 Hace algún tiempo, la plataforma Apache Ignite emergió en el horizonte y comenzó a ganar popularidad. La computación en memoria es velocidad, lo que significa que la velocidad debe garantizarse en todas las etapas del trabajo, especialmente al cargar datos.
Hace algún tiempo, la plataforma Apache Ignite emergió en el horizonte y comenzó a ganar popularidad. La computación en memoria es velocidad, lo que significa que la velocidad debe garantizarse en todas las etapas del trabajo, especialmente al cargar datos.
Debajo del corte se encuentra una descripción de un método para cargar rápidamente datos desde una tabla relacional en un clúster Apache Ignite distribuido. Se describe el preprocesamiento del conjunto de resultados de la consulta SQL en el nodo cliente del clúster y la distribución de datos en el clúster mediante la tarea de reducción de mapas. Describe las cachés y las tablas relacionales relacionadas, muestra cómo crear un objeto personalizado a partir de una fila de la tabla y cómo usar ComputeTaskAdapter para colocar rápidamente los objetos creados. Todo el código se puede ver en su totalidad en el repositorio FastDataLoad .
Historia del problema
Este texto es una traducción al ruso de mi publicación en el blog In-Memory Computing en el sitio web GridGain.
Entonces, cierta compañía decide acelerar una aplicación lenta moviendo la computación a un clúster en memoria. Los datos iniciales para los cálculos están en MS SQL; el resultado de los cálculos debe colocarse allí. El cluster está distribuido, dado que ya hay muchos datos, el rendimiento de la aplicación está al límite y el volumen de datos está creciendo. Se establecen límites de tiempo difíciles.
Antes de escribir código rápido para procesar datos, los datos deben cargarse rápidamente. Una búsqueda frenética en la web revela una clara escasez de ejemplos de código que pueden escalar a tablas de decenas o cientos de millones de filas. Ejemplos que puede descargar, compilar y seguir los pasos de la depuración. Esto es por un lado.
, Apache Ignite / GridGain, . , . " ?", — , .
, .
(World Database)
, data collocation, . world.sql Apache Ignite.
CSV , — SQL :
- countryCache — country.csv;
- cityCache — city.csv;
- countryLanguageCache — countryLanguage.csv.
countryCache country.csv. countryCache — code, — String, — Country, (name, continent, region).

, — , . Country , . org.h2.tools.Csv, CSV java.sql.ResultSet. Apache Ignite , SQL H2.
// define countryCache
IgniteCache<String,Country> cache = ignite.cache("countryCache");
try (ResultSet rs = new Csv().read(csvFileName, null, null)) {
while (rs.next()) {
String code = rs.getString("Code");
String name = rs.getString("Name");
String continent = rs.getString("Continent");
Country country = new Country(code,name,continent);
cache.put(code,country);
}
}. , , . - .
, . , .
Apache Ignite — -. , PARTITIONED - (partition) . ; , . -, affinity function, , .

, :
- HashMap partition_number -> key -> Value
Map<Integer, Map<String, Country>> result = new HashMap<>(); - affinity function partition_number. cache.put() - HashMap partition_number
try (ResultSet rs = new Csv().read(csvFileName, null, null)) { while (rs.next()) { String code = rs.getString("Code"); String name = rs.getString("Name"); String continent = rs.getString("Continent"); Country country = new Country(code,name,continent); result.computeIfAbsent(affinity.partition(key), k -> new HashMap<>()).put(code,country); } }
ComputeTaskAdapter ComputeJobAdapter. ComputeJobAdapter 1024. , .
ComputeJobAdapter . , .
Compute Task,
, "ComputeTaskAdapter initiates the simplified, in-memory, map-reduce process". ComputeJobAdapter map — , . reduce — .
(RenewLocalCacheJob)
targetCache.putAll(addend);RenewLocalCacheJob partition_number .
(AbstractLoadTask)
( loader) — AbstractLoadTask. . ( ), AbstractLoadTask TargetCacheKeyType. HashMap
Map<Integer, Map<TargetCacheKeyType, BinaryObject>> result;countryCache String. . AbstractLoadTask TargetCacheKeyType, BinaryObject. , — .
BinaryObject
— . , JVM, - . class definition , JAR- . Country
IgniteCache<String, Country> countryCache;, , classpath ClassNotFound.
. — classpath, :
- JAR- ;
- classpath ;
- ;
- .
— BinaryObject () . :
-
IgniteCache<String, BinaryObject> countryCache; - Country BinaryObject (. LoadCountries.java)
Country country = new Country(code, name, .. ); BinaryObject binCountry = node.binary().toBinary(country); - HashMap, BinaryObject
Map<Integer, Map<String, BinaryObject>> result
, . , , ClassNotFoundException .
. .
Apache Ignite : .
default-config.xml — . :
- GridGain CE Installing Using ZIP Archive. 8.7.10, FastDataLoad , ;
- {gridgain}\config default-config.xml
<bean id="grid.cfg" class="org.apache.ignite.configuration.IgniteConfiguration"> <property name="peerClassLoadingEnabled" value="true"/> </bean> - , {gridgain}\bin ignite.bat. ; ;
- , . ,
[08:40:04] Topology snapshot [ver=2, locNode=d52b1db3, servers=2, clients=0, state=ACTIVE, CPUs=8, offheap=3.2GB, heap=2.0GB]
. , 8.7.25, pom.xml
<gridgain.version>8.7.25</gridgain.version>
class org.apache.ignite.spi.IgniteSpiException: Local node and remote node have different version numbers (node will not join, Ignite does not support rolling updates, so versions must be exactly the same) [locBuildVer=8.7.25, rmtBuildVer=8.7.10] , , map-reduce. — JAR-, compute task . Windows, Linux.
:
- FastDataLoad;
- ;
mvn clean package - , .
java -jar .\target\fastDataLoad.jar
main() LoadApp LoaderAgrument . map-reduce LoadCountries.
LoadCountries RenewLocalCacheJob , ( ).
#1

#2

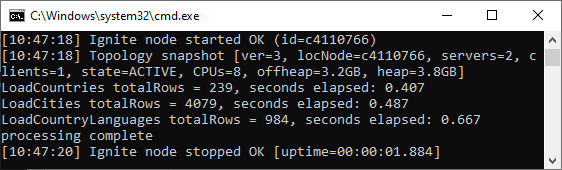
country.csv , CountryCode . cityCache countryLanguageCache; , .
.
.
:
- (SQL Server Management Studio):
- — 44 686 837;
- — 1.071 GB;
- — 0H:1M:35S;
- RenewLocalCacheJob reduce — 0H:0M:9S.
Se necesita menos tiempo para distribuir datos en un clúster que para ejecutar una consulta SQL.