¿Cómo sabemos que funciona el algoritmo?
Antes de desarrollar un algoritmo, debe pensar en cómo evaluaremos su rendimiento. Digamos que escribimos un algoritmo y dice que "esta imagen tiene los siguientes colores". ¿Será correcta su decisión? ¿Y qué significa eso - "correcto"?
Para resolver este problema, hemos elegido dos dimensiones importantes: el marcado correcto del color primario y el número correcto de colores. Establecemos esto como la distancia CIEDE 2000 ( fórmula de diferencia de color ) entre el color de primer plano predicho por nuestro algoritmo y nuestro color de primer plano real, y también calculamos el error absoluto promedio en el número de colores. Hicimos esta elección por las siguientes razones:
- Estos parámetros son fáciles de calcular.
- A medida que aumentaba el número de métricas, sería más difícil elegir el "mejor" algoritmo.
- Al reducir la cantidad de métricas, es posible que nos falte una diferencia importante entre los dos algoritmos.
- En cualquier caso, la mayoría de las prendas tienen uno o dos colores primarios y muchos de nuestros procesos se basan en un color primario. Por lo tanto, calcular correctamente el color base es mucho más importante que calcular correctamente el segundo o tercer color.
¿Qué pasa con los datos "reales"? Nuestro equipo de comerciantes nos ha proporcionado etiquetas, pero nuestras herramientas les permiten elegir solo los colores más comunes, como "gris" o "azul"; no se pueden llamar valor exacto. Estas definiciones generales incluyen bastantes tonos diferentes, por lo que no se pueden utilizar como colores reales. Tendremos que construir nuestro propio conjunto de datos.
Es posible que algunos de ustedes ya estén pensando en servicios como Mechanical Turk. Pero no necesitamos marcar demasiadas imágenes, por lo que describir esta tarea puede ser incluso más difícil que simplemente completarla. Además, la creación de un conjunto de datos le ayuda a comprenderlo mejor. Rápidamente estropeamos una aplicación HTML / Javascript y seleccionamos al azar 1000 imágenes, seleccionadas para cada píxel que representa su color primario, y marcamos la cantidad de colores que vimos en la imagen. Después de eso, fue fácil obtener dos números para evaluar la calidad de nuestro algoritmo (distancia al color principal CIEDE y el número de colores MAE).
A veces verificamos los programas manualmente, ejecutando ambos algoritmos en una imagen y mostrando dos listas de colores. Luego, clasificamos manualmente 200 imágenes, eligiendo qué colores se reconocieron como "mejores". Es muy importante trabajar en estrecha colaboración con los datos de esta manera, no solo para obtener el resultado ("el algoritmo B funcionó mejor que el algoritmo A en el 70% de los casos"), sino también para comprender qué sucede en cada uno de los casos ("el algoritmo B generalmente selecciona demasiados grupos, pero El algoritmo A pierde colores claros ”).

Suéter y colores seleccionados por dos algoritmos diferentes.
Nuestro algoritmo de extracción de color
Antes de procesar las imágenes, las convertimos al espacio de color CIELAB (o simplemente LAB) en lugar del RGB más común. Como resultado, nuestros tres números no representarán la cantidad de rojo, verde y azul. Los puntos del espacio LAB (L * a * b * sería más correcto, pero escribiremos LAB para simplificar) denotan tres ejes diferentes. L denota brillo de negro 0 a blanco 100. A y B denotan color: A denota una ubicación en el rango de -128 verde a 127 rojo y B de -128 azul a 127 amarillo La principal ventaja de este espacio es la uniformidad percibida. La distancia o diferencia entre dos puntos en el espacio LAB se percibirá igual, independientemente de su ubicación, si la distancia euclidiana entre ellos en el espacio también es la misma.
Naturalmente, el LAB tiene otros problemas: por ejemplo, consideramos imágenes en pantallas de computadora que usan espacio RGB específico del dispositivo. Además, la gama LAB es más amplia que la de RGB, es decir, en LAB puede expresar colores que no se pueden expresar a través de RGB. Por lo tanto, la conversión de LAB a RGB no puede ser de dos caras: al convertir un punto en una dirección y luego en la dirección opuesta, puede obtener un valor diferente. Teóricamente, estas deficiencias están presentes, pero en la práctica el método aún funciona.
Al convertir la imagen a LAB, obtendremos un conjunto de píxeles que se pueden visualizar como puntos (L, A, B, X, Y). El resto del algoritmo se ocupa de agrupar estos puntos, en los que los grupos de la primera etapa utilizan las cinco mediciones y la segunda etapa omite las mediciones X e Y.
Agrupación en el espacio
Comenzamos con una imagen sin agrupación de píxeles que ha sufrido los ajustes de color descritos en el artículo anterior , comprimida a 320x200 y convertida a LAB.

Primero, apliquemos el algoritmo Quickshift, que agrupa los píxeles cercanos en "superpíxeles".

Esto ya reduce nuestra imagen de 60.000 píxeles a unos cientos de superpíxeles, eliminando una complejidad innecesaria. Puede simplificar aún más la situación fusionando superpíxeles cercanos con una pequeña distancia de color entre ellos. Para hacer esto, dibujamos su gráfico de proximidad regional, un gráfico en el que los nodos que denotan dos superpíxeles diferentes están conectados por un borde si sus píxeles se tocan.

– (Regional Adjacency Graph, RAG) . , , , , . , , , , . – , .
Los nodos del gráfico son los superpíxeles que calculamos y los bordes son la distancia entre ellos en el espacio de color. El borde que conecta dos superpíxeles cercanos con colores similares tendrá un peso bajo (líneas oscuras) y el borde entre superpíxeles con colores muy diferentes tendrá un peso alto (líneas brillantes, así como la ausencia de líneas; no se dibujaron si su peso era superior a 20). Hay muchas formas de combinar superpíxeles cercanos, pero un simple umbral de 10 fue suficiente para nosotros.
En nuestro caso, logramos reducir 60.000 píxeles a 100 áreas, cada una de las cuales contiene píxeles del mismo color. Esto brinda ventajas computacionales: primero, sabemos que un gran superpíxel de color casi blanco es el fondo y se puede eliminar. Eliminamos todos los superpíxeles con L> 99, y A y B en el rango de -0,5 a 0,5. En segundo lugar, podemos reducir considerablemente el número de píxeles en el siguiente paso. No podremos reducir su número a 100, ya que necesitamos pesar las áreas en función del número de píxeles que contienen. Pero podemos eliminar fácilmente el 90% de los píxeles de cada grupo sin perder demasiados detalles y casi sin distorsión de la siguiente agrupación.
Agrupar sin ocupar espacio
En este paso, tenemos varios miles de píxeles con coordenadas (L, A, B). Hay muchas técnicas que pueden agrupar estos píxeles de forma agradable. Elegimos el método k-medias porque es rápido, fácil de entender, nuestros datos solo tienen 3 dimensiones y la distancia euclidiana en el espacio LAB tiene sentido.
No éramos demasiado inteligentes y teníamos una agrupación con K = 8. Si algún grupo contiene menos del 3% de puntos, lo intentamos de nuevo, esta vez con K = 7, luego 6, y así sucesivamente. Como resultado, tenemos una lista de 1 a 8 centros de agrupación y una fracción del número de puntos pertenecientes a cada uno de los centros. Son nombrados por el algoritmo colornamer descrito en el artículo anterior.
Resultados y problemas restantes
Logramos una distancia promedio de 5.86 en la escala CIEDE 2000 entre el color predicho y el "real". Es bastante difícil interpretar correctamente este indicador. En la métrica de distancia simple CIE76, nuestra distancia promedio es 7.82. En esta métrica, un valor de 2,3 representa una diferencia sutil. Por tanto, podemos decir que nuestros resultados, algo más de 3, indican una sutil diferencia.
También nuestro MAE fue de 2,28 colores. Pero nuevamente, esta es una métrica secundaria. Muchos algoritmos que se describen a continuación reducen este error, pero a costa de aumentar la distancia de color. Es mucho más fácil ignorar los colores falsos del quinto o sexto lugar que ignorar el primer color incorrecto.

Incluso las cosas que son claramente del mismo color, como estos pantalones cortos, contienen áreas que parecen mucho más oscuras debido
a las sombras El problema de las sombras persiste. La tela no se puede colocar perfectamente de manera uniforme, por lo que parte de la imagen siempre permanecerá en la sombra y parecerá un color engañosamente diferente. Los enfoques más simples, como encontrar colores duplicados del mismo tono y brillo diferente, no funcionan, ya que la transición de “píxel sin sombra” a “píxel en sombra” no siempre funciona de la misma manera. En el futuro, esperamos utilizar técnicas más sofisticadas como DeshadowNet o el reconocimiento automático de sombras .

Solo nos concentramos en el color de la ropa. Las joyas y los zapatos tienen sus propios problemas: nuestras fotografías de joyas son demasiado pequeñas, y las fotografías de zapatos a menudo muestran su interior. En el ejemplo de arriba, indicaríamos la presencia de burdeos y ocre en la foto, aunque solo el primero de ellos es importante.
Que mas hemos probado
Este último algoritmo parece bastante simple, ¡pero no fue fácil de idear! En esta sección, describiré las opciones que hemos probado y de las que hemos aprendido.
Eliminación de antecedentes
Hemos probado algoritmos de eliminación de fondo, por ejemplo, el algoritmo de Lyst . La evaluación informal mostró que no funcionaron con tanta precisión como la simple eliminación del fondo blanco. Sin embargo, planeamos estudiarlo más a fondo a medida que procesamos imágenes en las que nuestro estudio fotográfico no funcionó.
Hash de píxeles
Algunas bibliotecas de extracción de color han optado por una solución simple a este problema: agrupar píxeles dividiéndolos en varios contenedores suficientemente anchos y luego devolver los valores promedio de los contenedores LAB con la mayor cantidad de píxeles. Probamos la biblioteca Colorgram.py; a pesar de su simplicidad, funciona sorprendentemente bien. Además, funciona rápidamente, no más de un segundo por imagen, mientras que nuestro algoritmo gasta decenas de segundos por imagen. Sin embargo, Colorgram.py tenía una distancia promedio al color base mayor que nuestro algoritmo, principalmente porque su resultado se toma de las distancias promedio a contenedores grandes. Sin embargo, a veces lo usamos para casos en los que la velocidad es más importante que la precisión.
Otro algoritmo de división de superpíxeles
Usamos el algoritmo Quickshift para segmentar la imagen en superpíxeles, pero hay varios algoritmos posibles, por ejemplo, SLIC, Watershed y Felzenszwalb. En la práctica, Quickshift ha mostrado los mejores resultados gracias a su trabajo con piezas pequeñas. Por ejemplo, SLIC tiene un problema con cosas como rayas que ocupan mucho espacio en la imagen. Estos son los resultados indicativos del algoritmo SLIC con diferentes configuraciones:

Imagen original

compacidad = 1

compacidad = 10

compacidad = 100
Para trabajar con nuestros datos, Quickshift tiene una ventaja teórica: no requiere una comunicación continua de superpíxeles. Los investigadores notaron que esto puede causar problemas para los algoritmos, pero en nuestro caso esto es una ventaja: a menudo nos encontramos con áreas pequeñas con pequeños detalles que queremos llevar a un grupo.

Camisa a

cuadros Su agrupación de superpíxeles por Quickshift
Si bien la agrupación de superpíxeles de Quickshift parece caótica, en realidad agrupa todas las rayas rojas con otras rojas, azules con azules, etc.
Diferentes métodos de contar el número de grupos.
Cuando se usa el método de k-medias, surge la pregunta más común: ¿cómo hacer "k"? Es decir, si necesitamos agrupar puntos en un cierto número de grupos, ¿cuántos debemos hacer? Se han desarrollado varios enfoques para responder a la pregunta. El más simple es el "método codo", pero requiere un procesamiento manual del gráfico y necesitamos una solución automática. Gap Statistic formaliza este método, y con él obtuvimos los mejores resultados en la métrica "número de colores", pero a expensas de la precisión del color base. Dado que el color principal es el más importante, no lo usamos en el programa de trabajo, pero planeamos estudiar este tema más a fondo.
Finalmente, el método de la silueta es otro método de selección k popular. Da resultados ligeramente peores que nuestro algoritmo, y tiene un serio inconveniente: necesita al menos 2 grupos. Pero muchas prendas solo tienen un color.
DBSCAN
Una posible solución a la cuestión de elegir k es utilizar un algoritmo que no requiera que elija este parámetro. Un ejemplo popular es DBSCAN, que busca datos para grupos de densidad aproximadamente igual.

Blusa multicolor
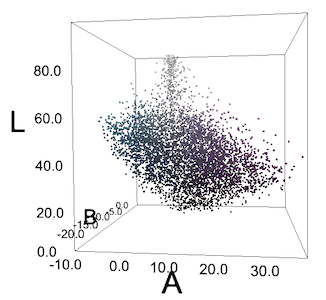
Todos los píxeles de su imagen están en el espacio LAB. Los píxeles no forman grupos cian y violeta claros.
A menudo no obtenemos tales grupos, o vemos algo así como grupos solo debido a las peculiaridades de la percepción humana. Para nosotros, los "pepinos" azul verdosos de la blusa se destacan sobre el fondo morado, pero si trazamos todos los píxeles en coordenadas RGB o LAB, no formarán grupos. Pero probamos DBSCAN de todos modos con diferentes valores de épsilon y obtuvimos resultados predeciblemente pobres.
Solución de Algolia
Uno de los buenos principios de los investigadores es ver si alguien ya ha resuelto tu problema. Leo Ercolanelli del sitio web Algolia publicó una descripción detallada de la solución a este problema hace más de tres años. Gracias a su generosidad en la distribución de fuentes, pudimos probar su solución nosotros mismos. Sin embargo, los resultados fueron ligeramente peores que los nuestros, así que dejamos nuestro algoritmo. No resuelven el mismo problema que nosotros: tenían imágenes de producto en modelos y sobre un fondo que no era el blanco, por lo que tiene sentido que sus resultados difieran de los nuestros.
Coordinación de colores
Este algoritmo completa el proceso descrito en nuestro artículo anterior. Después de extraer los centros de grupo, usamos Colornamer para nombrarlos y luego importamos esos colores a nuestras herramientas internas. Esto nos ayuda a visualizar fácilmente nuestros productos por color; esperamos incorporar estos datos en los algoritmos de recomendación de compra. Este proceso no es perfecto, nos ayuda a obtener los mejores datos sobre nuestros miles de productos, lo que a su vez contribuye a nuestro objetivo principal de ayudar a las personas a encontrar los estilos que les encantan.
Entrevista sobre la traducción de la primera parte