
Esta es una traducción del segundo artículo de una serie sobre privacidad diferencial.
La semana pasada, en el primer artículo de esta serie, " Privacidad diferencial: análisis de datos mientras se mantiene la confidencialidad (Introducción a la serie) ", analizamos los conceptos básicos y los usos de la privacidad diferencial. Hoy consideraremos posibles opciones para construir sistemas, dependiendo del modelo de amenaza esperado.
Implementar un sistema que cumpla con los principios de privacidad diferencial no es una tarea trivial. Como ejemplo, en nuestra próxima publicación veremos un programa Python simple que implementa la adición de ruido de Laplace directamente en una función que procesa datos sensibles. Pero para que esto funcione, necesitamos recopilar todos los datos necesarios en un servidor.
¿Y si piratean el servidor? En este caso, la privacidad diferencial no nos ayudará, ¡porque solo protege los datos obtenidos como resultado del trabajo del programa!
Al implementar sistemas basados en los principios de privacidad diferencial, es importante considerar el modelo de amenaza: de qué oponentes queremos proteger el sistema. Si este modelo incluye atacantes capaces de comprometer completamente un servidor con datos confidenciales, entonces debemos cambiar el sistema para que pueda resistir tales ataques.
Es decir, las arquitecturas de los sistemas que respetan la privacidad diferencial deben considerar tanto la privacidad como la seguridad . La privacidad controla lo que se puede recuperar de los datos devueltos por el sistema. Y la seguridad puede considerarse la tarea contraria: es el control del acceso a parte de los datos, pero no da ninguna garantía sobre su contenido.
Modelo de privacidad diferencial central
El modelo de amenaza más comúnmente utilizado en el trabajo de privacidad diferencial es el modelo de privacidad diferencial central (o simplemente "privacidad diferencial central").
El componente principal: el almacén de datos de confianza (curador de datos de confianza) . Cada fuente le envía sus datos confidenciales y los recopila en un solo lugar (por ejemplo, en un servidor). Un repositorio es confiable si asumimos que procesa nuestros datos confidenciales por sí solo, no los transfiere a nadie y no puede ser comprometido por nadie. En otras palabras, creemos que un servidor con datos sensibles no puede verse comprometido.
Como parte del modelo central, generalmente agregamos ruido a las respuestas a las consultas (veremos la implementación de Laplace en el próximo artículo). La ventaja de este modelo es la capacidad de agregar el menor valor de ruido posible, manteniendo así la máxima precisión permitida por los principios de privacidad diferencial. A continuación se muestra un diagrama del proceso. Hemos colocado una barrera de privacidad entre el almacén de datos confiable y el analista para que solo los resultados que cumplan con los criterios de privacidad diferencial especificados puedan salir. Por lo tanto, no se requiere que se confíe en el analista.
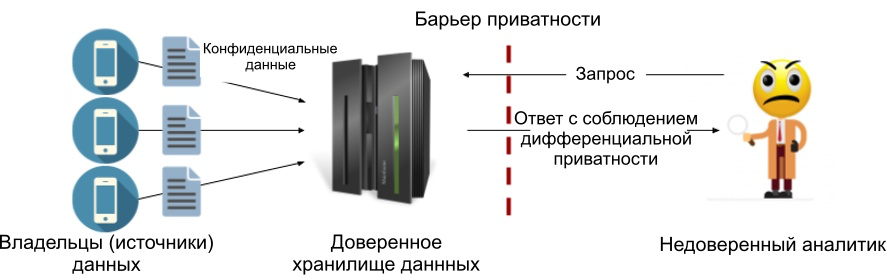
Figura 1: El modelo de privacidad diferencial central.
La desventaja del modelo central es que requiere una tienda confiable, y muchas de ellas no. De hecho, la falta de confianza en el consumidor de datos suele ser la razón principal para utilizar principios de privacidad diferencial.
Modelo de privacidad diferencial local
El modelo de privacidad diferencial local le permite deshacerse del almacén de datos de confianza: cada fuente de datos (o propietario de datos) agrega ruido a sus datos antes de transferirlos a la tienda. Esto significa que el almacenamiento nunca contendrá información sensible, lo que significa que no es necesario su poder notarial. La siguiente figura muestra el dispositivo del modelo local: en él, una barrera de privacidad se encuentra entre cada propietario de los datos y el almacenamiento (que puede ser de confianza o no).
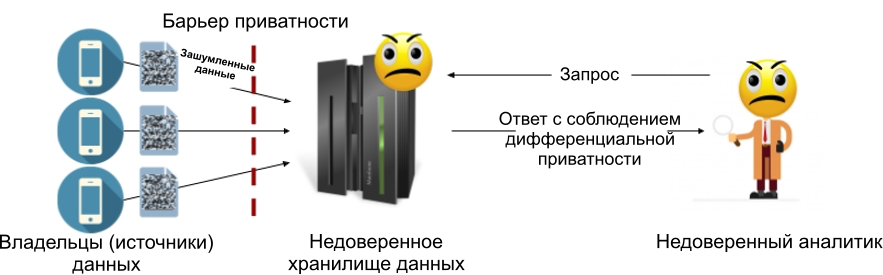
Figura 2: Modelo de privacidad diferencial local.
El modelo de privacidad diferencial local evita el problema principal del modelo central: si el almacén de datos se ve comprometido, los piratas informáticos solo tendrán acceso a datos ruidosos que ya cumplan con los requisitos de privacidad diferencial. Esta es la razón principal por la que se eligió el modelo local para sistemas como Google RAPPOR [1] y el sistema de recopilación de datos de Apple [2].
¿Pero en la otra mano? El modelo local es menos preciso que el central. En el modelo local, cada fuente agrega ruido de forma independiente para satisfacer sus propias condiciones de privacidad diferencial, de modo que el ruido total de todos los participantes es mucho mayor que el ruido en el modelo central.
En última instancia, este enfoque solo se justifica para consultas con una tendencia muy persistente (señal). Apple, por ejemplo, usa un modelo local para estimar la popularidad de los emoji, pero el resultado solo es útil para los emoji más populares (donde la tendencia es más pronunciada). Normalmente, este modelo no se utiliza para consultas más complejas, como las que utiliza el censo de EE. UU. [10] o el aprendizaje automático.
Modelos híbridos
Los modelos central y local tienen ventajas y desventajas, y ahora el principal esfuerzo es sacar lo mejor de ellos.
Por ejemplo, puede utilizar el modelo de barajado implementado en el sistema Prochlo [4]. Contiene un almacén de datos que no es de confianza, muchos propietarios de datos individuales y varios barajadores de confianza parcial.... Cada fuente primero agrega una pequeña cantidad de ruido a sus datos y luego lo envía al agitador, que agrega más ruido antes de enviarlo al almacén de datos. La conclusión es que es poco probable que los agitadores se "coluden" (o sean pirateados al mismo tiempo) con el almacén de datos o entre ellos, por lo que un poco de ruido agregado por las fuentes será suficiente para garantizar la privacidad. Cada mezclador puede manejar múltiples fuentes, al igual que el modelo central, por lo que una pequeña cantidad de ruido garantizará la privacidad del conjunto de datos resultante.
El modelo de agitador es un compromiso entre los modelos local y central: añade menos ruido que el local, pero más que el central.
También puede combinar la privacidad diferencial con la criptografía, como en el cálculo seguro multiparte (MPC) o el cifrado totalmente homomórfico (FHE). FHE permite cálculos con datos cifrados sin descifrarlos primero, y MPC permite que un grupo de participantes ejecute consultas de forma segura a través de fuentes distribuidas sin exponer sus datos. Cálculo de funciones privadas diferencialesEl uso de computación segura para criptografía (o simplemente segura) es una forma prometedora de lograr la precisión del modelo central con todos los beneficios de lo local. Además, en este caso, el uso de informática segura elimina la necesidad de tener un almacenamiento confiable. Un trabajo reciente [5] demuestra resultados alentadores de la combinación de MPC y privacidad diferencial, absorbiendo la mayoría de las ventajas de ambos enfoques. Es cierto que, en la mayoría de los casos, los cálculos seguros son varios órdenes de magnitud más lentos que los realizados localmente, lo que es especialmente importante para conjuntos de datos grandes o consultas complejas. La informática segura se encuentra actualmente en una fase de desarrollo activa, por lo que su rendimiento está aumentando rápidamente.
¿Entonces?
En el próximo artículo, veremos nuestra primera herramienta de código abierto para poner en práctica conceptos de privacidad diferencial. Veamos otras herramientas, tanto disponibles para principiantes como aplicables a bases de datos muy grandes como la Oficina del Censo de EE. UU. Intentaremos calcular los datos de población de acuerdo con los principios de privacidad diferencial.
Suscríbete a nuestro blog y no te pierdas la traducción del próximo artículo. Muy pronto.
Fuentes
[1] Erlingsson, Úlfar, Vasyl Pihur y Aleksandra Korolova. "Rappor: Respuesta ordinal agregable aleatoria que preserva la privacidad". En Actas de la conferencia ACM SIGSAC de 2014 sobre seguridad informática y de comunicaciones, págs. 1054-1067. 2014.
[2] Apple Inc. "Descripción técnica de la privacidad diferencial de Apple". Consultado el 31/7/2020. https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
[3] Garfinkel, Simson L., John M. Abowd y Sarah Powazek. "Problemas encontrados al implementar la privacidad diferencial". En Proceedings of the 2018 Workshop on Privacy in the Electronic Society, págs. 133-137. 2018.
[4] Bittau, Andrea, Úlfar Erlingsson, Petros Maniatis, Ilya Mironov, Ananth Raghunathan, David Lie, Mitch Rudominer, Ushasree Kode, Julien Tinnes y Bernhard Seefeld. "Prochlo: gran privacidad para la analítica entre la multitud". En Actas del 26º Simposio sobre principios de sistemas operativos, págs. 441-459. 2017.
[5] Roy Chowdhury, Amrita, Chenghong Wang, Xi He, Ashwin Machanavajjhala y Somesh Jha. "Criptas: Privacidad diferencial asistida por criptografía en servidores que no son de confianza". En Actas de la Conferencia Internacional ACM SIGMOD 2020 sobre Gestión de Datos, págs. 603-619. 2020.