EXPLAIN (ANALYZE, BUFFERS) ...es su herramienta favorita para conocer las peculiaridades de este DBMS, entonces los nuevos "chips" útiles de nuestro servicio para la visualización y análisis de planes explica.tensor.ru sin duda le serán útiles en esta difícil tarea.
Pero permítame recordarle de inmediato que sin un monitoreo completo y completo de la base de datos PostgreSQL, ¡usar solo el análisis del plan es actuar desde la posición del sabio # 5!

[ fuente KDPV , "The Blind Men and the Elephant" ]
, 1940
, ,
.
,
,
, .
, —
.
,
:
—
!
,
,
, ,
.
,
,
,
.
La contienda surgió entre los ciegos
y duró todo un año.
Entonces los ciegos finalmente
pusieron sus manos en movimiento.
Y como el quinto era fuerte,
cerró la boca a todos.
¡Y de ahora en adelante el elefante consta de
una cola!
Entonces, hoy en el programa:
- cambiar "galones" por "correas de hombro"
- reunimos planes "mega"
- mantenemos un archivo personal
- estudiando la genealogía de los planes
- mirando por las "ventanas"
¡Ni un solo color!
Históricamente, al ver el plan, marcamos los nodos "más calientes" con un "cheurón" vertical a la izquierda del valor; cuanto mayor es el valor, más rico es el color.

Pero en un modelo de este tipo, la proporción de valores se percibe mal; por ejemplo, una desviación del 30% en la diferencia de tonos solo puede ser notada por un ojo entrenado. Por lo tanto, hicimos un histograma a partir de "correas de hombro" horizontales.

Estadísticas útiles para planes "mega"
Muchas personas no notan la pestaña "Estadísticas" del plan, aquí está a la derecha:

Y quienquiera que lo notó, casi no lo usó activamente. Decidimos corregir esta omisión y hacerla realmente útil para analizar planes "grandes" (más de 100 nodos).
Agrupar nodos
Todos los nodos del plan "idénticos" (es decir, aquellos con el mismo tipo de nodo, tabla utilizada e índice) se agrupan en una fila de tabla. En este caso, se suman todos sus indicadores (tiempo de ejecución, número de registros leídos y descartados, número total de pasadas y cantidad de datos leídos).
Y para mayor claridad, cada tipo de nodo lleva una etiqueta de color:
- rojo - la lectura de datos de
nodosSeq Scan,Index Scan,CTE Scany varios otros... Scan - amarillo - Procesamiento de Datos
nodosSort,Unique,Aggregate,Group,Materialize, ... - verde - conexión de
nodosNested Loop,Merge Join,Hash Join, ...

Ordenar por cualquier indicador
Si de repente necesita un análisis no por el tiempo total, sino por el tipo de nodo, por ejemplo, simplemente haga clic en el encabezado de la columna, y todo será:

Sugerencia de nodo contextual
Para comprender en detalle la contribución de un nodo específico en el grupo, coloque el cursor sobre el número de cualquiera de ellos y verá la pista tradicional de lo que sucedió exactamente allí:
Archivo personal de planes
"¡Sin registro y sin SMS!"Si utiliza activamente nuestro servicio, ahora será mucho más fácil encontrar sus planos previamente analizados, simplemente cambie a la pestaña "mío" en el archivo . Los planes caen aquí independientemente de la publicación en el archivo general y solo son visibles para usted.

Genealogía de planes
Solía ser bastante difícil encontrar algún plan específico en el archivo, ahora es simple. Se pueden nombrar y agrupar en un "árbol genealógico" de optimización.
Simplemente especifique un nombre cuando agregue un plan:

... o en un plan existente, puede configurarlo, editar o agregar un plan vinculado:

luego puede cambiar rápidamente a través del árbol de opciones para evaluar el efecto de ciertas optimizaciones:

Y si un enlace a un plan específico de repente perdido, puede ser fácilmente identificado por su nombre en su archivo personal:

Miramos por las "ventanas"
Una pequeña pero útil mejora de Query Profiler , sobre la que escribí anteriormente : le enseñamos a "mirar en ventanas" y mapear correctamente para planificar nodos:
-> WindowAgg ==> WINDOW / OVER
-> Sort ==> PARTITION BY / ORDER BY... como varias definiciones independientes de "ventana" (
WINDOW) dentro de una sola consulta:
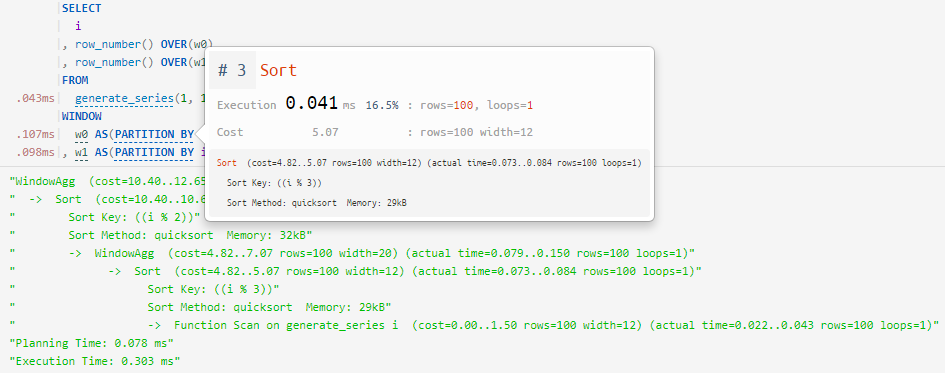
... y ordenando las funciones de ventana sin una definición explícita: ¡

Feliz caza de diversas ineficiencias!