Bob Steagall dio recientemente una charla en la CppCon 2020 titulada " Aventuras en el pensamiento SIMD ", donde, entre otras cosas, habló sobre su experiencia al usar AVX512 para el filtrado medio con la ventana 7. Esta charla me causó dos sentimientos: por un lado, fue genial , y afirmó una aceleración de casi 20 veces en comparación con la implementación de STL "más tonta"; por otro lado, en una pasada del algoritmo de 16 muestras de entrada, resultó solo 2 salidas, aunque los datos de entrada eran suficientes para 10, y algunos detalles de implementación me hicieron querer intentar mejorarlos. Pensé, pensé y se me ocurrió una idea, luego otra, luego las probé "en software" y me di cuenta de que tenía algo que compartir :) Y así resultó este artículo.
Implementación básica
Describiré brevemente cómo lo hizo Bob (de hecho, un breve recuento de la parte correspondiente de su historia, junto con sus propias imágenes). Hizo las siguientes primitivas usando AVX512 (omitiré las de las primitivas descritas por él que corresponden directamente a la única operación de AVX512):
rotar: rotar los elementos en el registro AVX-512 en un círculo

shift with carry : cambia los artículos de un registro, reemplazando los artículos de un segundo registro
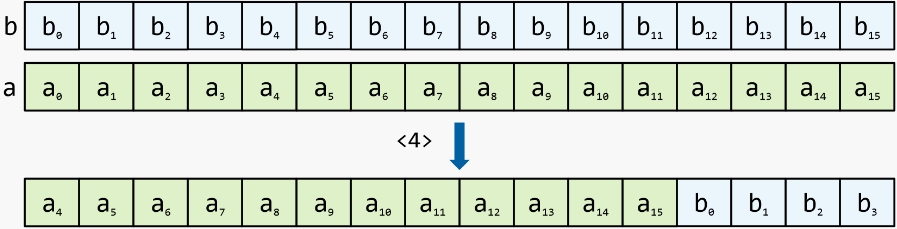
in place shift with carry : como shift con carry, pero los registros de entrada se pasan por referencia y el resultado del cambio permanece en ellos
comparar con intercambio : clasificación en paralelo de hasta 8 pares de elementos en un registro

, , : perm 0..15, ; mask 1 «» . : , perm. vmin , vmax ́ . , .
, , . :
1) shift with carry, «» , «» (.. 0 0..6, 1 — 1..7 . .)
2) , 0 , 1 —
3) 7 , — 6 compare and exchange, . — — .
0
- , . , , ( , L2). , . AVX-512…
1
, — . 7 ; 6 !

, 6 r1-r6 , r0 r7? S[0..5], X, , S[3] .
X >= S[3], S[3] ,X <= S[2], S[2] S[3], S[2]S[2] < X < S[3], X S[3], , X. ,clamp(X, S[2], S[3])=>min(max(X, S[2]), S[3])!
:
«» 4 7- ( 0, 7, 2, 9) – X 4
6- 1..6 3..8 ( 0..7 8..15, )
6-
clamp 2 3 X[0] X[1], 2 3 X[2] X[3]
2x — 2 ( 6 5 , 7 — 6), clamp . : 1,86x . . ?
2
«» X . 6- ; 5 , 2 ( 3 ). — : S[0] <=> S[1], S[2] <=> S[3], S[4] <=> S[5]
2, . . , , !

— 2 , 2 . , : 1.06x. , .
3
- , 1, 6- .

, 4 ( ), 6; , 4- ?
2 , 4- . 6- : 2- Y 4- S, 2 3 ( Z). , min(Y[0], S[0]) => Z[0], ; max(Y[0], S[0]) Z[1]..Z[5] – . max(Y[1], S[3]) , min(Y[1], S[3]).
4- S[1], S[2], min/max. , 4 , 1 2 — 2 3 6- . , «» 4- S[1] S[2], — . , 2 , Y.
:
r1-r2 . .
— Y, r1-2, r5-6, r7-8, r11-12; permute 4 , Y r0-1, r4-5 . .
( ) «» ; r3-r6 r7-r10
max min Y[0]/S[0], Y[1]/S[3]
mask_permute Y S, S[1] S[2] ,
4
1 2, min/max X 8
, , , 2. — 1.64x , 2, 3 , .
; ( - permute; , - ), .
, :)
benchmark:
512 : 3.1-3.2 ; 7.3 , memcpy avx-512
50 : 2.8-2.9 ; 1.8 , memcpy (!)
.
5? , (disclaimer: — ).
16- 12 .
- 3 ( …)
1 , 4 ( 6 ) 4- — , . . 4 , 5 ; 8 .
2 , — 2 ; , .
3 , . , — , 12 . , «» — 24 , 12 .
9? 8 .
—
1 — 2 8- 4 , 4 ( 7 6 )
2 — , -
3 — , — 6- 2, 6- ( , ) , 8-.
, - . , https://github.com/tea/avx-median/. « », , -. , .
- , — . .
UPDATE
AVX2 . , , , , ( , 16 , ). , : 1.64x , .
Resultó que no todo está perdido: ¡el primer paso de optimización también se puede aplicar a esta variante! Es necesario recopilar 32 bordes de X, es necesario confundir los datos para ordenarlos, los datos ordenados también deben permutarse, etc., pero a pesar de todos estos gestos, la aceleración es 1.27 veces.
No intenté hacer los pasos 2 y 3, porque obviamente será más lento. Es muy posible que para el caso de, digamos, la ventana 11, funcionen en un plus (pero no sé si alguien necesita un filtro 1D-mediano rápido con ventanas grandes).