En este artículo tocaré un tema un poco más complejo e interesante (al menos para mí, el desarrollador del equipo de búsqueda): la búsqueda de texto completo. Agregaremos un nodo Elasticsearch a nuestra región de contenedores, aprenderemos cómo crear un índice y buscar contenido, tomando descripciones de cinco mil películas de TMDB 5000 Movie Dataset como datos de prueba.... También aprenderemos cómo hacer filtros de búsqueda y profundizar un poco en la clasificación.
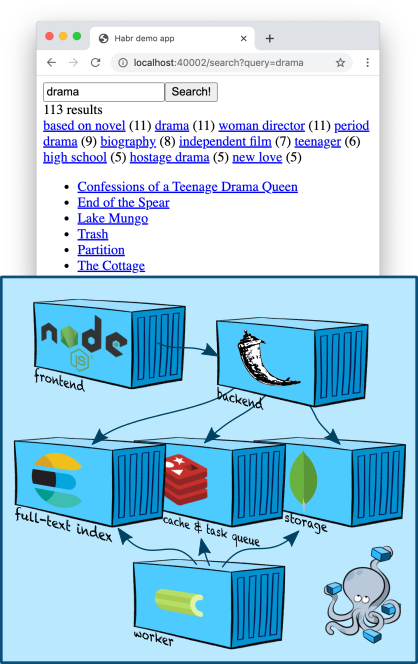
Infraestructura: Elasticsearch
Elasticsearch es un almacenamiento de documentos popular que puede crear índices de texto completo y, como regla, se utiliza específicamente como motor de búsqueda. Elasticsearch agrega al motor Apache Lucene en el que se basa, fragmentación, replicación, una conveniente API JSON y un millón de detalles más que la han convertido en una de las soluciones de búsqueda de texto completo más populares.
Agreguemos un nodo Elasticsearch al nuestro
docker-compose.yml:
services:
...
elasticsearch:
image: "elasticsearch:7.5.1"
environment:
- discovery.type=single-node
ports:
- "9200:9200"
...
La variable de entorno
discovery.type=single-nodele dice a Elasticsearch que se prepare para trabajar solo y que no busque otros nodos y se fusione con ellos en un clúster (este es el comportamiento predeterminado).
Tenga en cuenta que estamos publicando el puerto 9200 hacia afuera, aunque nuestra aplicación está navegando dentro de la red creada por docker-compose. Esto es puramente para depurar: de esta forma podemos acceder a Elasticsearch directamente desde la terminal (hasta que encontremos una forma más inteligente, más sobre eso a continuación).
Agregar el cliente Elasticsearch en nuestro cableado no es difícil ; lo bueno, Elastic proporciona un cliente Python minimalista .
Indexación
En el último artículo, colocamos nuestras entidades principales - "tarjetas" en una colección de MongoDB. Podemos recuperar rápidamente su contenido de una colección por identificador, porque MongoDB ha creado un índice directo para nosotros ; utiliza árboles B para esto .
Ahora nos enfrentamos a la tarea inversa: el contenido (o sus fragmentos) para obtener los identificadores de las tarjetas. Por lo tanto, necesitamos un índice inverso . ¡Aquí es donde Elasticsearch resulta útil!
El esquema general para construir un índice suele tener este aspecto.
- Cree un nuevo índice vacío con un nombre único, configúrelo según sea necesario.
- Revisamos todas nuestras entidades en la base de datos y las colocamos en un nuevo índice.
- Cambiamos la producción para que todas las consultas comiencen a dirigirse al nuevo índice.
- Eliminando el índice antiguo. Aquí, a voluntad, es posible que desee almacenar los últimos índices, de modo que, por ejemplo, sea más conveniente depurar algunos problemas.
Creemos el esqueleto de un indexador y luego entremos más detalles con cada paso.
import datetime
from elasticsearch import Elasticsearch, NotFoundError
from backend.storage.card import Card, CardDAO
class Indexer(object):
def __init__(self, elasticsearch_client: Elasticsearch, card_dao: CardDAO, cards_index_alias: str):
self.elasticsearch_client = elasticsearch_client
self.card_dao = card_dao
self.cards_index_alias = cards_index_alias
def build_new_cards_index(self) -> str:
# .
# .
index_name = "cards-" + datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# .
# .
self.create_empty_cards_index(index_name)
# .
#
# .
for card in self.card_dao.get_all():
self.put_card_into_index(card, index_name)
return index_name
def create_empty_cards_index(self, index_name):
...
def put_card_into_index(self, card: Card, index_name: str):
...
def switch_current_cards_index(self, new_index_name: str):
...
Indexación: creación de un índice
Un índice en Elasticsearch se crea mediante una simple solicitud PUT
/-o, en el caso de usar un cliente Python (en nuestro caso), llamando
elasticsearch_client.indices.create(index_name, {
...
})
El cuerpo de la solicitud puede contener tres campos.
- Descripción de alias (
"aliases": ...). El sistema de alias le permite mantener el conocimiento de qué índice está actualmente actualizado en el lado de Elasticsearch; hablaremos de ello a continuación. - Configuración (
"settings": ...). Cuando seamos grandes con producción real, podremos configurar la replicación, la fragmentación y otros placeres de SRE aquí. - Esquema de datos (
"mappings": ...). Aquí podemos especificar qué tipo de campos en los documentos que indexaremos, para cuál de estos campos necesitamos índices inversos, para qué agregaciones se deben admitir, etc.
Ahora solo nos interesa el esquema, y lo tenemos muy sencillo:
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
},
"text": {
"type": "text",
"analyzer": "english"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Hemos marcado el campo
name, y textcomo el texto en inglés. Un analizador es una entidad en Elasticsearch que procesa texto antes de almacenarlo en un índice. En el caso del englishanalizador, el texto se dividirá en tokens a lo largo de los límites de las palabras ( detalles ), después de lo cual los tokens individuales se lematizarán de acuerdo con las reglas del idioma inglés (por ejemplo, la palabra treesse simplificará tree), these eliminarán los lemas demasiado generales (como ) y los lemas restantes se colocarán en el índice inverso.
El campo es un
tagspoco más complicado. Un tipokeywordasume que los valores de este campo son algunas constantes de cadena que no necesitan ser procesadas por el analizador; el índice inverso se construirá en función de sus valores "brutos", sin tokenización ni lematización. Pero Elasticsearch creará estructuras de datos especiales para que las agregaciones puedan ser leídas por los valores de este campo (por ejemplo, para que, simultáneamente con la búsqueda, pueda averiguar qué etiquetas se encontraron en documentos que satisfacen la consulta de búsqueda y en qué cantidad). Esto es ideal para campos que son esencialmente enumeración; Usaremos esta función para hacer algunos filtros de búsqueda geniales.
Pero para que el texto de las etiquetas se pueda buscar también mediante búsqueda de texto, le agregamos un subcampo
"text", configurado por analogía con nameytextarriba - en esencia, esto significa que Elasticsearch creará otro campo "virtual" bajo el nombre en todos los documentos que lleguen a él tags.text, en el cual copiará el contenido tags, pero lo indexará de acuerdo con diferentes reglas.
Indexación: llenar el índice
Para indexar un documento, es suficiente realizar una solicitud PUT
/-/_create/id-o, cuando se usa un cliente Python, simplemente llamar al método requerido. Nuestra implementación se verá así:
def put_card_into_index(self, card: Card, index_name: str):
self.elasticsearch_client.create(index_name, card.id, {
"name": card.name,
"text": card.markdown,
"tags": card.tags,
})
Presta atención al campo
tags. Aunque lo describimos como que contiene una palabra clave, no estamos enviando una sola cadena, sino una lista de cadenas. Elasticsearch admite esto; nuestro documento se ubicará en cualquiera de los valores.
Indexación: cambiar el índice
Para implementar una búsqueda, necesitamos saber el nombre del índice completamente construido más reciente. El mecanismo de alias nos permite mantener esta información en el lado de Elasticsearch.
Un alias es un puntero a cero o más índices. La API de Elasticsearch le permite utilizar un nombre de alias en lugar de un nombre de índice al realizar una búsqueda (POST en
/-/_searchlugar de POST /-/_search); en este caso, Elasticsearch buscará todos los índices apuntados por el alias.
Crearemos un alias llamado
cards, que siempre apuntará al índice actual. En consecuencia, cambiar al índice real después de la finalización de la construcción se verá así:
def switch_current_cards_index(self, new_index_name: str):
try:
# , .
remove_actions = [
{
"remove": {
"index": index_name,
"alias": self.cards_index_alias,
}
}
for index_name in self.elasticsearch_client.indices.get_alias(name=self.cards_index_alias)
]
except NotFoundError:
# , - .
# , .
remove_actions = []
#
# .
self.elasticsearch_client.indices.update_aliases({
"actions": remove_actions + [{
"add": {
"index": new_index_name,
"alias": self.cards_index_alias,
}
}]
})
No entraré en más detalles sobre la API de alias; todos los detalles se pueden encontrar en la documentación .
Aquí es necesario hacer una observación de que en un servicio realmente muy cargado, tal cambio puede ser bastante doloroso y puede tener sentido hacer un calentamiento preliminar: cargue el nuevo índice con algún tipo de grupo de consultas de usuario guardadas.
Todo el código que implementa la indexación se puede encontrar en esta confirmación .
Indexación: agregar contenido
Para la demostración en este artículo, estoy usando datos del conjunto de datos de películas TMDB 5000 . Para evitar problemas de derechos de autor, solo proporciono el código de la utilidad que los importa desde un archivo CSV, que le sugiero que lo descargue usted mismo del sitio web de Kaggle. Después de descargar, simplemente ejecute el comando
docker-compose exec -T backend python -m tools.add_movies < ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv
para crear cinco mil tarjetas de películas y un equipo
docker-compose exec backend python -m tools.build_index
para construir un índice. Tenga en cuenta que el último comando no crea realmente el índice, sino que solo coloca la tarea en la cola de tareas, después de lo cual se ejecutará en el trabajador; analicé este enfoque con más detalle en el último artículo .
docker-compose logs worker¡Muestre cómo lo intentó el trabajador!
Antes de comenzar, de hecho, la búsqueda, queremos ver con nuestros propios ojos si algo está escrito en Elasticsearch, y si es así, ¡cómo se ve!
La forma más directa y rápida de hacer esto es usar la API HTTP de Elasticsearch. Primero, verifiquemos a dónde apunta el alias:
$ curl -s localhost:9200/_cat/aliases
cards cards-2020-09-20-16-14-18 - - - -
Genial, ¡el índice existe! Veámoslo de cerca:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18 | jq
{
"cards-2020-09-20-16-14-18": {
"aliases": {
"cards": {}
},
"mappings": {
...
},
"settings": {
"index": {
"creation_date": "1600618458522",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "iLX7A8WZQuCkRSOd7mjgMg",
"version": {
"created": "7050199"
},
"provided_name": "cards-2020-09-20-16-14-18"
}
}
}
}
Finalmente, echemos un vistazo a su contenido:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18/_search | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4704,
"relation": "eq"
},
"max_score": 1,
"hits": [
...
]
}
}
En total, nuestro índice es de 4704 documentos, y en el campo
hits(que me salté porque es demasiado grande) incluso se puede ver el contenido de algunos de ellos. ¡Éxito!
Una forma más conveniente de explorar el contenido del índice y, en general, todo tipo de mimos con Elasticsearch sería usar Kibana . Agreguemos el contenedor a
docker-compose.yml:
services:
...
kibana:
image: "kibana:7.5.1"
ports:
- "5601:5601"
depends_on:
- elasticsearch
...
Después de una segunda vez,
docker-compose uppodemos ir a Kibana en la dirección localhost:5601(atención, es posible que el servidor no se inicie rápidamente) y, después de una breve configuración, ver el contenido de nuestros índices en una bonita interfaz web.
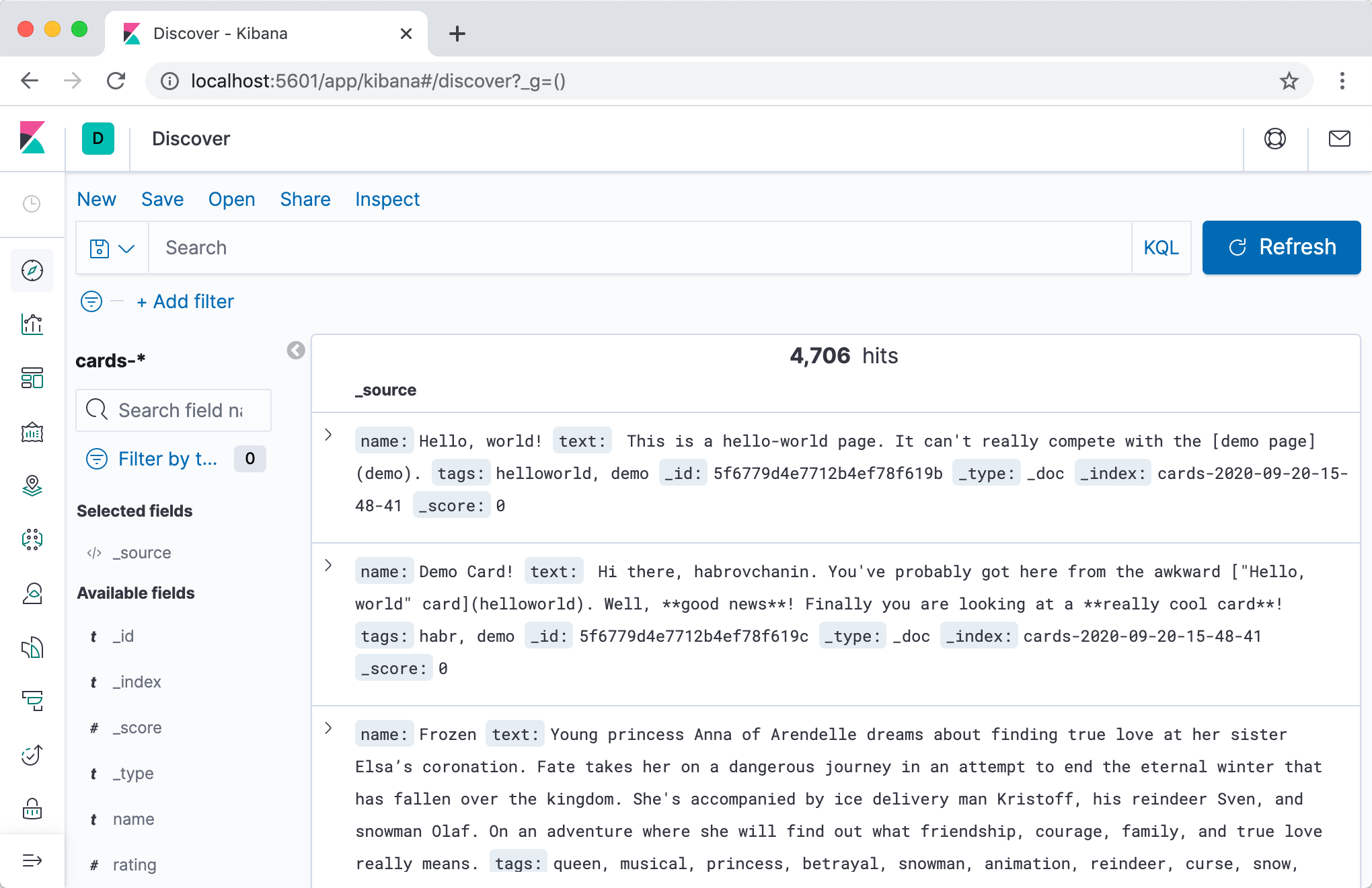
Recomiendo encarecidamente la pestaña Herramientas de desarrollo: durante el desarrollo, a menudo necesitará realizar ciertas solicitudes en Elasticsearch, y en modo interactivo con autocompletado y formateo automático es mucho más conveniente.
Buscar
Después de todos los preparativos increíblemente aburridos, ¡es hora de que agreguemos la funcionalidad de búsqueda a nuestra aplicación web!
Dividamos esta tarea no trivial en tres etapas y analicemos cada una por separado.
- Agregue un componente
Searcherresponsable de la lógica de búsqueda al backend . Formará una consulta a Elasticsearch y convertirá los resultados en más digeribles para nuestro backend. - Agrega un punto final a la API (manejar / ruta / ¿cómo lo llamas en tu empresa?) Que
/cards/searchrealiza la búsqueda. Llamará al método del componenteSearcher, procesará los resultados y se lo devolverá al cliente. - Implementemos la interfaz de búsqueda en la interfaz. Se pondrá en contacto
/cards/searchcuando el usuario haya decidido lo que quiere buscar y mostrará los resultados (y, posiblemente, algunos controles adicionales).
Búsqueda: implementamos
No es tan difícil escribir un administrador de búsqueda como diseñar uno. Describamos el resultado de la búsqueda y la interfaz del administrador y analicemos por qué es esto y no diferente.
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0) -> CardSearchResult:
pass
Algunas cosas son obvias. Por ejemplo, paginación. Somos una joven y ambiciosa empresa emergente de
Algunos son menos obvios. Por ejemplo, una lista de identificaciones, no tarjetas como resultado. Elasticsearch almacena todos nuestros documentos de forma predeterminada y los devuelve en los resultados de búsqueda. Este comportamiento se puede desactivar para ahorrar en el tamaño del índice de búsqueda, pero para nosotros esto es claramente una optimización prematura. Entonces, ¿por qué no devolver las tarjetas de inmediato? Respuesta: esto violaría el principio de responsabilidad única. Quizás algún día terminemos con una lógica compleja en el administrador de tarjetas que traduce las tarjetas a otros idiomas dependiendo de la configuración del usuario. Exactamente en este momento, los datos de la página de la tarjeta y los datos de los resultados de búsqueda estarán dispersos, porque nos olvidaremos de agregar la misma lógica al administrador de búsqueda. Y así sucesivamente y así sucesivamente.
La implementación de esta interfaz es tan simple que me dio pereza escribir esta sección :-(
# backend/backend/search/searcher_impl.py
from typing import Any
from elasticsearch import Elasticsearch
from backend.search.searcher import CardSearchResult, Searcher
ElasticsearchQuery = Any #
class ElasticsearchSearcher(Searcher):
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query
})
total_count = result["hits"]["total"]["value"]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
)
def _make_text_query(self, query: str) -> ElasticsearchQuery:
return {
# Multi-match query
# ( match
# query, ).
"multi_match": {
"query": query,
# ^ – .
# , .
"fields": ["name^3", "tags.text", "text"],
}
}
_match_all_query: ElasticsearchQuery = {"match_all": {}}
De hecho, simplemente vamos a la API de Elasticsearch y extraemos cuidadosamente los ID de las tarjetas encontradas del resultado.
La implementación del punto final también es bastante trivial:
# backend/backend/server.py
...
def search_cards(self):
request = flask.request.json
search_result = self.wiring.searcher.search_cards(**request)
cards = self.wiring.card_dao.get_by_ids(search_result.card_ids)
return flask.jsonify({
"totalCount": search_result.total_count,
"cards": [
{
"id": card.id,
"slug": card.slug,
"name": card.name,
# ,
# ,
# .
} for card in cards
],
"nextCardOffset": search_result.next_card_offset,
})
...
La implementación de la interfaz usando este punto final, aunque voluminosa, es generalmente bastante sencilla y en este artículo no quiero detenerme en ello. El código completo se puede ver en esta confirmación .

Hasta ahora todo bien, sigamos adelante.
 Búsqueda: agregar filtros
Búsqueda: agregar filtros
Las búsquedas de texto son geniales, pero si alguna vez ha buscado recursos serios, probablemente haya visto todo tipo de beneficios como filtros.
Nuestras descripciones de películas de la base de datos TMDB 5000 tienen etiquetas además de títulos y descripciones, así que implementemos filtros por etiquetas para la capacitación. Nuestro objetivo está en la captura de pantalla: cuando haces clic en una etiqueta, solo las películas con esta etiqueta deben permanecer en los resultados de búsqueda (su número se indica entre paréntesis al lado).

Para implementar filtros, necesitamos resolver dos problemas.
- Aprenda a comprender a pedido qué conjunto de filtros está disponible. No queremos mostrar todos los valores de filtro posibles en cada pantalla, porque hay muchos y la mayoría de ellos conducirán a un resultado vacío; debe comprender qué etiquetas tienen los documentos encontrados por solicitud e, idealmente, dejar la N más popular.
- Para aprender, de hecho, a aplicar un filtro: dejar en los resultados de búsqueda solo los documentos con etiquetas, el filtro por el que el usuario ha elegido.
El segundo en Elasticsearch se implementa simplemente a través de la API de consulta (ver términos de consulta ), el primero es a través de un mecanismo de agregación un poco menos trivial .
Entonces, necesitamos saber qué etiquetas se encuentran en las tarjetas encontradas y poder filtrar tarjetas con las etiquetas necesarias. Primero, actualice el diseño del administrador de búsqueda:
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class TagStats:
tag: str
cards_count: int
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
tag_stats: Iterable[TagStats]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0,
tags: Optional[Iterable[str]] = None) -> CardSearchResult:
pass
Ahora pasemos a la implementación. Lo primero que debemos hacer es iniciar una agregación por el campo
tags:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -10,6 +10,8 @@ ElasticsearchQuery = Any
class ElasticsearchSearcher(Searcher):
+ TAGS_AGGREGATION_NAME = "tags_aggregation"
+
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
@@ -18,7 +20,12 @@ class ElasticsearchSearcher(Searcher):
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query,
+ "aggregations": {
+ self.TAGS_AGGREGATION_NAME: {
+ "terms": {"field": "tags"}
+ }
+ }
})
Ahora, en el resultado de búsqueda de Elasticsearch, vendrá un campo
aggregationsdel cual, usando una clave, TAGS_AGGREGATION_NAMEpodemos obtener cubos que contienen información sobre qué valores están en el campo tagspara los documentos encontrados y con qué frecuencia ocurren. Extraigamos estos datos y devuélvalos como se diseñó anteriormente:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -28,10 +28,15 @@ class ElasticsearchSearcher(Searcher):
total_count = result["hits"]["total"]["value"]
+ tag_stats = [
+ TagStats(tag=bucket["key"], cards_count=bucket["doc_count"])
+ for bucket in result["aggregations"][self.TAGS_AGGREGATION_NAME]["buckets"]
+ ]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
+ tag_stats=tag_stats,
)
Agregar una aplicación de filtro es la parte más fácil:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -16,11 +16,17 @@ class ElasticsearchSearcher(Searcher):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
- def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
+ def search_cards(self, query: str = "", count: int = 20, offset: int = 0,
+ tags: Optional[Iterable[str]] = None) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
- "query": self._make_text_query(query) if query else self._match_all_query,
+ "query": {
+ "bool": {
+ "must": self._make_text_queries(query),
+ "filter": self._make_filter_queries(tags),
+ }
+ },
"aggregations": {
Las subconsultas incluidas en la cláusula must son obligatorias, pero también se tendrán en cuenta al calcular la velocidad de los documentos y, en consecuencia, la clasificación; si alguna vez agregamos más condiciones a los textos, es mejor agregarlas aquí. Las subconsultas en la cláusula de filtro solo filtran sin afectar la velocidad y la clasificación.
Queda por implementar
_make_filter_queries():
def _make_filter_queries(self, tags: Optional[Iterable[str]] = None) -> List[ElasticsearchQuery]:
return [] if tags is None else [{
"term": {
"tags": {
"value": tag
}
}
} for tag in tags]
Una vez más, no me detendré en la parte frontal; todo el código está en este compromiso .
Rango
Entonces, nuestra búsqueda busca tarjetas, las filtra de acuerdo con una lista determinada de etiquetas y las muestra en algún orden. ¿Pero cual? El orden es muy importante para una búsqueda práctica, pero todo lo que hicimos durante nuestro litigio en términos de orden fue sugerido a Elasticsearch que es más rentable encontrar palabras en el encabezado de la tarjeta que en la descripción o etiquetas especificando la prioridad
^3en la consulta de múltiples coincidencias.
A pesar de que, de forma predeterminada, Elasticsearch clasifica los documentos con una fórmula basada en TF-IDF bastante complicada, para nuestra ambiciosa startup imaginaria, esto no es suficiente. Si nuestros documentos son mercancías, debemos poder contabilizar sus ventas; si se trata de contenido generado por el usuario, poder tener en cuenta su frescura, etc. Pero no podemos simplemente ordenar por el número de ventas / fecha de adición, porque entonces no tendremos en cuenta la relevancia para la consulta de búsqueda.
La clasificación es un ámbito tecnológico amplio y confuso que no se puede cubrir en una sección al final de este artículo. Así que aquí estoy cambiando a trazos grandes; Trataré de decirle en los términos más generales cómo se puede organizar la clasificación de grado industrial en la búsqueda, y revelaré algunos detalles técnicos de cómo se puede implementar con Elasticsearch.
La tarea de clasificar es muy compleja, por lo que no es de extrañar que uno de los principales métodos modernos para resolverlo sea el aprendizaje automático. La aplicación de tecnologías de aprendizaje automático para clasificar se denomina colectivamente aprender a clasificar .
Un proceso típico se ve así.
Decidimos lo que queremos clasificar . Colocamos las entidades que nos interesan en el índice, aprendemos cómo obtener una parte superior razonable (por ejemplo, una clasificación y un corte simples) de estas entidades para una consulta de búsqueda determinada, y ahora queremos aprender cómo clasificarlas de una manera más inteligente.
Determinando cómo queremos clasificar... Decidimos sobre qué característica queremos clasificar nuestros resultados de acuerdo con los objetivos comerciales de nuestro servicio. Por ejemplo, si nuestras entidades son productos que vendemos, es posible que deseemos clasificarlos en orden descendente de probabilidad de compra; si memes - por probabilidad de me gusta o compartir, etc. Nosotros, por supuesto, no sabemos cómo calcular estas probabilidades, en el mejor de los casos podemos estimar, e incluso entonces solo para entidades antiguas para las que tenemos suficientes estadísticas, pero intentaremos enseñar al modelo a predecirlas en función de signos indirectos.
Extrayendo signos... Creamos un conjunto de características para nuestras entidades que podrían ayudarnos a evaluar la relevancia de las entidades para las consultas de búsqueda. Además del mismo TF-IDF, que ya sabe calcular Elasticsearch por nosotros, un ejemplo típico es CTR (click-through rate): tomamos los logs de nuestro servicio para todo el tiempo, para cada par de entidad + consulta de búsqueda, contamos cuántas veces apareció la entidad en los resultados de búsqueda. para esta solicitud y cuántas veces se hizo clic en ella, dividimos una por otra, et voilà: la estimación más simple de la probabilidad de clic condicional está lista. También podemos crear rasgos específicos del usuario y rasgos emparejados por entidad de usuario para personalizar las clasificaciones. Habiendo creado los signos, escribimos un código que los calcula, los coloca en algún tipo de almacenamiento y sabe cómo darlos en tiempo real para una consulta de búsqueda, un usuario y un conjunto de entidades dados.
Elaboración de un conjunto de datos de entrenamiento . Hay muchas opciones, pero todas ellas, por regla general, se forman a partir de los registros de eventos "buenos" (por ejemplo, un clic y luego una compra) y "malos" (por ejemplo, un clic y volver a emitir) en nuestro servicio. Cuando hemos reunido un conjunto de datos, ya sea una lista de afirmaciones "la evaluación de la relevancia del producto X para consultar Q es aproximadamente igual a P", una lista de pares "el producto X es más relevante para el producto Y para consultar Q" o un conjunto de listas "para la consulta Q, los productos P 1 , P 2 , ... clasifican correctamente así -que ”, ajustamos los signos correspondientes a todas las líneas que aparecen en él.
Entrenamos al modelo . Aquí están todos los clásicos de ML: train / test, hiperparámetros, reentrenamiento,
Incrustamos el modelo . Nos queda atornillar de alguna manera el cálculo del modelo sobre la marcha para toda la parte superior, para que los resultados ya clasificados lleguen al usuario. Hay muchas opciones; con fines ilustrativos, me centraré (nuevamente) en un simple complemento de Elasticsearch, Learning to Rank .
Clasificación: plugin de aprendizaje de clasificación de Elasticsearch
Elasticsearch Learning to Rank es un complemento que agrega a Elasticsearch la capacidad de calcular un modelo ML en el SERP y clasificar inmediatamente los resultados de acuerdo con las tasas calculadas. También nos ayudará a obtener características idénticas a las que se utilizan en tiempo real, mientras reutilizamos las capacidades de Elasticsearch (TF-IDF y similares).
Primero, necesitamos conectar el complemento en nuestro contenedor con Elasticsearch. Necesitamos un Dockerfile simple
# elasticsearch/Dockerfile
FROM elasticsearch:7.5.1
RUN ./bin/elasticsearch-plugin install --batch http://es-learn-to-rank.labs.o19s.com/ltr-1.1.2-es7.5.1.zip
y cambios relacionados a
docker-compose.yml:
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,7 +5,8 @@ services:
elasticsearch:
- image: "elasticsearch:7.5.1"
+ build:
+ context: elasticsearch
environment:
- discovery.type=single-node
También necesitamos compatibilidad con complementos en el cliente Python. Con asombro, descubrí que el soporte para Python no se completa con el complemento, por lo que especialmente para este artículo lo tengo aclarado . Añadir
elasticsearch_ltra requirements.txty actualizar el cliente de cableado:
--- a/backend/backend/wiring.py
+++ b/backend/backend/wiring.py
@@ -1,5 +1,6 @@
import os
+from elasticsearch_ltr import LTRClient
from celery import Celery
from elasticsearch import Elasticsearch
from pymongo import MongoClient
@@ -39,5 +40,6 @@ class Wiring(object):
self.task_manager = TaskManager(self.celery_app)
self.elasticsearch_client = Elasticsearch(hosts=self.settings.ELASTICSEARCH_HOSTS)
+ LTRClient.infect_client(self.elasticsearch_client)
self.indexer = Indexer(self.elasticsearch_client, self.card_dao, self.settings.CARDS_INDEX_ALIAS)
self.searcher: Searcher = ElasticsearchSearcher(self.elasticsearch_client, self.settings.CARDS_INDEX_ALIAS)
Clasificación: aserrar señales
Cada solicitud en Elasticsearch devuelve no solo una lista de ID de documentos que se encontraron, sino también algunos de ellos pronto (¿cómo traduciría la palabra puntuación al ruso?). Entonces, si esta es una consulta de coincidencia o de coincidencia múltiple que estamos usando, entonces rápido es el resultado de calcular esa fórmula tan complicada que involucra TF-IDF; si la consulta bool es una combinación de tasas de consulta anidadas; si consulta de puntuación de función- el resultado de calcular una función determinada (por ejemplo, el valor de algún campo numérico en un documento), y así sucesivamente. El complemento ELTR nos brinda la capacidad de usar la velocidad de cualquier solicitud como un signo, lo que nos permite combinar fácilmente datos sobre qué tan bien el documento coincide con la solicitud (a través de una consulta de coincidencia múltiple) y algunas estadísticas precalculadas que colocamos en el documento por adelantado (a través de la consulta de puntuación de función) ...
Dado que tenemos una base de datos TMDB 5000 en nuestras manos, que contiene descripciones de películas y, entre otras cosas, sus calificaciones, consideremos la calificación como una característica precalculada ejemplar.
En este compromisoAgregué algo de infraestructura básica para almacenar funciones en el backend de nuestra aplicación web y apoyé la carga de la calificación desde el archivo de la película. Para no forzarte a leer otro montón de código, describiré el más básico.
- Almacenaremos las funciones en una colección separada y las obtendremos por un administrador separado. Volcar todos los datos en una entidad es una mala práctica.
- Nos pondremos en contacto con este administrador en la etapa de indexación y pondremos todas las funciones disponibles en los documentos indexados.
- Para conocer el esquema de índice, necesitamos conocer la lista de todas las características existentes antes de comenzar a construir el índice. Vamos a codificar esta lista por ahora.
- Dado que no vamos a filtrar documentos por valores de atributo, sino que solo los vamos a extraer de documentos ya encontrados para calcular el modelo, desactivaremos la construcción de índices inversos por nuevos campos con una opción
index: falseen el esquema y ahorraremos un poco de espacio debido a esto.
Clasificación: recopilar el conjunto de datos
Ya que, en primer lugar, no tenemos la producción, y en segundo lugar, los márgenes de este artículo son demasiado pequeños para hablar de telemetría, Kafka, NIFI, Hadoop, la chispa y la construcción de los procesos ETL, que se acaba de generar vistas al azar y los clics de nuestras tarjetas y algún tipo de consultas de búsqueda. Después de eso, deberá calcular las características de los pares de solicitud de tarjeta resultantes.
Es hora de profundizar en la API del complemento ELTR. Para calcular las características, necesitaremos crear una entidad de tienda de características (hasta donde tengo entendido, esto es en realidad solo un índice en Elasticsearch en el que el complemento almacena todos sus datos), luego crear un conjunto de características, una lista de características con una descripción de cómo calcular cada una de ellas. Después de eso, será suficiente que vayamos a Elasticsearch con una solicitud especial para obtener un vector de valores de características para cada entidad encontrada como resultado.
Comencemos por crear un conjunto de características:
# backend/backend/search/ranking.py
from typing import Iterable, List, Mapping
from elasticsearch import Elasticsearch
from elasticsearch_ltr import LTRClient
from backend.search.features import CardFeaturesManager
class SearchRankingManager:
DEFAULT_FEATURE_SET_NAME = "card_features"
def __init__(self, elasticsearch_client: Elasticsearch,
card_features_manager: CardFeaturesManager,
cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.card_features_manager = card_features_manager
self.cards_index_name = cards_index_name
def initialize_ranking(self, feature_set_name=DEFAULT_FEATURE_SET_NAME):
ltr: LTRClient = self.elasticsearch_client.ltr
try:
# feature store ,
# ¯\_(ツ)_/¯
ltr.create_feature_store()
except Exception as exc:
if "resource_already_exists_exception" not in str(exc):
raise
# feature set !
ltr.create_feature_set(feature_set_name, {
"featureset": {
"features": [
#
# ,
# ,
# .
self._make_feature("name_tf_idf", ["query"], {
"match": {
# ELTR
# , .
# , ,
# ,
# match query.
"name": "{{query}}"
}
}),
# , .
self._make_feature("combined_tf_idf", ["query"], {
"multi_match": {
"query": "{{query}}",
"fields": ["name^3", "tags.text", "text"]
}
}),
*(
#
# function score.
# -
# , 0.
# (
# !)
self._make_feature(feature_name, [], {
"function_score": {
"field_value_factor": {
"field": feature_name,
"missing": 0
}
}
})
for feature_name in sorted(self.card_features_manager.get_all_feature_names_set())
)
]
}
})
@staticmethod
def _make_feature(name, params, query):
return {
"name": name,
"params": params,
"template_language": "mustache",
"template": query,
}
Ahora, una función que calcula características para una consulta y tarjetas determinadas:
def compute_cards_features(self, query: str, card_ids: Iterable[str],
feature_set_name=DEFAULT_FEATURE_SET_NAME) -> Mapping[str, List[float]]:
card_ids = list(card_ids)
result = self.elasticsearch_client.search({
"query": {
"bool": {
# ,
# — ,
# .
# ID.
"filter": [
{
"terms": {
"_id": card_ids
}
},
# — ,
# SLTR.
#
# feature set.
# ( ,
# filter, .)
{
"sltr": {
"_name": "logged_featureset",
"featureset": feature_set_name,
"params": {
# .
# , ,
#
# {{query}}.
"query": query
}
}
}
]
}
},
#
# .
"ext": {
"ltr_log": {
"log_specs": {
"name": "log_entry1",
"named_query": "logged_featureset"
}
}
},
"size": len(card_ids),
})
# (
# ) .
# ( ,
# , Kibana.)
return {
hit["_id"]: [feature.get("value", float("nan")) for feature in hit["fields"]["_ltrlog"][0]["log_entry1"]]
for hit in result["hits"]["hits"]
}
Un script simple que acepta CSV con solicitudes y tarjetas de identificación como entrada y genera CSV con las siguientes características:
# backend/tools/compute_movie_features.py
import csv
import itertools
import sys
import tqdm
from backend.wiring import Wiring
if __name__ == "__main__":
wiring = Wiring()
reader = iter(csv.reader(sys.stdin))
header = next(reader)
feature_names = wiring.search_ranking_manager.get_feature_names()
writer = csv.writer(sys.stdout)
writer.writerow(["query", "card_id"] + feature_names)
query_index = header.index("query")
card_id_index = header.index("card_id")
chunks = itertools.groupby(reader, lambda row: row[query_index])
for query, rows in tqdm.tqdm(chunks):
card_ids = [row[card_id_index] for row in rows]
features = wiring.search_ranking_manager.compute_cards_features(query, card_ids)
for card_id in card_ids:
writer.writerow((query, card_id, *features[card_id]))
¡Finalmente, puedes ejecutarlo todo!
# feature set
docker-compose exec backend python -m tools.initialize_search_ranking
#
docker-compose exec -T backend \
python -m tools.generate_movie_events \
< ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv \
> ~/Downloads/habr-app-demo-dataset-events.csv
#
docker-compose exec -T backend \
python -m tools.compute_features \
< ~/Downloads/habr-app-demo-dataset-events.csv \
> ~/Downloads/habr-app-demo-dataset-features.csv
Ahora tenemos dos archivos, con eventos y señales, y podemos comenzar a entrenar.
Ranking: capacitar e implementar el modelo
Saltemos los detalles de la carga de conjuntos de datos (puede ver el script completo en esta confirmación ) y vayamos directo al grano.
# backend/tools/train_model.py
...
if __name__ == "__main__":
args = parser.parse_args()
feature_names, features = read_features(args.features)
events = read_events(args.events)
# train test 4 1.
all_queries = set(events.keys())
train_queries = random.sample(all_queries, int(0.8 * len(all_queries)))
test_queries = all_queries - set(train_queries)
# DMatrix — , xgboost.
#
# . 1, ,
# 0, ( . ).
train_dmatrix = make_dmatrix(train_queries, events, feature_names, features)
test_dmatrix = make_dmatrix(test_queries, events, feature_names, features)
# !
#
# ML,
# XGBoost.
param = {
"max_depth": 2,
"eta": 0.3,
"objective": "binary:logistic",
"eval_metric": "auc",
}
num_round = 10
booster = xgboost.train(param, train_dmatrix, num_round, evals=((train_dmatrix, "train"), (test_dmatrix, "test")))
# .
booster.dump_model(args.output, dump_format="json")
# , :
# ROC-.
xgboost.plot_importance(booster)
plt.figure()
build_roc(test_dmatrix.get_label(), booster.predict(test_dmatrix))
plt.show()
Lanzamiento
python backend/tools/train_search_ranking_model.py \
--events ~/Downloads/habr-app-demo-dataset-events.csv \
--features ~/Downloads/habr-app-demo-dataset-features.csv \
-o ~/Downloads/habr-app-demo-model.xgb
Tenga en cuenta que, dado que exportamos todos los datos necesarios con los scripts anteriores, este script ya no necesita ejecutarse dentro de la ventana acoplable; debe ejecutarse en su máquina, habiendo instalado previamente
xgboosty sklearn. De manera similar, en la producción real, los scripts anteriores deberían ejecutarse en algún lugar donde haya acceso al entorno de producción, pero este no.
Si todo se hace correctamente, la modelo se entrenará con éxito y veremos dos bellas imágenes. El primero es un gráfico de la importancia de las características:

aunque los eventos se generaron al azar,
combined_tf_idfresultó ser mucho más significativo que otros, porque hice un truco y reduje artificialmente la probabilidad de un clic para las cartas que están más bajas en el SERP, clasificadas a nuestra manera anterior. El hecho de que el modelo haya notado esto es una buena señal y una señal de que no cometimos ningún error completamente estúpido en el proceso de aprendizaje.
El segundo gráfico es la curva ROC :

la línea azul está por encima de la línea roja, lo que significa que nuestro modelo predice etiquetas un poco mejor que un lanzamiento de moneda. (La curva del ingeniero de ML de la amiga de mamá casi debería tocar la esquina superior izquierda).
El asunto es bastante pequeño: agregamos un script para completar el modelo , lo completamos y agregamos un pequeño elemento nuevo a la consulta de búsqueda: resignación:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -27,6 +30,19 @@ class ElasticsearchSearcher(Searcher):
"filter": list(self._make_filter_queries(tags, ids)),
}
},
+ "rescore": {
+ "window_size": 1000,
+ "query": {
+ "rescore_query": {
+ "sltr": {
+ "params": {
+ "query": query
+ },
+ "model": self.ranking_manager.get_current_model_name()
+ }
+ }
+ }
+ },
"aggregations": {
self.TAGS_AGGREGATION_NAME: {
"terms": {"field": "tags"}
Ahora, después de que Elasticsearch realice la búsqueda que necesitamos y clasifique los resultados con su algoritmo (bastante rápido), tomaremos los 1000 mejores resultados y los volveremos a clasificar usando nuestra fórmula (relativamente lenta) de aprendizaje automático. ¡Éxito!
Conclusión
Tomamos nuestra aplicación web minimalista y pasamos de no tener una función de búsqueda per se a una solución escalable con muchas funciones avanzadas. Esto no fue tan fácil de hacer. ¡Pero tampoco es tan difícil! La aplicación final se encuentra en el repositorio de Github en una rama con un nombre modesto
feature/searchy requiere Docker y Python 3 con bibliotecas de aprendizaje automático para ejecutarse.
Usé Elasticsearch para mostrar cómo funciona esto en general, qué problemas se encuentran y cómo se pueden resolver, pero ciertamente esta no es la única herramienta para elegir. Solr , los índices de texto completo de PostgreSQL y otros motores también merecen su atención al elegir en qué construir su
Y, por supuesto, esta solución no pretende estar completa y lista para la producción, sino que es puramente una ilustración de cómo se puede hacer todo. ¡Puedes mejorarlo casi infinitamente!
- Indexación incremental. Al modificar nuestras tarjetas
CardManager, sería bueno actualizarlas inmediatamente en el índice. ParaCardManagerno saber que también tenemos una búsqueda en el servicio, y prescindir de dependencias cíclicas, tendremos que atornillar la inversión de dependencias de una forma u otra. - Para indexar en nuestro caso particular, MongoDB se combina con Elasticsearch, puede usar soluciones listas para usar como mongo-connector .
- , — Elasticsearch .
- , , .
- , , . -, -, - … !
- ( , ), ( ). , .
- , , .
- Orquestar un grupo de nodos con fragmentación y replicación es un placer completamente independiente.
Pero para mantener el tamaño del artículo legible, me detendré allí y los dejaré en paz con estos desafíos. ¡Gracias por la atención!