Para generar el informe requerido con una frecuencia especificada, es suficiente escribir un recurso de informe personalizado correspondiente.
Escenarios de uso
Se necesitan informes de medición personalizados, por ejemplo, en los siguientes casos:
- OpenShift, , (worker nodes) . . CPU , , -, , .
- OpenShift. Metering, , , , . , , , .
- Además, en una situación con clústeres compartidos, el departamento de operaciones sería útil para poder mantener registros en el contexto de equipos y departamentos por el tiempo operativo total de sus pods (o por la cantidad de recursos de CPU o memoria que se gastaron en él). En otras palabras, estamos nuevamente interesados en información sobre quién es el propietario de este o aquel sub.
Para solucionar estos problemas en el clúster, basta con crear determinados recursos personalizados, que haremos a continuación. La instalación del operador de medición está fuera del alcance de este artículo, por lo que debe consultar la documentación de instalación si es necesario . Puede obtener más información sobre cómo utilizar los informes de medición estándar en la documentación relacionada .
Cómo funciona la medición
Antes de crear activos personalizados, echemos un vistazo a Medición. Una vez instalado, crea seis tipos de recursos personalizados, de los cuales nos centraremos en los siguientes:
- ReportDataSources (RDS) : este mecanismo le permite especificar qué datos estarán disponibles y se pueden usar en ReportQuery o en recursos de informes personalizados. RDS también le permite extraer datos de múltiples fuentes. En OpenShift, los datos se extraen de Prometheus, así como de los recursos personalizados de ReportQuery (RQ).
- ReportQuery (rq) – SQL- , RDS. RQ- Report, RQ- , . RQ- RDS-, RQ- Metering view Presto ( Metering) .
- Report – , , ReportQuery. , , , Metering. Report .
Hay muchos RDS y RQ disponibles listos para usar. Dado que nos interesan principalmente los informes a nivel de nodo, veamos aquellos que le ayudarán a escribir sus consultas personalizadas. Ejecute el siguiente comando mientras está en el proyecto "openshift-metering":
$ oc project openshift-metering
$ oc get reportdatasources | grep node
node-allocatable-cpu-cores
node-allocatable-memory-bytes
node-capacity-cpu-cores
node-capacity-memory-bytes
node-cpu-allocatable-raw
node-cpu-capacity-raw
node-memory-allocatable-raw
node-memory-capacity-raw
Aquí estamos interesados en dos RDS: node-capacity-cpu-core y node-capput-capacity - capacity-raw, ya que queremos obtener un informe sobre el consumo de CPU. Comencemos con node-capacity-cpu-core y ejecutemos el siguiente comando para ver cómo recopila datos de Prometheus:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml
<showing only relevant snippet below>
spec:
prometheusMetricsImporter:
query: |
kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)
Aquí vemos una solicitud de Prometheus que obtiene datos de Prometheus y los almacena en Presto. Ejecutemos la misma solicitud en la consola de métricas de OpenShift y veamos el resultado. Tenemos un clúster de OpenShift con dos nodos trabajadores (cada uno con 16 núcleos) y tres nodos maestros (cada uno con 8 núcleos). La última columna, Valor, contiene el número de núcleos asignados al nodo.

Entonces, los datos se reciben y almacenan en tablas de Presto. Ahora veamos los recursos personalizados de reportquery (RQ):
$ oc project openshift-metering
$ oc get reportqueries | grep node-cpu
node-cpu-allocatable
node-cpu-allocatable-raw
node-cpu-capacity
node-cpu-capacity-raw
node-cpu-utilization
Aquí estamos interesados en los siguientes RQS: node-cpu-capacity y node-cpu-capacity-raw. Como sugiere el nombre, estas métricas contienen tanto datos descriptivos (cuánto tiempo está funcionando un nodo, cuántos procesadores ha asignado, etc.) como datos agregados.
Los dos RDS y los dos RQS que nos interesan están interconectados por la siguiente cadena:
node-cpu-capacity (rq) <b>uses</b> node-cpu-capacity-raw (rds) <b>uses</b> node-cpu-capacity-raw (rq) <b>uses</b> node-capacity-cpu-cores (rds)
Informes personalizables
Ahora escribamos nuestras propias versiones personalizadas de RDS y RQ. Necesitamos cambiar la solicitud de Prometheus para que muestre el modo del nodo (maestro / trabajador) y la etiqueta de nodo correspondiente, que indica a qué equipo pertenece este nodo. El modo de operación del nodo está contenido en la métrica kube_node_role Prometheus, consulte la columna de rol:
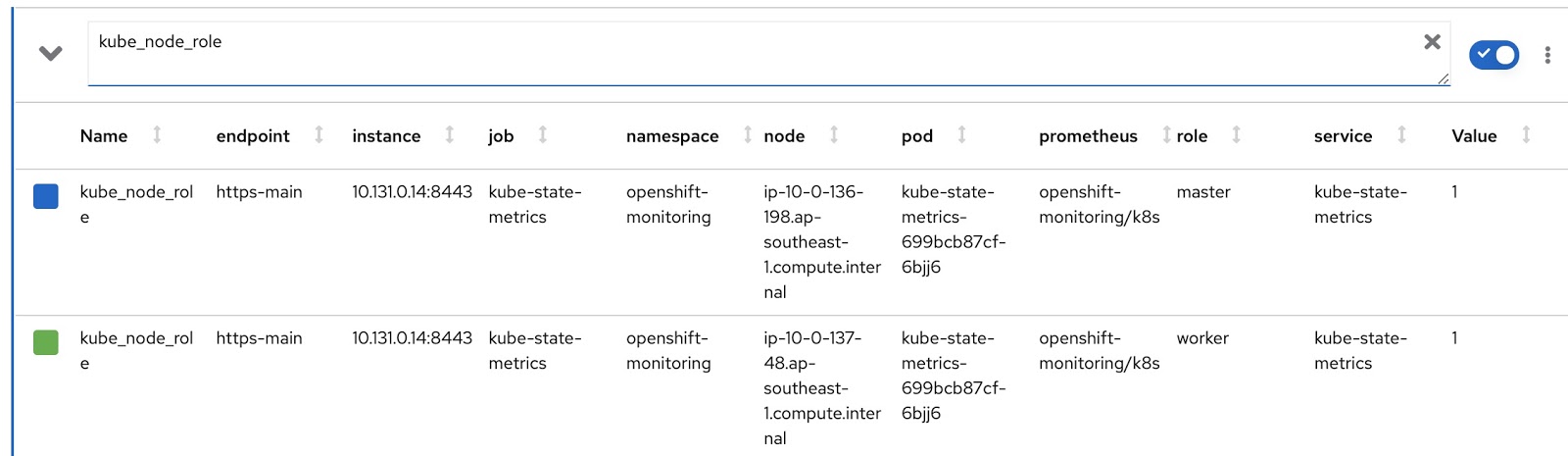
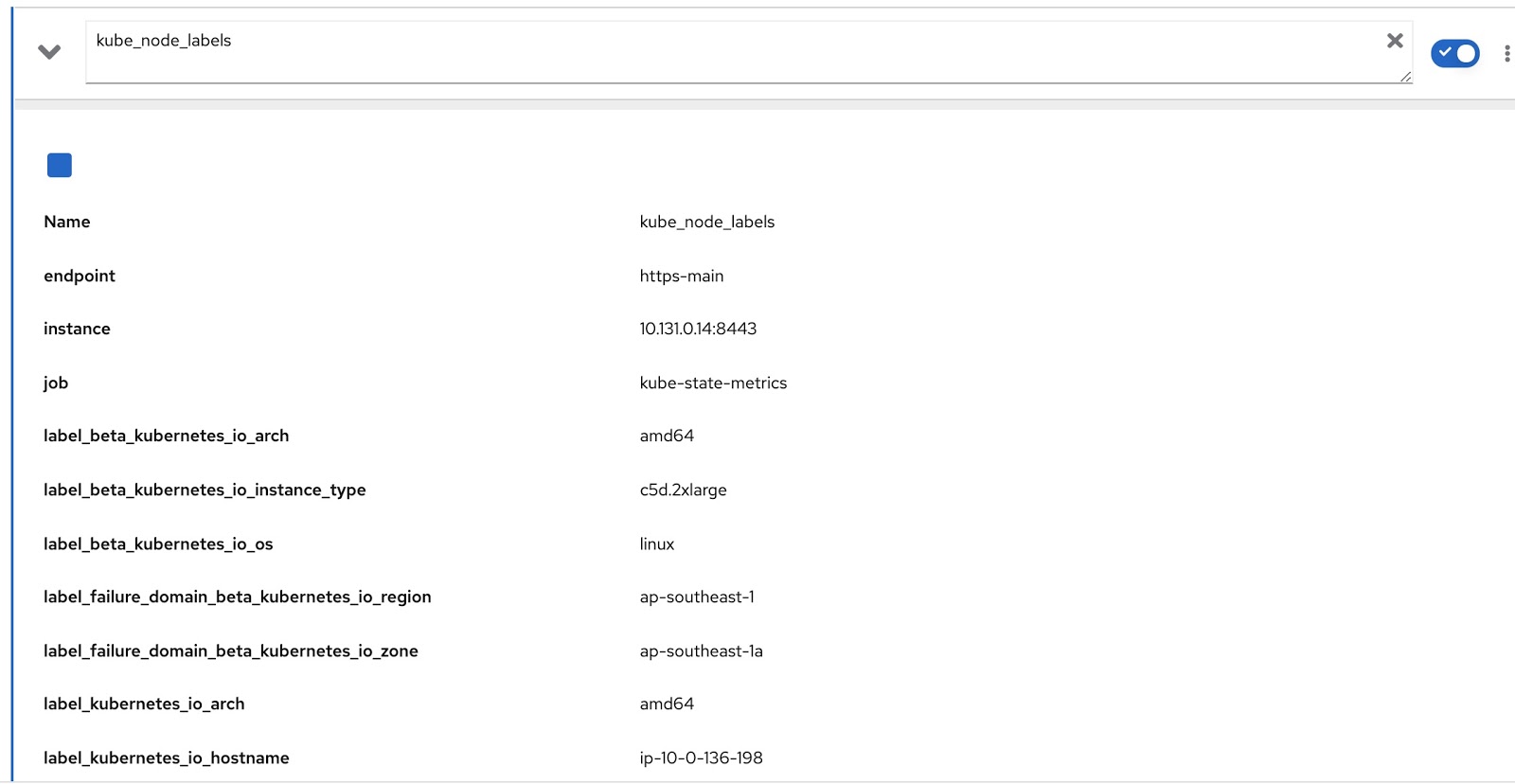
Y todas las etiquetas asignadas al nodo están contenidas en la métrica de Prometheus kube_node_labels, donde se forman utilizando la plantilla label_. por ejemplo, si un nodo tiene una etiqueta node_lob, aparecerá en la métrica de Prometheus como label_node_lob.
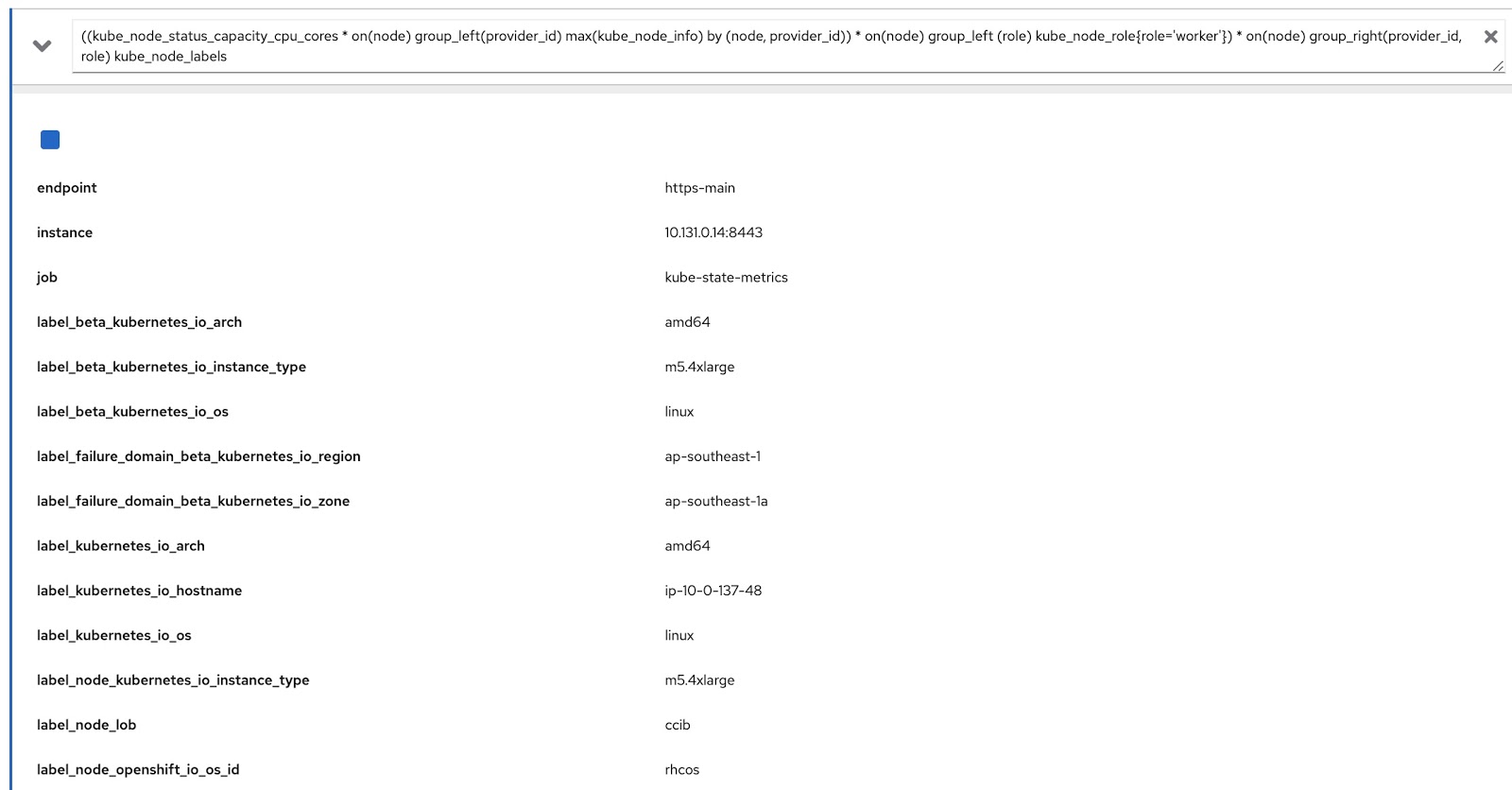
Ahora solo tenemos que modificar la consulta original usando estas dos consultas de Prometheus para obtener los datos que necesitamos, así:
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
Ahora ejecutemos esta consulta en la consola de métricas de OpenShift y asegurémonos de que devuelve datos tanto por etiquetas (node_lob) como por roles. En la siguiente imagen, esto es, en primer lugar, label_node_lob, así como el rol (está ahí, simplemente no apareció en la captura de pantalla):
Entonces, necesitamos escribir cuatro recursos personalizados (puede descargarlos de la lista a continuación):
- rds-custom-node-capacity-cpu-cores.yaml : especifica una solicitud de Prometheus.
- rq-custom-node-cpu-capacity-raw.yaml : hace referencia a la solicitud del paso 1 y genera datos sin procesar.
- rds-custom-node-cpu-capacity-raw.yaml : hace referencia a RQ del paso 2 y crea un objeto de vista en Presto.
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml : se refiere al RDS de la cláusula 3 y genera datos teniendo en cuenta las fechas de inicio y finalización ingresadas del informe. Además, las columnas de función y etiqueta se extraen en el mismo archivo.
Después de haber creado estos cuatro archivos yaml, vaya al proyecto de medición de openshift y ejecute los siguientes comandos:
$ oc project openshift-metering
$ oc create -f rds-custom-node-capacity-cpu-cores.yaml
$ oc create -f rq-custom-node-cpu-capacity-raw.yaml
$ oc create -f rds-custom-node-cpu-capacity-raw.yaml
$ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml
Ahora solo queda escribir un objeto de Informe personalizado que se referirá al objeto RQ del paso 4. Por ejemplo, puede hacer esto como se muestra a continuación para que el informe se ejecute inmediatamente y devuelva datos del 15 al 30 de septiembre.
$ cat report_immediate.yaml
apiVersion: metering.openshift.io/v1
kind: Report
metadata:
name: custom-role-node-cpu-capacity-lables-immediate
namespace: openshift-metering
spec:
query: custom-role-node-cpu-capacity-labels
reportingStart: "2020-09-15T00:00:00Z"
reportingEnd: "2020-09-30T00:00:00Z"
runImmediately: true
$ oc create -f report-immediate.yaml
Después de ejecutar este informe, el archivo de resultados (csv o json) se puede descargar desde la siguiente URL (simplemente reemplace DOMAIN_NAME con la suya propia):
metering-openshift-metering.DOMAIN_NAME / api / v1 / reports / get? Name = custom-role-node-cpu- capacity-hourly & namespace = openshift-metering & format = csv
Como puede ver en la captura de pantalla del archivo CSV, contiene tanto role como node_lob. Para obtener el tiempo de actividad del nodo en segundos, divida node_capacity_cpu_core_seconds por node_capacity_cpu_cores:

Conclusión
El operador de medición es algo interesante para los clústeres de OpenShift implementados en cualquier lugar. Al proporcionar un marco extensible, le permite crear recursos personalizados para generar los informes que desee. Todos los códigos fuente utilizados en este artículo se pueden descargar aquí .