Observo con pena que Libra (¡ESTE SOY YO!) Está en el último lugar ... Aunque, según los datos, me parece que hay anomalías. ¡De alguna manera sospechosamente pequeña Libra!
Parte 1. Análisis y obtención de datos iniciales
Wikipedia Lista de listas de listas
en la salida necesita una base con nombre completo + fecha de nacimiento + (si hay otros signos, por ejemplo, m / f, país, etc.) hay una API .
Este sitio resultó ser un sitio raspado (recolectando / recibiendo / extrayendo (extrayendo) / recolectando datos obtenidos de recursos web) usando la biblioteca Python Scrapy.
Las instrucciones detalladas
primero obtienen enlaces (hojas con personas de Wikipedia y luego datos).
En otros casos, se ha analizado correctamente como esta .
Resultado: archivo BD wiki.zip
Parte 2. Acerca del preprocesamiento (por Stanislav Kostenkov - contactos a continuación)
Mucha gente se enfrenta a la complejidad del procesamiento de datos de entrada. Entonces, en esta tarea fue necesario extraer datos de nacimiento de más de 42 mil artículos y, de ser posible, determinar el país de nacimiento. Por un lado, se trata de una simple tarea algorítmica, por otro lado, las herramientas de los sistemas Excel & BI no permiten que se haga "de frente".
En ese momento, los lenguajes de programación (Python, R) acuden al rescate, cuyo lanzamiento se proporciona en la mayoría de los sistemas de BI. Vale la pena señalar que, por ejemplo, en Power BI hay un límite de 30 minutos para ejecutar un script (programa) en Python. Por lo tanto, muchos procesos "pesados" se realizan antes del lanzamiento de los sistemas de BI, por ejemplo, en un lago de datos.
Cómo se resolvió el problema
Lo primero que hice después de cargar y verificar valores no válidos fue convertir cada artículo en una lista de palabras.
En esta tarea tuve suerte con el idioma, el inglés. Este lenguaje se caracteriza por una forma rígida de construcción de la oración, lo que facilitó mucho la búsqueda de la fecha de nacimiento. La palabra clave aquí es "nacido", luego busca y analiza lo que está después de ella.
Por otro lado, todos los artículos se tomaron de una sola fuente, lo que también facilitó la tarea. Todos los artículos tenían aproximadamente la misma estructura y velocidad.
Además, todos los años tenían 4 caracteres, todas las fechas tenían entre 1 y 2 caracteres y los meses eran textuales. Solo hubo 3-4 posibles variaciones en la ortografía de la fecha de nacimiento, que se resolvió con lógica simple. También se puede analizar mediante expresiones regulares.
El código real no está optimizado (tal tarea no se configuró, tal vez haya fallas en los nombres de las variables).
Como predijo el país, tuve la suerte de encontrar una tabla de correspondencias de países y nacionalidades. Por lo general, los artículos describen no el país, sino la pertenencia a él. Por ejemplo, Rusia - ruso. Por lo tanto, buscamos apariciones de nacionalidades, pero como podría haber más de 5 nacionalidades diferentes en un artículo, hice la hipótesis de que la palabra deseada sería lo más cercano posible a la palabra clave "quemar". Por lo tanto, el criterio fue: la distancia mínima de índice entre las palabras necesarias en el artículo. Luego, se cambió el nombre de una línea de nacionalidad a país.
Lo que no se hizo
En los artículos, muchas palabras tenían basura, es decir, algún fragmento del código estaba conectado a la palabra, o dos palabras se fusionaron. Por lo tanto, no se verificó la probabilidad de encontrar los valores deseados en tales palabras. Puede limpiar estas palabras utilizando algoritmos de similitud.
No se analizaron las entidades a las que pertenece la palabra clave "burn". Hubo varios ejemplos donde la palabra clave estaba relacionada con el nacimiento de familiares. Estos ejemplos fueron insignificantes. Estos ejemplos se remontan al hecho de que la palabra clave está lejos del comienzo del artículo. Puede calcular los percentiles para encontrar una palabra clave y determinar el criterio de recorte.
Algunas palabras sobre la utilidad del preprocesamiento al limpiar datos
Hay casos comunes en los que podemos adivinar exactamente qué debería estar en lugar de los huecos. Pero hay casos, por ejemplo, hay omisiones en función del género de un comprador de la tienda y hay datos sobre sus compras. No existen técnicas estándar para resolver este problema en los sistemas de BI, pero al mismo tiempo, en el nivel de preprocesamiento, puede crear un modelo "ligero" y ver varias opciones para llenar los vacíos. Hay opciones de relleno basadas en algoritmos simples de aprendizaje automático. Y vale la pena usarlo. No es dificil.
El código fuente (Python) está disponible en el enlace
Resultado: archivo out_data_fin.xls
Stanislav Kostenkov / CBS Consulting (Izhevsk, Rusia) staskostenkov@gmail.com
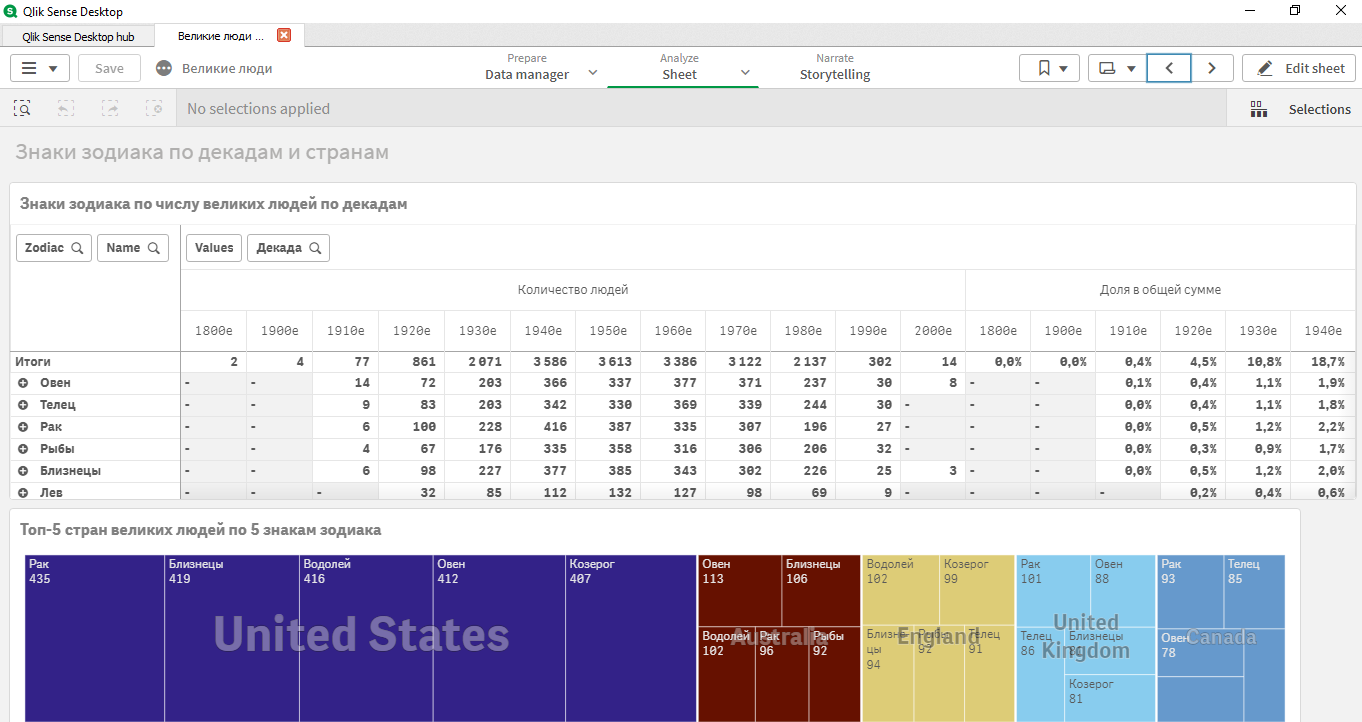
Parte 3. Aplicación Qlik Sense
Luego se realizó una aplicación clásica, donde se revelaron algunas anomalías con el conjunto de datos:
- tenía sentido elegir sólo las décadas de 1920-1980;
- en diferentes países había diferentes líderes según los signos del horóscopo;
- signos superiores: Cáncer, Aries, Géminis, Tauro, Capricornio.
Todos los datos (conjunto de datos, datos brutos, recibidos por la aplicación Qlik Sense para el análisis de datos) se ubican por referencia .