Prólogo
Comencemos con la programación lógica y el lenguaje Prolog. El conocimiento sobre el área temática se presenta en él como un conjunto de hechos y reglas. Los hechos describen el conocimiento inmediato. Los datos sobre clientes (ID, nombre y dirección de correo electrónico) y facturas (ID de cuenta, cliente, fecha, monto adeudado y monto pagado) del ejemplo de la publicación anterior se verían así
client(1, "John", "john@somewhere.net").
bill(1, 1,"2020-01", 100, 50).Las reglas describen el conocimiento abstracto que se puede inferir de otras reglas y hechos. La regla consta de una cabeza y un cuerpo. En el encabezado de la regla, debe especificar su nombre y una lista de argumentos. El cuerpo de una regla es una lista de predicados conectados por operaciones lógicas AND (especificado por una coma) y OR (especificado por un punto y coma). Los predicados pueden ser hechos, reglas o predicados incorporados, como operaciones de comparación, operaciones aritméticas, etc. La relación entre los argumentos del encabezado de la regla y los argumentos de los predicados en su cuerpo se establece mediante variables booleanas; si la misma variable está en las posiciones de dos argumentos diferentes, Esto significa que estos argumentos son idénticos. Una regla se considera verdadera cuando la expresión lógica del cuerpo de la regla es verdadera. El modelo de dominio se puede definir como un conjunto de reglas de referencia:
unpaidBill(BillId, ClientId, Date, AmoutToPay, AmountPaid) :- bill(BillId, ClientId, Date, AmoutToPay, AmountPaid), AmoutToPay < AmountPaid.
debtor(ClientId, Name, Email) :- client(ClientId, Name, Email), unpaidBill(BillId, ClientId, _, _, _).Hemos establecido dos reglas. En el primero, afirmamos que todas las facturas que tienen menos del monto adeudado son facturas impagas. En el segundo, el deudor es un cliente que tiene al menos una factura impaga.
La sintaxis de Prolog es muy simple: el elemento principal del programa es la regla, los elementos principales de la regla son predicados, operaciones lógicas y variables. En la regla, la atención se centra en las variables: desempeñan el papel de un objeto del mundo modelado y los predicados describen sus propiedades y la relación entre ellas. En la definición de la regla del deudor, establecemos que si los objetos ClientId, Name y Email están relacionados por el cliente y la relación nopaidBill, entonces también estarán relacionados por la relación del deudor. Prolog es útil cuando un problema se formula como un conjunto de reglas, declaraciones o declaraciones lógicas. Por ejemplo, cuando se trabaja con gramática del lenguaje natural, compiladores, en sistemas expertos, en el análisis de sistemas complejos como computadoras, redes de computadoras, objetos de infraestructura. Complejo,Los sistemas de reglas complicados se describen mejor de forma explícita y se dejan al tiempo de ejecución de Prolog para que los maneje automáticamente.
Prolog se basa en la lógica de primer orden (con algunos elementos de lógica de orden superior incluidos). La inferencia se realiza mediante un procedimiento llamado resolución SLD (resolución de cláusula definida lineal selectiva). Simplificado, su algoritmo es un recorrido de árbol de todas las soluciones posibles. El procedimiento de inferencia encuentra todas las soluciones para el primer predicado del cuerpo de la regla. Si el predicado actual en la base de conocimiento está representado solo por hechos, entonces las soluciones son las que corresponden a las vinculaciones actuales de variables a valores. Si es por reglas, entonces se requiere la verificación recursiva de sus predicados anidados. Si no se encuentran soluciones, la rama de búsqueda actual falla. Luego se crea una nueva rama para cada solución parcial encontrada. En cada rama, el procedimiento de inferencia vincula los valores encontrados a las variables,incluido en el predicado actual y busca de forma recursiva una solución para la lista restante de predicados. El trabajo termina cuando se llega al final de la lista de predicados. La búsqueda de una solución puede entrar en un bucle sin fin en el caso de una definición recursiva de reglas. El resultado del procedimiento de búsqueda es una lista de todos los posibles enlaces de valores a variables booleanas.
En el ejemplo anterior para la regla del deudor, la regla de resolución primero encontrará una solución para el predicado del cliente y la asociará con valores booleanos: ClientId = 1, Name = "John", Email = "john@somewhere.net". Luego, para esta variante de valores de variable, se realizará una solución para el siguiente predicado unpaidBill. Para hacer esto, primero necesita encontrar soluciones para la factura de predicado, siempre que ClientId = 1. El resultado serán enlaces para las variables BillId = 1, Date = "2020-01", AmoutToPay = 100, AmountPaid = 50. Al final, AmoutToPay <AmountPaid será verificado en el predicado de comparación incorporado.
Redes semánticas
Las redes semánticas son una de las formas más populares de representar el conocimiento. La Web Semántica es un modelo de información del dominio en forma de gráfico dirigido. Los vértices del gráfico corresponden a los conceptos del dominio y los arcos definen las relaciones entre ellos.
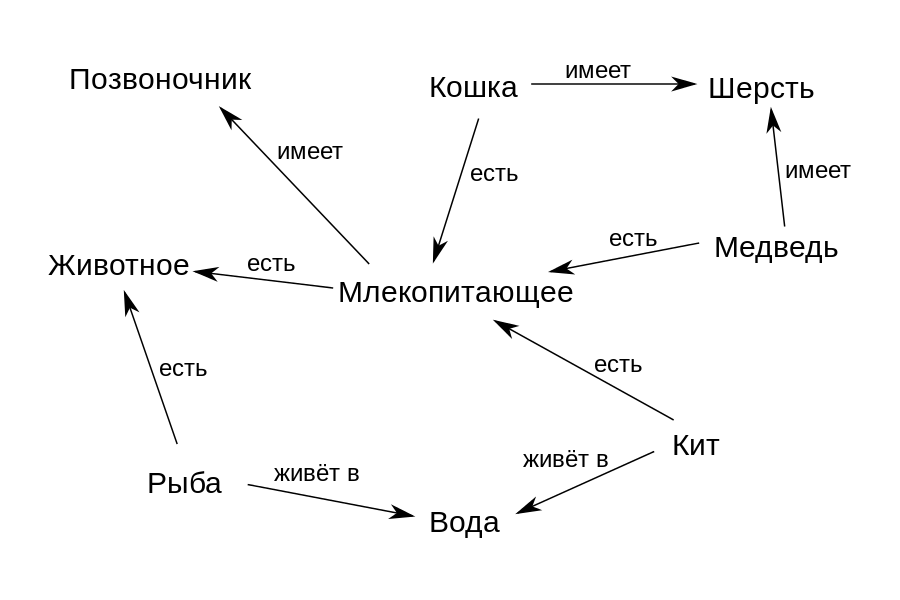
Por ejemplo, según el gráfico de la figura anterior, el concepto de "Ballena" está asociado con la relación "es" ("es") con el concepto de "Mamífero" y "vive en" con el concepto de "Agua". Por lo tanto, podemos establecer formalmente la estructura del área temática: qué conceptos incluye y cómo se relacionan entre sí. Y luego, dicho gráfico se puede utilizar para encontrar respuestas a preguntas y obtener nuevos conocimientos de él. Por ejemplo, podemos deducir el conocimiento de que Whale tiene "Spine" si decidimos que la relación "is" denota una relación clase-subclase, y la subclase "Whale" debería heredar todas las propiedades de su clase "Mammal".
RDF
La web semántica es un intento de construir una red semántica global basada en los recursos de la World Wide Web al estandarizar la presentación de la información en una forma adecuada para el procesamiento de la máquina. Para ello, la información se incrusta adicionalmente en las páginas HTML en forma de atributos especiales de etiquetas HTML, lo que permite describir el significado de su contenido en forma de ontología: un conjunto de hechos, conceptos abstractos y relaciones entre ellos.
El enfoque estándar para describir el modelo semántico de los recursos WEB es RDF (Marco de descripción de recursos o Marco de descripción de recursos). Según él, todos los enunciados deben tener la forma de un triplete "sujeto - predicado - objeto". Por ejemplo, el conocimiento sobre el concepto de "Ballena" se presentará de la siguiente manera: "Ballena" es un sujeto, "vive en" - un predicado, "Agua" - un objeto. Todo el conjunto de dichos enunciados se puede describir utilizando un gráfico dirigido, los sujetos y los objetos son sus vértices, y los predicados son arcos, los arcos de predicados se dirigen de los objetos a los sujetos. Por ejemplo, la ontología del ejemplo animal se puede describir de la siguiente manera:
@prefix : <...some URL...>
@prefix rdf: <http://www.w3.org/1999/02/rdf-schema#>
@prefix rdfs: <http://www.w3.org/2000/01/22-rdf-syntax-ns#>
:Whale rdf:type :Mammal;
:livesIn :Water.
:Fish rdf:type :Animal;
:livesIn :Water.Esta notación se llama Turtle y está destinada a ser legible por humanos. Pero lo mismo se puede escribir en formatos XML, JSON o usando etiquetas y atributos de un documento HTML. Aunque en la notación Turtle los predicados y los objetos se pueden agrupar por tema para facilitar la lectura, en el nivel semántico cada triplete es independiente.
RDF es útil en los casos en que el modelo de datos es complejo y contiene una gran cantidad de tipos de objetos y relaciones entre ellos. Por ejemplo, Wikipedia proporciona acceso al contenido de sus artículos en formato RDF. Los hechos descritos en los artículos están estructurados, se describen sus propiedades y relaciones, incluyendo hechos de otros artículos.
RDFS
Un modelo RDF es un gráfico; de forma predeterminada, no se incluye ninguna semántica adicional. Todos pueden interpretar los enlaces en el gráfico como mejor les parezca. Puede agregar algunos enlaces estándar usando RDF Schema, un conjunto de clases y propiedades para construir ontologías sobre RDF. RDFS le permite describir relaciones estándar entre conceptos, como la pertenencia de un recurso a una determinada clase, una jerarquía entre clases, una jerarquía de propiedades y restringir los posibles tipos de sujeto y objeto.
Por ejemplo, la declaración
:Mammal rdfs:subClassOf :Animal.especifica que "Mamífero" es una subclase del concepto "Animal" y hereda todas sus propiedades. En consecuencia, el concepto de "ballena" también se puede atribuir a la clase "animal". Pero para ello es necesario señalar que los conceptos "Mamífero" y "Animal" son clases:
:Animal rdf:type rdfs:Class.
:Mammal rdf:type rdfs:Class.Además, el predicado puede establecer restricciones sobre los posibles valores de su sujeto y objeto.
Declaración
:livesIn rdfs:range :Environment.indica que el objeto de la relación "vive en" siempre debe ser un recurso perteneciente a la clase "Entorno". Por lo tanto, debemos agregar una afirmación de que el concepto de "Agua" es una subclase del concepto de "Medio Ambiente":
:Water rdf:type :Environment.
:Environment rdf:type rdfs:ClassRDFS le permite describir el esquema de datos: enumerar clases, propiedades, establecer su jerarquía y restricciones sobre sus valores. Y RDF debe llenar este esquema con hechos concretos y definir la relación entre ellos. Ahora podemos hacer una pregunta sobre este gráfico. Esto se puede hacer en un lenguaje de consulta especial SPARQL, que se parece a SQL:
SELECT ?creature
WHERE {
?creature rdf:type :Animal;
:livesIn :Water.
} Esta consulta nos devolverá 2 valores: "Ballena" y "Pez".
Un ejemplo de publicaciones anteriores con cuentas y clientes se puede implementar aproximadamente de la siguiente manera. Con RDF, puede describir un esquema de datos y llenarlo con valores:
:Client1 :name "John";
:email "john@somewhere.net".
:Client2 :name "Mary";
:email "mary@somewhere.net".
:Bill_1 :client :Client1;
:date "2020-01";
:amountToPay 100;
:amountPaid 50.
:Bill_2 :client :Client2;
:date "2020-01";
:amountToPay 80;
:amountPaid 80.Pero conceptos abstractos como "Deudor" y "Facturas no pagadas" del primer artículo de esta serie incluyen operaciones aritméticas y comparación. No encajan en la estructura estática de la red semántica de conceptos. Estos conceptos se pueden expresar mediante consultas SPARQL:
SELECT ?clientName ?clientEmail ?billDate ?amountToPay ?amountPaid
WHERE {
?client :name ?clientName;
:email ?clientEmail.
?bill :client ?client;
:date ?billDate;
:amountToPay ?amountToPay;
:amountPaid ?amountPaid.
FILTER(?amountToPay > ?amountPaid).
}La cláusula WHERE es una lista de patrones triples y condiciones de filtro. Las variables booleanas se pueden sustituir en tripletes, cuyo nombre comienza con "?" La tarea del ejecutor de consultas es encontrar todos los valores posibles de las variables para las cuales todos los patrones de tripletes estarían contenidos en el gráfico y se cumplirían las condiciones de filtrado.
A diferencia de Prolog, donde las reglas se pueden usar para construir otras reglas, en RDF una consulta no es parte de la Web Semántica. No se puede hacer referencia a una solicitud como fuente de datos para otra solicitud. Es cierto que SPARQL tiene la capacidad de representar los resultados de las consultas como un gráfico. Por lo tanto, puede intentar combinar los resultados de la consulta con el gráfico original y ejecutar la nueva consulta en el gráfico combinado. Pero tal decisión claramente iría más allá de la ideología de RDF.
BÚHO
Un componente importante de las tecnologías de la Web Semántica es OWL (Web Ontology Language), un lenguaje para describir ontologías. Con el vocabulario RDFS, puede expresar solo las relaciones más básicas entre conceptos: la jerarquía de clases y relaciones. OWL ofrece un vocabulario mucho más rico. Por ejemplo, puede especificar que dos clases (o dos entidades) sean equivalentes (o diferentes). Esta tarea se encuentra a menudo al combinar ontologías.
Puede crear clases compuestas basadas en la intersección, unión o adición de otras clases:
- Cuando se cruzan, todas las instancias de una clase compuesta también deben aplicarse a todas las clases fuente. Por ejemplo, "Marine Mammal" debe ser "Mammal" y "Sea Dweller" al mismo tiempo.
- . , , «» «», «» «». «».
- , . , «» «».
- . , .
- — , .
Las expresiones que le permiten vincular conceptos se denominan constructores.
OWL también le permite establecer muchas propiedades de relación importantes:
- Transitividad. Si se cumplen las relaciones P (x, y) y P (y, z), entonces también se satisface la relación P (x, z). Ejemplos de tales relaciones son "Más" - "Menos", "Padre" - "Hijo", etc.
- Simetría. Si se satisface la relación P (x, y), también se cumple la relación P (y, x). Por ejemplo, una relación relativa.
- Dependencia funcional. Si se cumplen las relaciones P (x, y) y P (x, z), entonces los valores de y y z deben ser idénticos. Un ejemplo es la relación con el padre: una persona no puede tener dos padres diferentes.
- Inversión de relaciones. Puede especificar que si se satisface la relación P1 (x, y), entonces se debe cumplir una relación P2 (y, x) más. Un ejemplo de tal relación es la relación padre-hijo.
- Cadenas de relaciones. Puede especificar que si A está asociado con alguna propiedad con B, y B - con C, entonces A (o C) pertenece a una clase determinada. Por ejemplo, si A tiene un padre para B y el padre B tiene su propio padre, C, entonces A es el nieto de C.
También puede establecer restricciones sobre los valores de los argumentos de las relaciones. Por ejemplo, especifique que los argumentos siempre deben pertenecer a una determinada clase, o que una clase debe tener al menos una relación de un tipo determinado, o limitar el número de relaciones de este tipo para ella. O puede especificar que todas las instancias que están relacionadas por una relación determinada con un valor dado pertenecen a una clase específica.
OWL es ahora la herramienta estándar de facto para construir ontologías. Este lenguaje es más adecuado para construir ontologías grandes y complejas que RDFS. La sintaxis de OWL le permite expresar más propiedades diferentes de conceptos y las relaciones entre ellos. Pero también introduce una serie de restricciones adicionales, por ejemplo, el mismo concepto no puede declararse simultáneamente como clase y como instancia de otra clase. Las ontologías OWL son más estrictas, más estandarizadas y, por lo tanto, más legibles. Si RDFS son solo unas pocas clases adicionales sobre un gráfico RDF, entonces OWL tiene una base matemática diferente: lógica de descripción. En consecuencia, se encuentran disponibles procedimientos formales de inferencia que le permiten extraer nueva información de ontologías OWL, verificar su consistencia y responder preguntas.
La lógica descriptiva es una pieza de lógica de primer orden. Solo se permiten predicados de un lugar (por ejemplo, un concepto pertenece a una clase), predicados de dos lugares (un concepto tiene una propiedad y su valor), así como los constructores de clase y las propiedades de relación, enumerados anteriormente. Todas las demás expresiones de lógica de primer orden en lógica descriptiva se han descartado. Por ejemplo, serán aceptables las declaraciones de que el concepto de "Factura impagada" pertenece a la clase "Factura", el concepto de "Factura" tiene las propiedades "Monto a pagar" y "Monto pagado". Pero hacer una declaración de que el concepto de propiedad "Factura impaga" "Cantidad a pagar" debe ser mayor que la propiedad "Cantidad pagada" no funcionará. Esto requiere una regla que incluya un predicado para comparar estas propiedades. Desafortunadamente,Los constructores de OWL no te permiten hacer esto.
Por tanto, la expresividad de la lógica descriptiva es menor que la de la lógica de primer orden. Pero, por otro lado, los algoritmos de inferencia en lógica descriptiva son mucho más rápidos. Además, posee la propiedad de decidibilidad: la solución se puede encontrar garantizada en un tiempo finito. Se cree que, en la práctica, dicho vocabulario es suficiente para construir ontologías complejas y voluminosas, y OWL es un buen compromiso entre expresividad y eficiencia de inferencia.
También vale la pena mencionar el SWRL (Semantic Web Rule Language), que combina la capacidad de crear clases y propiedades en OWL con la escritura de reglas en una versión limitada del lenguaje Datalog. El estilo de estas reglas es el mismo que en Prolog. SWRL admite predicados integrados para comparación, matemáticas, cadenas, fechas y manipulación de listas. Esto es exactamente lo que nos faltó para implementar el concepto de "factura impaga" con la ayuda de una simple expresión.
Flora-2
Como alternativa a las redes semánticas, considere una tecnología como los marcos. Un marco es una estructura que describe un objeto complejo, una imagen abstracta, un modelo de algo. Consta de un nombre, un conjunto de propiedades (características) y sus valores. El valor de la propiedad puede ser otro marco. Además, la propiedad puede tener un valor predeterminado. Se puede adjuntar a una propiedad una función para calcular su valor. Un marco también puede incluir procedimientos de servicio, incluidos controladores para dichos eventos, como crear, eliminar un marco, cambiar el valor de las propiedades, etc. Una propiedad importante de los marcos es la capacidad de heredar. El marco secundario incluye todas las propiedades de los marcos principales.
El sistema de marcos enlazados forma una red semántica muy similar a un gráfico RDF. Pero en las tareas de creación de ontologías, los marcos fueron reemplazados por OWL, que ahora es el estándar de facto. OWL es más expresivo, tiene una base teórica más avanzada: lógica descriptiva formal. A diferencia de RDF y OWL, en los que las propiedades de los conceptos se describen independientemente unas de otras, en el modelo de marco, el concepto y sus propiedades se consideran como un todo único: el marco. Mientras que en los modelos RDF y OWL, los vértices del gráfico contienen los nombres de los conceptos y los bordes contienen sus propiedades, en el modelo de marco, los vértices del gráfico contienen conceptos con todas sus propiedades y los bordes contienen vínculos entre sus propiedades o relaciones de herencia entre conceptos.
En esto, el modelo de marco está muy cerca del modelo de programación orientada a objetos. Son en gran parte iguales, pero tienen un alcance diferente (los marcos están destinados a modelar una red de conceptos y relaciones entre ellos, y OOP) a modelar el comportamiento de los objetos, su interacción entre sí. Por lo tanto, OOP proporciona mecanismos adicionales para ocultar los detalles de implementación de un componente a otros, restringiendo el acceso a métodos y campos de una clase.
Los lenguajes de encuadre modernos (como KL-ONE, PowerLoom, Flora-2) combinan los tipos de datos compuestos del modelo de objetos con lógica de primer orden. En estos lenguajes, no solo puede describir la estructura de los objetos, sino también operar con estos objetos en reglas, crear reglas que describen las condiciones para que un objeto pertenezca a una clase determinada, etc. Los mecanismos de herencia y composición de clases reciben una interpretación lógica, que queda disponible para su uso mediante procedimientos de inferencia. Estos lenguajes son más expresivos que OWL y no se limitan a predicados de dos lugares.
Como ejemplo, intentemos implementar nuestro ejemplo con deudores en el lenguaje Flora-2... Este lenguaje incluye 3 componentes: la lógica de marco F-lógica, que combina marcos y lógica de primer orden, la lógica de orden superior HiLog, que proporciona herramientas para formar declaraciones sobre la estructura de otras declaraciones y metaprogramación, y la lógica de cambio de lógica transaccional, que permite en forma lógica describir cambios en los datos y efectos secundarios de los cálculos. Ahora estamos interesados sólo en la F-lógica marco de la lógica . Para empezar, lo usaremos para declarar la estructura de marcos que describen los conceptos (clases) de clientes y deudores:
client[|name => \string,
email => \string
|].
bill[|client => client,
date => \string,
amountToPay => \number,
amountPaid => \number,
amountPaid -> 0
|].Ahora podemos declarar instancias (objetos) de estos conceptos:
client1 : client[name -> 'John', email -> 'john@somewhere.net'].
client2 : client[name -> 'Mary', email -> 'mary@somewhere.net'].
bill1 : bill[client -> client1,
date -> '2020-01',
amountToPay -> 100
].
bill2 : bill[client -> client2,
date -> '2020-01',
amountToPay -> 80,
amountPaid -> 80
].El símbolo '->' significa la asociación de un atributo con un valor específico en un objeto y un valor predeterminado en una declaración de clase. En nuestro ejemplo, el campo amountPaid de la clase de factura tiene un valor predeterminado de cero. El símbolo ':' significa crear una entidad de la clase: cliente1 y cliente2 son entidades de la clase cliente.
Ahora podemos declarar que los conceptos "Factura impagada" y "Deudor" son subclases de los conceptos "Cuenta" y "Cliente":
unpaidBill :: bill.
debtor :: client.El símbolo '::' declara una relación de herencia entre clases. Se hereda la estructura de la clase, métodos y valores predeterminados para todos sus campos. Queda por declarar las reglas que especifican la pertenencia a las clases impagoBill y deudor:
?x : unpaidBill :- ?x : bill[amountToPay -> ?a, amountPaid -> ?b], ?a > ?b.
?x : debtor :- ?x : client, ?_ : unpaidBill[client -> ?x]. La primera declaración establece que una variable
?es una entidad nopaidBill si es una entidad de factura y su campo amountToPay es mayor que amountPaid. En el segundo, lo que ?pertenece a la clase unpaidBill, si pertenece a la clase cliente y existe al menos una entidad de la clase unpaidBill en la que el valor del campo cliente es igual a una variable ?. Esta entidad de la clase unpaidBill se asociará con una variable anónima ?_, cuyo valor no se utilizará más.
Puede obtener una lista de deudores mediante la consulta:
?- ?x:debtor.Le pedimos que busque todos los valores relacionados con la clase deudora. El resultado será una lista de todos los valores posibles para la variable
?x:
?x = client1La lógica de tramas combina la visibilidad de un modelo orientado a objetos con el poder de la programación lógica. Será conveniente cuando trabaje con bases de datos, modele sistemas complejos, integre datos dispares, en aquellos casos en los que necesite enfocarse en la estructura de conceptos.
SQL
Finalmente, echemos un vistazo a las características principales de la sintaxis SQL. En la última publicación, dijimos que SQL tiene una base teórica lógica, el cálculo relacional, y consideramos la implementación de un ejemplo con deudores en LINQ. En términos de semántica, SQL está cerca de los lenguajes de encuadre y los modelos OOP: en un modelo de datos relacionales, el elemento principal es una tabla, que se percibe como un todo y no como un conjunto de propiedades separadas.
La sintaxis SQL encaja perfectamente con esta orientación de tabla. La solicitud se divide en secciones. Las entidades del modelo, que están representadas por tablas, vistas y consultas anidadas, se han movido a la sección FROM. Los enlaces entre ellos se especifican mediante operaciones JOIN. Las dependencias entre campos y otras condiciones se encuentran en las cláusulas WHERE y HAVING. En lugar de variables booleanas que unen argumentos de predicado, operamos en campos de tabla directamente en la consulta. Esta sintaxis describe la estructura del modelo de dominio más claramente que la sintaxis de Prolog "lineal".
Cómo veo el estilo de sintaxis del lenguaje de modelado
Usando el ejemplo de factura impaga, podemos comparar enfoques como la programación lógica (Prolog), la lógica de marco (Flora-2), las tecnologías web semánticas (RDFS, OWL y SWRL) y el cálculo relacional (SQL). Resumí sus principales características en una tabla:
| Idioma | Base matemática | Orientación de estilo | Ámbito de aplicación |
|---|---|---|---|
| Prólogo | Lógica de primer orden | En las reglas | Sistemas basados en reglas, coincidencia de patrones. |
| RDFS | Grafico | Sobre la conexión entre conceptos | Esquema de datos de recursos WEB |
| BÚHO | Lógica descriptiva | Sobre la conexión entre conceptos | Ontologías |
| SWRL | Una versión simplificada de la lógica de primer orden de Datalog | Sobre reglas además de vínculos entre conceptos | Ontologías |
| Flora-2 | Marcos + lógica de primer orden | Sobre las reglas sobre la estructura del objeto | Bases de datos, modelado de sistemas complejos, integración de datos dispares |
| SQL | Cálculo relacional | En estructuras de mesa | Base de datos |
Ahora necesitamos encontrar una base matemática y un estilo de sintaxis para un lenguaje de modelado diseñado para trabajar con datos semiestructurados e integración de datos de fuentes dispares, que se combinarían con lenguajes de programación orientados a objetos y funcionales de propósito general.
Los lenguajes más expresivos son Prolog y Flora-2: se basan en una lógica completa de primer orden con elementos de lógica de orden superior. El resto de los enfoques son subconjuntos. A excepción de RDFS, no tiene nada que ver con la lógica formal. En esta etapa, la lógica de primer orden en toda regla me parece la opción preferida. Para empezar, planeo detenerme en eso. Pero la opción limitada en forma de cálculo relacional o lógica de base de datos deductiva también tiene sus ventajas. Proporciona un gran rendimiento cuando se trabaja con grandes cantidades de datos. Debería considerarse por separado en el futuro. La lógica descriptiva parece demasiado limitada e incapaz de expresar relaciones dinámicas entre conceptos.
Desde mi punto de vista, para trabajar con datos semiestructurados e integrar fuentes de datos dispares, la lógica de tramas es más adecuada que Prolog orientado a reglas, o OWL, que se centra en relaciones y clases de conceptos. El modelo de marco describe explícitamente las estructuras de los objetos y centra la atención en ellos. En el caso de objetos con muchas propiedades, la forma del marco es mucho más legible que las reglas o los tripletes sujeto-propiedad-objeto. La herencia también es un mecanismo muy útil que puede reducir drásticamente la cantidad de código repetitivo. En comparación con el modelo relacional, la lógica de marcos le permite describir estructuras de datos complejas, como árboles y gráficos, de una manera más natural. Y lo mas importantela proximidad del modelo marco para describir el conocimiento al modelo POO permitirá integrarlos en un idioma de forma natural.
Quiero tomar prestada una estructura de consulta de SQL. La definición de un concepto puede tener una forma compleja y no está de más dividirlo en secciones para enfatizar sus partes constituyentes y facilitar la percepción. Además, para la mayoría de los desarrolladores, la sintaxis SQL es bastante familiar.
Entonces, quiero tomar la lógica de marcos como la base del lenguaje de modelado. Pero dado que el objetivo es describir estructuras de datos e integrar fuentes de datos dispares, intentaré abandonar la sintaxis orientada a reglas y reemplazarla con una versión estructurada tomada de SQL. El elemento principal del modelo de dominio será un "concepto" (concepto). En su definición, quiero incluir toda la información necesaria para extraer sus entidades de los datos de origen:
- el nombre del concepto;
- un conjunto de sus atributos;
- () , ;
- , ;
- , .
La definición del concepto se parecerá a una consulta SQL. Y todo el modelo de dominio estará en forma de conceptos interrelacionados.
Planeo mostrar la sintaxis resultante del lenguaje de modelado en la próxima publicación. Para aquellos que quieran familiarizarse con él ahora, hay un texto completo en estilo científico en inglés, disponible aquí:
Programación híbrida orientada a la ontología para el procesamiento de datos semiestructurados
Enlaces a publicaciones anteriores:
Diseño de un lenguaje de programación multiparadigma. Parte 1 - ¿Para qué sirve?
Diseñamos un lenguaje de programación multiparadigma. Parte 2 - Comparación de la construcción de modelos en PL / SQL, LINQ y GraphQL