
Algunas palabras sobre los sistemas de recomendación
Seguramente, todos los conocieron más de una vez. Los sistemas de recomendación son programas y servicios que intentan predecir lo que podría ser interesante / necesario / útil para un usuario en particular y mostrarles esto. “¿Te gustan estas zapatillas para correr? Es posible que también necesite una cazadora, un monitor de frecuencia cardíaca y 15 artículos deportivos más " . En los últimos años, las marcas se han mostrado muy activas en la introducción de sistemas de recomendación en su trabajo, ya que tanto el vendedor como el comprador se "benefician" de esta decisión. Los consumidores reciben una herramienta que les ayuda a elegir entre una variedad infinita de bienes y servicios en poco tiempo, y el negocio aumenta las ventas y la audiencia.
¿Qué se nos ha dado?
Trabajé en un proyecto para una gran empresa global que brinda a sus clientes una solución de intercambio de carga SaaS o una plataforma de intercambio de carga.
Suena incomprensible, pero cómo sucede realmente: por un lado, están registrados en la plataforma usuarios que tienen cargas y que necesitan enviarlas a alguna parte. Colocan una aplicación como "Hay un lote de cosméticos decorativos, hay que llevarlo mañana de Amsterdam a Amberes".y están esperando una respuesta. Por otro lado, tenemos personas o empresas con camiones - transportistas de carga. Digamos que ya han realizado su vuelo semanal estándar, entregando yogures de París a Bruselas. Necesitan regresar y, para no ir con un camión vacío, encontrar algún tipo de carga para transportar en el camino de regreso. Para ello, los transportistas se dirigen a la plataforma de mi cliente y realizan la búsqueda (del buscador inglés), indicando la dirección y, posiblemente, el tipo de carga (o flete, del flete inglés), que es apta para un camión. El sistema recopila aplicaciones de los remitentes y se las muestra a los transportistas.
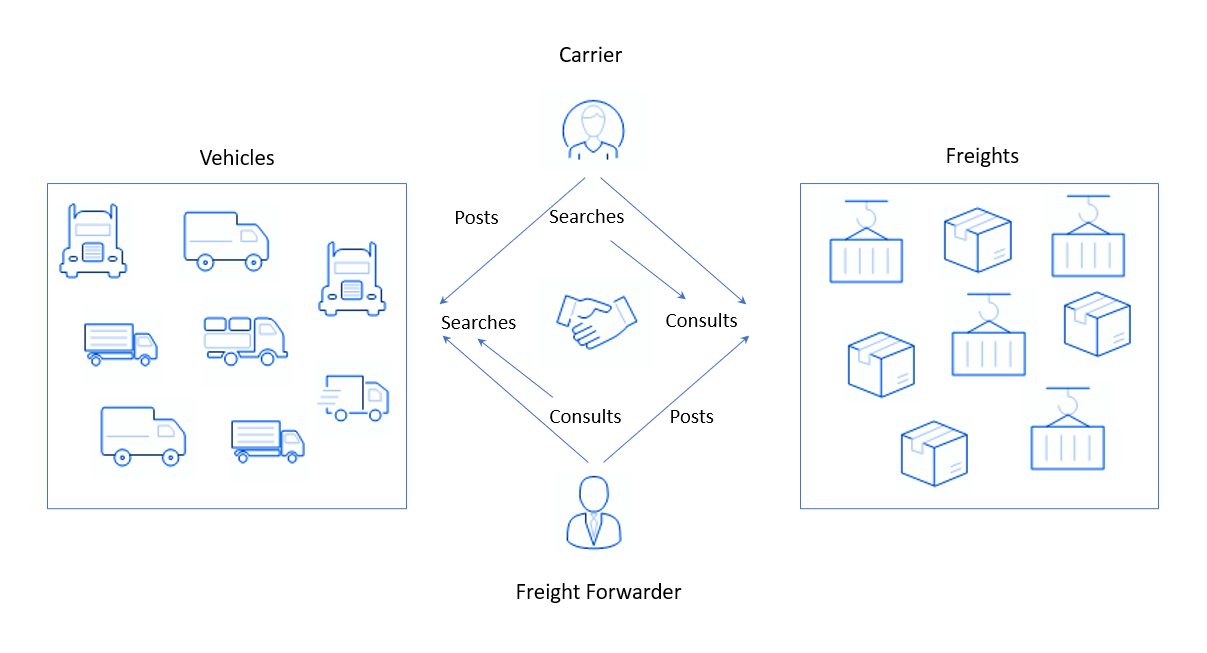
En tales plataformas, el equilibrio entre oferta y demanda es importante. Aquí, las mercancías tienen demanda de los transportistas de carga y los camiones de los transportistas, y como oferta, ocurre lo contrario: automóviles de transportistas y mercancías de empresas. El equilibrio es difícil de mantener por varias razones, por ejemplo:
- Comunicación cerrada entre el transportista y el cliente. Cuando un conductor a menudo solo trabaja con un cliente específico, no funciona bien en la plataforma. Si el remitente abandona el mercado, el servicio también puede perder al transportista, porque se convierte en cliente de otra empresa de logística.
- La presencia de mercancías que nadie quiere transportar. Esto sucede cuando las pequeñas empresas realizan pedidos de transporte, y luego no se actualizan y, en consecuencia, dejan rápidamente el número de activos.
La empresa quería mejorar la funcionalidad de su plataforma de intercambio de carga y aumentar la experiencia de usuario de los usuarios para que puedan ver todas las capacidades del sistema y una amplia gama de bienes, y además no perder la lealtad. Esto podría evitar que el público objetivo se cambie a un servicio competitivo y mostrar a los transportistas que se pueden encontrar pedidos adecuados no solo de las empresas con las que están acostumbrados a trabajar.
Teniendo en cuenta todos los deseos, me enfrenté a la tarea de desarrollar un sistema de recomendación que inmediatamente a la entrada de la plataforma mostrará a los transportistas la carga relevante actualmente disponible y adivinará qué quieren transportar y dónde. Este sistema debía integrarse en la plataforma de intercambio de mercancías existente.
¿Cómo "adivinaremos"?
Nuestro sistema de recomendaciones, como otros, trabaja en el análisis de los datos de los usuarios. Y hay varias fuentes en las que puede operar:
- Primero, abrir información sobre aplicaciones para el transporte de mercancías.
- En segundo lugar, la plataforma proporciona datos sobre el operador. Cuando el usuario suscribe un contrato con nuestros clientes, puede indicar cuántos camiones tiene y de qué tipo. Pero, lamentablemente, después de que estos datos no se actualicen. Y lo único en lo que podemos confiar es en el país del operador, ya que lo más probable es que no cambie.
- En tercer lugar, el sistema almacena el historial de búsquedas de los usuarios durante varios años: tanto las solicitudes más recientes como hace un año.
En la aplicación donde decidieron implementar el sistema de recomendación, ya existía un mecanismo de búsqueda de bienes por solicitudes anteriores. Por lo tanto, decidimos enfocarnos en identificar patrones o patrones por los cuales el usuario busca bienes para su transporte. Es decir, no recomendamos la carga, pero seleccionamos la dirección que es más adecuada para este usuario en la actualidad. Y ya encontraremos los productos utilizando el motor de búsqueda estándar.
En general, las búsquedas populares se basan en información geográfica y parámetros adicionales como el tipo de camión o el artículo que se transporta. Esto es bastante fácil de rastrear, porque estas preferencias apenas cambian. A continuación he proporcionado los datos de las solicitudes de uno de los usuarios durante 3 días. El orden de llenado es el siguiente: 1 columna - país de salida, 2 - país de destino, 3 - región de salida, 4 - región de destino.

Puede ver que este usuario tiene preferencias específicas en países y provincias. Pero este no es el caso de todos y no siempre. Muy a menudo el transportista indica solo el país de destino o no indica la región de salida, por ejemplo, está en Bélgica y puede venir a cualquier provincia a recoger la carga. En general, existen diferentes tipos de consultas: "país a país", "país a región", "región a país" o "región-región" (la mejor opción).
Muestras de algoritmos
Como sabe, las estrategias para crear sistemas de recomendación se dividen principalmente en filtrado basado en contenido y filtrado colaborativo. Sobre esta clasificación, comencé a construir soluciones.
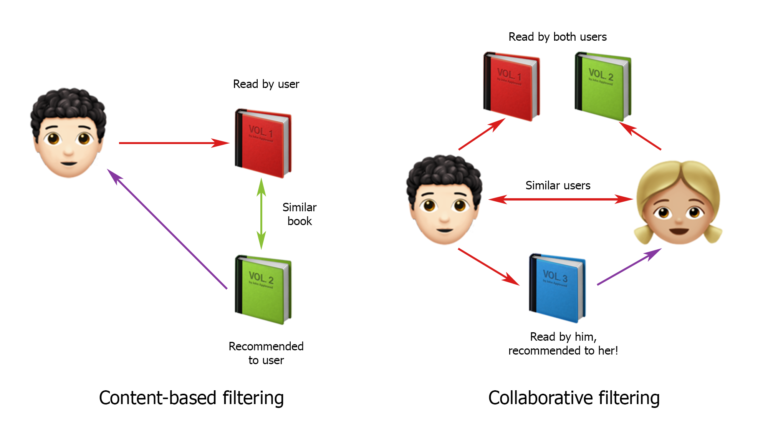
Tomé la foto de hub.forklog.com
Muchas fuentes dicen que el filtrado colaborativo funciona mejor. Es simple: estamos tratando de encontrar usuarios que sean similares a los nuestros, con patrones de comportamiento similares, y recomendamos a nuestro usuario las mismas solicitudes que las suyas. En general, esta solución fue la primera opción que presenté a los clientes. Pero no estuvieron de acuerdo con él y dijeron que no funcionaría. Después de todo, todo depende en gran medida de dónde esté ahora el camión, dónde ha llevado la carga, dónde vive y dónde es más conveniente que vaya. No sabemos de todo esto, por eso es tan difícil confiar en el comportamiento de otros usuarios, incluso si, a primera vista, son similares.
Ahora sobre los sistemas basados en contenido. Funcionan así: primero se determina y crea un perfil de usuario, y luego se hace una selección de recomendaciones en función de sus características. Bastante buena opción, pero en nuestro caso hay un par de matices. En primer lugar, un usuario puede ocultar a todo un grupo de personas que buscan carga para muchos camiones e iniciar sesión desde diferentes direcciones IP. En segundo lugar, a partir de los datos exactos solo tenemos el país del transportista, y la información sobre el número de camiones y sus tipos se "muestra" aproximadamente solo en las solicitudes realizadas por el usuario. Es decir, para poder construir un sistema basado en contenido para nuestro proyecto, necesitas mirar las solicitudes de cada usuario e intentar encontrar las más populares entre ellas.
Nuestro primer sistema de recomendación no utilizó algoritmos complejos. Intentamos clasificar las consultas y encontrar los mejores corazones para recomendarlas. Para probar el concepto, nuestro equipo trabajó con usuarios reales: les envió recomendaciones y luego recopiló comentarios. En principio, a los transportistas les gustó el resultado. Luego comparé nuestras recomendaciones con lo que buscaban los operadores en estos días y vi que el sistema funcionaba muy bien para usuarios con patrones de comportamiento persistentes. Pero, desafortunadamente para aquellos que hicieron una gama más amplia de solicitudes, la precisión de las recomendaciones no fue muy alta: era necesario mejorar el sistema.
Seguí averiguando a qué nos enfrentamos aquí. De hecho, es un modelo de Markov oculto donde un grupo de personas puede estar detrás de cada usuario. Además, los usuarios pueden estar en varios estados ocultos: no hay datos de dónde tienen actualmente un camión, cuántas personas hay en una cuenta y cuándo tendrán que ir a algún lugar la próxima vez. En ese momento, no conocía soluciones listas para la producción del modelo oculto de Markov, así que decidí buscar algo más simple.
Conoce PageRank
Así que llamé la atención sobre el algoritmo PageRank, una vez creado por los fundadores de Google, Sergey Brin y Larry Page, que todavía utiliza este motor de búsqueda para recomendar sitios a los usuarios. PageRank representa todo el espacio de Internet en forma de gráfico, donde cada página web es su nodo. Se puede utilizar para calcular la "importancia" (o rango) de cada nodo. PageRank es fundamentalmente diferente de los algoritmos de búsqueda que existían antes, ya que no se basa en el contenido de las páginas, sino en los enlaces que se encuentran dentro de ellas. Es decir, la clasificación de cada página depende del número y la calidad de los enlaces que apuntan a ella. Brin y Page demostraron la convergencia de este algoritmo, lo que significa que siempre podemos calcular el rango de cualquier nodo en un gráfico dirigido y llegar a valores que no cambiarán.
Veamos su fórmula:
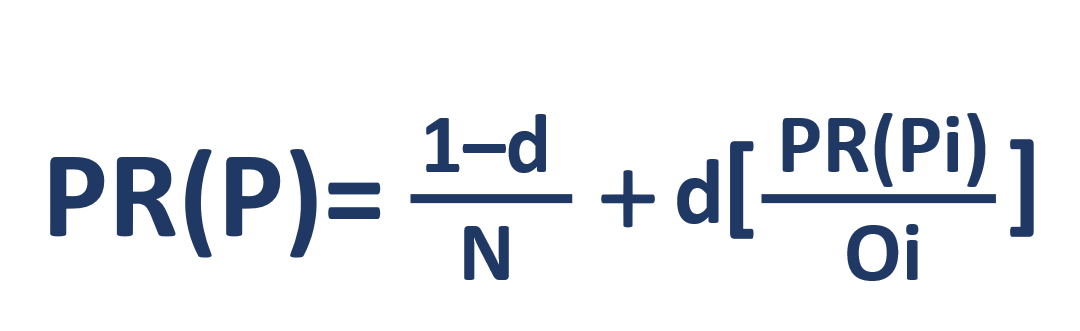
- PR(P) – rank
- N –
- i –
- O –
- d – . -, , - . , . 0 ≤ d ≤ 1 – d 0,85. .
Ahora, aquí hay un ejemplo simple de cálculo de PageRank para un gráfico simple con tres nodos. Es importante recordar que al principio todos los nodos reciben el mismo peso igual a 1 / número de nodos.
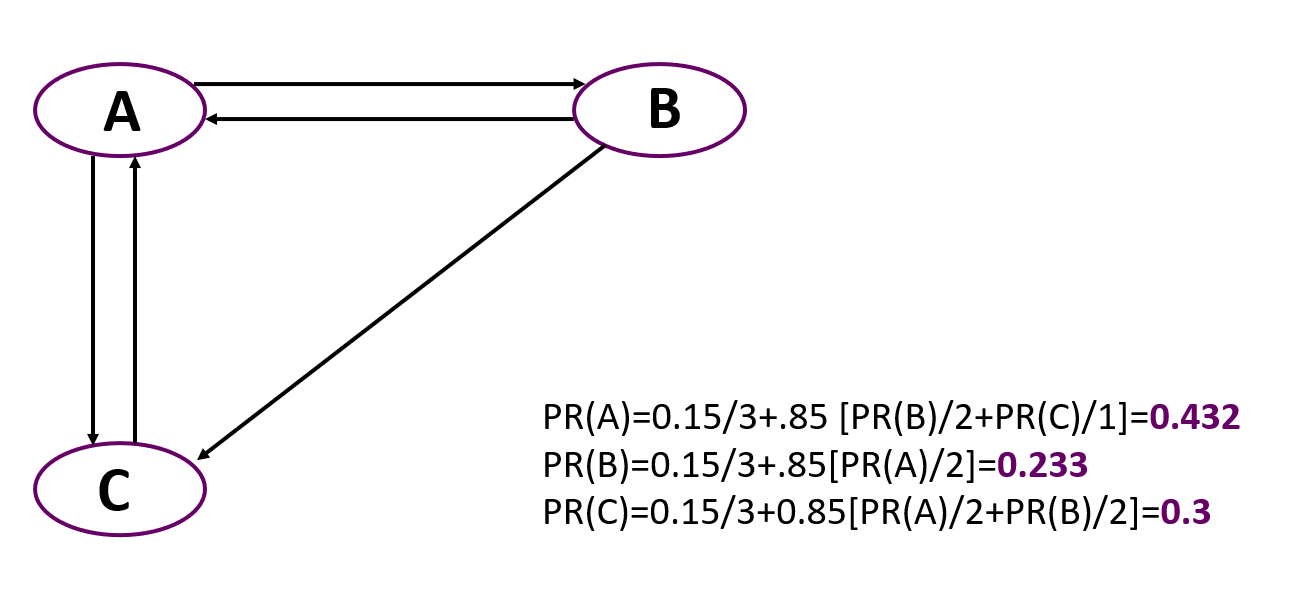
Puede ver que el más importante aquí se ha convertido en el nodo A, a pesar de que solo dos nodos apuntan a él, como C. Pero el rango de los nodos que apuntan a A es mayor que el de los nodos que llevan a C.
Supuestos y solución
Entonces, PageRank describe un proceso de Markov sin estados ocultos. Usándolo, siempre encontraremos el peso final de cada nodo, pero no podremos rastrear cambios en el gráfico. El algoritmo es realmente bueno, pudimos adaptarlo y mejorar la precisión de los resultados. Para ello, tomamos una modificación de PageRank - el algoritmo de PageRank personalizado, que se diferencia del básico en que la transición siempre se realiza a un número limitado de nodos. Es decir, cuando el usuario se cansa de "caminar" por los enlaces, no cambia a un nodo aleatorio, sino a uno de un conjunto dado.
En nuestro caso, los nodos del gráfico serán solicitudes de usuario. Dado que se supone que nuestro algoritmo dará recomendaciones para el día siguiente, he desglosado todas las solicitudes para cada operador por día. Ahora construimos un gráfico: el nodo A se conecta al nodo B, si la búsqueda del tipo B sigue a la búsqueda del tipo A, es decir, la búsqueda del tipo A fue realizada por el usuario antes del día en que buscaba la ruta B. Por ejemplo: "París - Bruselas" el martes (A), y el miércoles “Bruselas - Colonia” (B). Y algunos usuarios realizan muchas solicitudes por día, por lo que varios nodos están conectados entre sí a la vez y, como resultado, obtenemos gráficos bastante complejos.
Para agregar información sobre la importancia de pasar de un corazón a otro, agregamos pesos de los bordes del gráfico. El peso del borde A-B es la cantidad de veces que el usuario buscó B después de buscar A. También es muy importante tener en cuenta la antigüedad de las consultas, porque el usuario cambia su plantilla: puede mover o reorganizar el tipo de transporte principal, luego de lo cual no quiere ir con un camión vacío. Por lo tanto, debe monitorear el historial de rutas; agregamos una variable de vigencia, que también afectará el peso del nodo.
Vale la pena considerar la estacionalidad: podemos saber que, por ejemplo, en septiembre, el transportista viaja a menudo a Francia y en octubre a Alemania. En consecuencia, se puede dar más peso a los corazones que son "populares" en un mes determinado. Además, contamos con información sobre lo que el usuario buscó por última vez. Esto ayuda a adivinar indirectamente dónde podría estar el camión.
Resultado
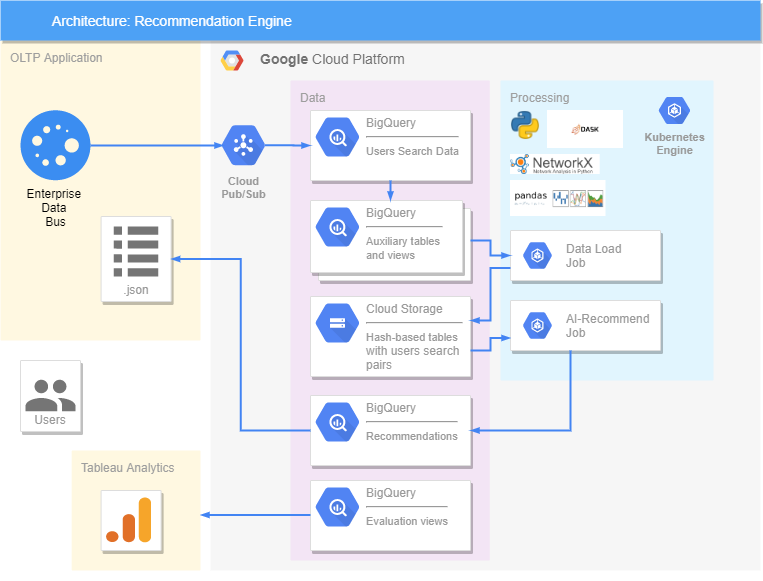
Todo está implementado en la plataforma de Google. Contamos con una aplicación OLTP, desde donde los datos de las consultas van y vienen a BigQuery, donde se forman vistas y tablas adicionales que contienen información ya procesada. La biblioteca DASK se utilizó para acelerar y paralelizar el procesamiento de grandes cantidades de datos. En nuestra solución, todos los datos se transfieren a Cloud Storage, porque DASK solo funciona con él y no interactúa con BigQuery. Se crearon dos trabajos en Kubernetes, uno de los cuales transfiere datos de BigQuery a Cloud Storage y el segundo hace recomendaciones. Funciona así: Job toma datos sobre pares de corazones de Cloud Storage, los procesa, genera recomendaciones para el día siguiente y los envía de vuelta a BigQuery. Desde allí, ya en formato .json, podemos enviar recomendaciones a la aplicación OLTP, donde los usuarios las verán.La precisión de las recomendaciones se evalúa en Tableau, donde nuestras recomendaciones se comparan con lo que el usuario realmente buscó, así como su reacción (le gustó o no).
Por supuesto, me gustaría compartir los resultados. Por ejemplo, aquí hay un usuario que hace 14 corazones de país a país todos los días. También le recomendamos la misma cantidad:
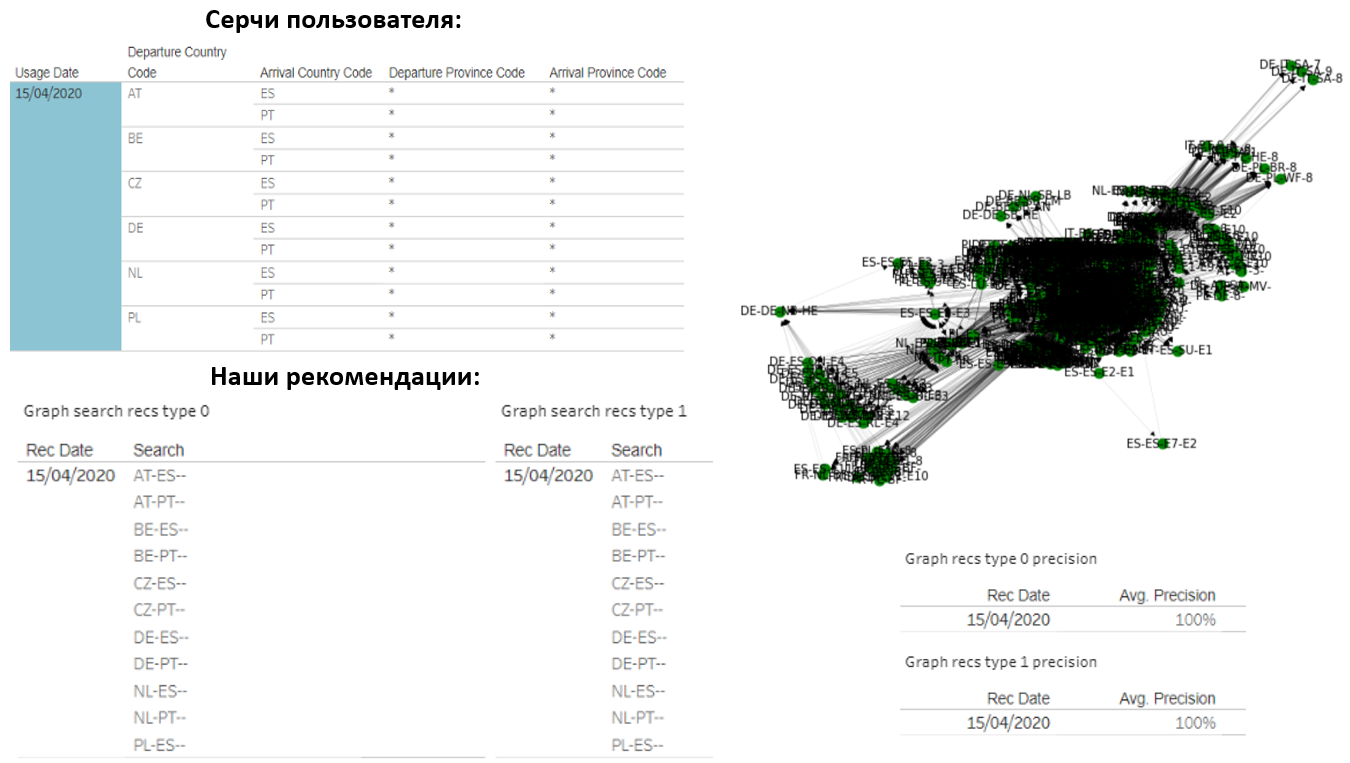
resultó que nuestras opciones coincidían por completo con lo que estaba buscando. La gráfica de este usuario consta de unas 1000 consultas diferentes, pero logramos adivinar con mucha precisión qué le interesaría.
El segundo usuario, en promedio, realiza 8 solicitudes diferentes cada 2 días, y busca tanto en el formato "país-país" como con una indicación de una región específica de salida. Además, los países de origen y entrega son completamente diferentes. Por lo tanto, no pudimos "adivinar" todo y la precisión de los resultados resultó ser menor:

Tenga en cuenta que el usuario tiene 2 gráficos con diferentes pesos. En uno, la precisión alcanzó el 38%, lo que significa que 3 de las 8 opciones recomendadas por nosotros resultaron ser relevantes. Y, quizás, si encontramos carga en estas direcciones, el usuario las elegirá.
El último y más sencillo ejemplo. Una persona realiza aproximadamente 2 búsquedas al día. Tiene patrones muy estables, no demasiadas preferencias y un gráfico simple. Como resultado, la precisión de nuestras predicciones es del 100%.

Desempeño en hechos
- Nuestros algoritmos se ejecutan en 4 CPU estándar y 10 GB de memoria.
- Los volúmenes de datos alcanzan los mil millones de registros.
- Se necesitan 18 minutos para crear recomendaciones para todos los usuarios de aproximadamente 20.000.
- La biblioteca DASK se usa para la paralelización y la biblioteca NetworkX se usa para el algoritmo PageRank.
Puedo decir que nuestras búsquedas y experimentos han dado muy buenos resultados. La presentación del comportamiento de los usuarios de la plataforma de intercambio de mercancías en forma de gráfico y el uso de PageRank nos permite predecir con precisión sus preferencias futuras y, así, construir sistemas de recomendación eficaces.