
Fuente de imagen
Dos revoluciones en el procesamiento del lenguaje natural
La primera revolución de la PNL se asoció con el éxito de modelos basados en representaciones vectoriales de la semántica de un lenguaje, obtenidos mediante métodos de aprendizaje no supervisados. El florecimiento de estos modelos comenzó con la publicación de los resultados de Tomáš Mikolov , estudiante de doctorado Yoshua Bengio (uno de los padres fundadores del aprendizaje profundo moderno, ganador del Premio Turing) y la aparición de la popular herramienta word2vec. La segunda revolución comenzó con el desarrollo de mecanismos de atención en redes neuronales recurrentes, lo que resultó en el entendimiento de que el mecanismo de atención es autosuficiente y bien podría utilizarse sin la red recurrente en sí. El modelo de red neuronal resultante se denomina "transformador". Se presentó a la comunidad científica en 2017 en un artículo titulado "La atención es todo lo que necesita ", escrito por un grupo de investigadores de Google Brain y Google Research. El rápido desarrollo de las redes basadas en transformadores ha dado como resultado modelos de lenguaje gigantes como el Transformador preentrenado generativo 3 de OpenAI (GPT-3)capaz de resolver eficazmente muchos problemas de PNL.
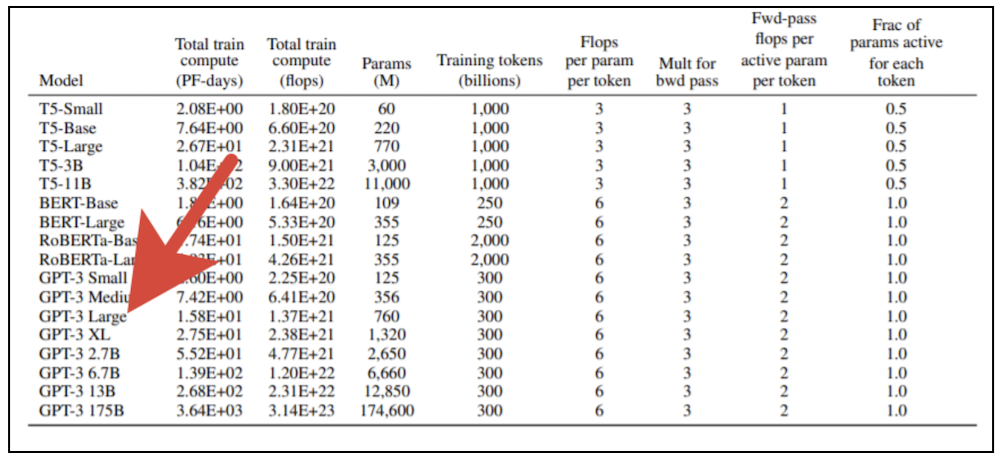
El entrenamiento de modelos de transformadores gigantes requiere importantes recursos computacionales. No puede simplemente tomar una tarjeta gráfica moderna y entrenar tal modelo en la computadora de su hogar. La publicación original de OpenAI presenta 8 variantes del modelo, y si tomas la más pequeña de ellas (GPT-3 Small) con 125 millones de parámetros e intentas entrenarla usando una tarjeta de video profesional NVidia V100 equipada con potentes núcleos tensores, entonces te llevará unos seis meses. Si tomamos la versión más grande del modelo con 175 mil millones de parámetros, entonces el resultado tendrá que esperar casi 500 años. El costo de capacitar la versión más grande del modelo a las tarifas de los servicios en la nube que proporcionan dispositivos informáticos modernos en alquiler.supera los mil millones de rublos (y esto todavía está sujeto a una escala de rendimiento lineal con un aumento en el número de procesadores involucrados, que en principio es inalcanzable).
¡Viva las supercomputadoras!
Está claro que estos experimentos solo están disponibles para empresas con importantes recursos informáticos. Para solucionar este tipo de problemas, en 2019 Sberbank puso en funcionamiento la supercomputadora Christophari , que ocupó el primer lugar en términos de rendimiento entre las supercomputadoras disponibles en nuestro país. 75 nodos de cómputo DGX-2 (cada uno con 16 tarjetas NVidia V100 ) conectados por un bus ultrarrápido basado en tecnología Infinibandle permiten entrenar GPT-3 Small en solo unas pocas horas. Sin embargo, incluso para una máquina de este tipo, la tarea de entrenar variantes más grandes del modelo no es trivial. En primer lugar, una parte de la máquina se ocupa de entrenar otros modelos diseñados para resolver problemas en el campo de la visión por computadora, el reconocimiento y síntesis de voz, y muchas otras áreas de interés para diversas empresas del ecosistema Sberbank. En segundo lugar, el proceso de aprendizaje en sí, que utiliza simultáneamente muchos nodos computacionales en una situación en la que los pesos del modelo no caben en la memoria de una tarjeta, no es estándar.
En general, nos encontramos en una situación en la que la antorcha distribuida, familiar para muchos, no era adecuada para nuestros propósitos. No teníamos tantas opciones, por lo que recurrimos a la implementación "nativa" de NVidia Megatron-LM.y la nueva creación de Microsoft: DeepSpeed , que requirió la creación de contenedores docker personalizados en Christophari, con lo que nuestros colegas de SberCloud nos ayudaron rápidamente . DeepSpeed, en primer lugar, nos brindó herramientas convenientes para el entrenamiento en paralelo de modelos, es decir, distribuir un modelo a varias GPU y fragmentar el optimizador entre GPU. Esto le permite utilizar lotes más grandes, así como modelos de trenes con más de 1,5 mil millones de pesos sin una montaña de código adicional.
Sorprendentemente, la tecnología durante el último medio siglo en su desarrollo ha descrito la siguiente ronda de la espiral: parece que está regresando la era de los mainframes (computadoras poderosas con acceso a terminales). Ya estamos acostumbrados al hecho de que la principal herramienta de desarrollo es una computadora personal asignada para uso exclusivo por parte del desarrollador. A fines de la década de 1960 y principios de la de 1970, una hora de operación de la computadora central costaba aproximadamente lo mismo que el salario de un mes completo para un operador de computadora. Parecía que estos tiempos se habían ido para siempre y el "hierro" se volvió para siempre más barato que el tiempo de trabajo. Sin embargo, parece que el hardware ha tenido un regreso impresionante. La vida cotidiana de un especialista en aprendizaje automático moderno vuelve a parecerse a la vida cotidiana de Sasha Privalov de la historia de los hermanos Strugatsky "El lunes comienza el sábado", con la única diferencia de que el lugar de "Aldan" en nuestro caso lo ocupa "Christofari", y el papel de la magia y la hechicería se realiza mediante métodos de aprendizaje profundo.
De la experiencia de SberDevices
Muchas veces en el pasado hemos tenido que aprender otros modelos basados en transformadores: estos son varios herederos de BERT y modelos de codificador-decodificador, como T5 de Google . Asistentes virtuales creados por SberDevices para varias superficies, comenzando con los últimos SberBox y SberPortaly terminando con la aplicación habitual de Sberbank Online, utilizan varios modelos similares en su trabajo para resolver diversos problemas en el transcurso de la comunicación con el usuario. Por ejemplo, el asistente virtual Joy usa el modelo GPT-2 Medium en el modo de chat, entrenado en un gran corpus de literatura rusa, entrenado en un conjunto de datos de diálogo especial y equipado con un mecanismo de clasificación especial diseñado para seleccionar las respuestas más interesantes. Estos modelos son capaces de mantener una conversación con el usuario, no eligiendo pistas de una biblioteca de respuestas preparada previamente, sino haciendo sus propias frases "sobre la marcha", lo que hace que la comunicación con ellos sea más diversa y entretenida.
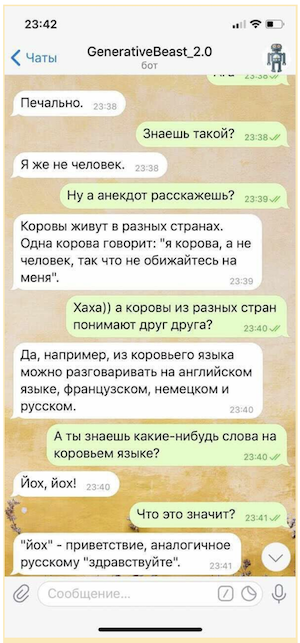

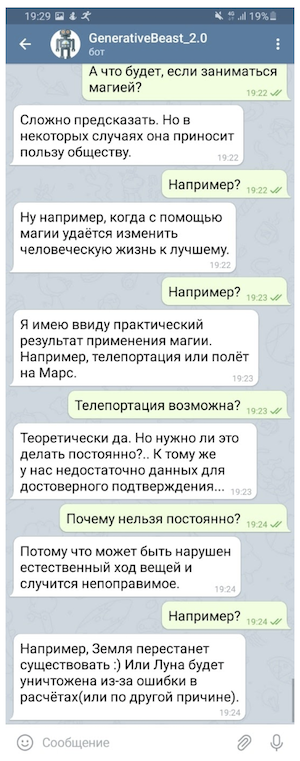
Por supuesto, tal "charla" no puede usarse sin algún seguro en forma de un sistema de microintentos (reglas diseñadas para proporcionar respuestas controladas a algunas de las preguntas más delicadas) y un modelo separado diseñado para esquivar preguntas provocativas, pero incluso en una forma tan limitada La "charla generativa" es capaz de elevar significativamente el estado de ánimo de su interlocutor.
En una palabra, nuestra experiencia en la enseñanza de grandes modelos de transformadores fue útil cuando la dirección de Sberbank decidió asignar recursos informáticos para un proyecto de investigación para entrenar a GPT-3. Tal proyecto requería combinar los esfuerzos de varias unidades a la vez. Por parte de SberDevices, el papel de liderazgo en este proceso lo asumió el Departamento de Sistemas Experimentales de Aprendizaje Automático (con la participación de varios expertos de otros equipos), y por parte de Sberbank.AI - por el equipo AGI NLP . Nuestros colegas de SberCloud, que apoyan a Christophari, también se unieron activamente al proyecto.
Junto con colegas del equipo AGI NLP, logramos ensamblar la primera versión del corpus de capacitación en idioma ruso con un volumen total de más de 600 GB. Incluye una gran colección de literatura rusa, instantáneas de Wikipedia en ruso e inglés, una colección de instantáneas de noticias y sitios de preguntas y respuestas , secciones públicas de Pikabu , una colección completa de materiales del portal de divulgación científica 22century.ru y el portal bancario banki.ru , así como el corpus Omnia Russica . Además, como queríamos experimentar con la capacidad de manejar código de programa, incluimos instantáneas de github y StackOverflow en el corpus de entrenamiento.... El equipo de AGI NLP ha trabajado mucho en la limpieza y deduplicación de datos, así como en la preparación de conjuntos para la validación y prueba de modelos. Si en el corpus original utilizado por OpenAI, la proporción de inglés a otros idiomas es 93: 7, entonces, en nuestro caso, la proporción de ruso a otros idiomas es aproximadamente 9: 1.
Elegimos las arquitecturas GPT-3 Medium (350 millones de parámetros) y GPT-3 Large (760 millones de parámetros) como base para los primeros experimentos. Al hacerlo, entrenamos el modelo como con bloques de transformadores alternos con escasay mecanismos y modelos de atención densos en los que todos los bloques de atención estaban completos. El hecho es que el trabajo original de OpenAI habla de intercalar bloques, pero no proporciona su secuencia específica. Si todos los bloques de atención en el modelo están completos, esto aumenta el costo computacional del entrenamiento, pero asegura que el potencial predictivo del modelo se utilice al máximo. Actualmente, la comunidad científica está estudiando activamente varios modelos de atención, diseñados para reducir los costos computacionales de los modelos de entrenamiento y aumentar la precisión. En poco tiempo, los investigadores han propuesto un reformador , un reformador , un transformador con una capacidad de atención adaptativa., Transformador compresor [transformador compresivo] , transformador ENBLOCK [transformador blockwise] , BigBird , transformador con complejidad lineal [linformer] y varios otros modelos similares. También estamos investigando en esta área, mientras que los modelos compuestos solo de bloques densos son una especie de punto de referencia que nos permite evaluar el grado de disminución en la precisión de varias versiones "aceleradas" del modelo.
Concurso "AI 4 Humanities: ruGPT-3"
Este año, en el marco de AI Journey, el equipo Sberbank.AI organizó el concurso AI 4 Humanities: ruGPT-3. Como parte de la prueba general, se invita a los participantes a enviar prototipos de soluciones para cualquier problema social o empresarial creado utilizando el modelo ruGPT-3 previamente entrenado. Se invita a los participantes en la nominación especial "AIJ Junior" a crear una solución para generar ensayos significativos en cuatro temas humanitarios (idioma ruso, historia, literatura, estudios sociales) del 11 ° grado (USE) sobre la base de ruGPT-3 sobre la base de ruGPT-3 para un tema / texto determinado de la tarea.
Especialmente para estas competiciones, entrenamos tres versiones del modelo GPT-3: 1) GPT-3 Medium, 2) GPT-3 Large con bloques alternados de transformadores dispersos y densos, 3) el más "poderoso" GPT-3 Large, compuesto solo bloques densos. Los conjuntos de datos de entrenamiento y los tokenizadores son idénticos para todos los modelos: se utilizaron el tokenizador BBPE y nuestro conjunto de datos Large1 personalizado con un volumen de 600 GB (su composición se da en el texto anterior).
Los tres modelos están disponibles para descargar en el repositorio de la competencia.
Aquí hay algunos ejemplos divertidos de cómo funciona el tercer modelo:



¿Cómo cambiarán nuestro mundo modelos como GPT-3?
Es importante entender que modelos como GPT-1/2/3, de hecho, resuelven exactamente un problema: intentan predecir el siguiente token (generalmente una palabra o parte de él) en la secuencia de los anteriores. Este enfoque permite utilizar datos “sin etiquetar” para la formación, es decir, prescindir de la participación de un “profesor”, y por otro lado, permite resolver una gama bastante amplia de problemas del campo de la PNL. De hecho, en el texto de un diálogo, por ejemplo, una respuesta-respuesta es una continuación de la historia de la comunicación, en una obra de ficción: el texto de cada párrafo continúa el texto anterior, y en una sesión de preguntas y respuestas, el texto de la respuesta sigue el texto de la pregunta. Como resultado, los modelos de gran capacidad pueden resolver muchos de estos problemas sin capacitación adicional especial; solo necesitan ejemplos que encajen en el "contexto del modelo".que GPT-3 tiene bastante impresionante: hasta 2048 tokens.
GPT-3 es capaz no solo de generar textos (incluyendo poemas, chistes y parodias literarias), sino también corregir errores gramaticales, conducir diálogos e incluso (¡FUERA DEL ESTADO!) Escribir código de programa más o menos significativo. Se pueden encontrar muchos usos interesantes de GPT-3 en el sitio del investigador independiente Gwern Branwen. Branuen, desarrollando una idea expresada en un tweet de broma de Andrej Karpathy, hace una pregunta interesante: ¿estamos presenciando el surgimiento de un nuevo paradigma de programación?
Aquí está el texto del tweet original de Karpaty:
“Me encanta la idea de Software 3.0. La programación pasa de preparar conjuntos de datos a preparar consultas que permiten que el sistema de metaaprendizaje "comprenda" la esencia de la tarea que necesita realizar. LOL "[Me encanta la idea de Software 3.0. La programación pasa de la selección de conjuntos de datos a la selección de indicaciones para que el metaaprendiz "obtenga" la tarea que se supone que debe realizar. LOL].
Desarrollando la idea de Karpaty, Branuen escribe:
« GPT-3 [ ] , : , , , ( GPT-2); , , , [prompt], , , «» - , , . , , «» «», GPT-3 . « » , : , , , , , , , , , ».
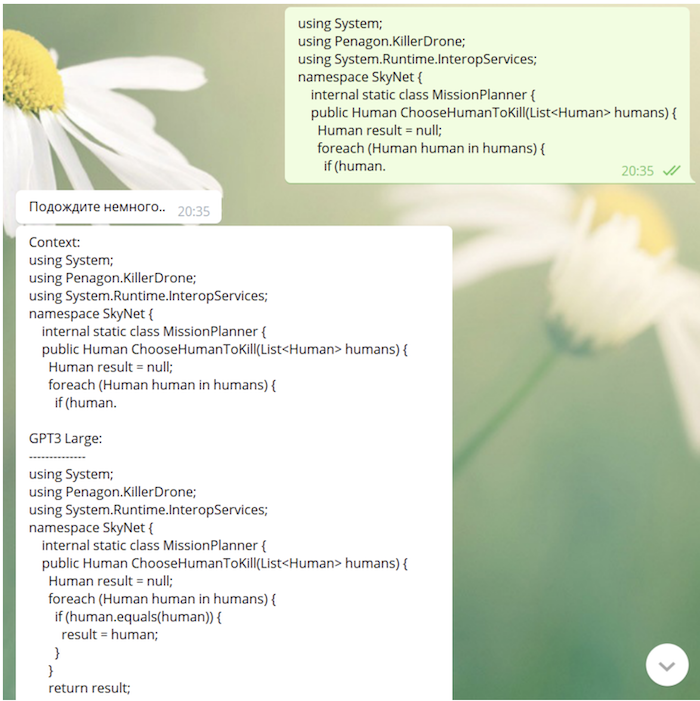
Dado que nuestro modelo "vio" github y StackOverflow en el proceso de aprendizaje, es bastante capaz de escribir código (a veces no carece de un significado muy profundo):
Que sigue
Este año continuaremos trabajando en modelos de transformadores gigantes. Otros planes están relacionados con una mayor expansión y limpieza de conjuntos de datos (estos, en particular, incluirán instantáneas del servicio de preimpresión arxiv.org para publicaciones científicas y la biblioteca de investigación de PubMed Central, conjuntos de datos de diálogo especializados y conjuntos de datos sobre lógica simbólica), aumentando el tamaño de los modelos entrenados, así como utilizando tokenizador mejorado.
Esperamos que la publicación de modelos capacitados estimule el trabajo de los investigadores y desarrolladores rusos que necesitan modelos de lenguaje superpoderosos, porque sobre la base de ruGPT-3 puede crear sus propios productos originales, resolver diversos problemas científicos y comerciales. Prueba a utilizar nuestros modelos, experimenta con ellos y asegúrate de compartir todos los resultados que obtengas. El progreso científico hace que nuestro mundo sea mejor y más interesante, ¡mejoremos el mundo juntos!