Puede confiar en su opinión, formada a partir de diferentes fuentes de información, por ejemplo, publicaciones en sitios o experiencia. Puede preguntar a colegas y conocidos. Otra opción es mirar los temas de la conferencia: el comité del programa son representantes activos de la industria, por lo que confiamos en ellos para elegir los temas relevantes. Un área separada es la investigación y los informes. Pero hay un problema. La investigación sobre el estado de DevOps se lleva a cabo anualmente en el mundo, los informes son publicados por empresas extranjeras y casi no hay información sobre DevOps ruso.
Pero ha llegado el día en que se realizó tal estudio, y hoy le contaremos los resultados obtenidos. El estado de DevOps en Rusia fue investigado conjuntamente por Express 42 y Ontiko". Express 42 ayuda a las empresas de tecnología a implementar y desarrollar prácticas y herramientas de DevOps y fue una de las primeras en comenzar a hablar sobre DevOps en Rusia. Los autores del estudio, Igor Kurochkin y Vitaly Khabarov, se dedican al análisis y consultoría en Express 42, con antecedentes técnicos de operación y experiencia laboral en diferentes empresas. Durante 8 años, los colegas han analizado decenas de empresas y proyectos, desde nuevas empresas hasta empresas, con diferentes problemas, así como con diferente madurez cultural y de ingeniería.
En su informe, Igor y Vitaliy contaron qué problemas había en el proceso de investigación, cómo los resolvieron, así como también cómo se realiza la investigación de DevOps en principio y por qué Express 42 decidió realizar la suya propia. Su informe se puede ver aquí .

Investigación de DevOps
Igor Kurochkin inició la conversación.
Regularmente hacemos una pregunta a la audiencia en las conferencias de DevOps: "¿Ha leído el informe de estado de DevOps de este año?" Solo unos pocos levantan la mano, y nuestro estudio mostró que solo un tercio los estudia. Si nunca ha visto informes de este tipo, digamos de inmediato que todos son muy similares. La mayoría de las veces hay frases como: "Comparado con el año pasado ..."
Aquí tenemos el primer problema, y después dos más:
- No tenemos datos del año pasado. El estado de DevOps en Rusia no interesa a nadie;
- Metodología. No está claro cómo probar hipótesis, cómo construir preguntas, cómo realizar análisis, comparar resultados, encontrar conexiones;
- Terminología. Todos los informes están en inglés, se requiere traducción, aún no se ha inventado un marco DevOps común y todos crean el suyo.
Echemos un vistazo a cómo se realizaron en general los análisis del estado de DevOps en todo el mundo.
Referencia histórica
La investigación de DevOps se ha realizado desde 2011. El primero fue realizado por Puppet, un desarrollador de sistemas de administración de configuración. En ese momento, era una de las principales herramientas para describir la infraestructura en forma de código. Hasta 2013, estos estudios se realizaban simplemente en forma de encuestas cerradas y sin informes públicos.
En 2013, nació IT Revolution, el editor de los principales libros de DevOps. Junto con Puppet, prepararon la primera publicación "State of DevOps", donde aparecieron por primera vez 4 métricas clave. Al año siguiente, ThoughtWorks, una empresa de consultoría conocida por sus radares tecnológicos habituales sobre prácticas y herramientas de la industria, se unió. Y en 2015, se agregó una sección de metodología, y quedó claro cómo realizan el análisis.
En 2016, los autores del estudio, después de crear su empresa DORA (DevOps Research and Assessment), publicaron un informe anual. Al año siguiente, DORA y Puppet publicaron un informe conjunto por última vez.
Y entonces empezó lo interesante:

En 2018, las empresas se separaron y se publicaron dos informes independientes: uno de Puppet, el segundo de DORA en conjunto con Google. DORA ha continuado utilizando su metodología con métricas clave, perfiles de desempeño y prácticas de ingeniería que impactan las métricas clave y el desempeño de toda la empresa. Y Puppet ofreció su propio enfoque que describe el proceso y la evolución de DevOps. Pero la historia no se puso de moda, en 2019 Puppet abandonó esta metodología y lanzó una nueva versión de los informes, en la que enumeraba las prácticas clave y cómo afectan a DevOps desde su punto de vista. Luego sucedió otra cosa: Google compró DORA y juntos publicaron otro informe. Puede que lo hayas visto.
Las cosas se complicaron este año. Se sabe que Puppet ha lanzado su propia encuesta. Lo hicieron una semana antes que nosotros y ya terminó. Participamos y vimos qué temas les interesan. Puppet está realizando su análisis y preparándose para publicar el informe.
Pero todavía no hay ningún anuncio de DORA y Google. En mayo, cuando solía comenzar la encuesta, llegó la información de que Nicole Forsgren, una de las fundadoras de DORA, se había mudado a otra empresa. Por lo tanto, asumimos que no habrá investigación ni informe de DORA este año.
¿Cómo van las cosas en Rusia?
No hemos realizado ninguna investigación de DevOps. Hablamos en conferencias, volviendo a contar las conclusiones de otras personas y Raiffeisenbank tradujo "State of DevOps" para 2019 (puede encontrar su anuncio en Habré), muchas gracias a ellos. Y es todo.
Por lo tanto, realizamos nuestra propia investigación en Rusia utilizando metodologías y hallazgos de DORA. Usamos el informe de colegas de Raiffeisenbank para nuestra investigación, incluso para la sincronización de terminología y traducción. Y las preguntas específicas de la industria provienen de los informes DORA de este año y la encuesta Puppet.
Proceso de investigación
El informe es solo la parte final. Todo el proceso de investigación consta de cuatro grandes pasos:
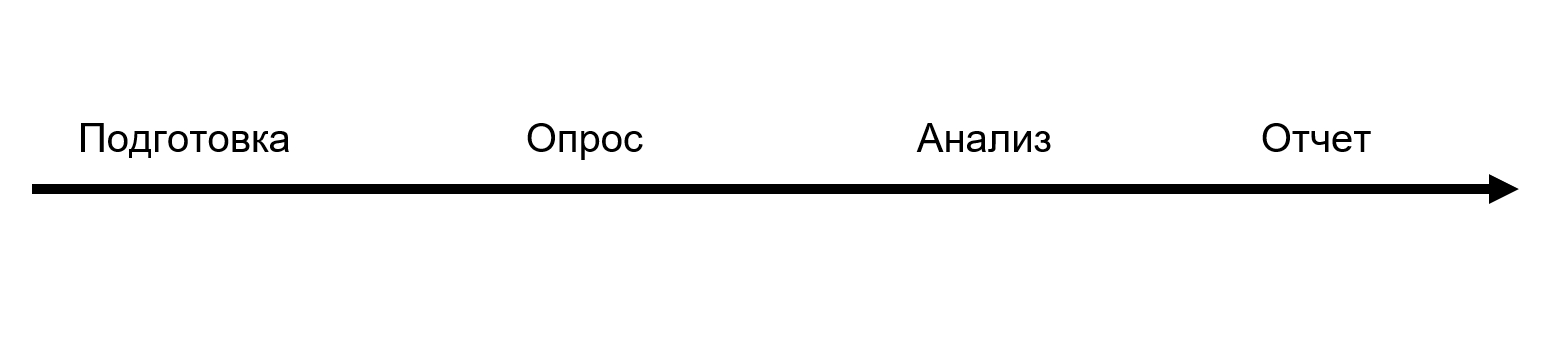
Durante la fase de preparación, entrevistamos a expertos de la industria y preparamos una lista de hipótesis. Sobre esta base, se elaboraron preguntas y se lanzó una encuesta para todo el mes de agosto. Luego analizamos y preparamos el informe en sí. Para DORA, este proceso lleva 6 meses. Nos reunimos 3 meses, y ahora entendemos que apenas tuvimos tiempo suficiente: solo realizando el análisis se comprende qué preguntas hay que plantear.
Participantes
Todos los informes extranjeros comienzan con un retrato de los participantes, y la mayoría de ellos no son de Rusia. El porcentaje de encuestados rusos fluctúa del 5 al 1% de un año a otro, y esto no permite sacar ninguna conclusión.
Mapa del informe Accelerate State of DevOps 2019:

En nuestro estudio, logramos entrevistar a 889 personas; esto es bastante (DORA encuesta a unas mil personas en sus informes anualmente) y aquí logramos el objetivo:
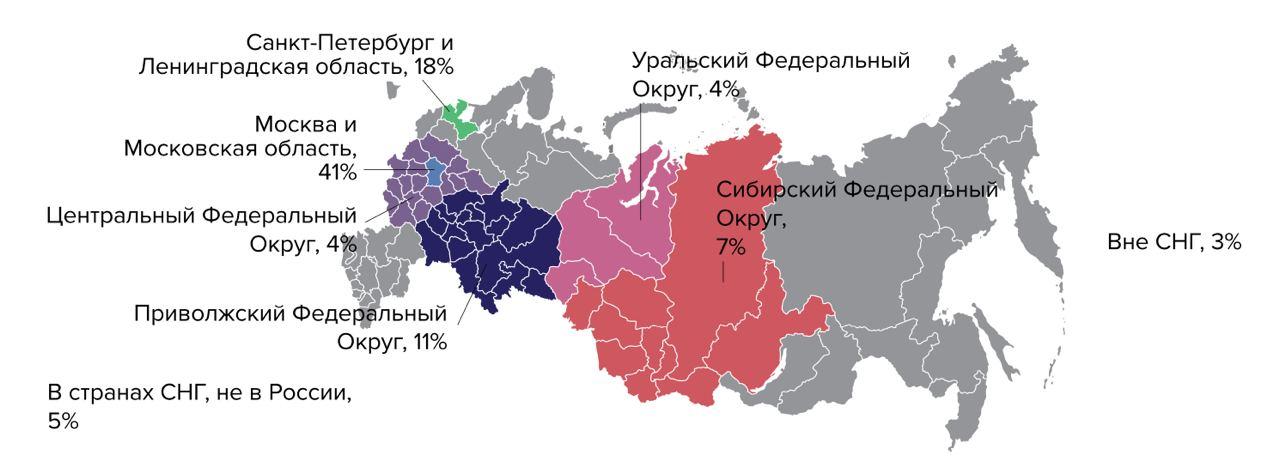
Es cierto, no todos nuestros participantes llegaron al final: porcentaje el relleno resultó ser un poco menos de la mitad. Pero incluso esto fue suficiente para obtener una muestra representativa y realizar un análisis. DORA no revela el porcentaje de llenado en sus informes, por lo que no se puede comparar aquí.
Industrias y posiciones
Nuestros encuestados representan una docena de industrias. La mitad de ellos trabaja en tecnología de la información. Le siguen los servicios financieros, el comercio, las telecomunicaciones y otros. Entre los puestos se encuentran especialistas (desarrollador, tester, ingeniero de operaciones) y personal de gestión (jefes de equipo, equipos, direcciones, directores):

Cada segundo trabaja en una empresa mediana. Una de cada tres personas trabaja en grandes empresas. La mayoría trabaja en equipos de hasta 9 personas. Por separado, preguntamos por las principales actividades, y la mayoría están de una forma u otra relacionadas con la operación, y alrededor del 40% están comprometidas con el desarrollo:

así recolectamos información para comparar y analizar representantes de diferentes industrias, empresas, equipos. Mi colega Vitaly Khabarov le informará sobre el análisis.
Análisis y comparación
Vitaly Khabarov: Muchas gracias a todos los participantes que completaron nuestra encuesta, completaron los cuestionarios y nos brindaron datos para un mayor análisis y prueba de nuestras hipótesis. Y gracias a nuestros clientes y clientes, tenemos una gran experiencia que ayudó a identificar los problemas que preocupan a la industria y formular las hipótesis que probamos en nuestra investigación.
Desafortunadamente, no se puede simplemente tomar una lista de preguntas por un lado y datos por otro, compararlas de alguna manera, decir: “Sí, así es como funciona, teníamos razón” y dispersarse. No, necesitamos metodología y métodos estadísticos para estar seguros de que no nos equivocamos y nuestras conclusiones son fiables. Entonces podemos construir nuestro trabajo adicional sobre la base de estos datos:

Llaves metricas
Tomamos como base la metodología DORA, que describieron en detalle en el libro "Accelerate State of DevOps". Verificamos si las métricas clave son adecuadas para el mercado ruso, ¿se pueden usar de la misma manera que DORA usa para responder la pregunta: "¿Cómo se corresponde la industria en Rusia con la industria extranjera?"
Llaves metricas:
- Frecuencia de implementación. ¿Con qué frecuencia se implementa una nueva versión de una aplicación en el entorno de producción (cambios planificados, excluidas las correcciones urgentes y la respuesta a incidentes)?
- El tiempo de entrega. ¿Cuál es el tiempo medio entre la realización de un cambio (escribir la funcionalidad como código) y la implementación del cambio en el entorno del producto?
- . , , ?
- . ( , )?
DORA ha encontrado una relación entre estas métricas y el desempeño organizacional en su investigación. También lo comprobamos en nuestra investigación.
Pero para asegurarse de que las cuatro métricas clave puedan influir en algo, debe comprender: ¿están relacionadas de alguna manera entre sí? DORA respondió afirmativamente con una salvedad: la relación entre la tasa de fallos de cambio y las otras tres métricas es ligeramente más débil. Tenemos aproximadamente la misma imagen. Si el tiempo de entrega, la frecuencia de implementación y el tiempo de recuperación se correlacionan entre sí (encontramos esta correlación a través de la correlación de Pearson y a través de la escala de Chaddock), entonces no existe una correlación tan fuerte con los cambios fallidos.
En principio, la mayoría de los encuestados tienden a responder que tienen un número bastante pequeño de incidentes que ocurren en la producción. Aunque en el futuro veremos que aún existe una diferencia significativa entre los grupos de encuestados en términos de la tasa de cambios fallidos, para esta división aún no podemos utilizar esta métrica.
Atribuimos esto al hecho de que (como resultó durante el análisis y la comunicación con algunos de nuestros clientes) existe una ligera diferencia en la percepción de lo que se considera un incidente. Si logramos restaurar el rendimiento de nuestro servicio durante la ventana técnica, ¿puede esto considerarse un incidente? Probablemente no, porque arreglamos todo, somos geniales. ¿Se puede considerar un incidente si tuviéramos que volver a implementar nuestra aplicación 10 veces en un modo normal, habitual para nosotros? Parece que no. Por tanto, la cuestión de la relación de los cambios fallidos con otras métricas permanece abierta. Lo refinaremos aún más.
Aquí es importante que encontremos una correlación significativa entre los tiempos de entrega, los tiempos de recuperación y la frecuencia de implementación. Por lo tanto, tomamos estas tres métricas para dividir aún más a los encuestados en grupos de desempeño.
¿Cuánto pesar en gramos?
Usamos análisis de conglomerados jerárquicos:
- Distribuimos a los encuestados en un espacio n-dimensional, donde la coordenada de cada encuestado son sus respuestas a las preguntas.
- Declaramos a cada encuestado como un pequeño grupo.
- Combinamos los dos grupos más cercanos entre sí en un grupo más grande.
- Busque el siguiente par de grupos y combínelos en un grupo más grande.
Así es como agrupamos a todos nuestros encuestados en el número requerido de grupos. Con la ayuda de un dendrograma (un árbol de conexiones entre grupos) vemos la distancia entre dos grupos vecinos. Todo lo que nos queda es establecer un cierto límite de distancia entre estos grupos y decir: "Estos dos grupos son bastante distinguibles entre sí porque la distancia entre ellos es enorme".
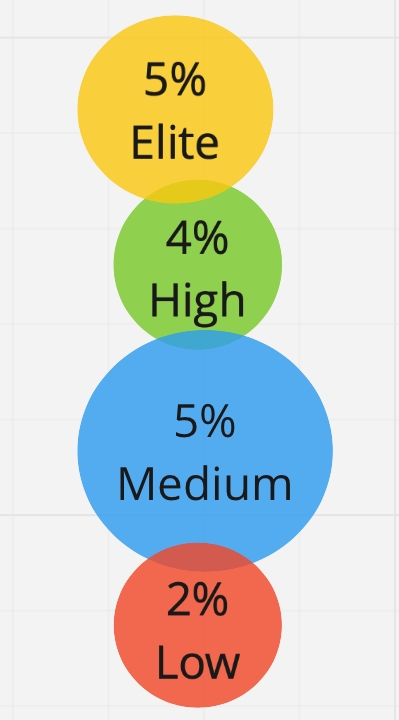
Pero hay un problema oculto aquí: no tenemos restricciones en la cantidad de grupos; podemos obtener 2, 3, 4, 10 grupos. Y la primera idea fue: ¿por qué no dividir a todos nuestros encuestados en 4 grupos, como hace DORA? Pero descubrimos que las diferencias entre estos grupos se vuelven insignificantes y no podemos estar seguros de que el encuestado realmente pertenezca a su propio grupo y no al vecino. Todavía no podemos dividir el mercado ruso en cuatro grupos. Por lo tanto, nos detuvimos exactamente en tres perfiles, entre los cuales hay una diferencia estadísticamente significativa:

A continuación, determinamos el perfil por conglomerados: tomamos las medianas de cada métrica para cada grupo y elaboramos una tabla de perfiles de desempeño. De hecho, obtuvimos los perfiles de desempeño del participante promedio en cada grupo. Hemos identificado tres perfiles de eficiencia: Baja, Media, Alta:

Aquí hemos confirmado nuestra hipótesis de que las 4 métricas clave son adecuadas para determinar el perfil de rendimiento y funcionan tanto en el mercado occidental como en el ruso. Hay una diferencia entre los grupos y es estadísticamente significativa. Me gustaría enfatizar que existe una diferencia significativa en el promedio entre los perfiles de desempeño según la métrica de cambios no exitosos, aunque inicialmente no dividimos a los encuestados por este parámetro.
Entonces surge la pregunta: ¿cómo usar todo esto?
Cómo utilizar
Si toma cualquier equipo, 4 métricas clave y lo aplica a la tabla, entonces en el 85% de los casos no obtendremos una coincidencia completa; esto es solo un participante promedio, y no lo que es en realidad. Todos (y cada equipo) somos un poco diferentes.
Verificamos: tomamos a nuestros encuestados y el perfil de desempeño de DORA, y observamos cuántos encuestados encajan en un perfil en particular. Descubrimos que solo el 16% de los encuestados accedió con precisión a uno de los perfiles. Todos los demás están dispersos en algún punto intermedio:
Esto significa que el perfil de rendimiento tiene un alcance limitado. Para entender dónde se encuentra en una primera aproximación, puede usar esta tabla: "¡Oh, parece que estamos más cerca de Medio o Alto!" Si sabe adónde ir a continuación, esto puede ser suficiente. Pero si su objetivo es la mejora constante y continua, y desea saber con mayor precisión dónde desarrollar y qué hacer, entonces necesita fondos adicionales. Las llamamos calculadoras:
- Calculadora DORA
- Calculator Express 42 * (en desarrollo)
- Desarrollo propio (puedes crear tu propia calculadora interna).
¿Para qué se necesitan? Comprender:
- ¿El equipo de nuestra organización cumple con nuestros estándares?
- Si no es así, ¿podemos ayudarla, acelerarla dentro del marco de la experiencia que tiene nuestra empresa?
- Si es así, ¿podemos hacerlo aún mejor?
También puede utilizarlos para recopilar estadísticas dentro de la empresa:
- Qué equipos tenemos;
- Divida los equipos en perfiles;
- Ver: Oh, estos equipos tienen un rendimiento inferior (no tiran un poco), y son geniales: se implementan todos los días, sin errores, tienen menos de una hora de tiempo de espera.
Y luego puede descubrir que dentro de nuestra empresa existe la experiencia y las herramientas necesarias para aquellos equipos que aún no resisten.
O, si comprende que dentro de la empresa se siente muy bien, es mejor que muchos, entonces puede echar un vistazo más amplio. Esta es exactamente la industria rusa: ¿podemos obtener la experiencia necesaria en la industria rusa para acelerarnos? Calculator Express 42 ayudará aquí (está en desarrollo). Si ha superado el mercado ruso, mire la calculadora DORA y el mercado global.
Bueno. Y si estás en el grupo Elit de la calculadora DORA, ¿qué hacer? Aquí no hay una buena solución. Lo más probable es que esté a la vanguardia de la industria, y es posible una mayor aceleración y mejora de la confiabilidad debido a la I + D interna y al gasto de más recursos.
Pasemos a la comparación más dulce.
Comparación
Inicialmente queríamos comparar la industria rusa con la industria occidental. Si comparamos directamente, vemos que tenemos menos perfiles, y están un poco más mezclados entre sí, los límites son un poco más borrosos:

nuestros Elite Performers están ocultos entre los High Performers, pero existen: son la élite, unicornios que han alcanzado alturas significativas. En Rusia, la diferencia entre el perfil Elite y el perfil alto aún no es lo suficientemente significativa. Creemos que en el futuro esta separación se producirá en relación con la mejora de la cultura de la ingeniería, la calidad de la implementación de las prácticas de ingeniería y la experiencia dentro de las empresas.
Pasando a una comparación directa dentro de la industria rusa, vemos que los equipos de alto perfil son mejores en todos los aspectos. También confirmamos nuestra hipótesis de que existe una relación entre estas métricas y el desempeño organizacional: los equipos de alto perfil tienen muchas más probabilidades de no solo alcanzar metas, sino también superarlas.
Convirtámonos en equipos de alto perfil y no nos detengamos ahí:
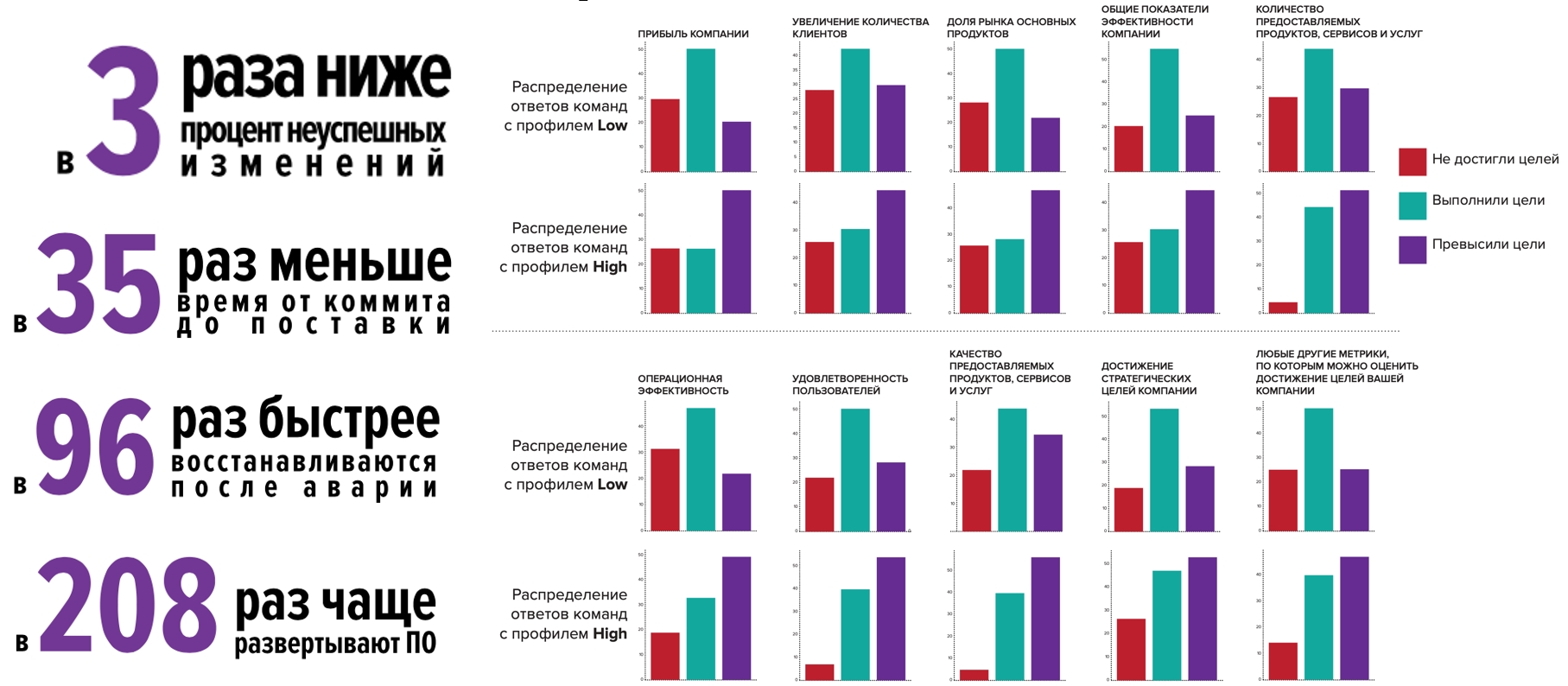
pero este año es especial, y decidimos comprobar cómo viven las empresas en una pandemia: los equipos de alto perfil lo hacen mucho mejor y se sienten mejor que el promedio de la industria:
- Los nuevos productos se lanzaron 1,5-2 veces más a menudo
- Dos veces más probabilidades de mejorar la confiabilidad y / o el rendimiento de la infraestructura de la aplicación.
Es decir, las competencias que ya tenían les ayudaron a desarrollarse más rápido, introducir nuevos productos, modificar productos existentes, conquistando así nuevos mercados y nuevos usuarios:

¿Qué más ayudó a nuestros equipos?
Prácticas de ingeniería

Le contaré los hallazgos importantes de cada práctica que verificamos. Quizás algo más ayudó a los equipos, pero estamos hablando de DevOps. Y dentro de DevOps, vemos una diferencia entre equipos de diferentes perfiles.
Plataforma como servicio
No encontramos una conexión significativa entre la edad de la plataforma y el perfil del equipo: las plataformas aparecieron casi al mismo tiempo tanto para los equipos bajos como para los equipos altos. Pero para este último, la plataforma proporciona, en promedio, más servicios y más interfaces de programación para el control a través del código del programa. Y es más probable que los equipos de la plataforma ayuden a sus desarrolladores y equipos a usar la plataforma, más a menudo para resolver los problemas e incidentes relacionados con la plataforma y para educar a otros equipos.

Infraestructura como código
Todo es bastante estándar aquí. Encontramos una relación entre automatizar cómo funciona el código de infraestructura y cuánta información se almacena dentro del repositorio de infraestructura. Los comandos de alto perfil almacenan más información en los repositorios: esta es la configuración de la infraestructura, la canalización de CI / CD, la configuración del entorno y los parámetros de compilación. Almacenan esta información con más frecuencia, funcionan mejor con el código de infraestructura y han automatizado más procesos y tareas para trabajar con código de infraestructura.
Curiosamente, no vimos diferencias significativas en las pruebas de infraestructura. Asocio esto con el hecho de que los comandos de perfil alto generalmente tienen más automatización de pruebas. Quizás no deberían distraerse por separado con las pruebas de infraestructura, pero las pruebas que utilizan para comprobar las aplicaciones son suficientes, y gracias a ellas ya pueden ver qué y dónde se rompieron.
Integración y entrega
La sección más aburrida porque confirmamos que cuanta más automatización tengas, mejor trabajes con el código, más probabilidades tendrás de obtener las mejores métricas.
Arquitectura
Queríamos ver cómo afectan los microservicios al rendimiento. Si en verdad no es así, ya que el uso de microservicios no está asociado a un aumento de los indicadores de rendimiento. Los microservicios son utilizados tanto por los comandos de perfil alto como por los comandos de perfil bajo.
Pero lo importante es que para los equipos de alto nivel, la transición a una arquitectura de microservicio les permite desarrollar y desplegar sus servicios de forma independiente. Si la arquitectura permite a los desarrolladores actuar de forma autónoma, no esperar a alguien externo al equipo, entonces esta es una competencia clave para aumentar la velocidad. Aquí es donde los microservicios ayudan. Y su implementación no juega un papel importante.
¿Cómo encontramos todo esto?
Teníamos un plan ambicioso para replicar completamente la metodología DORA, pero carecíamos de recursos. Si DORA usa mucho patrocinio y la investigación les lleva medio año, hicimos nuestra investigación en poco tiempo. Queríamos construir un modelo DevOps como lo hace DORA y lo haremos en el futuro. Hasta ahora, nos hemos limitado a los mapas de calor: observamos

la distribución de las prácticas de ingeniería entre los equipos de cada perfil y descubrimos que los equipos del perfil alto, en promedio, utilizan las prácticas de ingeniería con más frecuencia. Puede leer más sobre todo esto en nuestro informe .
Para variar, cambiemos de estadísticas complejas a estadísticas simples.
¿Qué más hemos encontrado?
Herramientas
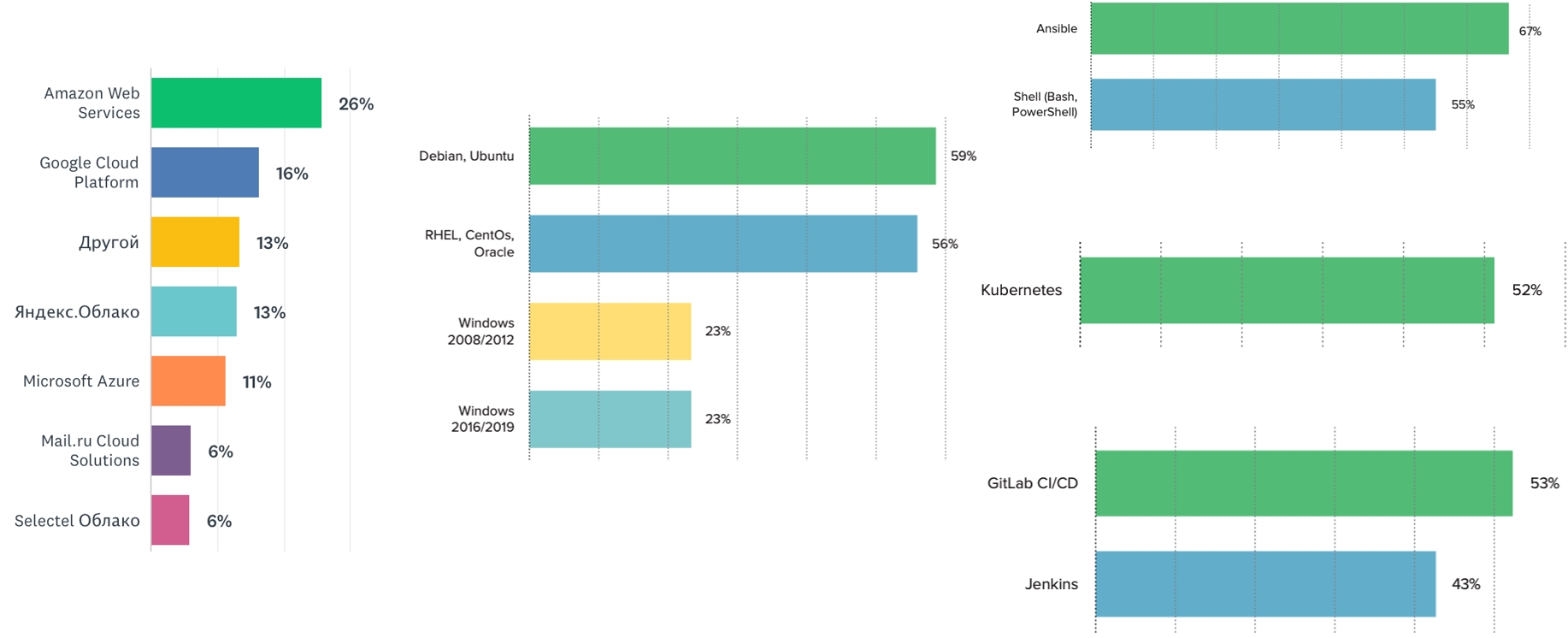
Observamos que la mayoría de los equipos utilizan el sistema operativo Linux. Pero Windows todavía está en tendencia: al menos una cuarta parte de nuestros encuestados notó el uso de una u otra versión. El mercado parece tener esta necesidad. Por lo tanto, puede desarrollar estas competencias y realizar presentaciones en conferencias.
Kubernetes es el líder entre los orquestadores (52%). El siguiente orquestador en línea es Docker Swarm (alrededor del 12%). Los sistemas de CI más populares son Jenkins y GitLab. El sistema de gestión de configuración más popular es Ansible, seguido de nuestro querido Shell.
Amazon sigue siendo el líder entre los servicios de alojamiento en la nube. La proporción de nubes rusas aumenta gradualmente. El año que viene, será interesante ver cómo se sienten los proveedores de la nube rusos y si su participación de mercado crece. Lo son, puedes usarlos, y está bien:
le doy la palabra a Igor, que dará algunas estadísticas más.
Difusión de prácticas
Igor Kurochkin: Por separado, pedimos a los encuestados que indicaran cómo se difunden las prácticas de ingeniería consideradas en la empresa. La mayoría de las empresas tienen un enfoque mixto con un conjunto diferente de patrones y los proyectos piloto son muy populares. También vimos una ligera diferencia entre los perfiles. Los representantes de alto perfil utilizan con más frecuencia el patrón de “Iniciativa desde abajo”, cuando pequeños equipos de especialistas cambian los procesos de trabajo, las herramientas y comparten desarrollos exitosos con otros equipos. En Medium, esta es una iniciativa de arriba hacia abajo que afecta a toda la empresa creando comunidades y centros de excelencia:

Agile y DevOps
La relación entre Agile y DevOps es un tema candente en la industria. Este problema también se plantea en el informe State of Agile para 2019/2020, por lo que decidimos comparar cómo se relacionan las actividades Agile y DevOps en las empresas. Descubrimos que las DevOps no ágiles son poco frecuentes. Para la mitad de los encuestados, la difusión de Agile comenzó mucho antes, y alrededor del 20% observó un inicio simultáneo, y uno de los signos de un perfil bajo será la ausencia de prácticas Agile y DevOps:

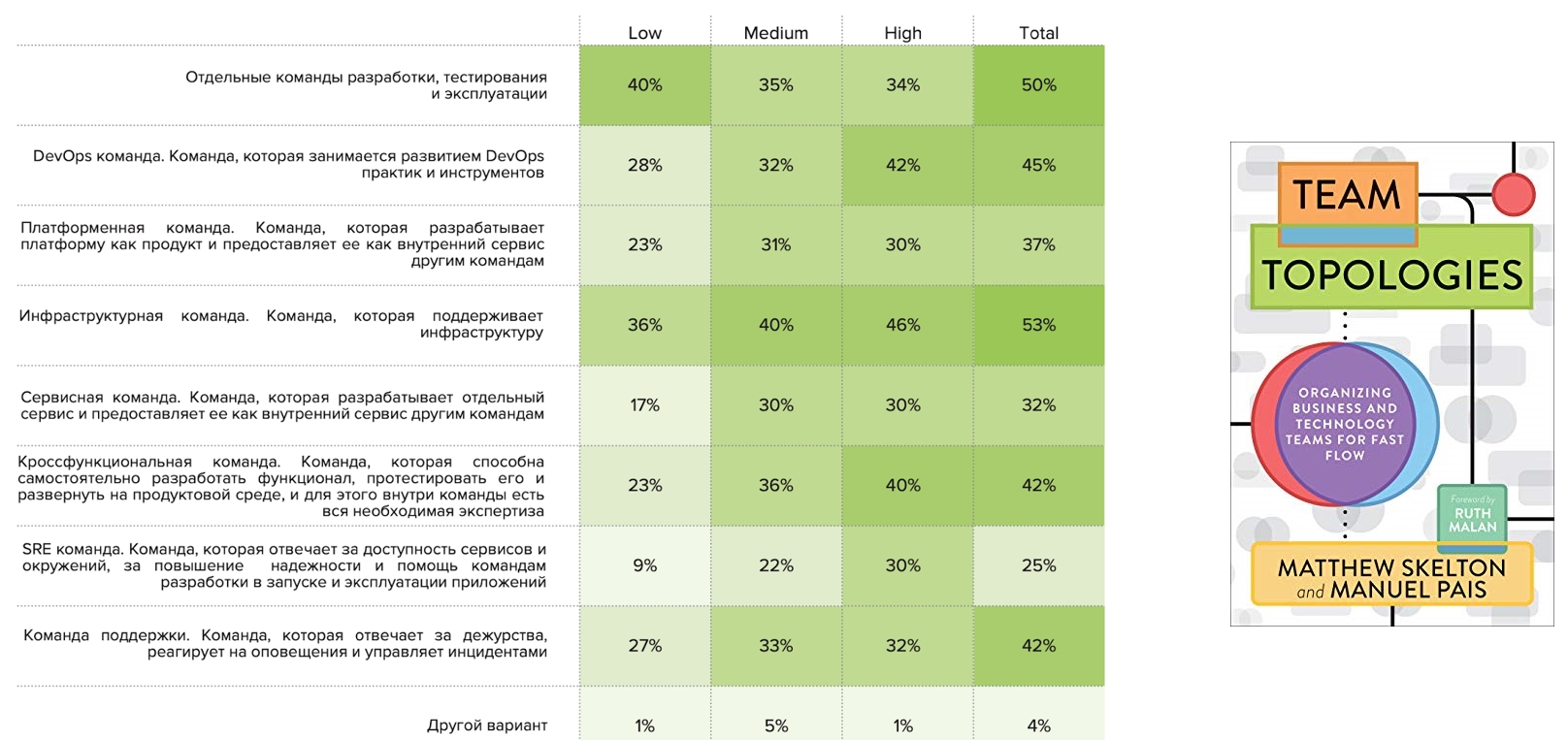
Topologías de comando
A finales del año pasado se publicó el libro " Topologías de equipo ", que proponía un marco para describir las topologías de equipo. Nos preguntamos si era aplicable a las empresas rusas. Y nos hicimos la pregunta: "¿Qué patrones encuentras?"
Los equipos de infraestructura son observados por la mitad de los encuestados, así como también por equipos separados de desarrollo, prueba y operación. Los equipos individuales de DevOps se notaron en un 45%, entre los cuales los representantes altos son más comunes. A esto le siguen los equipos multifuncionales, que también son más comunes para High. Los comandos SRE separados aparecen en los perfiles Alto, Medio y rara vez aparecen en el perfil Bajo:
Relación DevQaOps
Vimos esta pregunta en FaceBook del líder del equipo de la plataforma Skyeng: estaba interesado en la proporción de desarrolladores, probadores y administradores en las empresas. Lo preguntamos y miramos las respuestas en función de los perfiles: los representantes de High Profile tienen menos ingenieros de pruebas y operaciones por desarrollador:
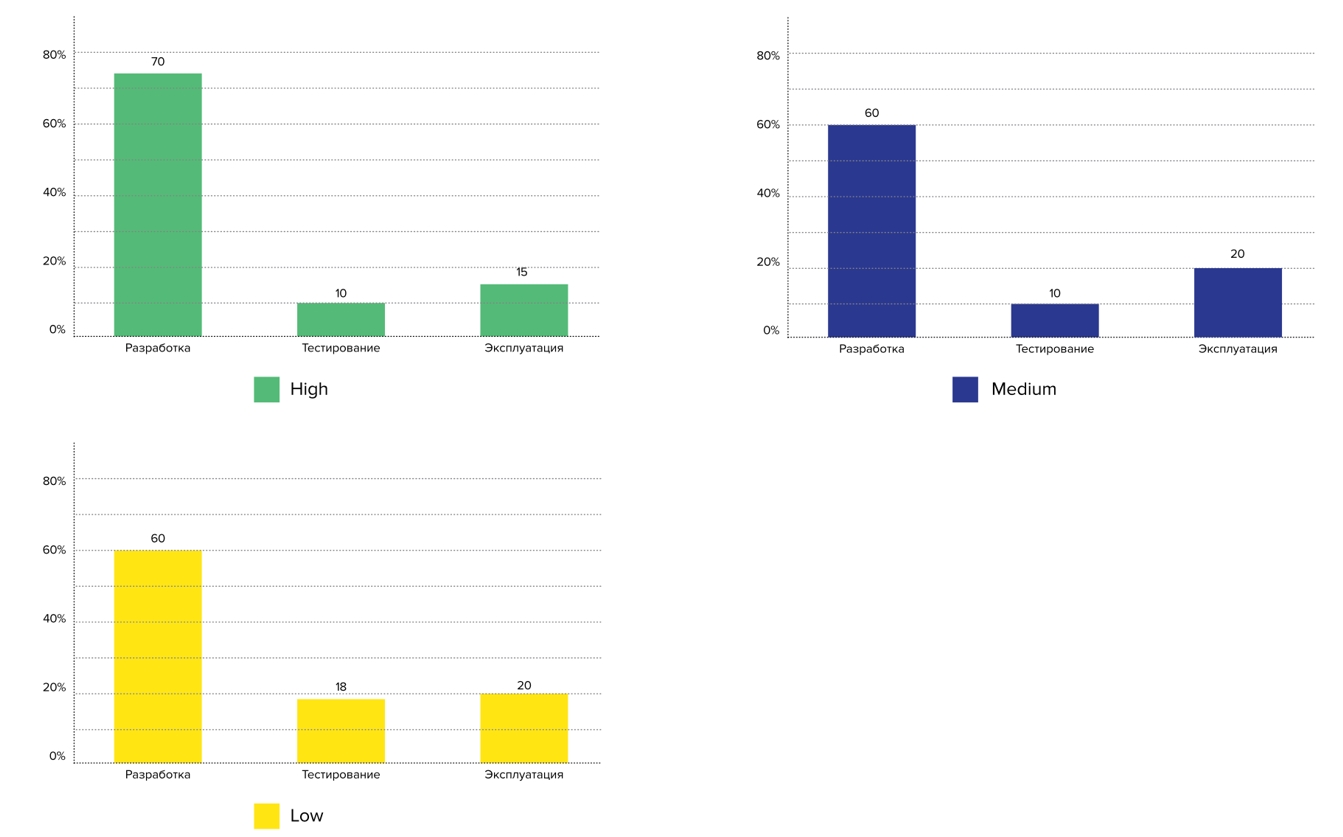
Planes para 2021
En sus planes para el próximo año, los encuestados señalaron las siguientes actividades:

Aquí puede ver la intersección con la conferencia DevOps Live 2020. Revisamos cuidadosamente el programa:
- Infraestructura como producto
- Transformación DevOps
- Difundir las prácticas de DevOps
- DevSecOps
- Clubes de casos y debates
Pero nuestro discurso no será suficiente para considerar todos los temas. Dejado detrás de escena:
- Plataforma como servicio y como producto;
- Infraestructura como código, entornos y nubes;
- Integración y entrega continuas;
- Arquitectura;
- Patrones DevSecOps;
- Plataformas y equipos multifuncionales.
Nuestro informe resultó ser voluminoso, en 50 páginas, y se puede ver con más detalle.
Resumiendo
Esperamos que nuestra investigación e informe lo inspiren a experimentar con nuevos enfoques para el desarrollo, las pruebas y las operaciones, así como que lo ayuden a navegar, compararse con otros participantes de la investigación e identificar áreas en las que puede mejorar sus propios enfoques.
Resultados de la primera encuesta sobre el estado de DevOps en Rusia:
- Llaves metricas. Hemos descubierto que las métricas clave (tiempo de entrega, frecuencia de implementación, tiempo de recuperación y cambios fallidos) son apropiadas para analizar la efectividad del desarrollo, las pruebas y las operaciones.
- High, Medium, Low. High, Medium, Low , , . High , Low. .
- , 2021 . , . High , , .
- Prácticas DevOps, herramientas y su desarrollo. Los principales planes de las empresas para el próximo año incluyen el desarrollo de prácticas y herramientas DevOps, la introducción de prácticas DevSecOps y un cambio en la estructura organizacional. Y la implementación y desarrollo efectivo de las prácticas DevOps se realiza a través de proyectos piloto, la formación de comunidades y centros de excelencia, iniciativas en los niveles superior e inferior de la empresa.
Estaremos encantados de escuchar sus comentarios, historias y comentarios. Gracias a todos los que participaron en el estudio y esperamos su participación el próximo año.