
El equipo invierte mucho trabajo, esfuerzo y recursos en cada cambio en el juego: a veces, el desarrollo de una nueva funcionalidad o nivel lleva varios meses. La tarea del analista es minimizar los riesgos de la introducción de tales cambios y ayudar al equipo a tomar la decisión correcta sobre el desarrollo futuro del proyecto.
Al analizar decisiones, es importante guiarse por datos estadísticamente significativos que coincidan con las preferencias de la audiencia, en lugar de suposiciones intuitivas. Las pruebas A / B ayudan a obtener dichos datos y evaluarlos.
6 pasos "sencillos" de las pruebas A / B
Para el término de búsqueda "prueba A / B" o "prueba dividida", la mayoría de las fuentes ofrecen varios pasos "simples" para una prueba exitosa. Hay seis de esos pasos en mi estrategia.
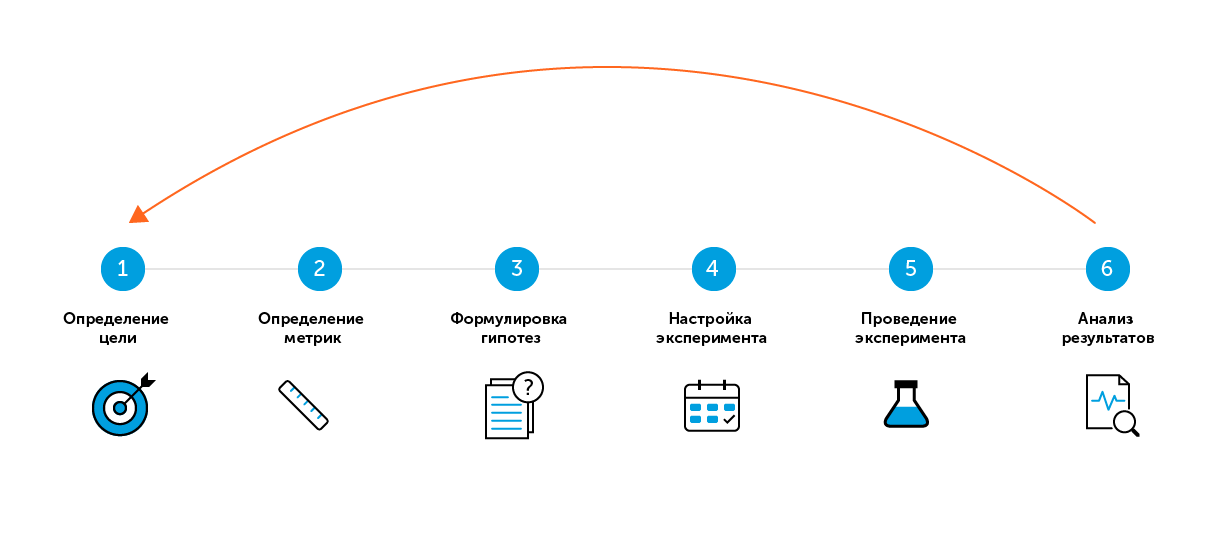
A primera vista, todo es sencillo:
- hay grupo A, control, no hay cambios en el juego;
- hay grupo B, prueba, con cambios. Por ejemplo, se ha agregado nueva funcionalidad, se ha aumentado la dificultad de los niveles, se ha cambiado el tutorial;
- Ejecute la prueba y vea qué variante tiene mejor rendimiento.
En la práctica, es más difícil. Para que el equipo implemente la mejor solución, yo, como analista, necesito responder qué tan seguro estoy de los resultados de las pruebas. Tratemos las dificultades paso a paso.
Paso 1. Determine el objetivo
Por un lado, podemos probar todo lo que se le ocurra a cada miembro del equipo, desde el color del botón hasta los niveles de dificultad del juego. La capacidad técnica para realizar pruebas divididas se incorpora a nuestros productos en la etapa de diseño.
Por otro lado, es importante priorizar todas las sugerencias para mejorar el juego según el nivel del efecto en la métrica objetivo. Por lo tanto, primero elaboramos un plan para lanzar las pruebas divididas desde la hipótesis de mayor prioridad a la menor.
Intentamos no ejecutar múltiples pruebas A / B en paralelo para comprender exactamente cuál de las nuevas funcionalidades afectó la métrica objetivo. Parece que con esta estrategia, llevará más tiempo probar todas las hipótesis. Pero la priorización ayuda a eliminar hipótesis poco prometedoras en la etapa de planificación.
Obtenemos los datos que mejor reflejan el efecto de cambios específicos y no perdemos tiempo configurando pruebas con efectos cuestionables.
Definitivamente discutimos el plan de lanzamiento con el equipo, ya que el foco de interés cambia en diferentes etapas del ciclo de vida del producto. Al comienzo del proyecto, esto suele ser Retención D1: el porcentaje de jugadores que regresaron al juego al día siguiente de su instalación. En etapas posteriores, estas pueden ser métricas de retención o monetización: conversión, ARPU y otras.
Ejemplo.Las métricas de retención requieren una atención especial después de que un proyecto se lanza suavemente. En esta etapa, resaltemos uno de los posibles problemas: la retención D1 no alcanza el nivel de los puntos de referencia de la compañía para un género de juego en particular. Es necesario analizar el embudo de pasar los primeros niveles. Supongamos que observa una gran caída de jugadores entre el inicio y la finalización del tercer nivel: una tasa de finalización baja del tercer nivel.
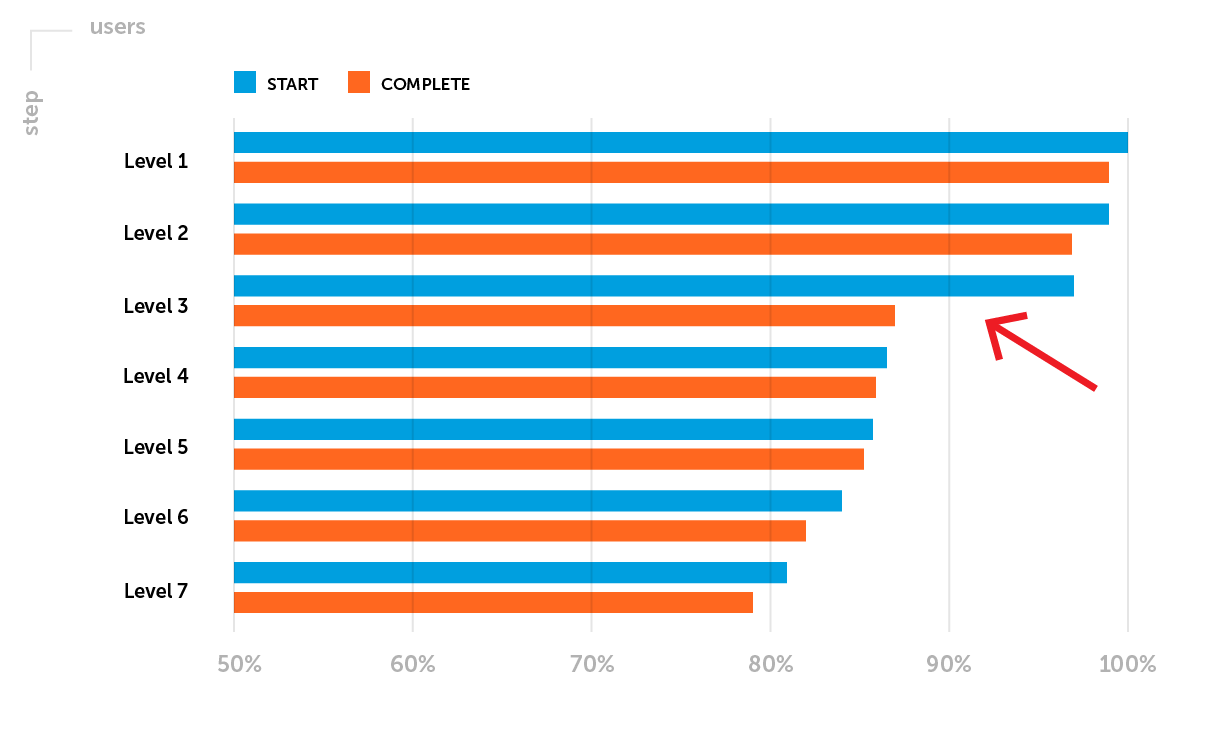
El objetivo de la prueba A / B planificada : aumentar la retención D1 aumentando la proporción de jugadores que completaron con éxito el nivel 3.
Paso 2. Definición de métricas
Antes de comenzar la prueba A / B, determinamos el parámetro monitoreado: seleccionamos la métrica, cambios en los cuales mostrarán si la nueva funcionalidad del juego es más exitosa que la original.
Hay dos tipos de métricas:
- cuantitativo: la duración promedio de la sesión, el valor del cheque promedio, el tiempo para completar el nivel, la cantidad de experiencia, etc.
- calidad - Retención, Tasa de Conversión y otros.
El tipo de métrica influye en la elección del método y las herramientas para evaluar la importancia de los resultados.
Es probable que la funcionalidad probada afecte no a un objetivo, sino a varias métricas. Por lo tanto, observamos los cambios en general, pero no intentamos encontrar "nada" cuando no hay significación estadística en la evaluación de la métrica objetivo.
De acuerdo con el objetivo del primer paso, para la próxima prueba A / B, evaluaremos la tasa de finalización del tercer nivel , una métrica cualitativa.
Paso 3. Formular una hipótesis
Cada prueba A / B prueba una hipótesis general, que se formula antes del lanzamiento. Respondemos a la pregunta: ¿qué cambios esperamos en el grupo de prueba? Por lo general, la redacción se ve así:
"Esperamos que (el impacto) cause (cambio)"
Los métodos estadísticos funcionan de manera opuesta; no podemos usarlos para probar que la hipótesis es correcta. Por tanto, luego de formular una hipótesis general, se determinan dos estadísticas. Ayudan a comprender que la diferencia observada entre el grupo de control A y el grupo de prueba B es un accidente o el resultado de cambios.
En nuestro ejemplo:
- Hipótesis nula ( H0 ): Reducir la dificultad del Nivel 3 no afectará la proporción de usuarios que completen con éxito el Nivel 3. La tasa de finalización del nivel 3 para los grupos A y B no es realmente diferente y las diferencias observadas son aleatorias.
- Hipótesis alternativa ( H1 ): Reducir la dificultad del Nivel 3 aumentará la proporción de usuarios que completen con éxito el Nivel 3. La tasa de finalización del nivel 3 es más alta en el grupo B que en el grupo A, y estas diferencias son el resultado de cambios.
En esta etapa, además de formular una hipótesis, es necesario evaluar el efecto esperado.
Hipótesis: "Esperamos que una disminución en la complejidad del 3er nivel provoque un aumento en la Tasa de Finalización del 3er nivel del 85% al 95%, es decir, en más del 11%".
(95% -85%) / 85% = 0.117 => 11.7%
En este ejemplo, al determinar la Tasa de finalización esperada del Nivel 3, nuestro objetivo es acercarla a la Tasa de finalización promedio de los niveles iniciales.
Paso 4. Configurar el experimento
1. Defina los parámetros para los grupos A / B antes de comenzar el experimento: para qué público lanzamos la prueba, para qué proporción de jugadores, qué configuraciones establecemos en cada grupo.
2. Comprobamos la representatividad de la muestra en su conjunto y la homogeneidad de las muestras en los grupos. Puede ejecutar previamente una prueba A / A para evaluar estos parámetros, una prueba en la que los grupos de prueba y control tienen la misma funcionalidad. La prueba A / A ayuda a asegurarse de que no hay diferencias estadísticamente significativas en las métricas objetivo en ambos grupos. Si hay diferencias, no se puede ejecutar una prueba A / B con tales configuraciones (tamaño de muestra y nivel de confianza).
La muestra no será perfectamente representativa, pero siempre prestamos atención a la estructura de los usuarios en términos de sus características: usuario nuevo / antiguo, nivel en el juego, país. Todo está ligado al propósito de la prueba A / B y se negocia de antemano. Es importante que la estructura de usuarios en cada grupo sea condicionalmente la misma.
Aquí hay dos trampas potencialmente peligrosas:
- Las métricas altas en grupos durante un experimento pueden ser una consecuencia de atraer un buen tráfico. El tráfico es bueno si las tasas de participación son altas. El tráfico deficiente es la causa más común de caída de las métricas.
- Heterogeneidad muestral. Digamos que el proyecto de nuestro ejemplo se está desarrollando para una audiencia de habla inglesa. Esto significa que debemos evitar una situación en la que más usuarios de países donde el inglés no es el idioma predominante caerán en uno de los grupos.
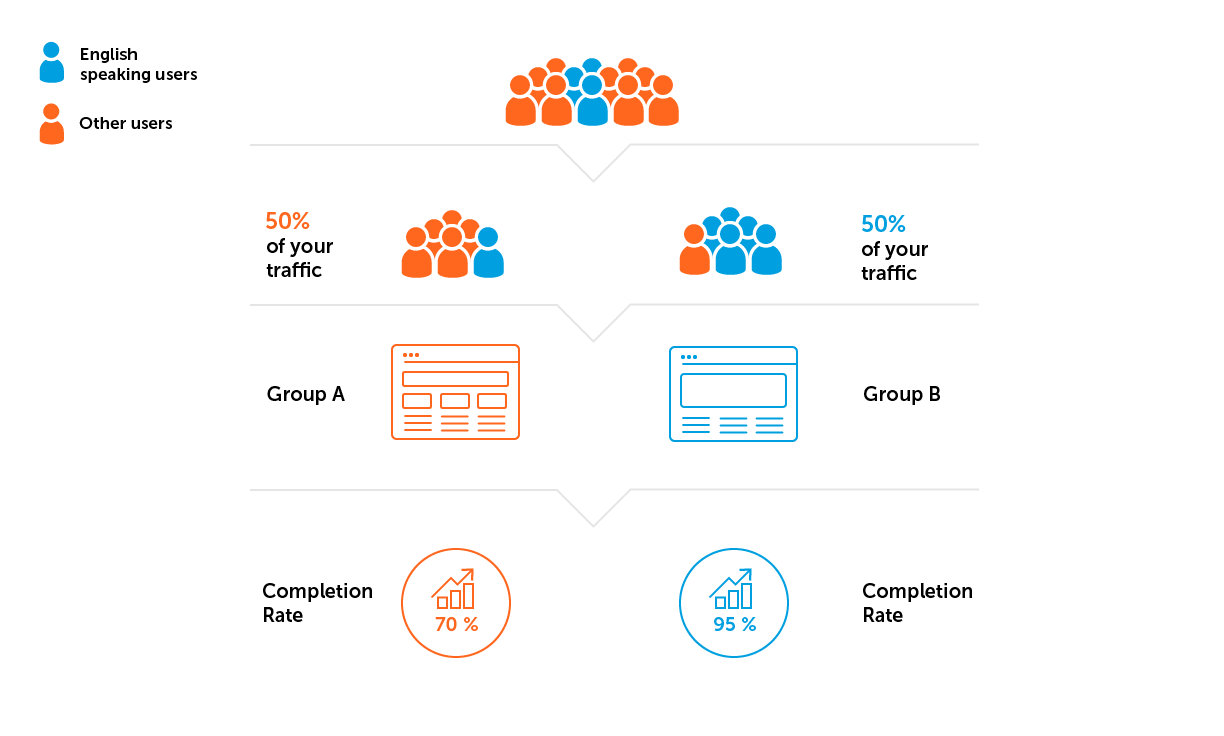
3. Calcule el tamaño de la muestra y la duración del experimento.
Parecería que el momento es transparente, dado el enorme conjunto de calculadoras en línea.
Sin embargo, su uso requiere la entrada de información inicial específica. Para seleccionar la opción de calculadora en línea adecuada, recuerde los tipos de datos y comprenda los siguientes términos.
- Población general : todos los usuarios a los que se distribuirán las conclusiones de la prueba A / B en el futuro.
- Muestra : usuarios que realmente se someten a pruebas. Con base en los resultados del análisis de la muestra, se extraen conclusiones sobre el comportamiento de toda la población general.
- , . — , , , .
- , . .
- (α) — , (0), .
- (1-α) — , , .
- (1-β) — , , .
La combinación de estos parámetros le permite calcular el tamaño de muestra requerido en cada grupo y la duración de la prueba.
En una calculadora en línea, puede jugar con los datos de entrada para comprender la naturaleza de sus relaciones.
Un ejemplo . Usemos la calculadora Optimizely para calcular el tamaño de la muestra para una tasa de conversión del 1%. Considere que el tamaño del efecto esperado es del 5% a un nivel de confianza del 95% (el indicador se calcula como 1-α). Tenga en cuenta que en la interfaz de esta calculadora, el término Significación estadística se utiliza para significar "Nivel de confianza" a un nivel de significancia del 5%.
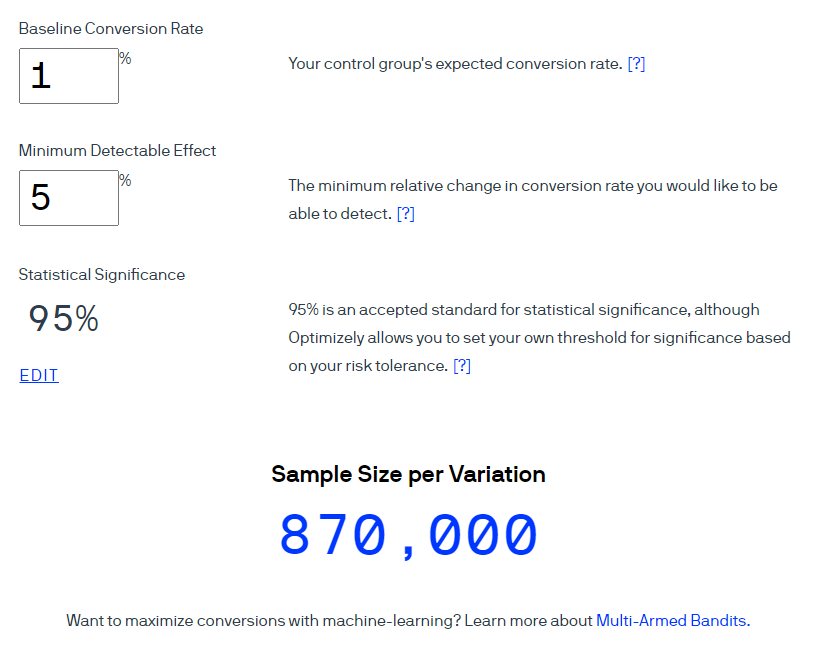
Optimizely afirma que se deberían incluir 870.000 usuarios en cada grupo.
Conversión del tamaño de la muestra a una duración aproximada de la prueba: dos cálculos simples.
Cálculo n. ° 1. Tamaño de la muestra × número de grupos en el experimento = número total de usuarios requeridos
Cálculo n. ° 2. Número total de usuarios requeridos ÷ número promedio de usuarios por día = número aproximado de días del experimento
Si el primer grupo requiere 870,000 usuarios, entonces para la prueba de dos opciones el total el número de usuarios será de 1.740.000, teniendo en cuenta el tráfico de 1.000 jugadores por día, la prueba debería durar 1.740 días. Esta duración no está justificada. En esta etapa, normalmente revisamos la hipótesis, los datos de referencia y la idoneidad de la prueba.
En nuestro ejemplo con una mejora de Nivel 3, la conversión es la proporción de quienes completaron con éxito el Nivel 3. Es decir, la tasa de conversión es del 85%, queremos aumentar este indicador en al menos un 11%. Con un nivel de confianza del 95%, obtenemos 130 usuarios por grupo.

Con el mismo volumen de tráfico de 1000 usuarios, la prueba, en términos generales, se puede completar en menos de un día. Esta conclusión es fundamentalmente errónea, ya que no tiene en cuenta la estacionalidad semanal. El comportamiento del usuario difiere en los diferentes días de la semana, por ejemplo, puede cambiar en días festivos. Y en algunos proyectos esta influencia es muy fuerte, en otros apenas se nota. Esta no es una condición necesaria en todos los proyectos y no para todas las pruebas, pero en los proyectos con los que he trabajado siempre se observó la estacionalidad semanal en KPI.
Por lo tanto, redondeamos la duración de la prueba a semanas para tener en cuenta la estacionalidad. Con mayor frecuencia, nuestro ciclo de pruebas es de una a dos semanas, según el tipo de prueba A / B.
Paso 5. Realización de un experimento
Después de ejecutar una prueba A / B, inmediatamente desea ver los resultados, pero la mayoría de las fuentes prohíben estrictamente hacer esto para eliminar el problema de mirar a escondidas. Para explicar la esencia del problema en palabras simples, en mi opinión, nadie ha tenido éxito hasta ahora. Los autores de estos artículos basan sus pruebas en la evaluación de probabilidades, varios resultados de modelos matemáticos, que llevan a los lectores a la zona de las "fórmulas matemáticas complejas". Su principal conclusión es un hecho casi indiscutible: no mire los datos antes de que se haya mecanografiado la muestra requerida y haya pasado el número requerido de días después de que se inicie la prueba. Como resultado, muchas personas malinterpretan el problema de "espiar" y siguen literalmente las recomendaciones.
Hemos configurado los procesos para que podamos ver datos actualizados para monitorear proyectos de KPI a diario. En paneles de control preparados previamente, seguimos el progreso del experimento desde el principio: verificamos si los grupos se reclutan de manera uniforme, si hay algún problema crítico después de comenzar la prueba que pueda afectar los resultados, etc.
La regla principal es no sacar conclusiones prematuras. Todas las conclusiones se formulan de acuerdo con el diseño establecido de la prueba A / B y se resumen en un informe detallado. Hemos estado monitoreando los cambios en el indicador desde el lanzamiento de la prueba A / B.
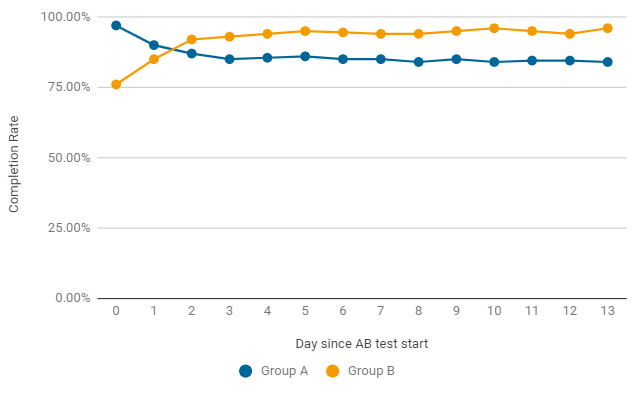
Un ejemplo, como en la prueba A / B, la tasa de finalización puede cambiar por día.En los primeros dos días después del lanzamiento, la variante del juego ganó sin cambios (grupo A), pero resultó ser solo un accidente. Ya después del segundo día, el indicador del grupo B obtiene resultados consistentemente mejores. Para completar la prueba, no solo necesita significación estadística, sino también estabilidad, por lo que estamos esperando el final de la prueba.
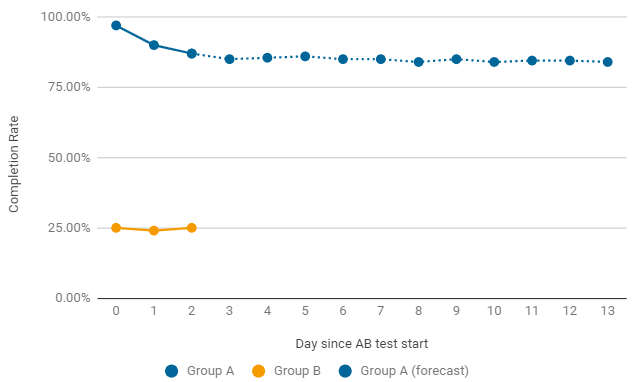
Un ejemplo de cuándo vale la pena finalizar una prueba A / B antes de tiempo. Si, después del lanzamiento, uno de los grupos ofrece tasas críticamente bajas, buscamos inmediatamente las razones de tal caída. Los más habituales son los errores en la configuración y ajustes del nivel de juego. En este caso, la prueba actual se termina antes de tiempo y se inicia una nueva con correcciones.
Paso 6. Analizar los resultados
El cálculo de métricas clave no es particularmente difícil, pero evaluar la importancia de los resultados obtenidos es un problema aparte.
Las calculadoras en línea se pueden usar para probar la importancia estadística de los resultados al evaluar métricas de calidad como Retención y Conversión.
Mis 3 calculadoras en línea principales para tareas como esta:
- Awesome A / B Tools de Evan es una de las más populares. Implementa varios métodos para evaluar la importancia de una prueba. Al usarlo, debe comprender claramente la esencia de cada parámetro ingresado, interpretar de forma independiente los resultados y formular conclusiones.
- , A/B Testguide. , . — , .
- A/B Testing Calculator Neilpatel. -, .
Un ejemplo . Para analizar dichas pruebas A / B, tenemos un tablero que muestra toda la información necesaria para sacar conclusiones y resalta automáticamente el resultado con un cambio significativo en el objetivo.

Veamos cómo sacar conclusiones de esta prueba A / B usando calculadoras.
Datos iniciales:
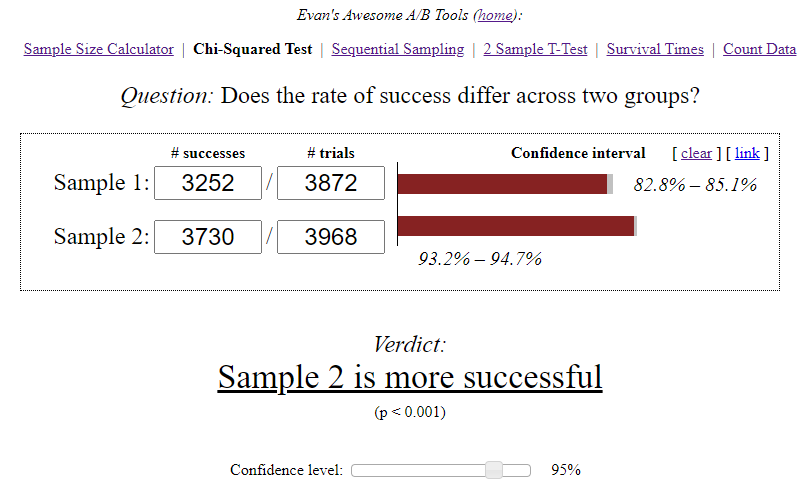
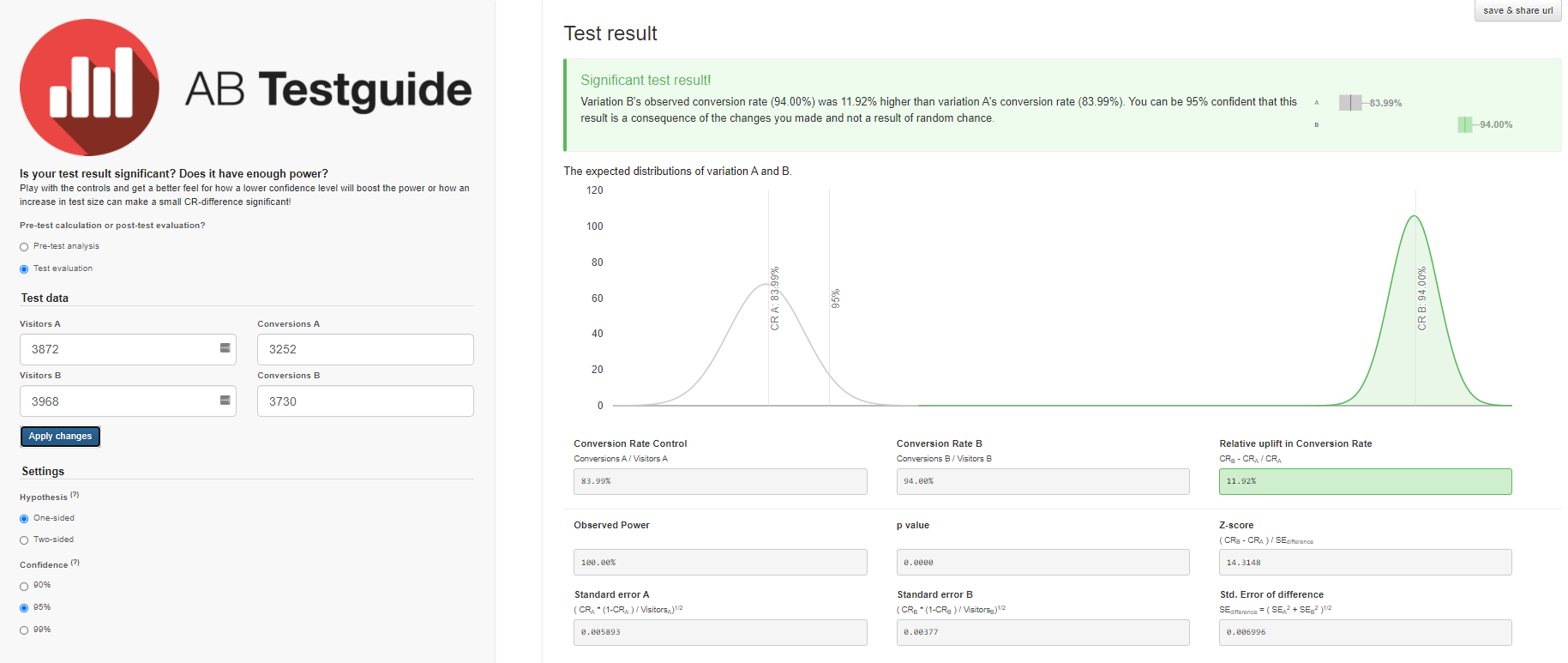
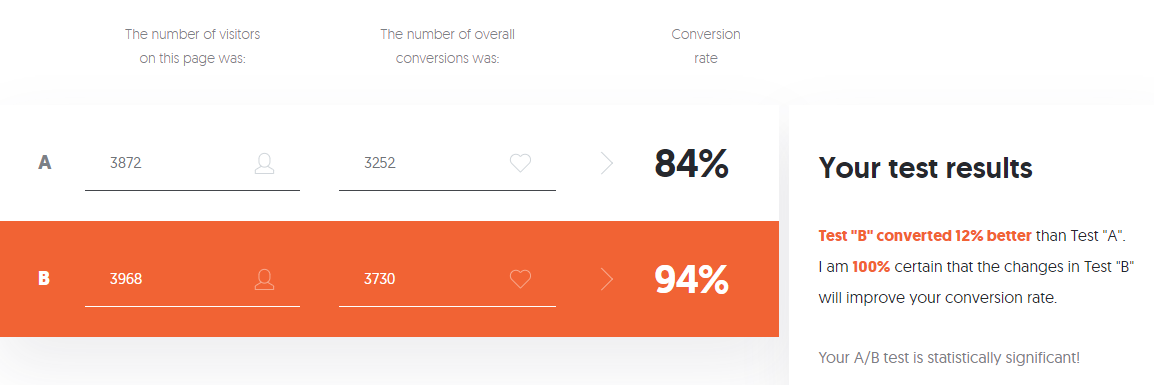
- En el grupo A, de 3870 usuarios que comenzaron el nivel 3, solo 3252 usuarios lo aprobaron con éxito, es decir, el 84%.
- En el grupo B, de 3968 usuarios, 3730 pasaron con éxito el nivel, es decir, el 94%.
La calculadora Awesome A / B Tools de Evan calculó el intervalo de confianza para cada opción, teniendo en cuenta el tamaño de la muestra y el nivel de significancia seleccionado.
Conclusiones independientes:
- A — 84,00%, 82,8%—85,1%. B — 94,00%, 93,2%—94,7%. (94%-84%)/84% = 0,119 => 12%
- 12% , A. — , . 95%.
- .
Obtendremos resultados similares con la calculadora A / B Testguide . Pero aquí ya puedes jugar con la configuración, obtener un resultado gráfico y formular conclusiones.
Si tiene miedo de tantas configuraciones, no desea o necesita lidiar con la variedad de datos calculados por la calculadora, puede usar la Calculadora de pruebas A / B de Neilpatel .
Cada calculadora en línea tiene sus propios criterios y algoritmos, que pueden no tener en cuenta todas las características del experimento. Como resultado, surgen preguntas y dudas en la interpretación de los resultados. Además, si la métrica objetivo es cuantitativa (verificación promedio o duración promedio de la primera sesión), las calculadoras en línea enumeradas ya no son aplicables y se requieren métodos de evaluación más avanzados.
Realizo un informe detallado de cada prueba A / B, por lo que he seleccionado e implementado métodos y criterios adecuados a mis tareas para evaluar la significancia estadística de los resultados.
Conclusión
La prueba A / B es una herramienta que no da una respuesta inequívoca a la pregunta "¿Qué opción es mejor?", Sino que solo le permite reducir la incertidumbre en el camino hacia la búsqueda de soluciones óptimas. Al realizarlo, los detalles son importantes en todas las etapas de preparación, cada inexactitud cuesta recursos y puede afectar negativamente la confiabilidad de los resultados. Espero que este artículo te haya sido útil y te ayude a evitar errores en las pruebas A / B.