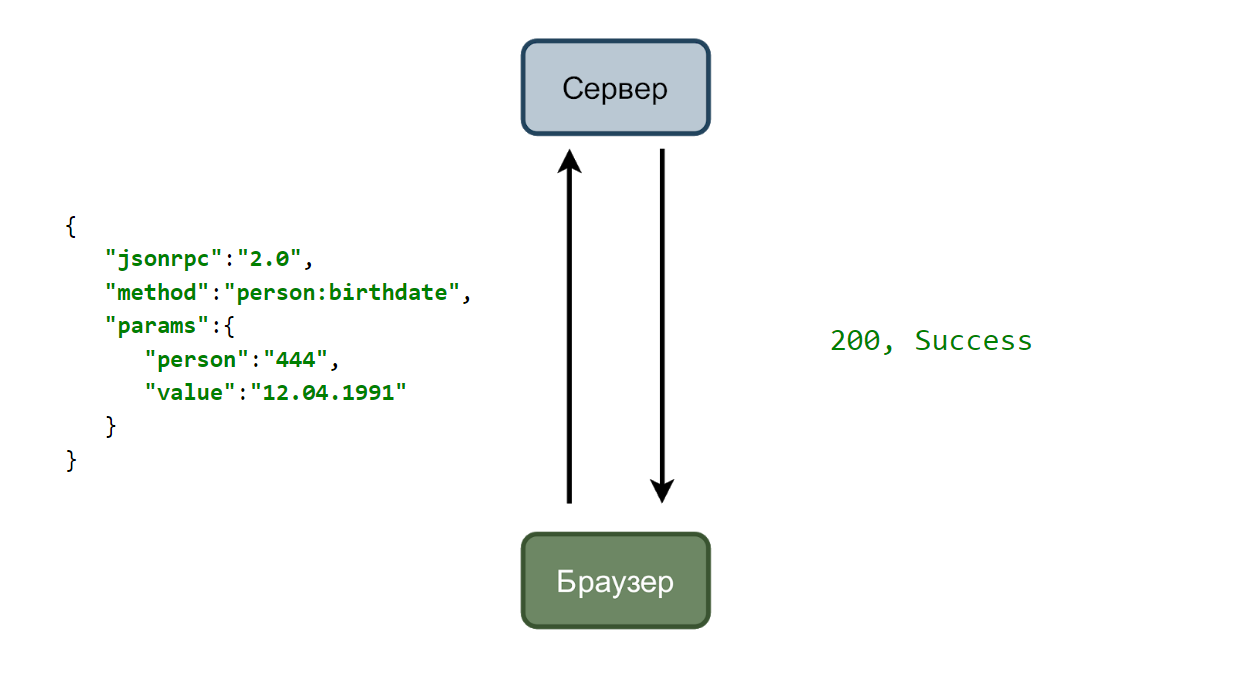
Y si todo va bien, entonces el servicio responde con el código doscientos.

Es conveniente trabajar con json mediante programación y podemos enseñar a nuestra herramienta de fuzzing a encontrar y determinar fechas en los datos transmitidos. Y comenzará a sustituirlos por varios valores, por ejemplo, transmitirá un mes inexistente.

Y si recibimos una excepción en lugar de un mensaje sobre una fecha no válida en respuesta, corregimos el error.
Difundir una API no es difícil. Aquí tenemos los parámetros transmitidos en json, aquí enviamos una solicitud, recibimos una respuesta y la analizamos. ¿Qué pasa con la GUI?
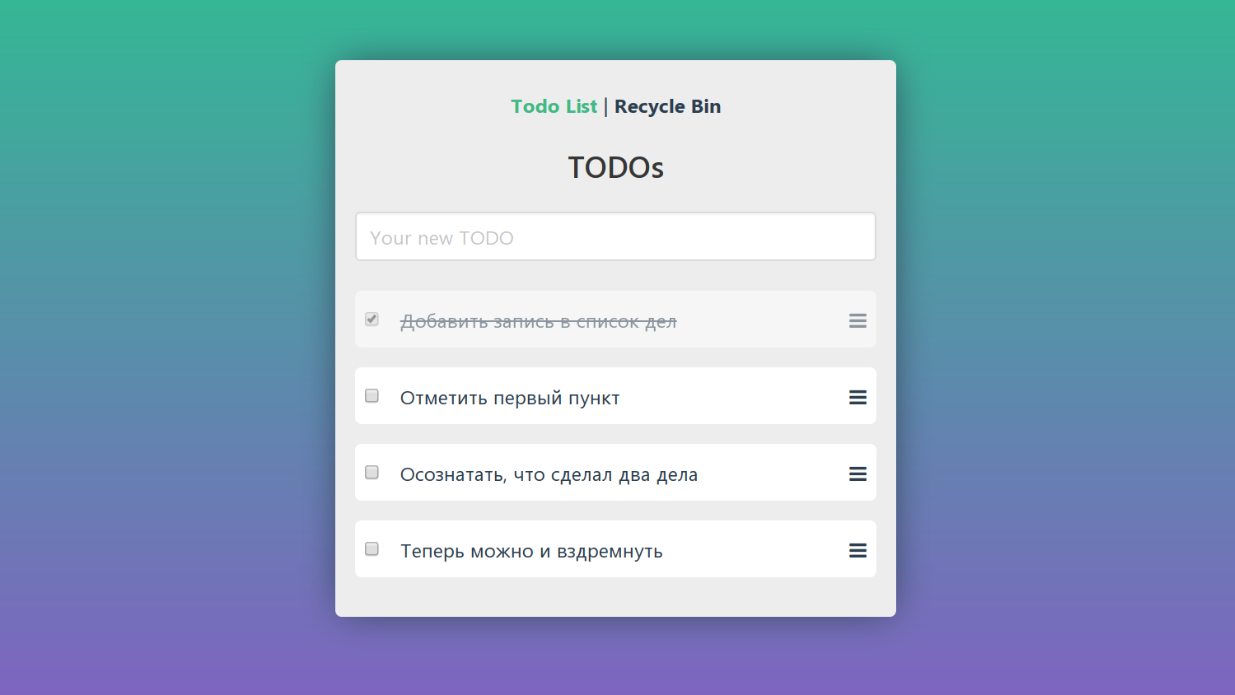
Echemos un vistazo al programa del ejemplo de prueba ficticia nuevamente. En él, puede agregar nuevas tareas, marcar como completadas, eliminar y ver la cesta.
Si nos ocupamos de la descomposición, entonces veremos que la interfaz no es un monolito único, también consta de elementos separados:
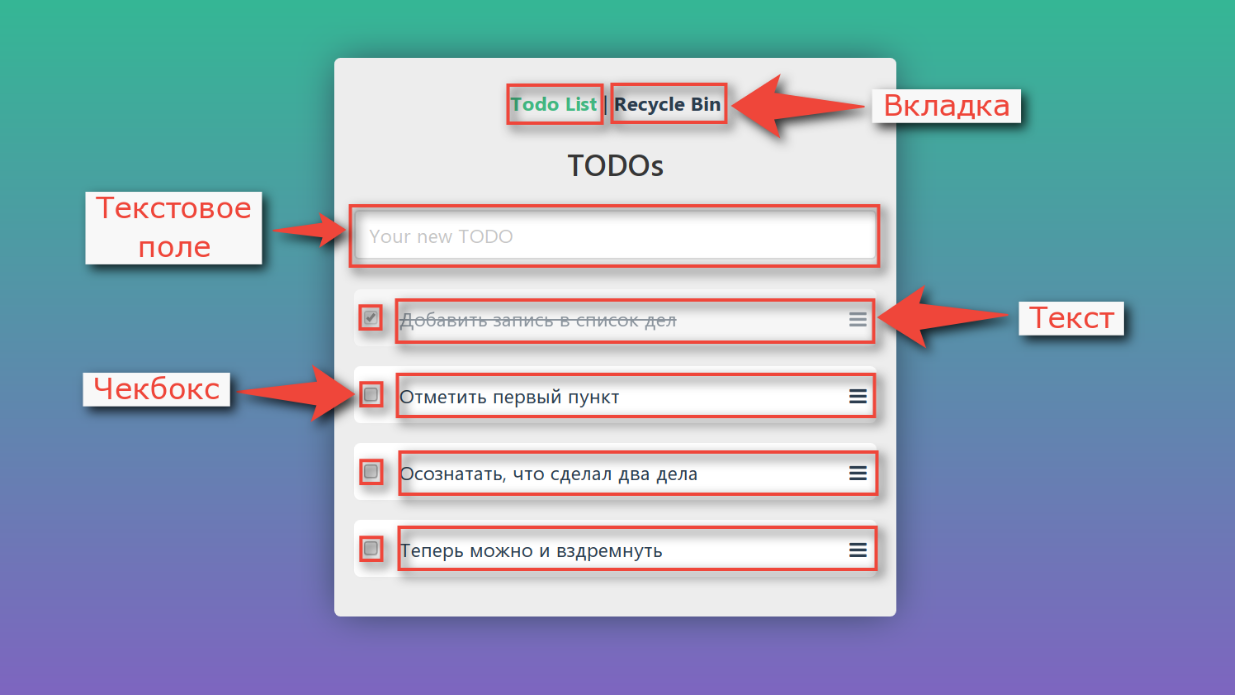
No hay mucho que podamos hacer con cada uno de los controles. Tenemos un mouse con dos botones, una rueda y un teclado. Puede hacer clic en un elemento, mover el cursor del mouse sobre él, puede ingresar texto en los campos de texto.
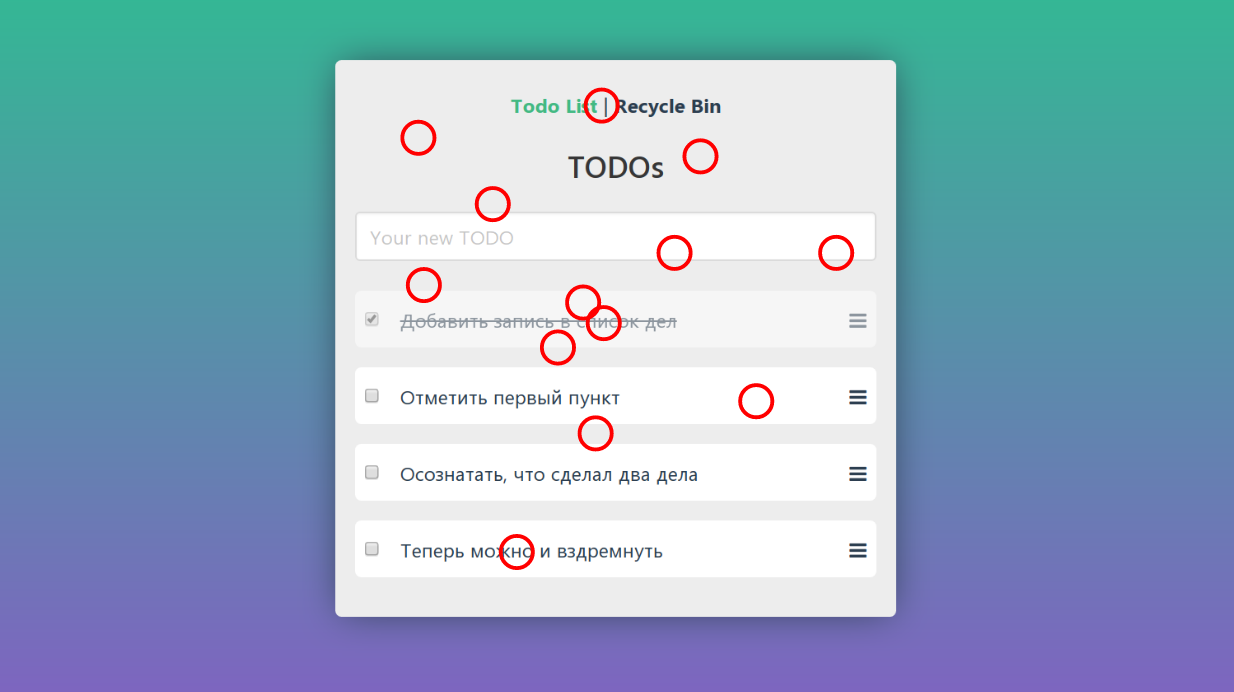
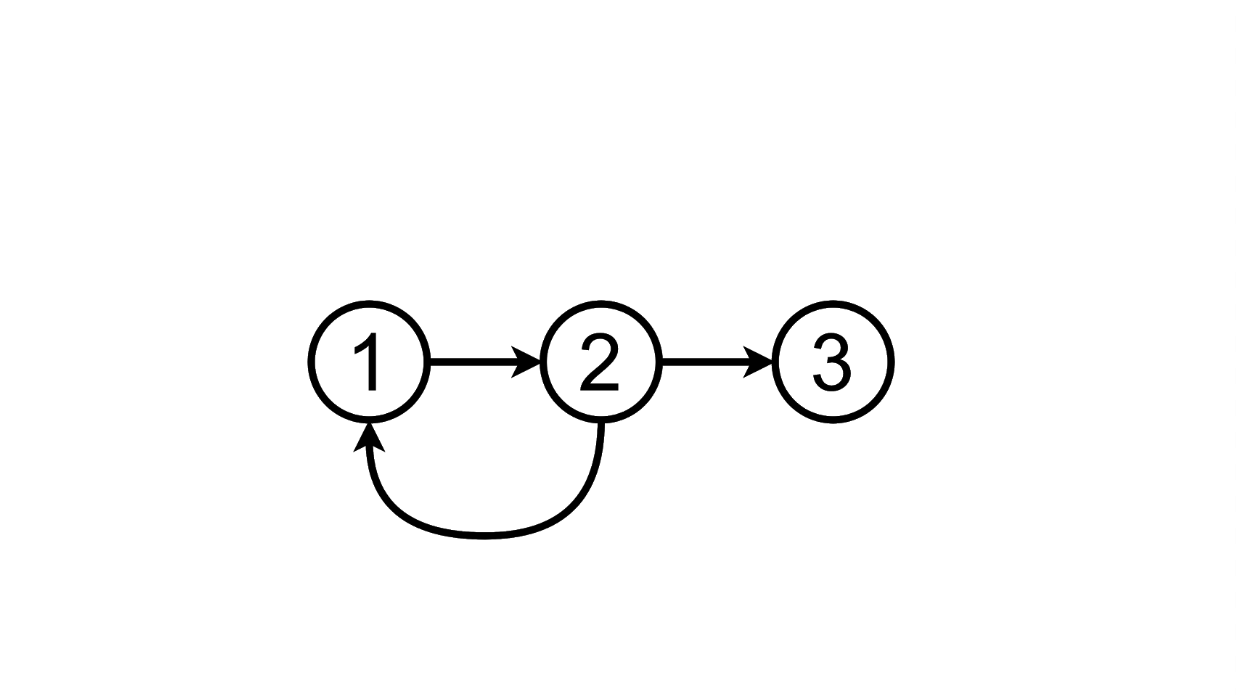
Si ingresamos algún texto en el campo de texto y presionamos Enter, entonces nuestra página irá de un estado a otro:
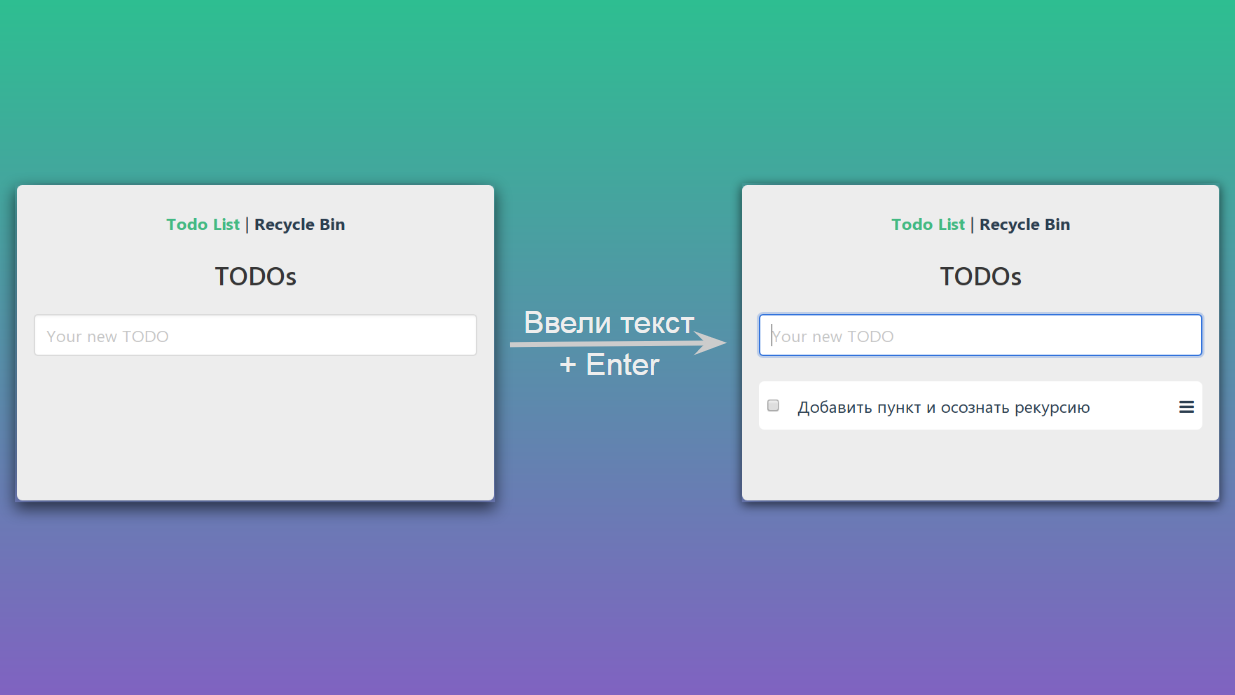
Esquemáticamente se puede representar así:

Desde este estado podemos ir al tercero agregando otra tarea a la lista:
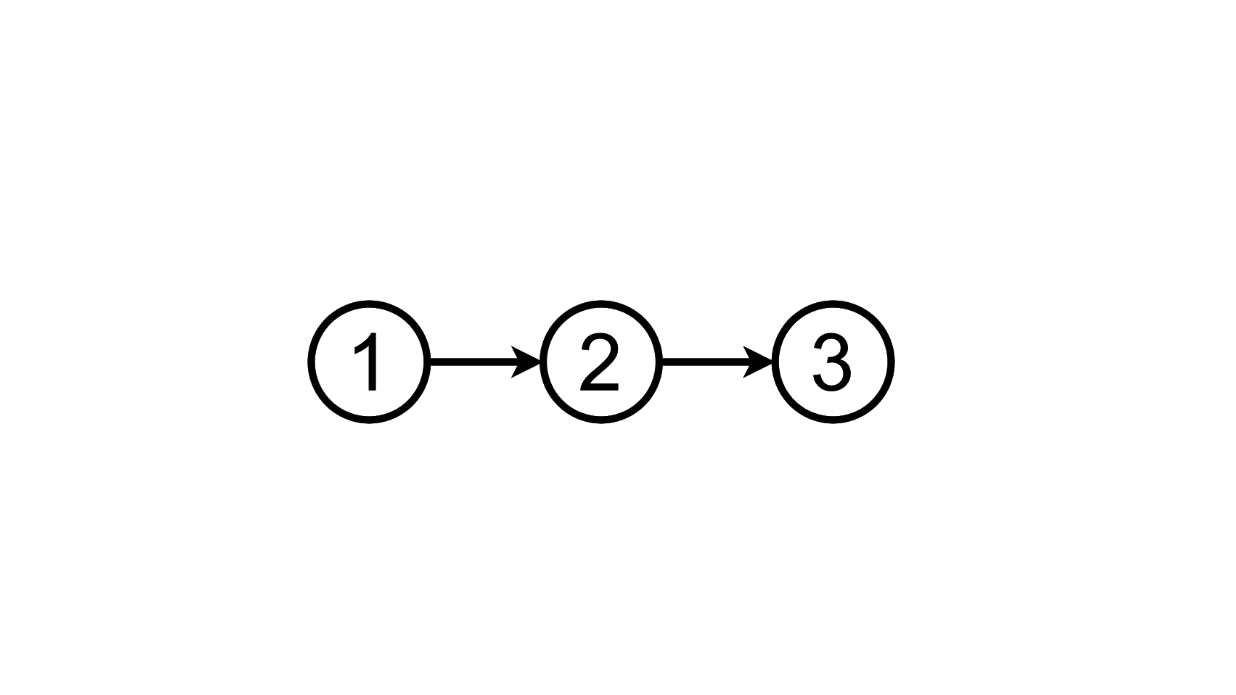
Y podemos eliminar el agregado tarea, volviendo al primer estado:
O haga clic en la etiqueta TODOs y permanezca en el segundo estado:
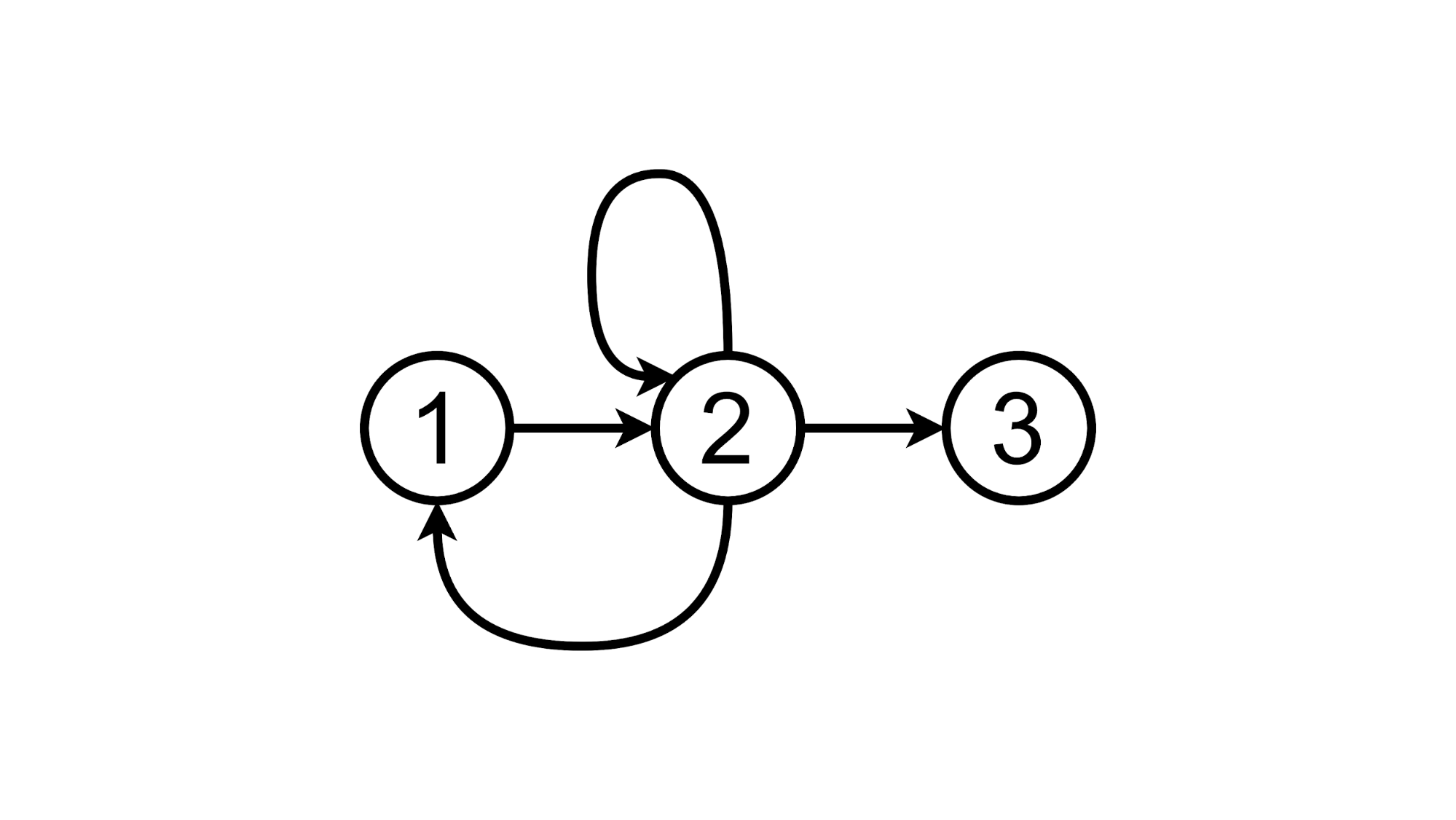
Y ahora intentemos implementar la Prueba de concepto de este enfoque.

Para trabajar con el navegador, tomaremos un controlador cromado, trabajaremos con el diagrama de estado y las transiciones a través de la biblioteca de Python NetworkX, y dibujaremos a través de yEd.

Lanzamos el navegador, creamos una instancia de grafo, en la que puede haber muchas conexiones con diferentes direcciones entre dos vértices. Y abrimos nuestra aplicación.

Ahora necesitamos describir el estado de la aplicación. Debido al algoritmo de compresión de imágenes, podemos utilizar el tamaño de la imagen PNG como identificador de estado y, mediante el método __eq__, implementar una comparación de este estado con otros. A través del atributo iterado, registramos que se han pulsado todos los botones, se han introducido valores en todos los campos en este estado, para excluir el reprocesamiento.

Escribimos un algoritmo básico que evitará toda la aplicación. Aquí arreglamos el primer estado en el gráfico, en el bucle hacemos clic en todos los elementos en este estado y arreglamos los estados resultantes. A continuación, seleccione el siguiente estado sin procesar y repita los pasos.

Al realizar un fuzzing del estado actual, debemos volver cada vez a este estado desde uno nuevo. Para hacer esto, usamos la función nx.shortest_path, que devolverá una lista de elementos en los que es necesario hacer clic para pasar del estado base al actual.
Para esperar el final de la respuesta de la aplicación a nuestras acciones, la función de espera utiliza la API de tareas largas de red, que muestra si JS está ocupado con algún trabajo.
Volvamos a nuestra aplicación. El estado inicial es el siguiente:
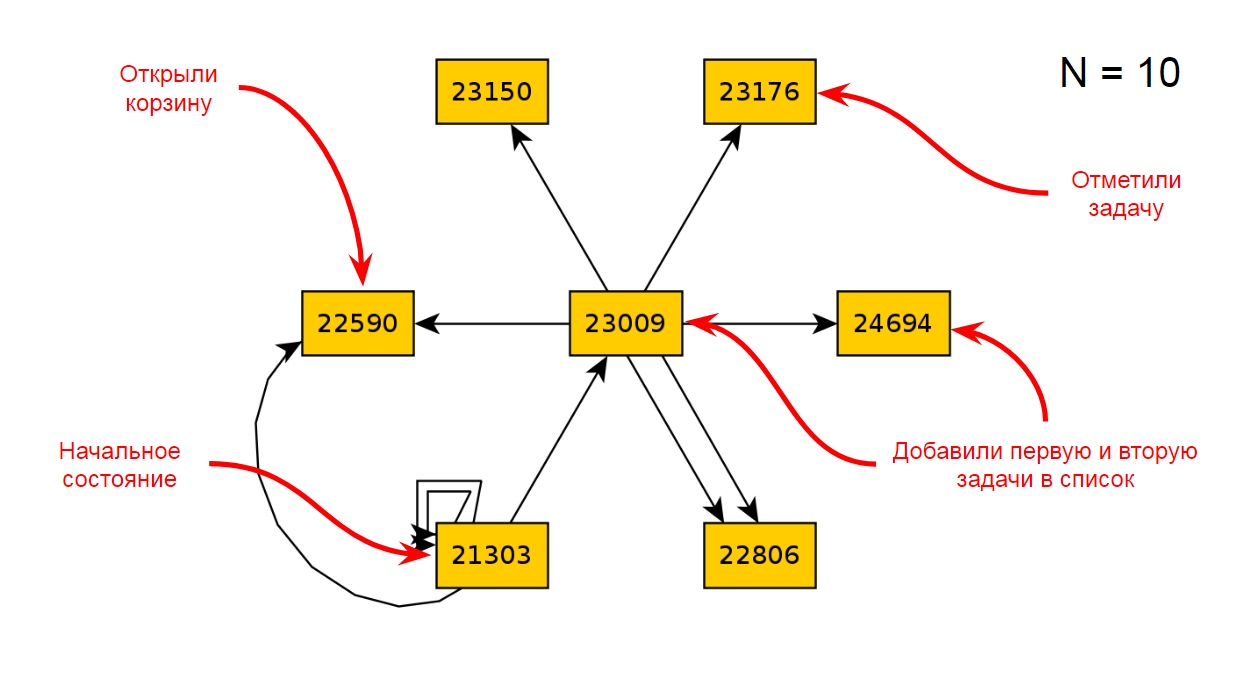
Después de diez iteraciones de la aplicación, obtendremos el siguiente diagrama de estados y transiciones:
Después de 22 iteraciones, este es el siguiente:
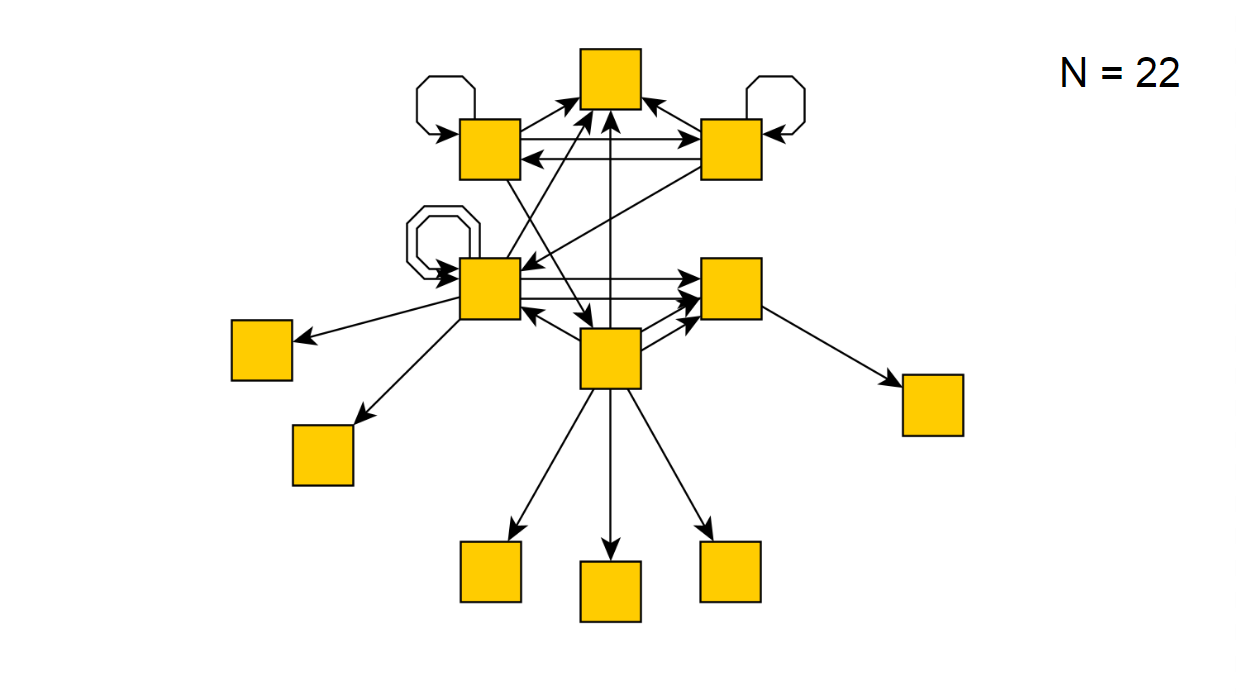
Si ejecutamos nuestro script durante varias horas, de repente informará que ha omitido todos los estados posibles y recibió el siguiente diagrama:

Entonces, con una aplicación de demostración simple lo hicimos. ¿Y qué sucede si configura este script en una aplicación web real? Y habrá caos:
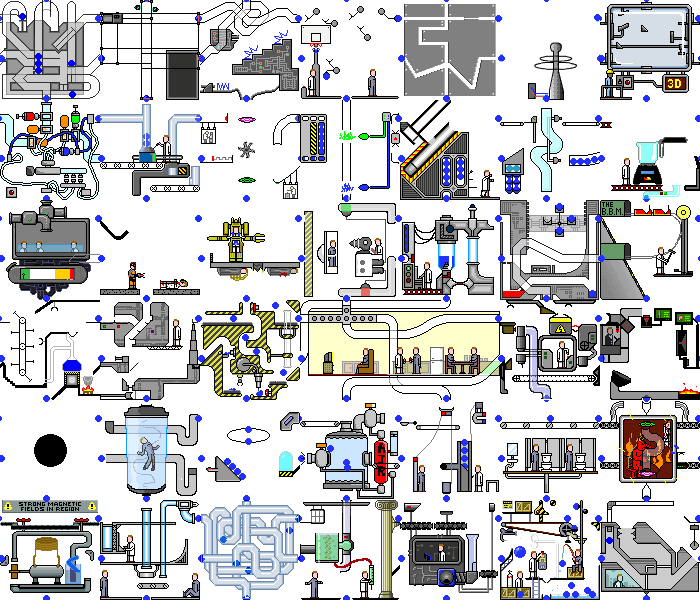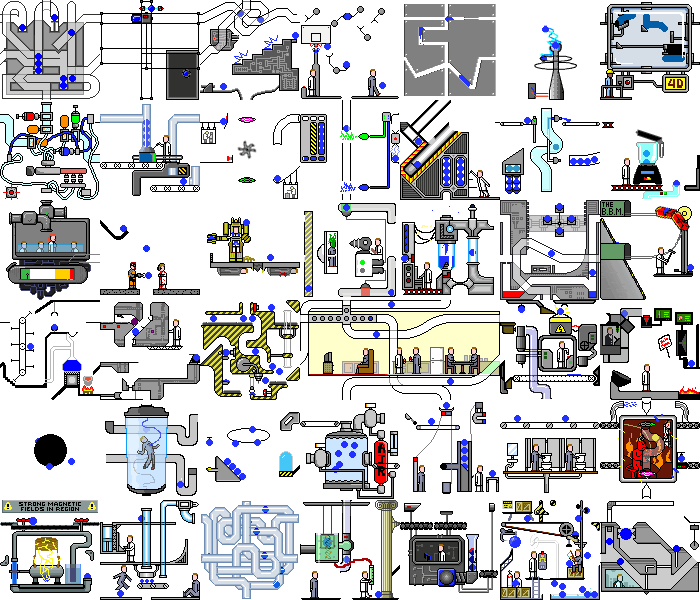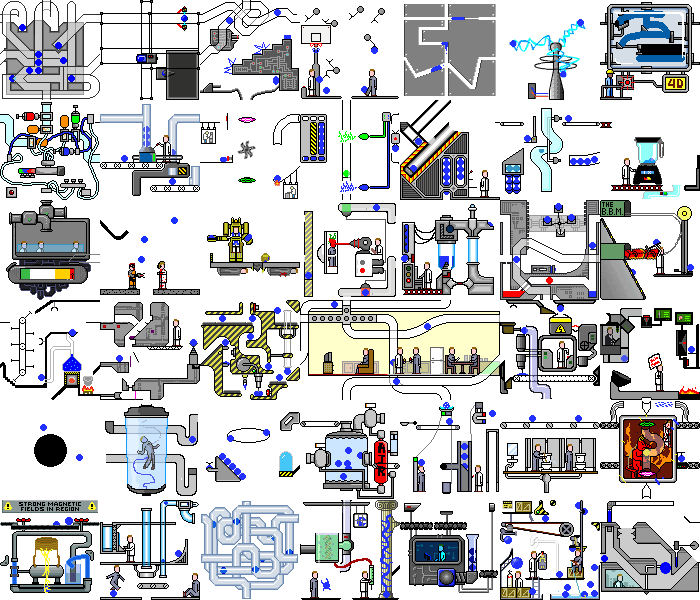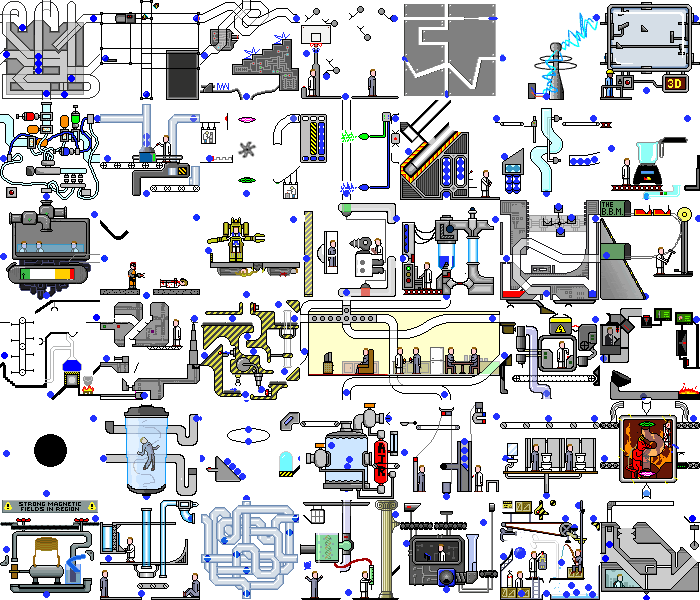
no solo ocurren cambios en el backend, la página en sí se redibuja constantemente al reaccionar a temporizadores o eventos, al realizar las mismas acciones, podemos obtener diferentes estados. Pero incluso en tales aplicaciones, puede encontrar piezas de funcionalidad que nuestro script puede manejar sin modificaciones significativas.
Vamos a probarloPágina de autenticación VLSI:

Y para ello, resultó lo suficientemente rápido como para construir un diagrama completo de estados y transiciones:
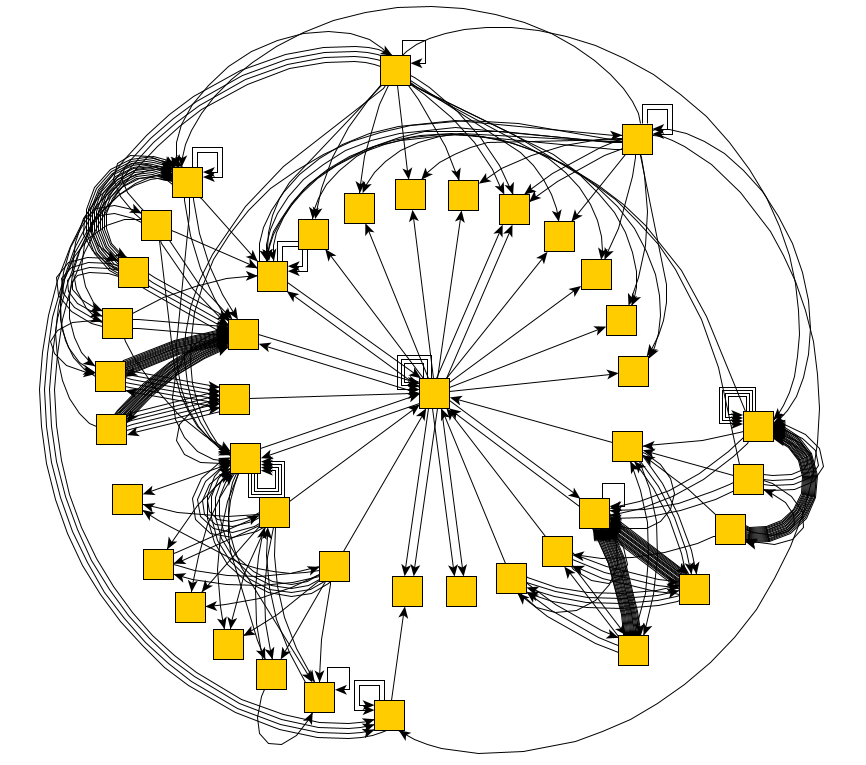

¡Excelente! Ahora podemos recorrer todos los estados de la aplicación. Y puramente en teoría, encontrar todos los errores que dependen de las acciones. Pero, ¿cómo se enseña a un programa a comprender que hay un error delante de él?
En las pruebas, las respuestas del programa siempre se comparan con un cierto estándar llamado oráculo. Pueden ser especificaciones técnicas, maquetas, análogos de programas, versiones anteriores, experiencia de probadores, requisitos formales, casos de prueba, etc. También podemos usar algunos de estos oráculos en nuestra herramienta.

Consideremos el último patrón "antes era diferente". Los autotests se dedican a las pruebas de regresión.
Volvamos al gráfico después de 10 iteraciones de TODO:
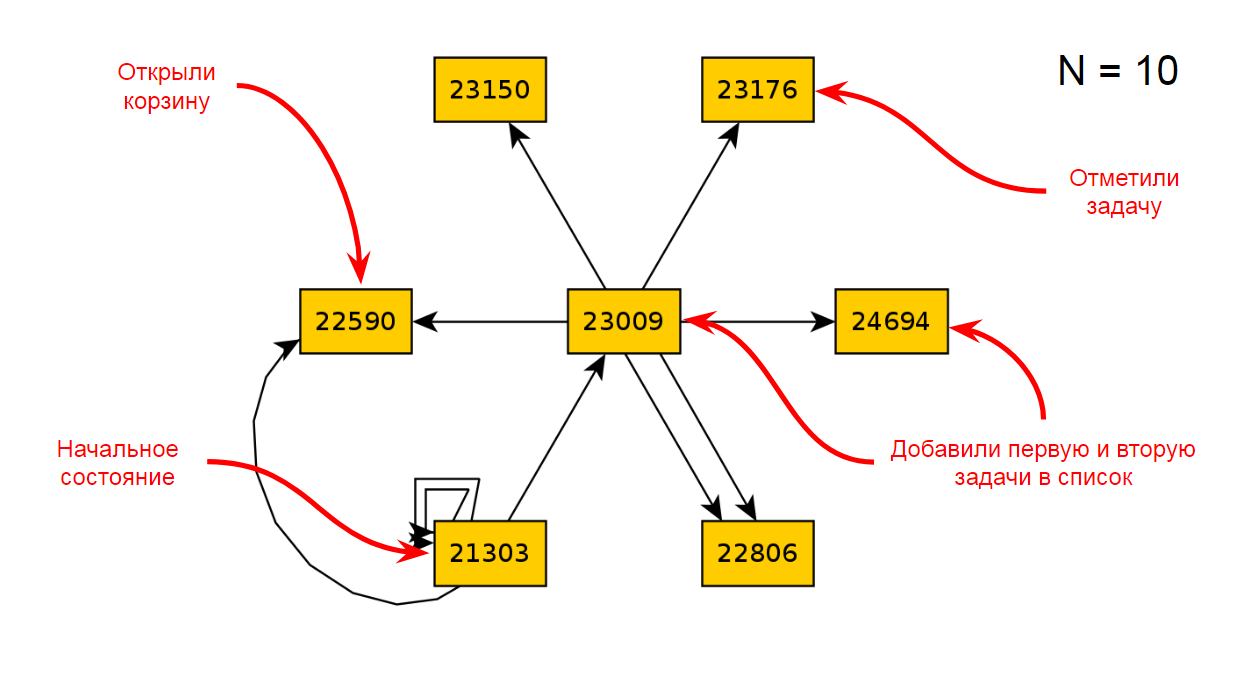
Vamos a romper el código que es responsable de abrir el carrito de compras y ejecutar 10 iteraciones nuevamente:
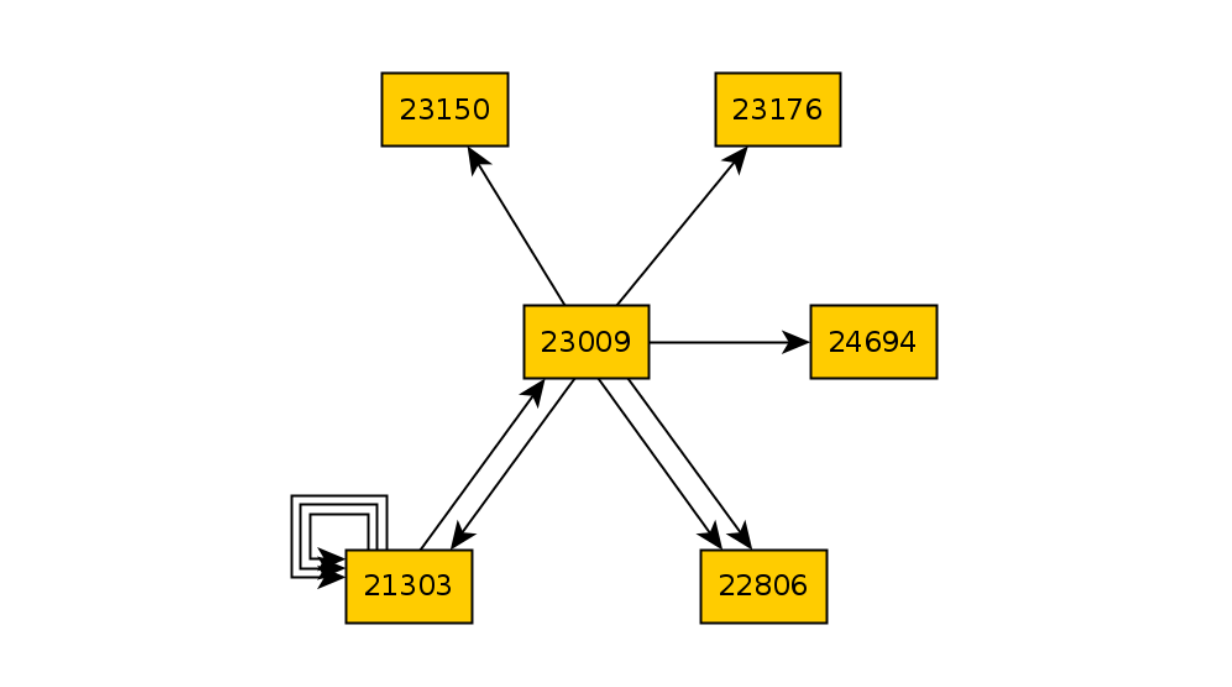
Y luego comparamos los dos gráficos y encontramos la diferencia en los estados:
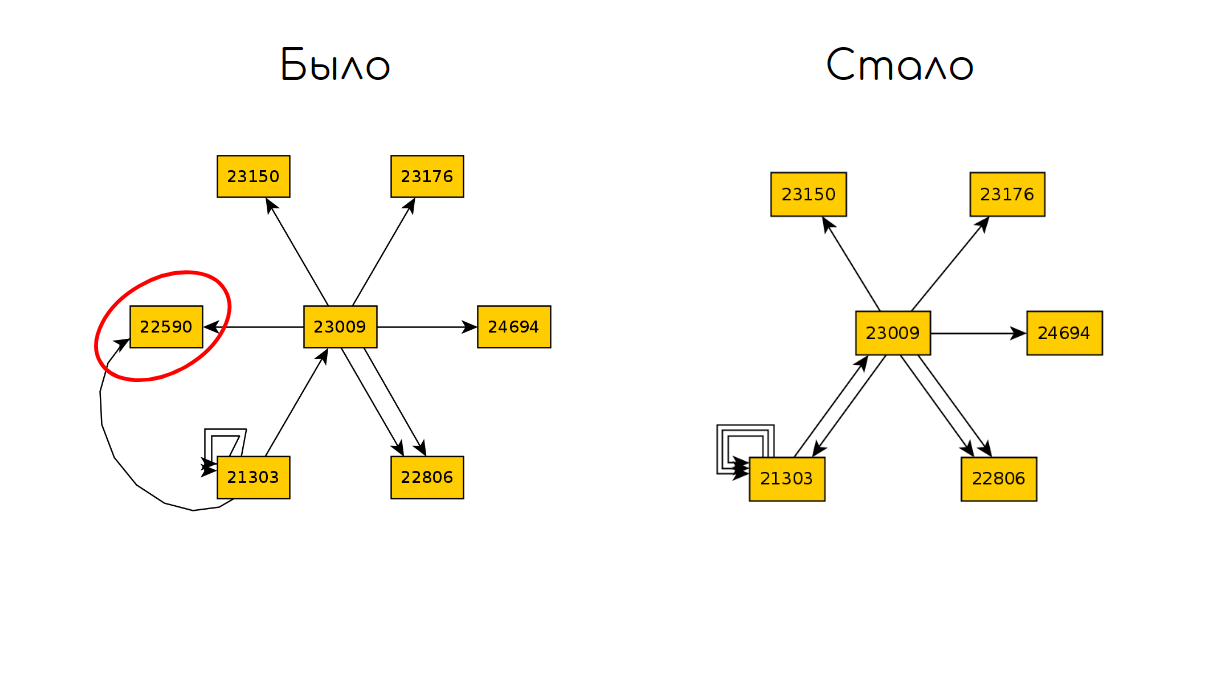
Podemos resumir para este enfoque:

Tal como está, esta técnica se puede usar para probar una pequeña aplicación e identificar errores obvios o de regresión. Para que la técnica despegue para aplicaciones grandes con GUI inestables, se requieren mejoras significativas.
Todo el código fuente y una lista de materiales usados se pueden encontrar en el repositorio: https://github.com/svdokuchaev/venom . Para aquellos que quieran comprender el uso de fuzzing en las pruebas, les recomiendo The Fuzzing Book . Allí, en una de las partes, se describe el mismo enfoque para difuminar formularios html simples.
