
¿Su empresa desea recopilar y analizar datos para estudiar tendencias sin sacrificar la privacidad? ¿O quizás ya utilizas varias herramientas para preservarlo y quieres profundizar en tus conocimientos o compartir tu experiencia? En cualquier caso, este material es para ti.
¿Qué nos impulsó a comenzar esta serie de artículos? NIST (Instituto Nacional de Estándares y Tecnología) lanzó el Espacio de Colaboración de Ingeniería de Privacidad el año pasado- una plataforma de cooperación, que contiene herramientas de código abierto, así como soluciones y descripciones de procesos necesarios para el diseño de la confidencialidad de los sistemas y la gestión de riesgos. Como moderadores de este espacio, ayudamos al NIST a recopilar las herramientas de privacidad diferencial disponibles en el área de anonimización. El NIST también publicó el Marco de privacidad: una herramienta para mejorar la privacidad a través de la gestión de riesgos empresariales y un plan de acción que describe una variedad de preocupaciones de privacidad, incluida la anonimización. Ahora queremos ayudar a Collaboration Space a lograr los objetivos establecidos en el plan de anonimización (desidentificación). En última instancia, ayude al NIST a desarrollar esta serie de publicaciones en una guía más profunda sobre la privacidad diferencial.
Cada artículo comenzará con conceptos básicos y ejemplos de aplicaciones para ayudar a los profesionales, como los propietarios de procesos comerciales o los oficiales de privacidad de datos, a aprender lo suficiente como para volverse peligrosos (es broma). Después de revisar los conceptos básicos, analizaremos las herramientas disponibles y los enfoques utilizados en ellas, que ya serán útiles para aquellos que están trabajando en implementaciones específicas.
Comenzaremos nuestro primer artículo describiendo los conceptos clave y los conceptos de privacidad diferencial, que usaremos en artículos posteriores.
Formulación del problema
¿Cómo se pueden estudiar los datos de la población sin afectar a miembros específicos de la población? Intentemos responder dos preguntas:
- ¿Cuántas personas viven en Vermont?
- ¿Cuántas personas llamadas Joe Near viven en Vermont?
La primera pregunta se refiere a las propiedades de toda la población y la segunda revela información sobre una persona específica. Necesitamos poder determinar las tendencias para toda la población, sin permitir información sobre un individuo específico.
Pero, ¿cómo podemos responder a la pregunta "cuántas personas viven en Vermont?" - que luego llamaremos "investigación" - sin responder la segunda pregunta "¿Cuántas personas con el nombre Joe Nier viven en Vermont?" La solución más común es la desidentificación (o anonimización), que consiste en eliminar toda la información de identificación del conjunto de datos (en adelante, creemos que nuestro conjunto de datos contiene información sobre personas específicas). Otro enfoque es permitir solo consultas agregadas, por ejemplo, con un promedio. Desafortunadamente, ahora ya sabemos que ninguno de los enfoques proporciona la protección de privacidad necesaria. Los datos anonimizados son objeto de ataques que establecen vínculos con otras bases de datos. La agregación protege la privacidad solo cuando el tamaño del grupo muestreado essuficientemente grande. Pero incluso en tales casos, los ataques exitosos son posibles [1, 2, 3, 4].
Privacidad diferencial
La privacidad diferencial [5, 6] es una definición matemática del concepto de “tener privacidad”. No es un proceso específico, sino una propiedad que puede poseer un proceso. Por ejemplo, puede calcular (probar) que un proceso dado cumple con los principios de privacidad diferencial.
En pocas palabras, para cada persona cuyos datos se incluyen en el conjunto de datos que se analiza, la privacidad diferencial garantiza que el resultado del análisis de privacidad diferencial sea prácticamente indistinguible, independientemente de si sus datos están en el conjunto de datos o no . El análisis de privacidad diferencial se suele denominar mecanismo , y lo denominaremos...
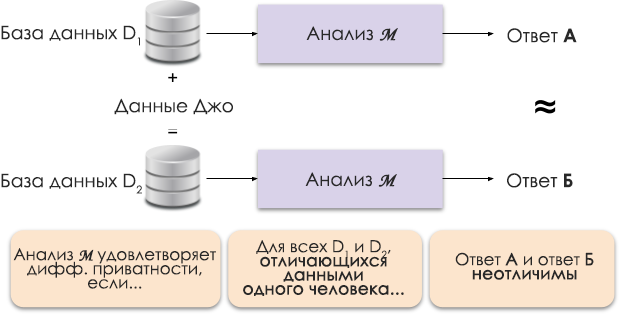
Figura 1: Representación esquemática de privacidad diferencial.
El principio de privacidad diferencial se muestra en la Figura 1. La respuesta A se calcula sin los datos de Joe y la respuesta B con sus datos. Y se argumenta que ambas respuestas serán indistinguibles. Es decir, quien mire los resultados no podrá decir en qué caso se utilizaron los datos de Joe y en cuál no.
Controlamos el nivel requerido de privacidad cambiando el parámetro de privacidad ε, que también se denomina pérdida de privacidad o presupuesto de privacidad. Cuanto menor sea el valor de ε, menos distinguibles serán los resultados y más seguros serán los datos de las personas.
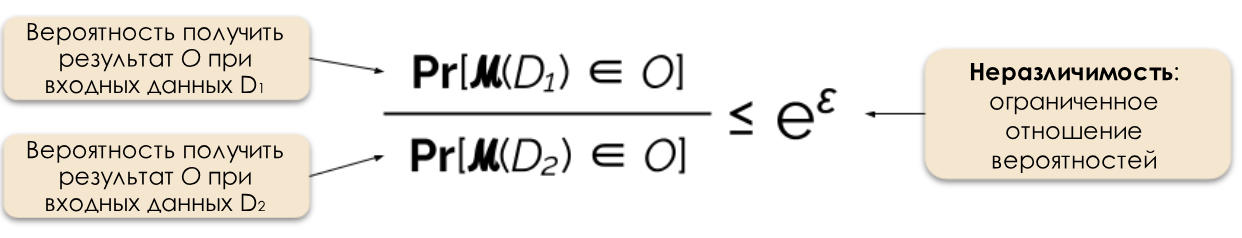
Figura 2: Definición formal de privacidad diferencial.
A menudo podemos responder a una consulta de una manera de privacidad diferencial agregando ruido aleatorio a la respuesta. La dificultad radica en determinar exactamente dónde y cuánto ruido agregar. Uno de los mecanismos de contaminación acústica más populares es el mecanismo de Laplace [5, 7].
Las solicitudes de mayor privacidad requieren más ruido para satisfacer un valor épsilon específico de privacidad diferencial. Y este ruido adicional puede reducir la utilidad de los resultados obtenidos. En artículos futuros, entraremos en más detalles sobre la privacidad y el compromiso entre privacidad y utilidad.
Beneficios de la privacidad diferencial
La privacidad diferencial tiene varias ventajas importantes sobre las técnicas anteriores.
- , , ( ) .
- , .
- : , . , . , .
Debido a estas ventajas, la aplicación de métodos de privacidad diferencial en la práctica es preferible a algunos otros métodos. La otra cara de la moneda es que esta metodología es bastante nueva y no es fácil encontrar herramientas, estándares y enfoques probados fuera de la comunidad de investigación académica. Sin embargo, creemos que la situación mejorará en un futuro cercano debido a la creciente demanda de soluciones confiables y simples para mantener la privacidad de los datos.
¿Que sigue?
Suscríbete a nuestro blog y muy pronto publicaremos la traducción del próximo artículo, en el que se habla de los modelos de amenazas que se deben tener en cuenta a la hora de construir sistemas de privacidad diferencial, así como de las diferencias entre los modelos central y local de privacidad diferencial.
Fuentes
[1] Garfinkel, Simson, John M. Abowd y Christian Martindale. "Comprensión de los ataques de reconstrucción de bases de datos sobre datos públicos". Comunicaciones del ACM 62.3 (2019): 46-53.
[2] Gadotti, Andrea y col. "Cuando la señal está en el ruido: explotando el ruido pegajoso de diffix". 28º Simposio de Seguridad de USENIX (USENIX Security 19). 2019.
[3] Dinur, Irit y Kobbi Nissim. "Revelar información preservando la privacidad". Actas del vigésimo segundo simposio ACM SIGMOD-SIGACT-SIGART sobre Principios de los sistemas de bases de datos. 2003.
[4] Sweeney, Latanya. "Los datos demográficos simples a menudo identifican a las personas de manera única". Salud (San Francisco) 671 (2000): 1-34.
[5] Dwork, Cynthia y col. "Calibración del ruido a la sensibilidad en el análisis de datos privados". Conferencia de teoría de la criptografía. Springer, Berlín, Heidelberg, 2006.
[6] Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O'Brien, Thomas Steinke y Salil Vadhan. « Privacidad diferencial: un manual para un público no técnico. »Vand. J. Ent. & Tech. L. 21 (2018): 209.
[7] Dwork, Cynthia y Aaron Roth. "Los fundamentos algorítmicos de la privacidad diferencial". Fundamentos y tendencias en informática teórica 9, no. 3-4 (2014): 211-407.