
Implementamos y comparamos 4 optimizadores de entrenamiento de redes neuronales populares: optimizador de impulsos, propagación de rms, descenso de gradiente de mini lotes y estimación de par adaptativo. El repositorio, una gran cantidad de código Python y su salida, visualizaciones y fórmulas están todos bajo el corte.
Introducción
Un modelo es el resultado de un algoritmo de aprendizaje automático que se ejecuta en algunos datos. El modelo representa lo aprendido por el algoritmo. Esta es la "cosa" que persiste después de ejecutar el algoritmo en los datos de entrenamiento y representa las reglas, números y cualquier otra estructura de datos específica del algoritmo y necesaria para la predicción.
¿Qué es un optimizador?
Antes de pasar a esto, necesitamos saber qué es una función de pérdida. La función de pérdida es una medida de qué tan bien su modelo de predicción predice el resultado (o valor) esperado. La función de pérdida también se denomina función de costo (más información aquí ).
Durante el entrenamiento, intentamos minimizar la pérdida de función y actualizar los parámetros para mejorar la precisión. Los parámetros de la red neuronal suelen ser los pesos de los enlaces. En este caso, los parámetros se estudian en la etapa de entrenamiento. Entonces, el algoritmo en sí (y los datos de entrada) ajusta estos parámetros. Puede encontrar más información aquí .
Por lo tanto, el optimizador es un método para lograr mejores resultados, ayudando a acelerar el aprendizaje. En otras palabras, es un algoritmo que se usa para cambiar ligeramente parámetros como pesos y tasas de aprendizaje para mantener el modelo funcionando de manera correcta y rápida. Aquí hay una descripción general básica de los diversos optimizadores utilizados en el aprendizaje profundo y un modelo simple para comprender la implementación de ese modelo. Recomiendo encarecidamente clonar este repositorio y realizar cambios observando los patrones de comportamiento.
Algunos términos de uso común:
- Propagación hacia atrás
Los objetivos de la propagación hacia atrás son simples: ajustar cada peso en la red de acuerdo con cuánto contribuye al error general. Si reduce iterativamente el error de cada peso, termina con una serie de pesos que dan buenas predicciones. Encontramos la pendiente de cada parámetro para la función de pérdida y actualizamos los parámetros restando la pendiente (más información aquí ).

- Descenso de gradiente
El descenso de gradiente es un algoritmo de optimización utilizado para minimizar una función moviéndose iterativamente hacia el descenso más pronunciado, definido por un valor de gradiente negativo. En el aprendizaje profundo, utilizamos el descenso de gradientes para actualizar los parámetros del modelo (más información aquí ).
- Hiperparámetros
Un hiperparámetro de modelo es una configuración externa al modelo, cuyo valor no puede estimarse a partir de los datos. Por ejemplo, el número de neuronas ocultas, la tasa de aprendizaje, etc. No podemos estimar la tasa de aprendizaje a partir de los datos (más información aquí ).
- Tasa de aprendizaje
La tasa de aprendizaje (α) es un parámetro de ajuste en el algoritmo de optimización que determina el tamaño del paso en cada iteración mientras se mueve hacia el mínimo de la función de pérdida (más información aquí).
Optimizadores populares

A continuación se muestran algunos de los SEO más populares:
- Descenso de gradiente estocástico (SGD).
- Optimizador de momento.
- Propagación cuadrática media (RMSProp).
- Estimación de torque adaptativo (Adam).
Consideremos cada uno de ellos en detalle.
1. Descenso de gradiente estocástico (especialmente mini lotes)
Usamos un ejemplo a la vez cuando entrenamos el modelo (en SGD puro) y actualizamos el parámetro. Pero tenemos que usar otro para el bucle. Llevará mucho tiempo. Por lo tanto, utilizamos SGD de mini lotes.
El descenso de gradiente de mini lotes busca equilibrar la solidez del descenso de gradiente estocástico y la eficiencia del descenso de gradiente de lote. Esta es la implementación más común del descenso de gradientes que se usa en el aprendizaje profundo. En SGD de mini lotes, al entrenar el modelo, tomamos un grupo de ejemplos (por ejemplo, 32, 64 ejemplos, etc.). Este enfoque funciona mejor porque solo se necesita un bucle para el minibatch, no todos los ejemplos. Los minipaquetes se seleccionan aleatoriamente para cada iteración, pero ¿por qué? Cuando los mini-paquetes se eligen al azar, cuando se atascan en mínimos locales, algunos pasos ruidosos pueden llevar a la salida de estos mínimos. ¿Por qué necesitamos este optimizador?
- La tasa de actualización de los parámetros es mayor que en el descenso de gradiente por lotes simple, lo que permite una convergencia más confiable al evitar los mínimos locales.
- Las actualizaciones por lotes proporcionan un proceso computacionalmente más eficiente que el descenso de gradiente estocástico.
- Si tiene un poco de RAM, los mini-paquetes son la mejor opción. El procesamiento por lotes es eficiente debido a la falta de todos los datos de entrenamiento en la memoria y las implementaciones de algoritmos.
¿Cómo genero minipaquetes aleatorios?
def RandomMiniBatches(X, Y, MiniBatchSize):
m = X.shape[0]
miniBatches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :]
shuffled_Y = Y[permutation, :].reshape((m,1)) #sure for uptpur shape
num_minibatches = m // MiniBatchSize
for k in range(0, num_minibatches):
miniBatch_X = shuffled_X[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch_Y = shuffled_Y[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
#handeling last batch
if m % MiniBatchSize != 0:
# end = m - MiniBatchSize * m // MiniBatchSize
miniBatch_X = shuffled_X[num_minibatches * MiniBatchSize:, :]
miniBatch_Y = shuffled_Y[num_minibatches * MiniBatchSize:, :]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
return miniBatches
¿Cuál será el formato del modelo?
Estoy dando una descripción general del modelo en caso de que sea nuevo en el aprendizaje profundo. Se parece a esto:
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 64) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
params = update_params(params, grad, beta=0.9,learning_rate=learning_rate)
return params
En la siguiente figura, puede ver que hay grandes cambios en SGD. El movimiento vertical no es necesario: solo queremos movimiento horizontal. Si disminuye el movimiento vertical y aumenta el movimiento horizontal, el modelo aprenderá más rápido, ¿no está de acuerdo?

¿Cómo minimizar las vibraciones no deseadas? Los siguientes optimizadores los minimizan y ayudan a acelerar el aprendizaje.
2. Optimizador de impulsos
Hay muchas dudas en SGD o descenso de gradiente. Necesitas avanzar, no hacia arriba y hacia abajo. Necesitamos aumentar la tasa de aprendizaje del modelo en la dirección correcta y lo haremos con el optimizador de impulso.

Como puede ver en la imagen de arriba, la Línea Verde del Optimizador de Pulso es más rápida que otras. La importancia de aprender rápidamente se puede ver cuando tiene grandes conjuntos de datos y muchas iteraciones. ¿Cómo implementar este optimizador?

El valor normal de β es de aproximadamente 0,9. Puede
ver que hemos creado dos parámetros, vdW y vdb , a partir de los parámetros de retropropagación . Considere el valor β = 0.9, entonces la ecuación toma la forma:
vdw= 0.9 * vdw + 0.1 * dw
vdb = 0.9 * vdb + 0.1 * dbComo puede ver, vdw depende más del valor anterior de vdw que de dw. Cuando el renderizado es un gráfico, puede ver que el optimizador de impulso tiene en cuenta los degradados anteriores para suavizar la actualización. Por eso es posible minimizar las fluctuaciones. Cuando usamos SGD, el camino tomado por el descenso de gradiente de mini lotes osciló hacia la convergencia. Momentum Optimizer ayuda a reducir estas fluctuaciones.
def update_params_with_momentum(params, grads, v, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l + 1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads['dW' + str(l + 1)]
v["db" + str(l + 1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads['db' + str(l + 1)]
#updating parameters W and b
params["W" + str(l + 1)] = params["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
params["b" + str(l + 1)] = params["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return params
El repositorio está aquí
3. Diferencial cuadrático medio
La propagación de la raíz cuadrada media (RMSprop) es una media que decae exponencialmente. La propiedad esencial de RMSprop es que no está limitado solo a la suma de gradientes anteriores, sino que está más limitado a los gradientes de los últimos pasos de tiempo. RMSprop contribuye a la media exponencialmente decreciente de los "gradientes de ley cuadrada" del pasado. En RMSProp estamos tratando de reducir el movimiento vertical usando la media, porque suman aproximadamente 0 al tomar la media. RMSprop proporciona el promedio de la actualización.

Una fuente

Eche un vistazo al siguiente código. Esto le dará una comprensión básica de cómo implementar este optimizador. Todo es igual que con SGD, tenemos que cambiar la función de actualización.
def initilization_RMS(params):
s = {}
for i in range(len(params)//2 ):
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return s
def update_params_with_RMS(params, grads,s, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
s["dW" + str(l)]= beta * s["dW" + str(l)] + (1 - beta) * np.square(grads['dW' + str(l)])
s["db" + str(l)] = beta * s["db" + str(l)] + (1 - beta) * np.square(grads['db' + str(l)])
#updating parameters W and b
params["W" + str(l)] = params["W" + str(l)] - learning_rate * grads['dW' + str(l)] / (np.sqrt( s["dW" + str(l)] )+ pow(10,-4))
params["b" + str(l)] = params["b" + str(l)] - learning_rate * grads['db' + str(l)] / (np.sqrt( s["db" + str(l)]) + pow(10,-4))
return params
4. Adam Optimizer
Adam es uno de los algoritmos de optimización más eficientes en el entrenamiento de redes neuronales. Combina las ideas de RMSProp y Pulse Optimizer. En lugar de adaptar la tasa de aprendizaje de los parámetros en función de la media del primer momento (media) como en RMSProp, Adam también usa la media de los segundos momentos de los gradientes. En particular, el algoritmo calcula el promedio móvil exponencial del gradiente y el gradiente cuadrático, y los parámetros
beta1y beta2controla la tasa de caída de estos promedios móviles. ¿Cómo?
def initilization_Adam(params):
s = {}
v = {}
for i in range(len(params)//2 ):
v["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
v["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return v, s
def update_params_with_Adam(params, grads,v, s, beta1,beta2, learning_rate,t):
epsilon = pow(10,-8)
v_corrected = {}
s_corrected = {}
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l)] = beta1 * v["dW" + str(l)] + (1 - beta1) * grads['dW' + str(l)]
v["db" + str(l)] = beta1 * v["db" + str(l)] + (1 - beta1) * grads['db' + str(l)]
v_corrected["dW" + str(l)] = v["dW" + str(l)] / (1 - np.power(beta1, t))
v_corrected["db" + str(l)] = v["db" + str(l)] / (1 - np.power(beta1, t))
s["dW" + str(l)] = beta2 * s["dW" + str(l)] + (1 - beta2) * np.power(grads['dW' + str(l)], 2)
s["db" + str(l)] = beta2 * s["db" + str(l)] + (1 - beta2) * np.power(grads['db' + str(l)], 2)
s_corrected["dW" + str(l)] = s["dW" + str(l)] / (1 - np.power(beta2, t))
s_corrected["db" + str(l)] = s["db" + str(l)] / (1 - np.power(beta2, t))
params["W" + str(l)] = params["W" + str(l)] - learning_rate * v_corrected["dW" + str(l)] / np.sqrt(s_corrected["dW" + str(l)] + epsilon)
params["b" + str(l)] = params["b" + str(l)] - learning_rate * v_corrected["db" + str(l)] / np.sqrt(s_corrected["db" + str(l)] + epsilon)
return params
Hiperparámetros
- Valor de β1 (beta1) casi 0,9
- β2 (beta2) - casi 0.999
- ε: evita la división por cero (10 ^ -8) (no afecta demasiado el aprendizaje)
¿Por qué este optimizador?
Sus ventajas:
- Implementación simple.
- Eficiencia computacional.
- Requisitos de memoria bajos.
- Invariante a la escala diagonal de gradientes.
- Muy adecuado para grandes tareas en términos de datos y parámetros.
- Adecuado para fines no estacionarios.
- Adecuado para tareas con pendientes muy ruidosas o escasas.
- Los hiperparámetros son sencillos y generalmente requieren pocos ajustes.
Construyamos un modelo y veamos cómo los hiperparámetros aceleran el aprendizaje
Hagamos una demostración práctica de cómo acelerar el aprendizaje. En este artículo no vamos a explicar las otras cosas (inicialización, proyecciones,
forward_prop, back_prop, descenso de gradiente, y así sucesivamente. D.). Las funciones necesarias para el entrenamiento ya están integradas en NumPy. Si quieres echarle un vistazo, ¡ aquí tienes el enlace !
¡Empecemos!
Estoy creando una función de modelo genérico que funciona para todos los optimizadores discutidos aquí.
1. Inicialización:
Inicializamos los parámetros usando una función de inicialización que toma entradas como
features_size (en nuestro caso 12288) y una matriz oculta de tamaños (usamos [100,1]) y esta salida como parámetros de inicialización. Existe otro método de inicialización. Te animo a leer este artículo.
def initilization(input_size,layer_size):
params = {}
np.random.seed(0)
params['W' + str(0)] = np.random.randn(layer_size[0], input_size) * np.sqrt(2 / input_size)
params['b' + str(0)] = np.zeros((layer_size[0], 1))
for l in range(1,len(layer_size)):
params['W' + str(l)] = np.random.randn(layer_size[l],layer_size[l-1]) * np.sqrt(2/layer_size[l])
params['b' + str(l)] = np.zeros((layer_size[l],1))
return params
2. Propagación hacia adelante:
En esta función, la entrada es X, así como los parámetros, la extensión de las capas ocultas y el abandono, que se utilizan en la técnica de abandono.
Establecí el valor en 1, por lo que no habrá ningún efecto en el entrenamiento. Si su modelo está sobreajustado, puede establecer un valor diferente. Solo aplico el abandono en las capas pares .
Calculamos el valor de activación para cada capa usando una función
forward_activation.
#activations-----------------------------------------------
def forward_activation(A_prev, w, b, activation):
z = np.dot(A_prev, w.T) + b.T
if activation == 'relu':
A = np.maximum(0, z)
elif activation == 'sigmoid':
A = 1/(1+np.exp(-z))
else:
A = np.tanh(z)
return A
#________model forward ____________________________________________________________________________________________________________
def model_forward(X,params, L,keep_prob):
cache = {}
A =X
for l in range(L-1):
w = params['W' + str(l)]
b = params['b' + str(l)]
A = forward_activation(A, w, b, 'relu')
if l%2 == 0:
cache['D' + str(l)] = np.random.randn(A.shape[0],A.shape[1]) < keep_prob
A = A * cache['D' + str(l)] / keep_prob
cache['A' + str(l)] = A
w = params['W' + str(L-1)]
b = params['b' + str(L-1)]
A = forward_activation(A, w, b, 'sigmoid')
cache['A' + str(L-1)] = A
return cache, A
3. Retropropagación:
Aquí escribimos la función de retropropagación. Devolverá grad ( pendiente ). Usamos
gradal actualizar los parámetros, (si no lo sabe). Recomiendo leer este artículo.
def backward(X, Y, params, cach,L,keep_prob):
grad ={}
m = Y.shape[0]
cach['A' + str(-1)] = X
grad['dz' + str(L-1)] = cach['A' + str(L-1)] - Y
cach['D' + str(- 1)] = 0
for l in reversed(range(L)):
grad['dW' + str(l)] = (1 / m) * np.dot(grad['dz' + str(l)].T, cach['A' + str(l-1)])
grad['db' + str(l)] = 1 / m * np.sum(grad['dz' + str(l)].T, axis=1, keepdims=True)
if l%2 != 0:
grad['dz' + str(l-1)] = ((np.dot(grad['dz' + str(l)], params['W' + str(l)]) * cach['D' + str(l-1)] / keep_prob) *
np.int64(cach['A' + str(l-1)] > 0))
else :
grad['dz' + str(l - 1)] = (np.dot(grad['dz' + str(l)], params['W' + str(l)]) *
np.int64(cach['A' + str(l - 1)] > 0))
return grad
Ya hemos visto la función de actualización del optimizador, así que la usaremos aquí. Hagamos algunos cambios menores a la función del modelo de la discusión de SGD.
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
costs = []
itr = []
if optimizer == 'momentum':
v = initilization_moment(params)
elif optimizer == 'rmsprop':
s = initilization_RMS(params)
elif optimizer == 'adam' :
v,s = initilization_Adam(params)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 32) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
if optimizer == 'momentum':
params = update_params_with_momentum(params, grad, v, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'rmsprop':
params = update_params_with_RMS(params, grad, s, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'adam' :
params = update_params_with_Adam(params, grad,v, s, beta1=0.9,beta2=0.999, learning_rate=learning_rate,t=i) #UPDATE PARAMETERS
elif optimizer == "minibatch":
params = update_params(params, grad,learning_rate=learning_rate)
if i%5 == 0:
costs.append(cost)
itr.append(i)
if i % 100 == 0 :
print('cost of iteration______{}______{}'.format(i,cost))
return params,costs,itr
Entrenamiento con mini packs
params, cost_sgd,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='minibatch')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Conclusión al acercarse con mini paquetes:
cost of iteration______100______0.35302967575683797
cost of iteration______200______0.472914548745098
cost of iteration______300______0.4884728238471557
cost of iteration______400______0.21551100063345618
train_accuracy------------ 0.8494208494208494
Entrenamiento del optimizador de pulso
params,cost_momentum, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='momentum')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Salida del optimizador de pulsos:
cost of iteration______100______0.36278494129038086
cost of iteration______200______0.4681552335189021
cost of iteration______300______0.382226159384529
cost of iteration______400______0.18219310793752702 train_accuracy------------ 0.8725868725868726Entrenamiento con RMSprop
params,cost_rms,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='rmsprop')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Salida RMSprop:
cost of iteration______100______0.2983858963793841
cost of iteration______200______0.004245700579927428
cost of iteration______300______0.2629426607580565
cost of iteration______400______0.31944824707807556 train_accuracy------------ 0.9613899613899614Entrenando con Adam
params,cost_adam, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='adam')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Conclusión de Adam:
cost of iteration______100______0.3266223660473619
cost of iteration______200______0.08214547683157716
cost of iteration______300______0.0025645257286439583
cost of iteration______400______0.058015188756586206 train_accuracy------------ 0.9845559845559846¿Has visto la diferencia de precisión entre los dos? Usamos los mismos parámetros de inicialización, la misma tasa de aprendizaje y el mismo número de iteraciones; solo el optimizador es diferente, ¡pero mira el resultado!
Mini-batch accuracy : 0.8494208494208494
momemtum accuracy : 0.8725868725868726
Rms accuracy : 0.9613899613899614
adam accuracy : 0.9845559845559846Visualización gráfica del modelo

Puedes consultar el repositorio si tienes dudas sobre el código.
Resumen
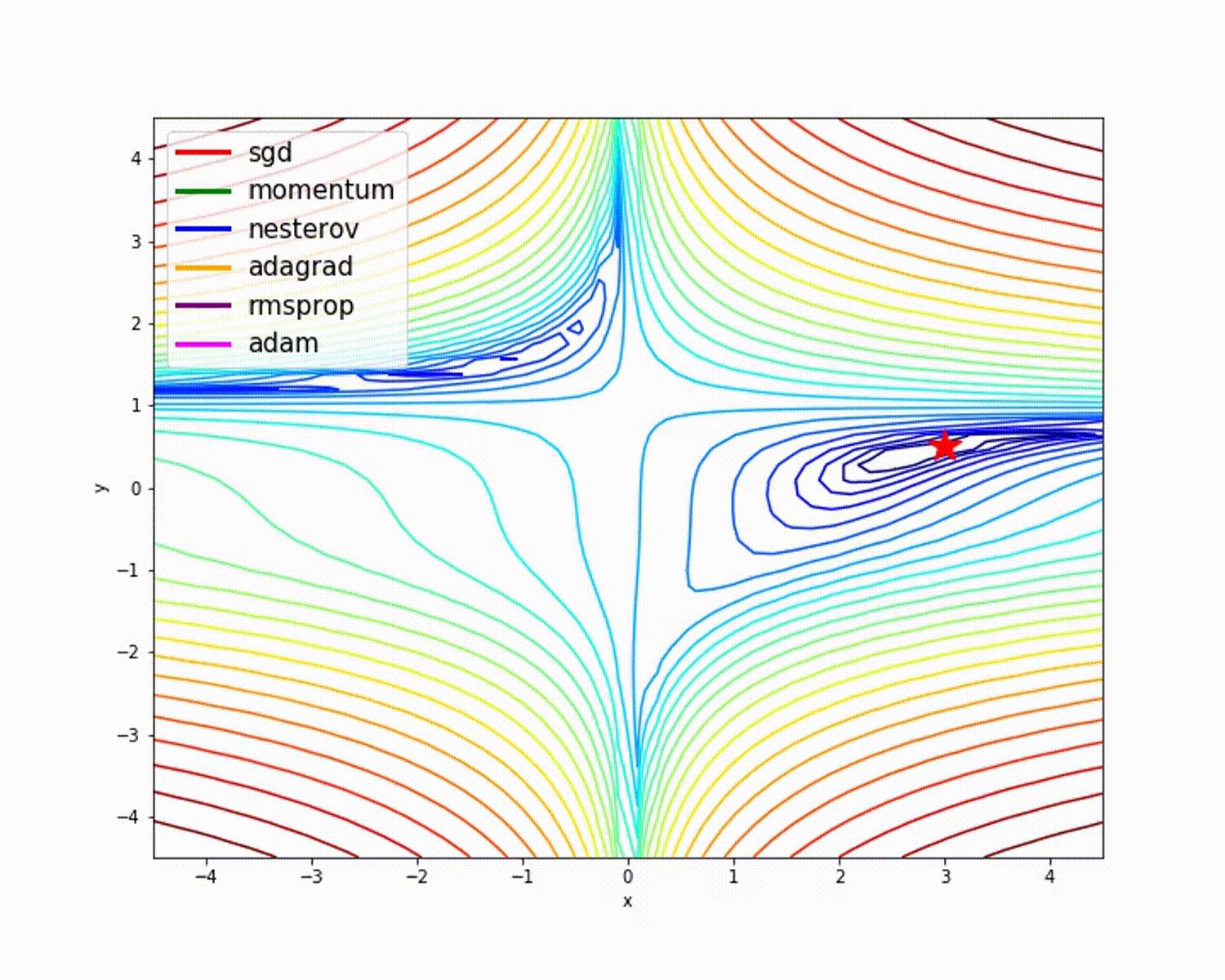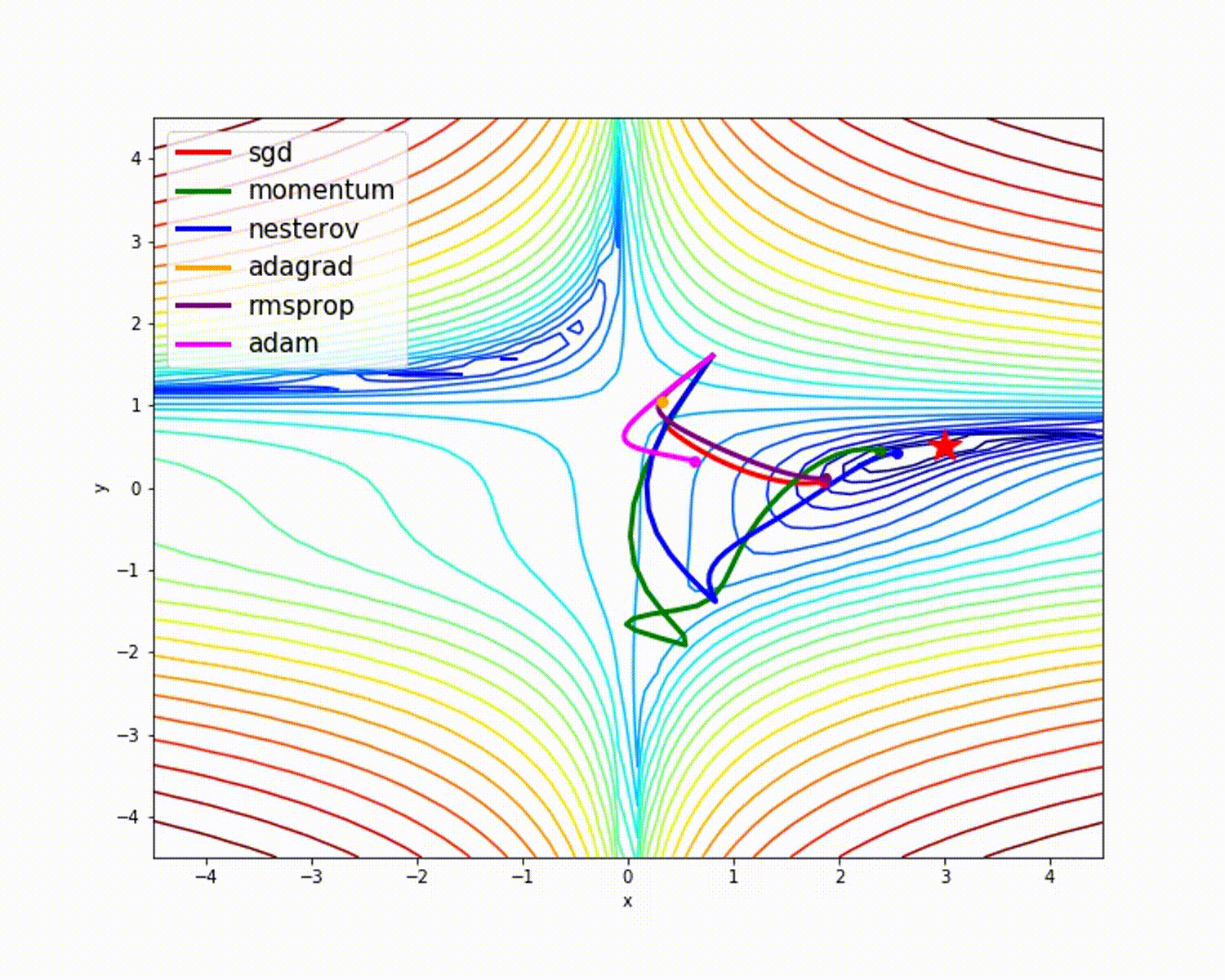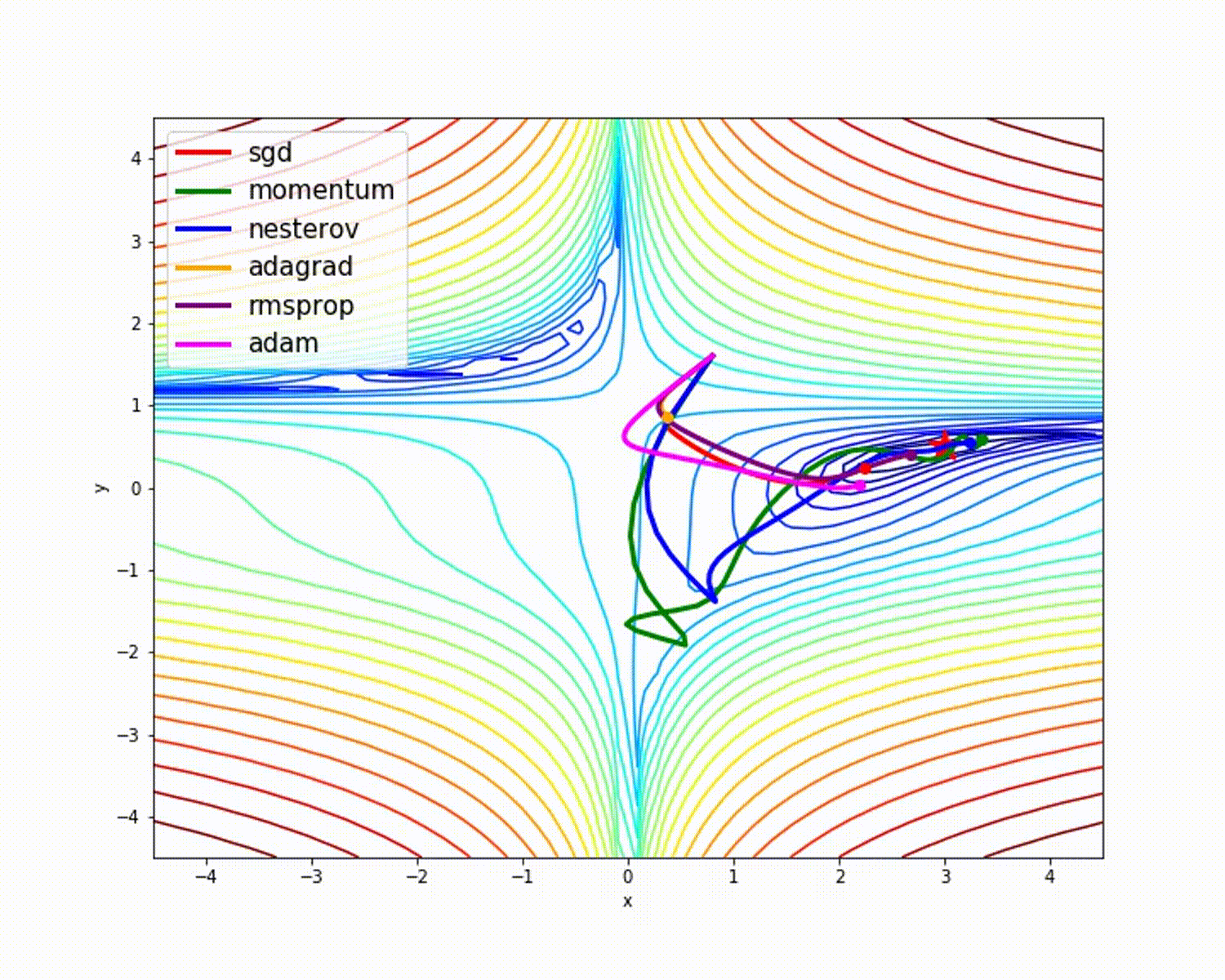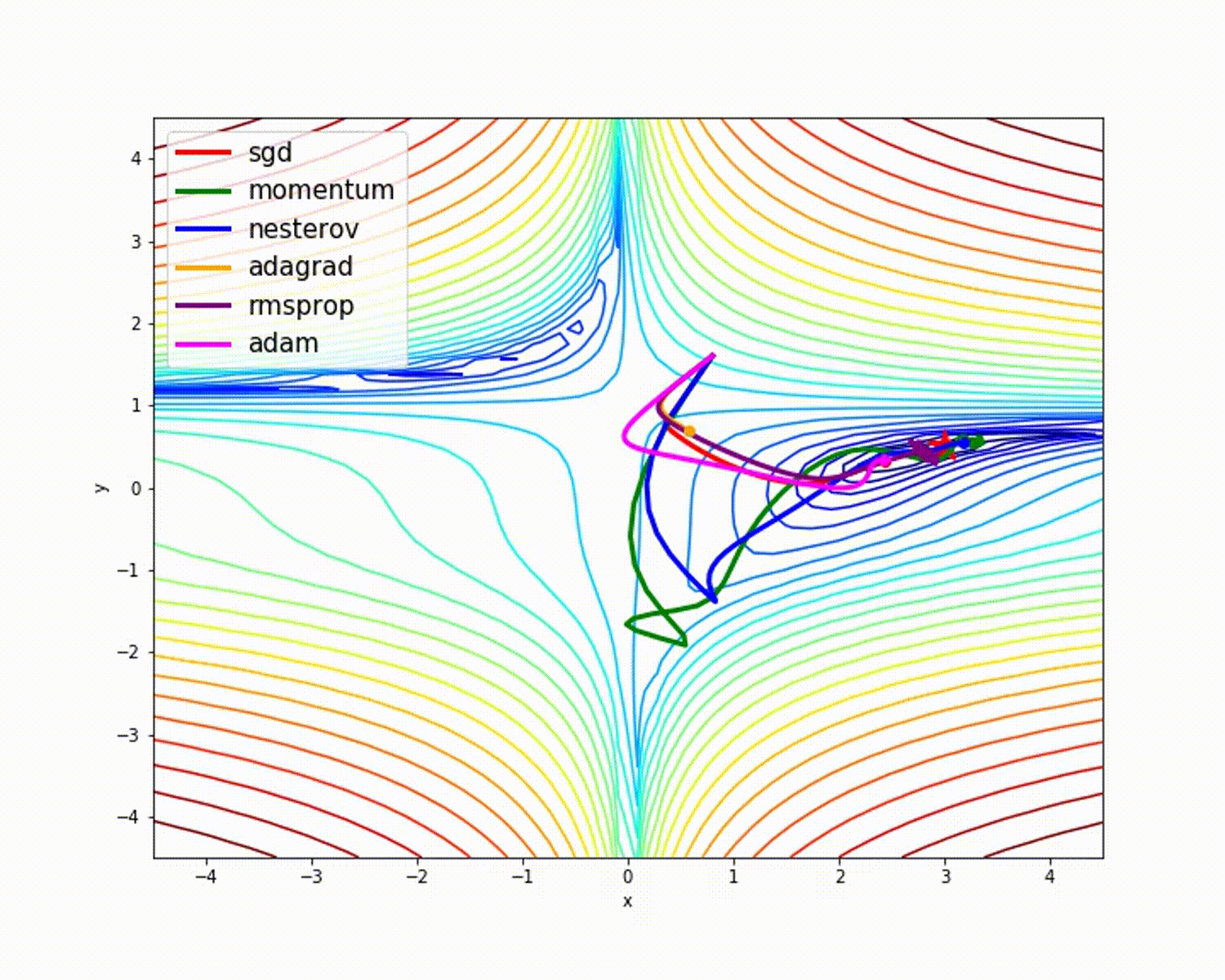
fuente
Como hemos visto, el optimizador de Adam ofrece una buena precisión en comparación con otros optimizadores. La imagen de arriba muestra cómo el modelo aprende a través de iteraciones. Momentum da la velocidad SGD y RMSProp da el promedio exponencial de los pesos para los parámetros actualizados. Hemos utilizado menos datos en el modelo anterior, pero veremos más beneficios de los optimizadores cuando trabajemos con grandes conjuntos de datos y muchas iteraciones. Hemos hablado de la idea básica de los optimizadores y espero que esto le dé algo de motivación para aprender más sobre los optimizadores y utilizarlos.
Recursos
- Coursera —
- —
Las perspectivas para las redes neuronales y el aprendizaje automático profundo son enormes y, según las estimaciones más conservadoras, su impacto en el mundo será aproximadamente el mismo que el impacto de la electricidad en la industria en el siglo XIX. Los expertos que evalúan estas perspectivas antes que nadie tienen todas las posibilidades de convertirse en líderes del progreso. Para estas personas, hemos creado un código de promoción HABR , que otorga un 10% adicional al descuento de capacitación indicado en el banner.

- Curso de aprendizaje automático
- Curso "Matemáticas y aprendizaje automático para la ciencia de datos"
- Curso avanzado "Machine Learning Pro + Deep Learning"
- Bootcamp en línea para ciencia de datos
- Formación de la profesión de analista de datos desde cero
- Bootcamp en línea de análisis de datos
- Enseñar la profesión de ciencia de datos desde cero
- Curso de Python para desarrollo web
Más cursos
- DevOps
- -
- iOS-
- Android-
- Java-
- JavaScript
Artículos recomendados
- Cómo convertirse en un científico de datos sin cursos en línea
- 450
- Machine Learning 5 9
- : 2020
- Machine Learning Computer Vision