Modelos basados en transformadores han logrado excelentes resultados en una amplia variedad de disciplinas, incluyendo conversacional AI , el lenguaje natural de procesamiento , imagen de proceso , e incluso la música . El componente principal de cualquier arquitectura es el módulo de atención de Transformers ( módulo de atención), que calcula la similitud para todos los pares en la secuencia de entrada. Sin embargo, no se escala bien con el aumento en la longitud de la secuencia de entrada, lo que requiere un aumento cuadrático en el tiempo de cálculo para obtener todas las estimaciones de similitud, así como un aumento cuadrático en la cantidad de memoria utilizada para construir una matriz para almacenar estas estimaciones.
Para las aplicaciones que requieren una mayor atención, se han propuesto varios proxies más rápidos y compactos, como técnicas de almacenamiento en caché de memoria , pero la solución más común es utilizar la atención escasa . La atención escasa reduce el tiempo computacional y los requisitos de memoria para el mecanismo de atención al calcular solo un número limitado de puntuaciones de similitud de una secuencia en lugar de todos los pares posibles, lo que da como resultado una matriz escasa en lugar de completa. Estas ocurrencias escasas se pueden sugerir manualmente, encontrar usando técnicas de optimización, aprender o incluso aleatorizar, como lo demuestran técnicas como Sparse Transformers , Longformers, Transformadores de enrutamiento , Reformers y Big Bird . Dado que las matrices dispersas también se pueden representar mediante gráficos y aristas , los métodos dispersos también están motivados por la literatura sobre redes neuronales gráficas , especialmente en lo que respecta al mecanismo de atención descrito en Redes de atención gráfica. Tales arquitecturas de escasez generalmente requieren capas adicionales para crear implícitamente un mecanismo de atención total.
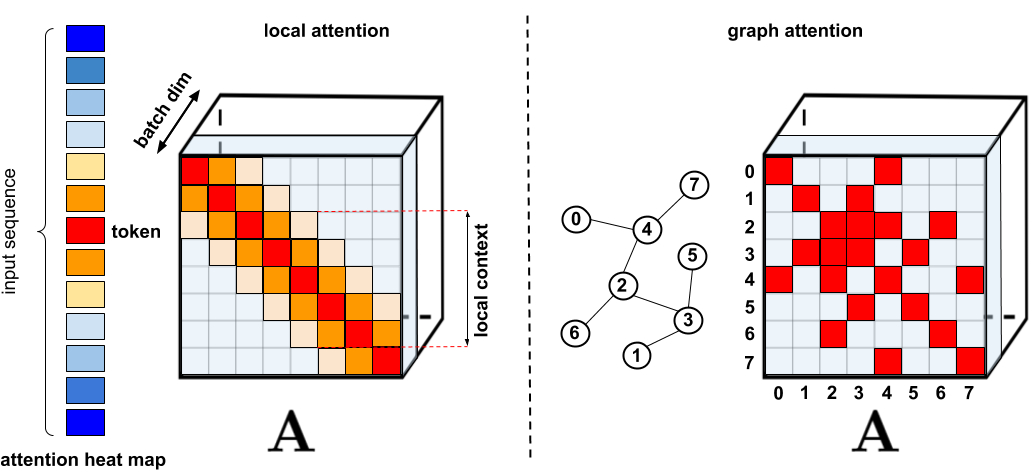
. : , . : Graph Attention Networks, , , . . « : » .
, . (1) , ; (2) ; (3) , , ; (4) , , . , , , Pointer Networks. , , , (softmax), .
, Performer, , . , , , ImageNet64, , PG-19. Performer () , , () . (Fast Attention Via Positive Orthogonal Random Features, FAVOR+), . ( , -). , .
, , , . , - . , , .
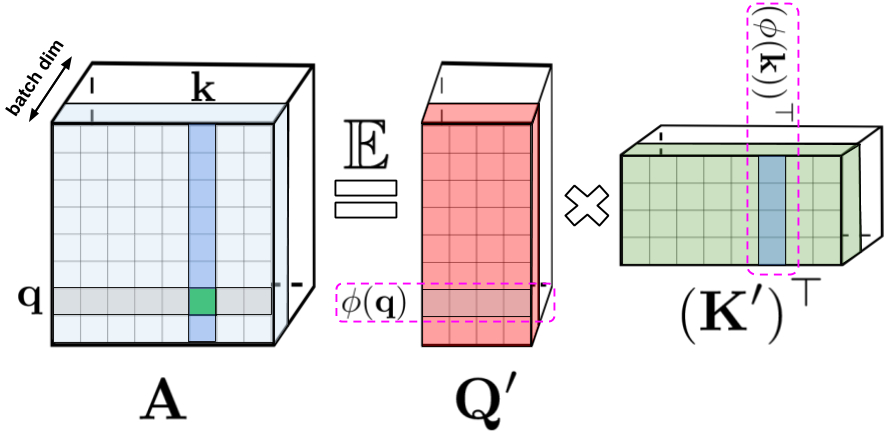
: , , , q k. : Q' K' , /. - , .
, , . , , , , -.
FAVOR+:
, . , . , , . , FAVOR+.
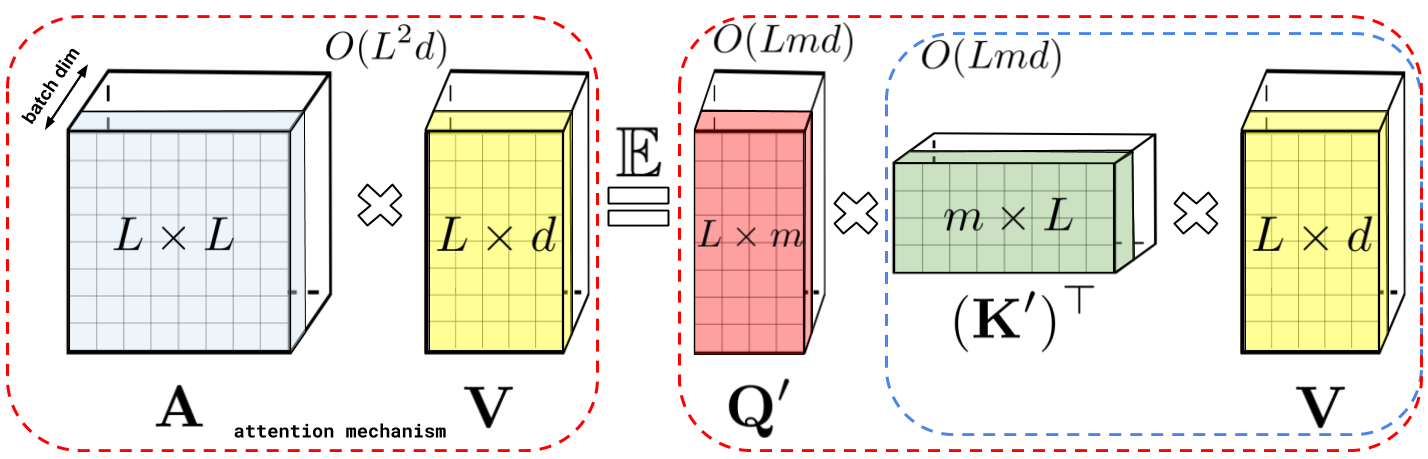
: , A V. : Q' K', A , , , , A .
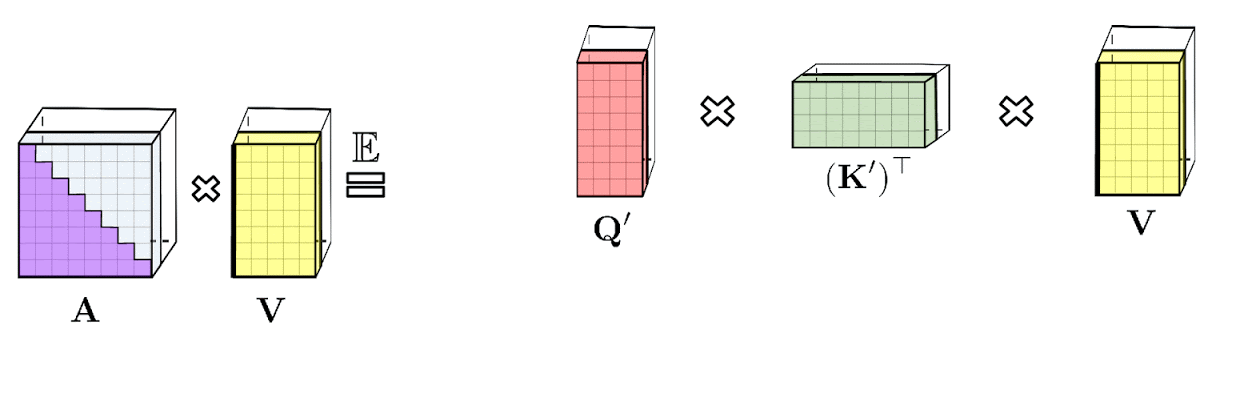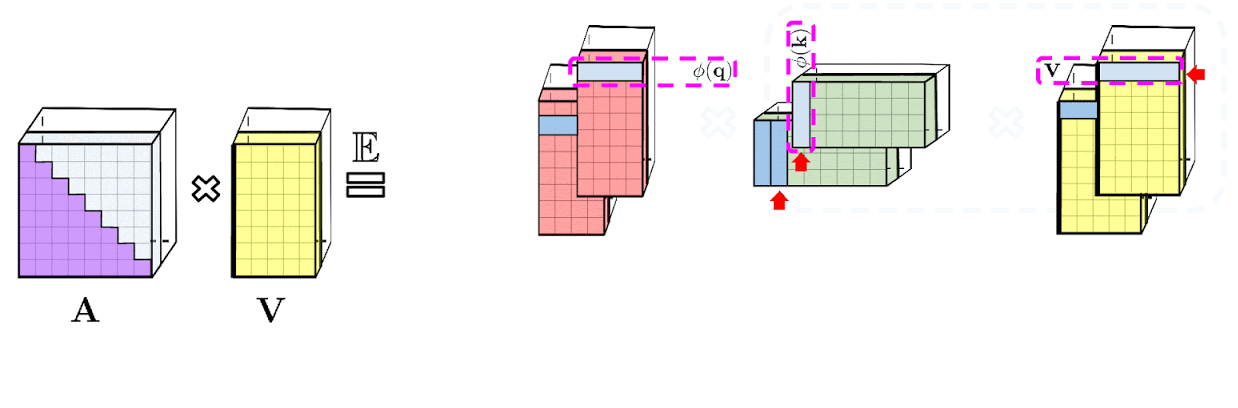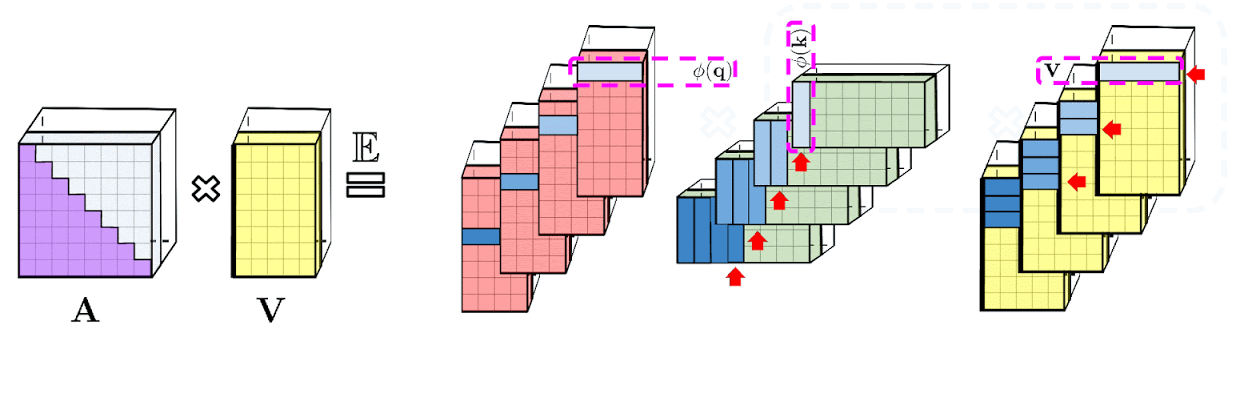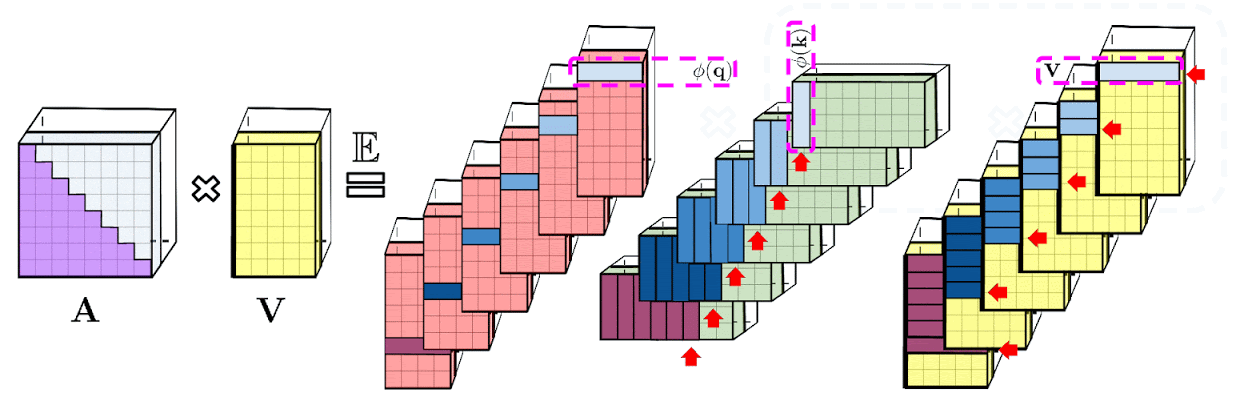
: , . : , .
Performer , , , .
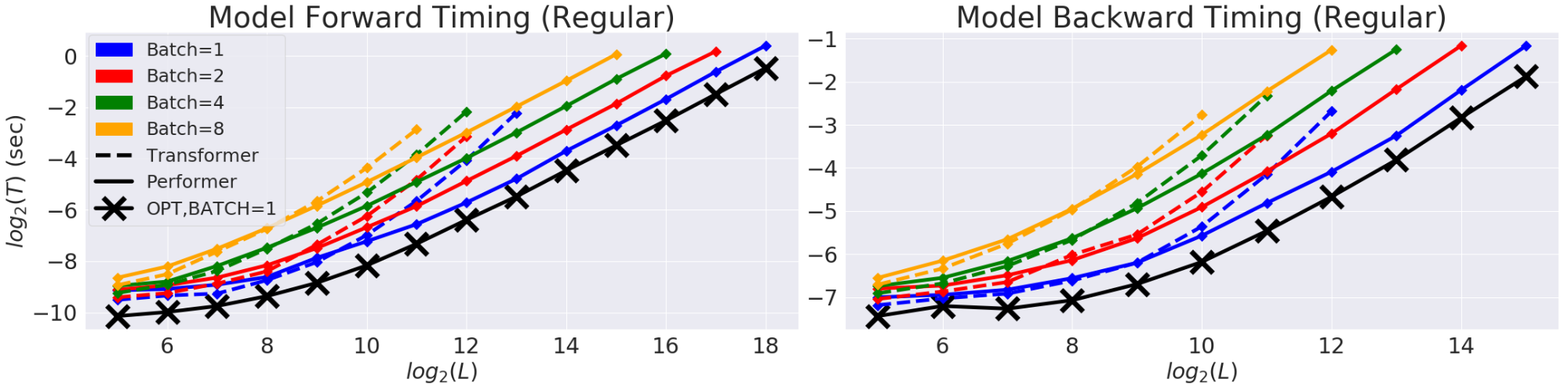
(T) (L). GPU. (X) «» , , , . Performer .
, Performer, -, , .
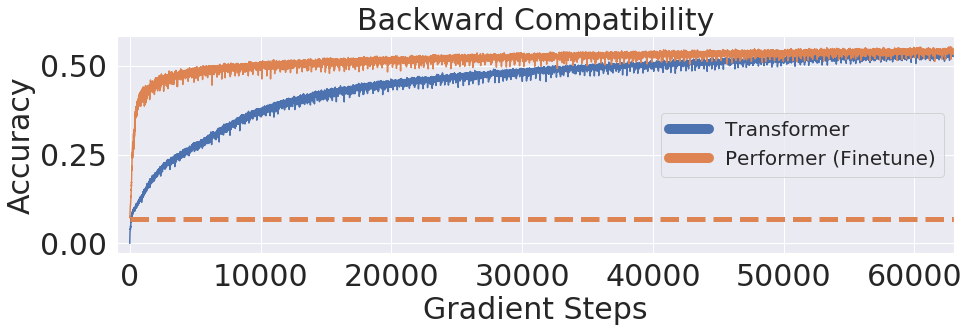
One Billion Word Benchmark (LM1B), Performer, 0.07 ( ). Performer .
:
— , . , , 20 . (, UniRef) , . Performer-ReLU ( ReLU, , ) , Performer-Softmax (accuracy) , .
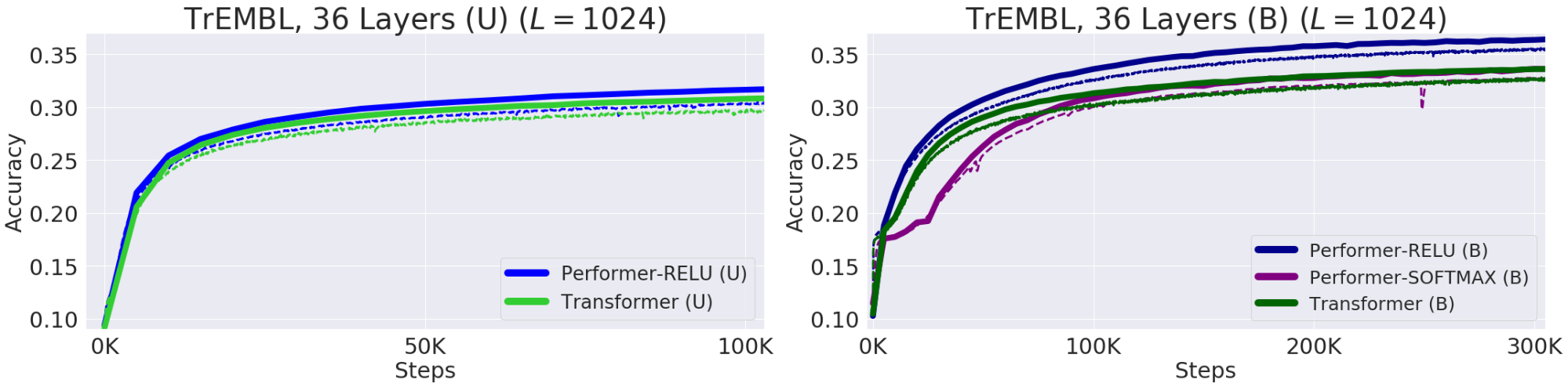
. (Train) — , (Validation) – , — (U), — (B). 36 ProGen (2019) , 16x16 TPU-v2. .
Protein Performer, ReLU. Performer , , . , , . Performer' . , , Performer - .
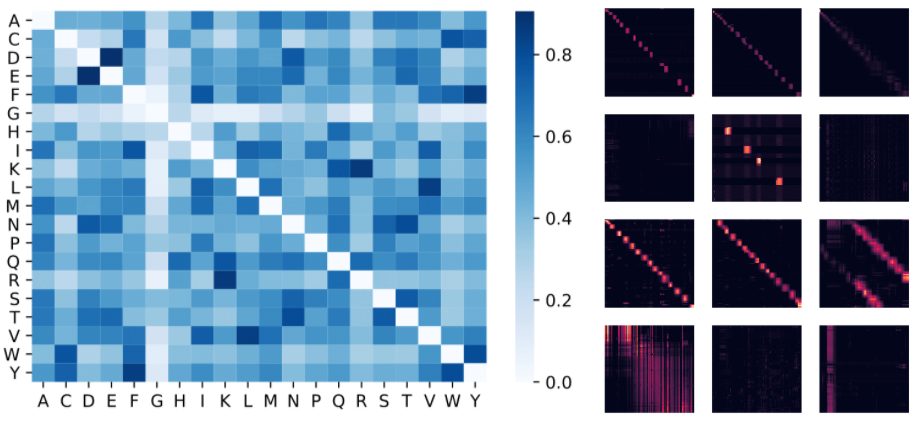
: , . , (D, E) (F, Y), . : 4 () 3 «» () BPT1_BOVIN, .
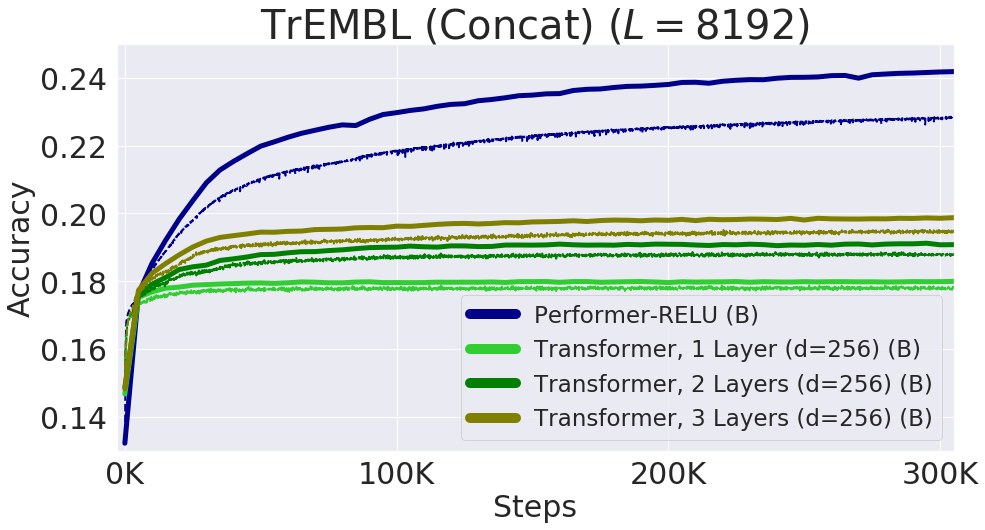
8192, . TPU, ( ) .
, . , , FAVOR Reformer. , Performer' . , , .
- — Krzysztof Choromanski, Lucy Colwell
- —
- Edición y maquetación - Sergey Shkarin