Comenzando un ejemplo
A continuación, escribiremos una aplicación simple en java (el autor usó java 14, pero java 8 también está bien), mediremos su rendimiento usando contadores dentro de la aplicación e intentaremos mejorar el resultado ejecutando el código en varios hilos. Todo lo que se requiere para reproducir el ejemplo es cualquier entorno de desarrollo java o simplemente jdk y una utilidad visualvm que nos ayudará a diagnosticar los problemas que han surgido. El ejemplo no utiliza intencionalmente varios puntos de referencia para medir el rendimiento y otras herramientas avanzadas; en este caso, son superfluos. El caso de prueba se ejecutó bajo Windows en un procesador Intel Core i7 con 4 núcleos físicos y 8 lógicos.
Entonces, creemos una aplicación simple que, en un bucle, realizará una tarea computacional que sobrecarga al procesador, es decir, el cálculo del factorial. Además, cada tarea en el ciclo también calculará el factorial de un número en el rango de 1 a 25. El rango flotante se toma para acercar el ejemplo a la realidad. A continuación se muestra el código de la función work ():
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(RandomUtils.nextInt(1, 25));
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
La función recibe como entrada el número de ciclos para calcular el factorial, especificado por una constante:
private static final int POWER_BASE = 1000000;Después de completar una cierta cantidad de tareas especificadas en la variable
private static final int LOG_STEP = 10;Se registran el número de tareas completadas y el tiempo total de su ejecución. La función
work () también utiliza:
//
private long startTime;
//
private AtomicLong counter = new AtomicLong();
//
private long factorial(int power) {
if (power == 1) return power;
else return power * factorial(power - 1);
}
Cabe señalar que una ejecución única de la función work () en un hilo tarda unos 20 ms, por lo que una llamada sincronizada a la variable del contador compartido al final, que podría ser un cuello de botella, no crea problemas, ya que ocurre para cada hilo no más de 20 veces ms, que supera significativamente el tiempo de ejecución de counter.incrementAndGet (). En otras palabras, la contención entre subprocesos asociada con el acceso a un contador sincronizado no debería afectar significativamente los resultados del experimento y puede descuidarse.
Ejecutemos el siguiente código en un hilo y veamos el resultado:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
work(POWER_BASE);
}
En la consola vemos el siguiente resultado:
10 Tareas completadas en 0 segundos
...
100 Tareas completadas en 2 segundos
...
500 Tareas completadas en 10 segundos
Entonces, en un hilo obtuvimos un rendimiento igual a 50 tareas por segundo o 20 ms por tarea.
Código de paralelización
Si obtuvimos el rendimiento X en un hilo, luego en 4 procesadores, en ausencia de carga adicional, podemos esperar que el rendimiento sea aproximadamente 4 * X, es decir, aumentará 4 veces. Esto parece bastante lógico. Bueno, intentemos!
Introduzcamos un grupo simple con un número fijo de subprocesos:
private ExecutorService executorService = Executors.newFixedThreadPool(POOL_SIZE);
Constante:
private static final int POOL_SIZE = 1;Cambiaremos en el rango de 1 a 16 y arreglaremos el resultado.
Rediseño del código de lanzamiento:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executorService.execute(() -> work(POWER_BASE));
}
De forma predeterminada, el tamaño de la cola de tareas en el grupo de subprocesos es Integer.MAX_VALUE, no agregamos más de Integer.MAX_VALUE tareas al grupo de subprocesos, por lo que la cola de tareas no debe desbordarse.
¡Vamos!
Primero, establezcamos la constante POOL_SIZE en 8 subprocesos:
private static final int POOL_SIZE = 8;Ejecute la aplicación y observe la consola:
10 tareas completadas en 3 segundos
20 tareas completadas en 6 segundos
30 tareas completadas en 8 segundos
40 tareas completadas en 10 segundos
50 tareas completadas en 14 segundos
60 tareas completadas en 16 segundos
70 tareas completadas en 19 segundos
80 Tareas completadas en 20 segundos
90 Tareas completadas en 23 segundos
100 Tareas completadas en 24 segundos
110 Tareas completadas en 26 segundos
120 Tareas completadas en 28 segundos
130 Tareas completadas en 29 segundos
140 Tareas completadas en 31 segundos
150 Tareas completadas en 33 segundos
160 Tareas completadas en 36 segundos
170 tareas completadas en 46 segundos
¿Qué vemos? En lugar del aumento de rendimiento esperado, se redujo más de 10 veces de 20 ms por tarea a 270 ms. ¡Pero eso no es todo! El mensaje sobre 170 tareas completadas es el último del registro. Entonces la aplicación pareció haberse detenido por completo.
Antes de abordar las razones de este comportamiento extraño del programa, comprendamos la dinámica y eliminemos el registro secuencialmente para 4 y 16 subprocesos estableciendo la constante POOL_SIZE en los valores apropiados.
Registro de 4 subprocesos:
10 tareas completadas en 2 segundos
20 tareas completadas en 4 segundos
30 tareas completadas en 6 segundos
40 tareas completadas en 8 segundos
50 tareas completadas en 10 segundos
60 tareas completadas en 13 segundos
70 tareas completadas en 15 segundos
80 tareas completadas en 18 segundos
90 tareas completadas en 21 segundos
100 tareas completadas en 33 segundos
Las primeras 90 tareas se completaron aproximadamente en el mismo tiempo que para 8 subprocesos, luego se necesitaron otros 12 segundos para completar otras 10 tareas y la aplicación se colgó.
Registro para 16 subprocesos:
10 tareas completadas en 2 segundos
20 tareas completadas en 3 segundos
30 tareas completadas en 6 segundos
40 tareas completadas en 8 segundos
...
290 tareas completadas en 51 segundos
300 tareas completadas en 52 segundos
310 tareas completadas en 63 segundos
Después de la finalización Para 310 tareas, la aplicación se congeló y, como en los casos anteriores, las últimas 10 tareas tardaron más de 10 segundos en completarse.
Resumamos:
La paralelización de la ejecución de tareas conduce a la degradación del rendimiento en 10 o más veces.En
todos los casos, la aplicación se cuelga y cuantos menos hilos, más rápido se cuelga (volveremos a este hecho)
Buscar problemas
Obviamente, algo anda mal con nuestro código. Pero, ¿cómo encuentras la razón? Para hacer esto, usaremos la utilidad visualvm. Y lo lanzaremos antes de la ejecución de nuestra aplicación, y luego de lanzar la aplicación cambiaremos al proceso java requerido en la interfaz visualvm. La aplicación se puede iniciar directamente desde el entorno de desarrollo. Por supuesto, esto es generalmente incorrecto, pero en nuestro ejemplo no afectará el resultado.
En primer lugar, miramos la pestaña Monitor y vemos que algo anda mal con la memoria.
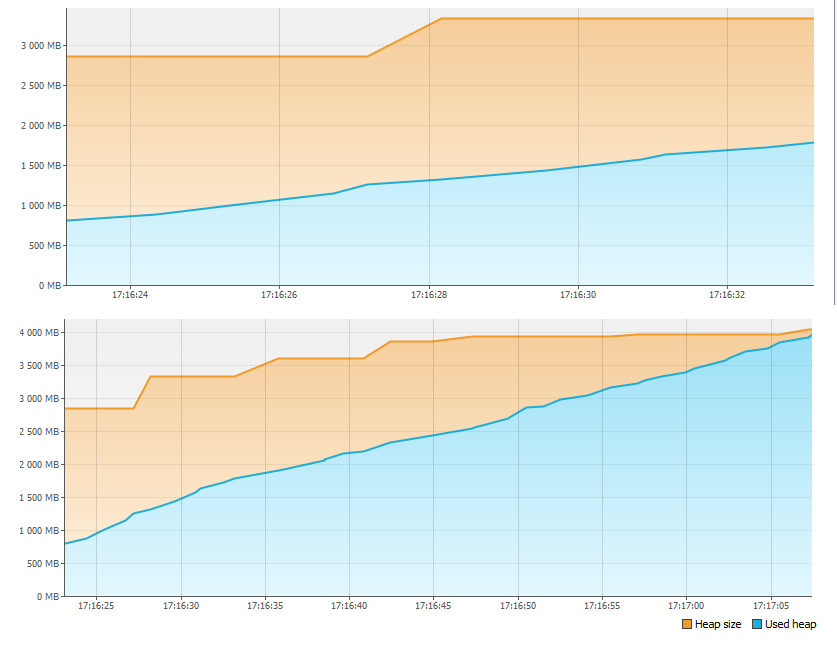
En menos de un minuto, ¡simplemente se agotaron 4GB de memoria! Por tanto, la aplicación se detuvo. ¿Pero a dónde se fue el recuerdo?
Reinicie la aplicación y presione el botón Heap Dump en la pestaña Monitor. Después de eliminar y abrir el volcado de memoria, vemos:

En la sección Clases por tamaño de instancias, la clase LinkedBlockingQueue $ Node ocupa más de 1 GB. No es más que una parte superior de la cola de tareas del grupo de subprocesos. La segunda clase más grande es la tarea en sí que se agrega al grupo de subprocesos. En apoyo de esto, en la sección Clases por número de instancias, vemos la correspondencia entre el número de instancias de la primera y la segunda clase (la coincidencia no es del todo precisa, aparentemente debido al hecho de que primero se crea una tarea, y luego solo una nueva parte superior de la cola, y debido a la diferencia de tiempo multiplicado por el número de subprocesos, tenemos una ligera discrepancia en el número de instancias).
Ahora vamos a contar. Creamos alrededor de 2 mil millones de tareas en un ciclo (Integer.MAX_VALUE), es decir, alrededor de 2 GB de tareas. Las tareas se ejecutan más lentamente de lo que se crean, por lo que el tamaño de la cola sigue creciendo. Incluso si cada tarea requiriera solo 8 bytes de memoria, el tamaño máximo de la cola sería:
8 * 2GB = 16GB
Con un tamaño de pila total de 4GB, no es sorprendente que no hubiera suficiente memoria. De hecho, si no interrumpiéramos la ejecución de la aplicación, cuyo log se detuvo, al cabo de un tiempo veríamos el famoso OutOfMemoryError e incluso sin visualvm, con solo mirar el código, podríamos adivinar hacia dónde va la memoria.
Recordemos que cuanto menor sea el número de subprocesos que ejecutan las tareas, más rápido se detuvo la aplicación. Ahora podemos intentar explicar esto. Cuanto menor sea el número de subprocesos, más rápido se ejecutará la aplicación (por qué, todavía tenemos que averiguarlo) y más rápido se llenará la cola de tareas y se llenará la memoria.
Bueno, solucionar el problema del desbordamiento de la memoria es muy sencillo. Creemos una constante en lugar de Integer.MaxValue:
privado estático final int MAX_TASKS = 1024 * 1024;
Y cambiemos el código de la siguiente manera:
startTime = System.currentTimeMillis();
for (int i = 0; i < MAX_TASKS; i++) {
executorService.execute(() -> work(POWER_BASE));
}
Ahora queda ejecutar la aplicación y asegurarse de que todo esté en orden con la memoria:

Continuamos el análisis
Iniciamos nuestra aplicación nuevamente, aumentando gradualmente el número de hilos y arreglando el resultado.
1 hilo - 500 tareas en 10 segundos
2 hilos - 500 tareas en 21 segundos
4 hilos - 500 tareas en 37 segundos
8 hilos - 500 tareas en 49 segundos
16 hilos - 500 tareas en 57 segundos
Como podemos ver, el tiempo de ejecución de 500 tareas al aumentar el número de subprocesos no disminuye, sino que aumenta, mientras que la velocidad de ejecución de cada parte de las 10 tareas es uniforme y los subprocesos ya no se congelan.
Usemos la utilidad visualvm nuevamente y realicemos un volcado de subprocesos mientras se ejecuta la aplicación. Para obtener una imagen más precisa, es mejor hacer un volcado cuando se trabaja en 16 hilos. Existen diferentes utilidades para analizar volcados de subprocesos, pero en nuestro caso, simplemente puede desplazarse por todos los subprocesos con los nombres "pool-1-thread-1", "pool-1-thread-2", etc. en la interfaz visualvm y ver lo siguiente:

En el momento del dumping, la mayoría de los hilos generan el siguiente número aleatorio para calcular el factorial. Resulta que esta es la función que consume más tiempo. ¿Porqué entonces? Para resolverlo, vayamos al código fuente de Random.next () y veamos lo siguiente:
private final AtomicLong seed;
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
Todos los subprocesos comparten una única instancia de la variable semilla, cuyo acceso se sincroniza mediante la clase AtomicLong. Esto significa que cuando se genera cada número aleatorio, los subprocesos se ponen en cola para acceder a esta variable, en lugar de ejecutarse en paralelo. Por tanto, la productividad no crece. Pero, ¿por qué se cae? La respuesta es simple. Al paralelizar la ejecución, se gastan recursos adicionales en soportar el procesamiento paralelo, en particular, cambiando el contexto del procesador entre subprocesos. Resulta que han aparecido costos adicionales y los subprocesos aún no funcionan en paralelo, ya que compiten por el acceso al valor de la variable semilla y se ponen en cola cuando se llama a seed.compareAndSet (). Competencia entre hilos por un recurso limitado, tal vezla causa más común de degradación del rendimiento al paralelizar los cálculos.
Cambiemos el código de la función work () de la siguiente manera:
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(20);
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
y verifique nuevamente el rendimiento en un número diferente de subprocesos:
1 subproceso - 1000 tareas en 17 segundos
2 subprocesos - 1000 tareas en 10 segundos
4 subprocesos - 1000 tareas en 5 segundos
8 subprocesos - 1000 tareas en 4 segundos
16 subprocesos - 1000 tareas en 4 segundos
Ahora el resultado se acerca a nuestras expectativas. El rendimiento en 4 subprocesos se ha incrementado aproximadamente 4 veces. Además, el aumento en el rendimiento prácticamente se detuvo porque la paralelización está limitada por los recursos del procesador. Echemos un vistazo a los gráficos de carga del procesador, capturados a través de visualvm cuando se trabaja en 4 y 8 subprocesos.

Como puede ver en los gráficos, con 4 subprocesos, más del 50% de los recursos del procesador son gratuitos, y con 8 subprocesos, el procesador está casi al 100% utilizado. Esto significa que en este ejemplo, 8 subprocesos es el límite, el rendimiento adicional solo disminuirá. En nuestro ejemplo, el crecimiento del rendimiento ya se detuvo en 4 subprocesos, pero si los subprocesos, en lugar de calcular el factorial, realizaban E / S sincrónicas, lo más probable es que el límite de paralelización en el que da una ganancia de rendimiento podría aumentar significativamente. Los lectores pueden comprobar esto por sí mismos y escribir el resultado en los comentarios del artículo.Si
hablamos de práctica, se pueden señalar dos puntos importantes:
La paralelización suele ser eficaz cuando la cantidad de subprocesos es hasta 2 veces la cantidad de núcleos de procesador (por supuesto, en ausencia de otra carga de procesador) La
utilización de la CPU en la práctica no debe exceder el 80% para garantizar la tolerancia a fallas
Reducir la contención entre hilos
Dejándonos llevar por las conversaciones sobre rendimiento, nos olvidamos de una cosa esencial. Al cambiar la llamada a RandomUtils.nextInt () en el código a una constante, cambiamos la lógica comercial de nuestra aplicación. Volvamos al antiguo algoritmo evitando problemas de rendimiento. Descubrimos que llamar a RandomUtils.nextInt () hace que cada uno de los subprocesos use la misma variable semilla para generar un número aleatorio y, mientras tanto, esto es completamente opcional. Usando en nuestro ejemplo en lugar de
RandomUtils.nextInt(1, 25)de la clase ThreadLocalRandom:
ThreadLocalRandom.current().nextInt(1, 25)Resolverá el problema con la competencia. Ahora cada hilo utilizará su propia instancia de la variable interna necesaria para generar el siguiente número aleatorio.
El uso de una variable independiente para cada subproceso, en lugar del acceso sincronizado a una única instancia de una clase compartida entre subprocesos, es una técnica común para mejorar el rendimiento al reducir la contención entre subprocesos. La clase java.lang.ThreadLocal se puede utilizar para almacenar los valores de las variables en el contexto de un hilo, aunque existen herramientas más avanzadas, por ejemplo, Contexto de diagnóstico mapeado.
En conclusión, me gustaría señalar que reducir la competencia entre hilos no es solo una tarea técnica, sino también lógica. En nuestro ejemplo, cada hilo puede usar su propia instancia de variable sin ningún problema, pero ¿qué pasa si necesitamos una instancia para todos, por ejemplo, un contador común? En este caso, tendría que refactorizar el algoritmo en sí. Por ejemplo, almacene un contador en el contexto de cada flujo y periódicamente o cuando lo solicite calcular el valor del contador total en función de los valores de los contadores para cada flujo.
Conclusión
Entonces, hay 3 puntos que afectan el desempeño del procesamiento paralelo:
- Recursos de la CPU
- Competencia entre hilos
- Otros factores que afectan indirectamente al resultado general