
Unicornio rinoceronte mítico. MS TECH / PIXABAY
Aprender en menos de un intento ayuda a un modelo a identificar más objetos que la cantidad de ejemplos en los que se ha entrenado.
Normalmente, el aprendizaje automático requiere muchos ejemplos. Para que un modelo de IA reconozca un caballo, debe mostrarle miles de imágenes de caballos. Esta es la razón por la que la tecnología es tan cara desde el punto de vista computacional y muy diferente del aprendizaje humano. Un niño a menudo necesita ver solo algunos ejemplos de un objeto, o incluso uno, para aprender a reconocerlo de por vida.
De hecho, los niños a veces no necesitan ningún ejemplo para identificar algo. Muestre imágenes de un caballo y un rinoceronte, dígales que el unicornio está en el medio y reconocerán a la criatura mítica en el libro de imágenes tan pronto como la vean por primera vez.

Mmm ... ¡En realidad no! MS TECH / PIXABAY
Ahora, una investigación de la Universidad de Waterloo en Ontario sugiere que los modelos de IA también pueden hacer esto, un proceso que los investigadores llaman aprendizaje "en menos de un" intento. En otras palabras, el modelo de IA puede reconocer claramente más objetos que la cantidad de ejemplos en los que se ha entrenado. Esto puede ser crítico en un área que se vuelve cada vez más cara e inaccesible a medida que crecen los conjuntos de datos utilizados.
« »
Los investigadores primero demostraron esta idea al experimentar con un popular conjunto de datos de entrenamiento de visión por computadora conocido como MNIST. MNIST contiene 60.000 imágenes de números escritos a mano del 0 al 9, y el conjunto se utiliza a menudo para probar nuevas ideas en esta área.
En un artículo anterior, los investigadores del Instituto de Tecnología de Massachusetts presentaron un método para "destilar" conjuntos de datos gigantes en pequeños. Como prueba de concepto, comprimieron MNIST a 10 imágenes. No se tomaron muestras de las imágenes del conjunto de datos original. Han sido cuidadosamente diseñados y optimizados para contener el equivalente a un conjunto completo de información. Como resultado, cuando se entrena en estas 10 imágenes, el modelo de IA logra casi la misma precisión que se entrena en todo el conjunto MNIST.

Imágenes de muestra del conjunto MNIST. WIKIMEDIA

10 en la foto, "destilada" de MNIST, puede entrenar un modelo de IA para lograr un 94 por ciento de precisión en el reconocimiento de dígitos escritos a mano. Tongzhou Wang et al.
Investigadores de la Universidad de Wotrelu querían continuar con el proceso de destilación. Si es posible reducir 60.000 imágenes a 10, ¿por qué no comprimirlas a cinco? Se dieron cuenta de que el truco consistía en mezclar varios números en una imagen y luego introducirlos en un modelo de IA con las llamadas etiquetas híbridas o "blandas". (Imagine un caballo y un rinoceronte a los que se les han dado las características de un unicornio).
"Piense en el número 3, parece el número 8, pero no el número 7", dice Ilya Sukholutsky, estudiante de posgrado de Waterloo y autor principal del artículo. - Las marcas suaves intentan capturar estas similitudes. Entonces, en lugar de decirle al auto: "Esta imagen es el número 3", decimos: "Esta imagen es 60% número 3, 30% número 8 y 10% número 0" ".
Limitaciones del nuevo método de enseñanza
Después de que los investigadores utilizaron con éxito etiquetas suaves para lograr adaptaciones del MNIST al aprendizaje en menos de un intento, comenzaron a preguntarse hasta dónde podría llegar la idea. ¿Existe un límite en la cantidad de categorías que un modelo de IA puede aprender a identificar a partir de una pequeña cantidad de ejemplos?
Sorprendentemente, parece que no hay límite. Con etiquetas blandas cuidadosamente diseñadas, incluso dos ejemplos podrían codificar teóricamente cualquier número de categorías. “Con solo dos puntos, puede dividir mil clases, o 10,000 clases, o un millón de clases”, dice Sukholutsky.
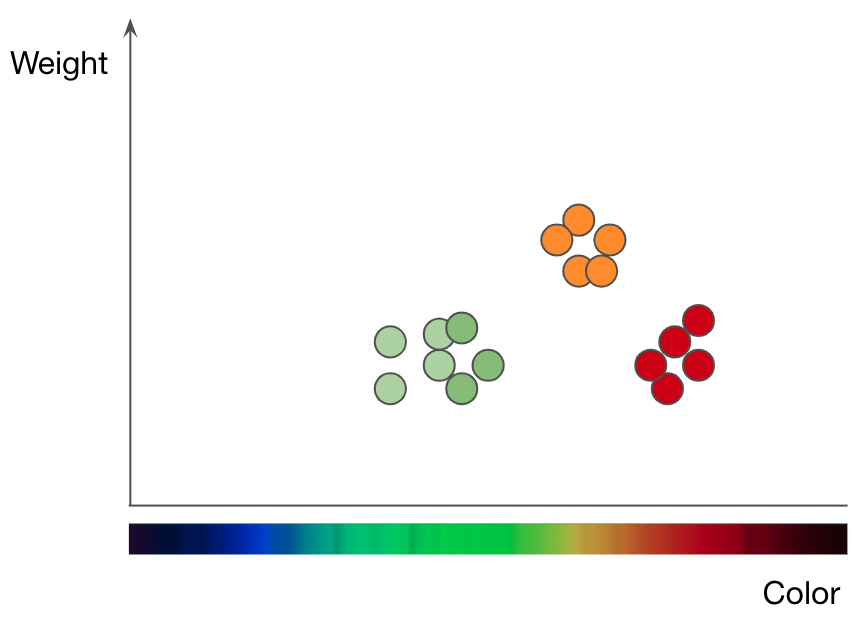
Desglose de manzanas (puntos verdes y rojos) y naranjas (puntos naranjas) por peso y color. Adaptado de la presentación de Jason Mace Machine Learning 101
Esto es lo que mostraron los científicos en su último artículo a través de una investigación puramente matemática. Implementaron este concepto utilizando uno de los algoritmos de aprendizaje automático más simples conocido como k vecinos más cercanos (kNN), que clasifica los objetos mediante un enfoque gráfico.
Para comprender cómo funciona el método kNN, tomemos un problema de clasificación de frutas como ejemplo. Para entrenar el modelo kNN para que comprenda la diferencia entre manzanas y naranjas, primero debe seleccionar las funciones que desea utilizar para representar cada fruta. Si elige color y peso, entonces para cada manzana y naranja ingresa un punto de datos con el color de la fruta como valor x y el peso como valor y... El algoritmo kNN luego traza todos los puntos de datos en un gráfico 2D y traza una línea a medio camino entre las manzanas y las naranjas. El gráfico ahora está claramente dividido en dos clases, y el algoritmo puede decidir si los nuevos puntos de datos representan manzanas o naranjas, dependiendo de qué lado de la línea esté el punto.
Para estudiar el aprendizaje en menos de un intento con el algoritmo kNN, los investigadores crearon una serie de pequeños conjuntos de datos sintéticos y pensaron cuidadosamente en sus etiquetas blandas. Luego dejaron que el algoritmo kNN trazara los límites que vio y descubrieron que dividió con éxito el gráfico en más clases que puntos de datos. Los investigadores también han controlado en gran medida dónde discurren las fronteras. Usando varias modificaciones a las etiquetas suaves, hicieron que el algoritmo kNN dibujara patrones precisos en forma de flores.
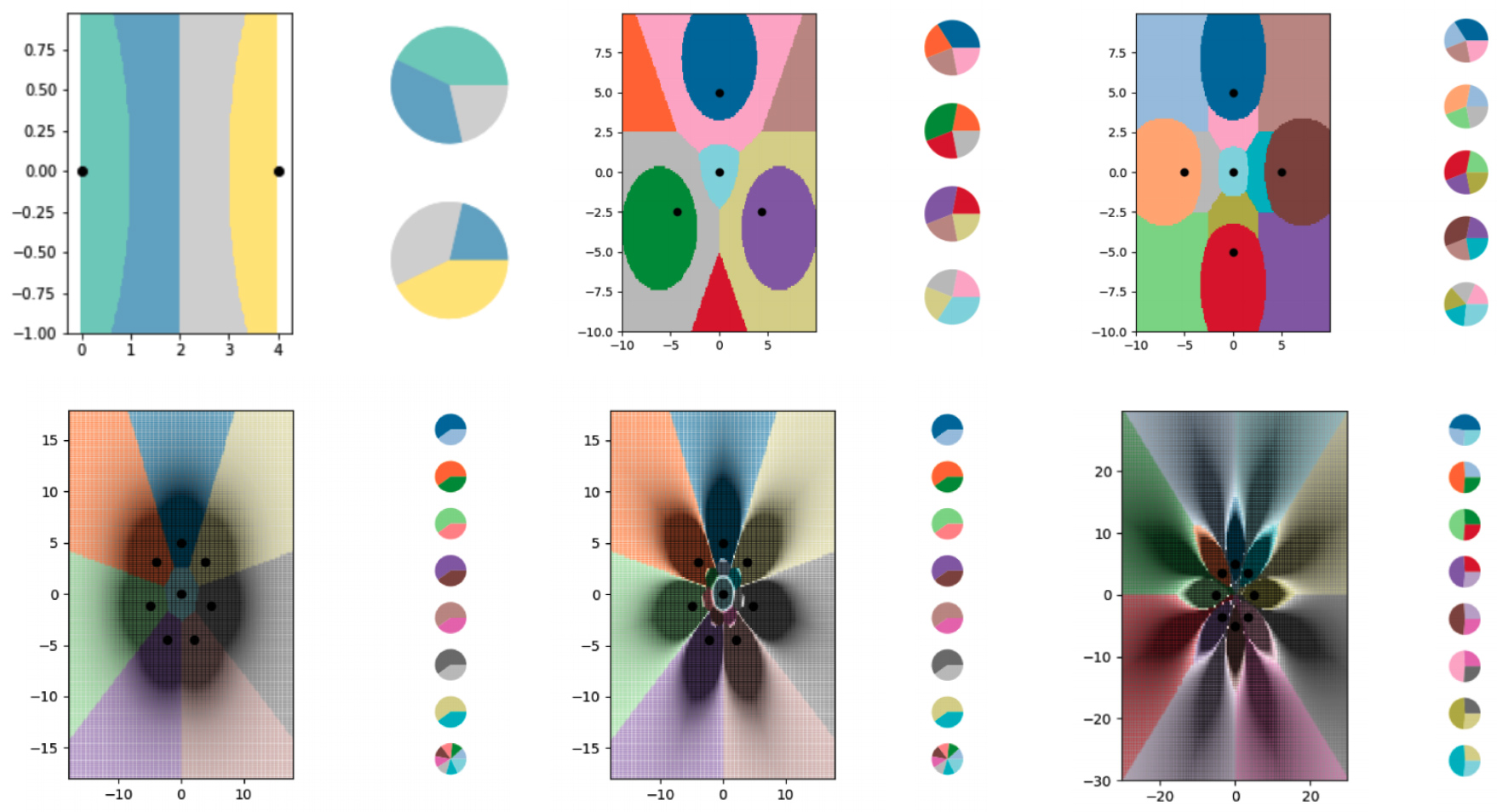
Los investigadores utilizaron ejemplos de etiquetas blandas para entrenar el algoritmo kNN para codificar límites cada vez más complejos y dividir el diagrama en más clases que puntos de datos. Cada una de las áreas coloreadas representa una clase separada, y los gráficos circulares junto a cada gráfico muestran la distribución de etiquetas suaves para cada punto de datos.
Ilya Sukholutskiy et al.Varios
diagramas muestran los límites construidos utilizando el algoritmo kNN. Cada gráfico tiene cada vez más líneas de límites codificadas en pequeños conjuntos de datos.
Por supuesto, estos estudios teóricos tienen algunas limitaciones. Si bien la idea de aprender de "menos de un" intento sería deseable para transferirla a algoritmos más complejos, la tarea de desarrollar ejemplos con una etiqueta "blanda" se vuelve mucho más complicada. El algoritmo kNN es interpretado y visual, lo que permite a las personas crear etiquetas. Las redes neuronales son complejas e impenetrables, lo que significa que lo mismo puede no ser cierto para ellas. La destilación de datos, que es buena para desarrollar ejemplos de etiquetas suaves para redes neuronales, también tiene un inconveniente importante: requiere que comiences con un conjunto de datos gigante, reduciéndolo a algo más eficiente.
Sukholutsky dice que está tratando de encontrar otras formas de crear estos pequeños conjuntos de datos sintéticos, ya sea a mano o con otro algoritmo. A pesar de estas complejidades de investigación adicionales, el artículo presenta los fundamentos teóricos del aprendizaje. “Independientemente de los conjuntos de datos que tenga, puede lograr ganancias de eficiencia significativas”, dijo.
Esto es lo que más le interesa a Tongzhou Wang, un estudiante graduado del Instituto de Tecnología de Massachusetts. Dirigió la investigación previa sobre datos de destilación. "Este artículo se basa en un objetivo realmente nuevo e importante: entrenar modelos potentes a partir de pequeños conjuntos de datos", dice sobre la contribución de Sukholutsky.
Ryan Hurana, investigador del Instituto de Montreal para la Ética de la Inteligencia Artificial, comparte este punto de vista: "Más importante aún, aprender en menos de un intento reducirá drásticamente los requisitos de datos para construir un modelo funcional". Esto podría hacer que la IA sea más accesible para las empresas y las industrias que hasta ahora se han visto obstaculizadas por los requisitos de datos en esta área. También puede mejorar la privacidad de los datos, ya que los modelos de utilidad de capacitación requerirán menos información de las personas.
Sukholutsky enfatiza que la investigación se encuentra en una etapa inicial. Sin embargo, ya excita la imaginación. Siempre que un autor comienza a presentar su artículo a otros investigadores, su primera reacción es argumentar que la idea está más allá del ámbito de lo posible. Cuando de repente se dan cuenta de que están equivocados, se abre un mundo completamente nuevo.

