
En octubre, tradicionalmente, GPT-3 vuelve a ser el centro de atención. Hay varias noticias relacionadas con el modelo de OpenAI, buenas y no tan buenas.
Acuerdo de OpenAI y Microsoft
Tendremos que comenzar con uno menos agradable: Microsoft se hizo cargo de los derechos exclusivos de GPT-3. Como era de esperar, el acuerdo provocó indignación : Elon Musk, fundador de OpenAI y ahora ex miembro de la junta directiva de la compañía, dijo que Microsoft esencialmente se había hecho cargo de OpenAI.
El hecho es que OpenAI se creó originalmente como una organización sin fines de lucro con una alta misión: no permitir que la inteligencia artificial esté en manos de un estado o corporación separados. Los fundadores de la organización pidieron la apertura de la investigación en esta área, para que la tecnología funcione en beneficio de toda la humanidad.
Microsoft, en su defensa, dice que no van a restringir el acceso a la API del modelo. Por lo tanto, de hecho, nada ha cambiado; antes, OpenAI tampoco publicaba el código, pero si antes, incluso las empresas asociadas podían trabajar con GPT-3 solo a través de la API, ahora Microsoft tiene derechos exclusivos de uso.
ruGPT3 de Sberbank
Ahora, a noticias más agradables: los investigadores de Sberbank han publicado un modelo en acceso abierto que repite la arquitectura GPT-3 y se basa en el código GPT-2 y, lo más importante, está capacitado en el corpus en idioma ruso.
Se utilizó una colección de literatura rusa, datos de Wikipedia, instantáneas de sitios de noticias y preguntas y respuestas, materiales de los portales Pikabu, 22century.ru banki.ru, Omnia Russica como un conjunto de datos para la capacitación. Los desarrolladores también han incluido datos de GitHub y StackOverflow para enseñar cómo generar y programar código. La cantidad total de datos limpiados es más de 600 GB.
La noticia es definitivamente buena, pero hay un par de advertencias. Este modelo es similar al GPT-3, pero no. Los propios autores admitenque es 230 veces más pequeño que la versión más grande de GPT-3, que tiene 175 mil millones de pesos, lo que significa que no puede repetir exactamente los resultados de referencia. Es decir, no espere que este modelo escriba textos indistinguibles de los textos periodísticos.
También vale la pena considerar que la arquitectura GPT-3 descrita puede diferir de la implementación real. Puede decirlo con seguridad solo después de leer los parámetros de entrenamiento, y si antes de que los pesos se publicaran con un retraso, a la luz de los eventos recientes no se pueden esperar.
El hecho es que el presupuesto del proyecto depende de la cantidad de parámetros de capacitación y, según los expertos, la capacitación de GPT-3 cuesta al menos $ 10 millones. Por lo tanto, solo las grandes empresas con sólidos especialistas en ML y potentes recursos informáticos pueden reproducir el trabajo de OpenAI.
Informe sobre el estado de la IA 2020
Todo lo anterior confirma las conclusiones del tercer informe anual sobre la situación actual en el campo del aprendizaje automático. Nathan Benaich e Ian Hogarth, inversores que se especializan en startups de IA, han publicado una presentación detallada que cubre tecnología, recursos humanos, aplicaciones industriales y complejidades legales.
Curiosamente, hasta el 85% de la investigación se publica sin código fuente. Si las organizaciones comerciales pueden justificarse por el hecho de que el código a menudo se integra en la infraestructura de los proyectos, ¿qué pasa con las instituciones de investigación y las empresas sin fines de lucro como DeepMind y OpenAI?
También se dice que un aumento en los conjuntos de datos y modelos conduce a un aumento en los presupuestos, y dado que el campo del aprendizaje automático está estancado, cada nuevo avance requiere presupuestos desproporcionadamente grandes (compare el tamaño de GPT-2 y GPT-3), lo que significa que pueden pagarlo. solo grandes corporaciones.
Le recomendamos que se familiarice con este documento, ya que está escrito de forma concisa y clara, bien ilustrada. Además, ya se han cumplido cuatro predicciones para 2020 del último informe.
No exageraremos más, todavía hay buenas historias, de lo contrario esta colección no existiría.
Abra modelos multilingües de Google y Facebook
mT5
Google ha publicado el código fuente y el conjunto de datos de la familia T5 de modelos multilingües. Debido a la exageración asociada con OpenAI, esta noticia pasó casi desapercibida, a pesar de la impresionante escala: el modelo más grande tiene 13 mil millones de parámetros.
Para la formación se utilizó un conjunto de datos de 101 idiomas, entre los que el ruso ocupa el segundo lugar. Esto se puede explicar por el hecho de que nuestro grande y poderoso es el segundo lugar más popular en la web.
M2M-100
Facebook tampoco se queda atrás y ha presentado un modelo multilingüe , que, según sus declaraciones, permite traducir directamente 100x100 pares de idiomas sin un idioma intermedio.
En el campo de la traducción automática, es habitual crear y entrenar modelos para cada idioma y tarea individual. Pero en el caso de Facebook, este enfoque no puede escalar de manera efectiva, ya que los usuarios de la red social publican contenido en más de 160 idiomas.
Normalmente, los sistemas multilingües que manejan varios idiomas a la vez se basan en el inglés. La traducción es mediada e imprecisa. Cerrar la brecha entre los idiomas de origen y destino es difícil debido a la falta de datos, ya que puede ser muy difícil encontrar una traducción del chino al francés y viceversa. Para hacer esto, los creadores tuvieron que generar datos sintéticos mediante traducción inversa.
El artículo proporciona puntos de referencia, el modelo se adapta mejor a la traducción que los análogos que se basan en el inglés, así como un enlace al conjunto de datos .

Avances en videoconferencia
En octubre aparecieron de inmediato algunas noticias interesantes de Nvidia.
EstiloGAN2
Primero, publicamos actualizaciones para StyleGAN2 . La arquitectura de bajos recursos del modelo ahora proporciona un rendimiento mejorado en conjuntos de datos con menos de 30 mil imágenes. La nueva versión introduce soporte para precisión mixta: entrenamiento acelerado ~ 1.6x veces, inferencia ~ 1.3x veces, consumo de GPU disminuido ~ 1.5x veces. También agregamos una selección automática de hiperparámetros del modelo: soluciones listas para usar para conjuntos de datos de diferentes resoluciones y un número diferente de procesadores gráficos disponibles.
NeMo
Neural Modules es un conjunto de herramientas de código abierto que le ayuda a crear, entrenar y ajustar rápidamente modelos de conversación. NeMo consta de un núcleo que proporciona una apariencia única para todos los modelos y colecciones, que consta de módulos agrupados por alcance.
Maxine
Es probable que otro producto anunciado utilice las dos tecnologías anteriores internamente. La plataforma de videollamadas Maxine combina todo un zoológico de algoritmos ML. Esto incluye la mejora de resolución ya familiar, eliminación de ruido, eliminación de fondo, pero también corrección de mirada y sombras, restauración de imágenes basada en rasgos faciales clave (es decir, deepfakes), generación de subtítulos y traducción del habla a otros idiomas en tiempo real. Es decir, casi todo lo que anteriormente se reunía por separado, Nvidia se combinaba en un solo producto digital. Ahora puede solicitar el acceso anticipado.
Nuevos desarrollos de Google
Debido a la cuarentena, este año hay una verdadera carrera por el liderazgo en el campo de la videoconferencia. Google Meet compartió un caso de estudio sobre la creación de su algoritmo para la eliminación de fondo de alta calidad basado en el marco de Mediapipe (que puede rastrear el movimiento de los ojos, la cabeza y las manos).
Google también ha lanzado una nueva función para el servicio YouTube Stories en iOS que mejora la calidad del habla. Este es un caso interesante , porque hay muchos más potenciadores disponibles para video que para audio. Este algoritmo rastrea y registra las correlaciones entre el habla y los marcadores visuales, como las expresiones faciales, los movimientos de los labios, que luego utiliza para separar el habla de los sonidos de fondo, incluidas las voces de otros hablantes.
La empresa también presentó un nuevo intentoen el campo del reconocimiento de la lengua de signos.
Hablando de software de videoconferencia, también vale la pena mencionar los nuevos algoritmos deepfake.
MakeItTalk
Recientemente, se publicó en acceso abierto el código del algoritmo que anima la foto, basándose únicamente en el flujo de audio. Esto es digno de mención, ya que generalmente los algoritmos deepfake toman el video como entrada.

Increíble
La nueva generación de algoritmos deepfake se propone reemplazar no solo el rostro, sino todo el cuerpo, incluido el color del cabello, el tono de piel y la figura. Esta tecnología se va a aplicar fundamentalmente en el ámbito de la compra online, de forma que se puedan utilizar las fotos de producto facilitadas por la propia marca, sin tener que contratar modelos individuales. Se pueden ver más aplicaciones en la demostración en video . Hasta ahora, parece poco convincente, pero pronto todo puede cambiar.
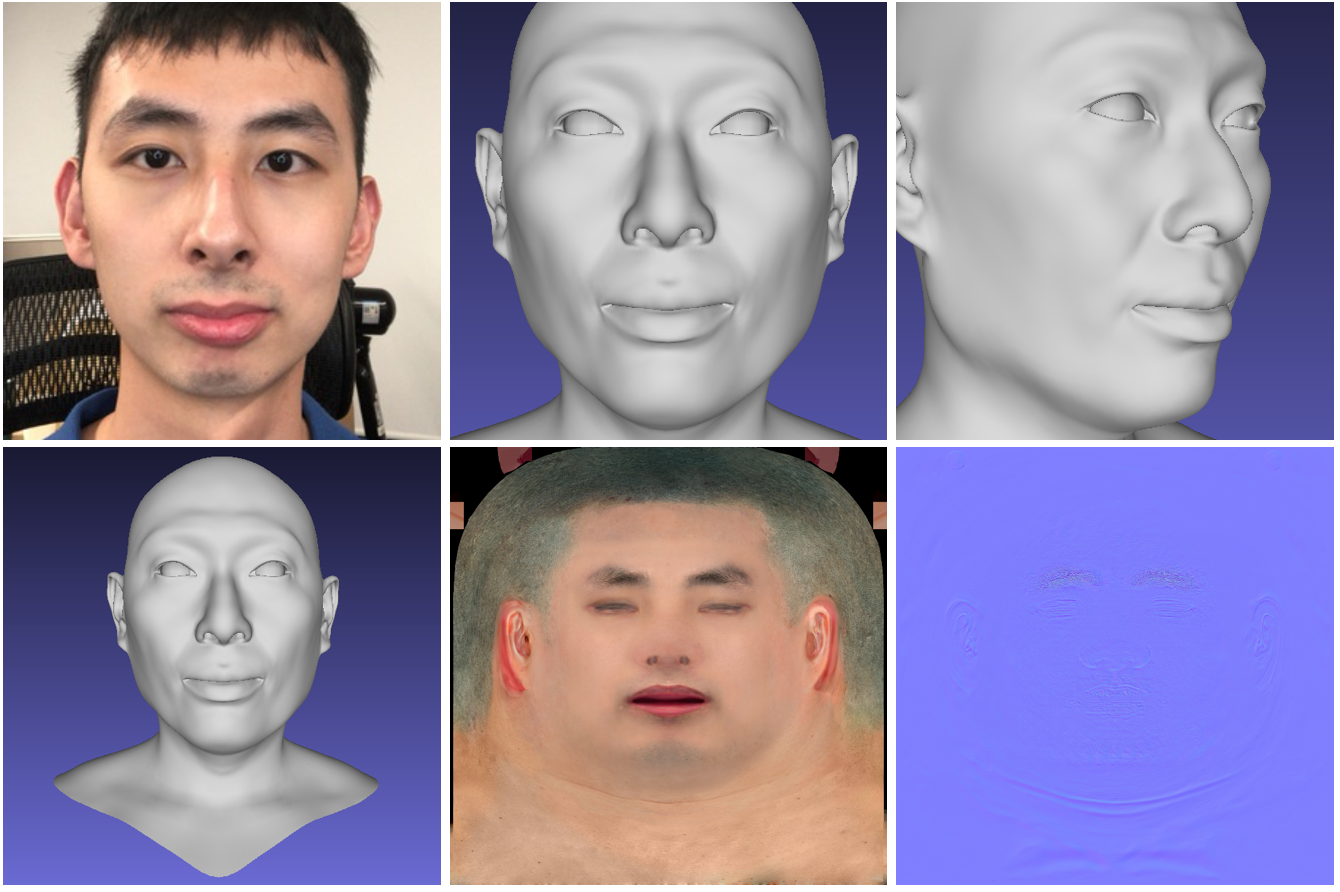
Cara 3D de alta fidelidad
La red neuronal genera un modelo 3D de alta calidad del rostro de una persona a partir de fotografías. El modelo recibe un video corto de una cámara RGB-D normal como entrada, y en la salida da un modelo 3D generado de la cara. El código del proyecto y el modelo 3DMM están disponibles públicamente .

SkyAR
Los autores presentaron una tecnología de código abierto para reemplazar el cielo con video en tiempo real, lo que también permite controlar los estilos. Se pueden generar efectos meteorológicos como rayos en el video de destino.
El modelo de tubería resuelve una serie de tareas en etapas: la cuadrícula mapea el cielo, rastrea los objetos en movimiento, envuelve y vuelve a colorear la imagen para que coincida con el esquema de color del palco.

Sea-thru
La herramienta resuelve la extraordinaria tarea de restaurar colores verdaderos en imágenes submarinas. Es decir, el algoritmo tiene en cuenta la profundidad y la distancia a los objetos para restaurar la iluminación y eliminar el agua de las imágenes. Hasta ahora, solo se encuentran disponibles conjuntos de datos.
Modelo MIT para diagnosticar Covid-19
En conclusión, compartiremos un caso interesante sobre un tema relevante: los investigadores del MIT han desarrollado un modelo que distingue a los pacientes asintomáticos con infección por coronavirus de las personas sanas que utilizan grabaciones de tos forzada.
El modelo ha sido entrenado en decenas de miles de cintas de audio de muestras de tos. Según el MIT , el algoritmo identifica a las personas que se ha confirmado que tienen Covid-19 con una precisión del 98,5%.
Las autoridades gubernamentales ya aprobaron la creación de la aplicación. El usuario podrá descargar una grabación de audio de su tos y, en función del resultado, determinar si es necesario realizar un análisis completo en el laboratorio.
Eso es todo, gracias por tu atención!