Las necesidades del cliente se pueden expresar mediante las siguientes características del perfilador deseado:
- tener una herramienta de análisis de rendimiento para un conjunto específico de arquitecturas;
- ser capaz de hacer un análisis en profundidad del rendimiento hasta las instrucciones en código desensamblado;
- tenga un medio para ver y trabajar con la salida del código desensamblado en una GUI conveniente para tal conjunto de arquitecturas: x86_64, ARMv7, ARMv8.
Es decir, se requería un generador de perfiles, que debería:
- ser multiplataforma;
- poder generar un desensamblador de funciones para arquitecturas de este conjunto - x86_64, ARMv7, ARMv8;
- mostrar resultados e interactuar con el usuario a través de la GUI y mantener la usabilidad.
Para satisfacer las necesidades del cliente, hemos desarrollado un nuevo componente del sistema: un desensamblador multiplataforma con generación de código para x86_64, ARMv7, ARMv8 (funcionalidad y GUI para trabajar con su salida).
Veamos un ejemplo de una demostración simple de código C ++ en Hotspot en acción y las capacidades de análisis de rendimiento que proporciona. Ejemplo:
cat demo.cpp:
#include <iostream>
int g (int arg) {
return abs(rand()) * arg;
}
int f() {
int i = 1;
int res = 1 ;
std::cout << abs(rand()) << std::endl;
while (i < 1000000) {
res += i * g(res);
i++;
}
std::cout << res << std::endl;
return res;
}
int main() {
std::cout << f() << std::endl;
return 0;
}Compilamos, construimos nuestra aplicación de demostración:
g++ demo.cpp -o demoInicie nuestro perfilador:
./hotspotPaso 1: recopile y escriba datos en el archivo perf.data.
Esto se puede hacer de dos maneras: desde la línea de comando usando una llamada explícita a perf
record -o /home/demo/perf.data --call-graph dwarf ./demoO usando el menú de Hotspot Archivo-> Registrar datos.
Para nuestra demostración, recopilamos eventos del tipo de ciclos, pero puede configurar cualquier otro o un conjunto de tipos de eventos (fallas de caché, instrucciones, fallas de rama, etc.)

Haga clic en Iniciar grabación, espere a que se iluminen Ver resultados:

Sumérjase en el mundo del análisis de rendimiento.
Aquí encontraremos información resumida y campeones entre los consumidores del tiempo de ejecución de nuestra demostración.

Cadenas de llamadas en ambas direcciones: desde el llamado al método de llamada (Bottom Up) y viceversa (Bottom Down) con tiempos (pesos).


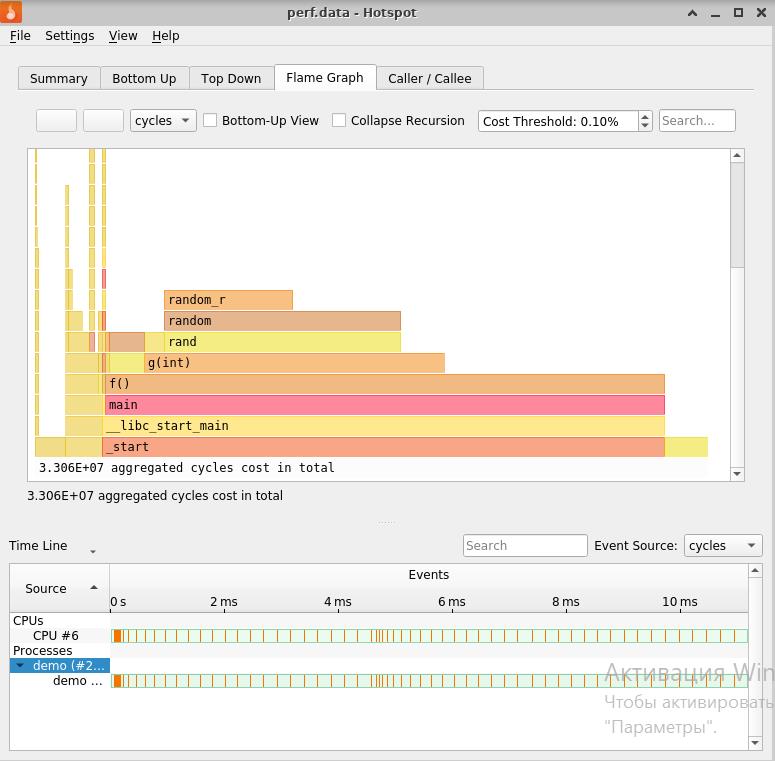
Flame Graph y datos sobre rendimiento, tiempo de ejecución para cada
función / método que sea significativo para él.
Para obtener información más detallada sobre la función que nos interesa, con la distribución de eventos dentro de ella (hasta las instrucciones para el código desensamblado), haga clic en Desmontaje, el elemento del menú contextual. Se abre haciendo clic derecho en la función que te gusta: ¡

Ahora sabemos todo sobre esta función!

Puede navegar por la pila de llamadas. Haga doble clic en una instrucción de llamada resaltada en azul. Y ante nosotros hay un desensamblador para la función llamada g (int). La instrucción que consume CPU no tiene competidores aquí.

Ctrl + B, Ctrl + D - y también tenemos códigos de máquina de comandos, y el desensamblador se generó usando objdump. En los casos anteriores, mostré el código producido al llamar a perf annotate.

El botón Atrás está iluminado, ¡puede moverse a lo largo de la pila de llamadas en ambas direcciones!
Vaya a la instrucción con la dirección 1236 y haga doble clic en la instrucción con la dirección 124f. Y nuevamente, está disponible la transición de regreso a la instrucción con la dirección 1236.

Ctrl + B, Ctrl + I nos cambia a la sintaxis Intel Assembler: Estaremos

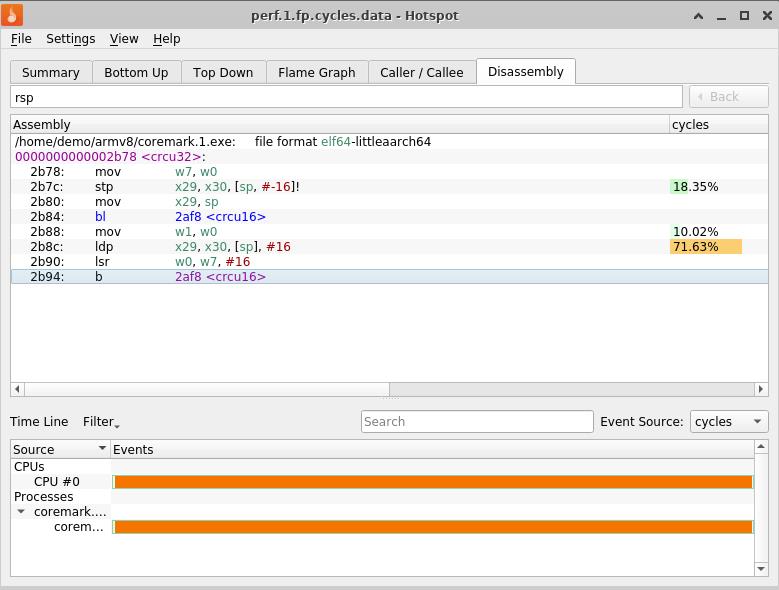
encantados de tener la oportunidad de buscar texto por el patrón ingresado, por ejemplo, usando el registro% rsp:

Y ... sin salir del lugar, pasamos a ARM ... Para hacer esto, necesitaremos, básicamente, dos entidades: el archivo ejecutable de la aplicación de usuario, compilado en ARM, y el archivo perf.data para él, registrado allí. En nuestra demostración, estos son coremark.1.exe y perf.1.fp.cycles.data, basados en ARMv8. Los ponemos en / home / demo / armv8 / y cargamos perf.data -

Por lo tanto, no solo completamos las tareas establecidas por el cliente, sino que también las cumplimos en exceso; en particular, el cálculo y la visualización de la distribución de eventos de acuerdo con las instrucciones del desensamblador nos permite hacer un análisis en profundidad hasta una instrucción que se puede vincular a una cadena en el código, el programa tiene una GUI, una interfaz fácil de usar. con configuraciones de perfiles cruzados.
Linux perf gui Hotspot se distribuye bajo los términos de la Licencia Pública General GNU por acuerdo con nuestros socios. En otras palabras, otorgamos a todos los usuarios interesados el derecho de copiar, modificar y distribuir este programa de perfilado de forma gratuita.
Está alojado en GitHub junto con instrucciones para descargar e instalar . Todo el mundo puede conocerlo y apreciarlo.
Lo invitamos, llevando Linux Perf GUI (Hotspot) a las guías, en un viaje fascinante a través de su aplicación y las peculiaridades de su trabajo, sumergirse en la atmósfera de élite de los equipos de ensamblaje, visitar varias arquitecturas y mucho más.