Según la creencia popular, extraer texto de archivos PDF no debería ser tan difícil. Después de todo, aquí está, el texto, ante nuestros ojos, y la gente percibe constantemente y con gran éxito el contenido de PDF. ¿De dónde proviene la dificultad en la extracción automática de texto?
Resulta que así como trabajar con nombres de personas es difícil para los algoritmos debido a muchos casos extremos y suposiciones incorrectas, trabajar con PDF es difícil debido a la extrema flexibilidad del formato PDF.
El principal problema es que PDF no fue diseñado como un formato para la entrada de datos, sino que se desarrolló como un canal de salida, lo que permite ajustar la apariencia del documento final.
Básicamente, el formato PDF consiste en un flujo de instrucciones que describen cómo se crea una imagen en una página. En particular, los datos de texto no se almacenan como párrafos, ni siquiera como palabras, sino como caracteres dibujados en lugares específicos de la página. Como resultado, al convertir texto o documento de Word a PDF, se pierde la mayor parte de la semántica del contenido. Toda la estructura interna del texto se convierte en una sopa amorfa de personajes flotando en la página.
Al completar FilingDB, hemos extraído datos de texto de decenas de miles de documentos PDF. En el proceso, observamos cómo absolutamente todas nuestras suposiciones sobre la estructura de los archivos PDF resultaron ser incorrectas. Nuestra misión fue especialmente difícil porque teníamos que procesar documentos PDF provenientes de diferentes fuentes con estilos, fuentes y apariencia completamente diferentes.
A continuación se describen las características de los archivos PDF que dificultan o incluso imposibilitan la extracción de texto de ellos.
Protección de lectura de PDF
Es posible que haya encontrado archivos PDF que prohíben copiar contenido de texto de ellos. Por ejemplo, esto es lo que produce el programa SumatraPDF al intentar copiar texto de un documento protegido contra copia:

Es interesante que el texto sea visible, pero el espectador se niega a transferir el texto seleccionado al portapapeles.
Esto se logra con varios indicadores de "permisos de acceso", uno de los cuales controla el permiso de copia. Es importante comprender que el archivo PDF en sí no obliga a esto: su contenido no cambia a partir de esto y la tarea de su implementación recae completamente en el espectador.
Naturalmente, esto no protege realmente contra la extracción de texto de PDF, ya que cualquier biblioteca lo suficientemente avanzada para trabajar con PDF permitirá al usuario cambiar estos indicadores o ignorarlos.
Caracteres fuera de las páginas
A menudo, un PDF contiene más datos textuales de los que se muestran en la página. Tome esta página del Informe anual de 2010 de Nestlé.
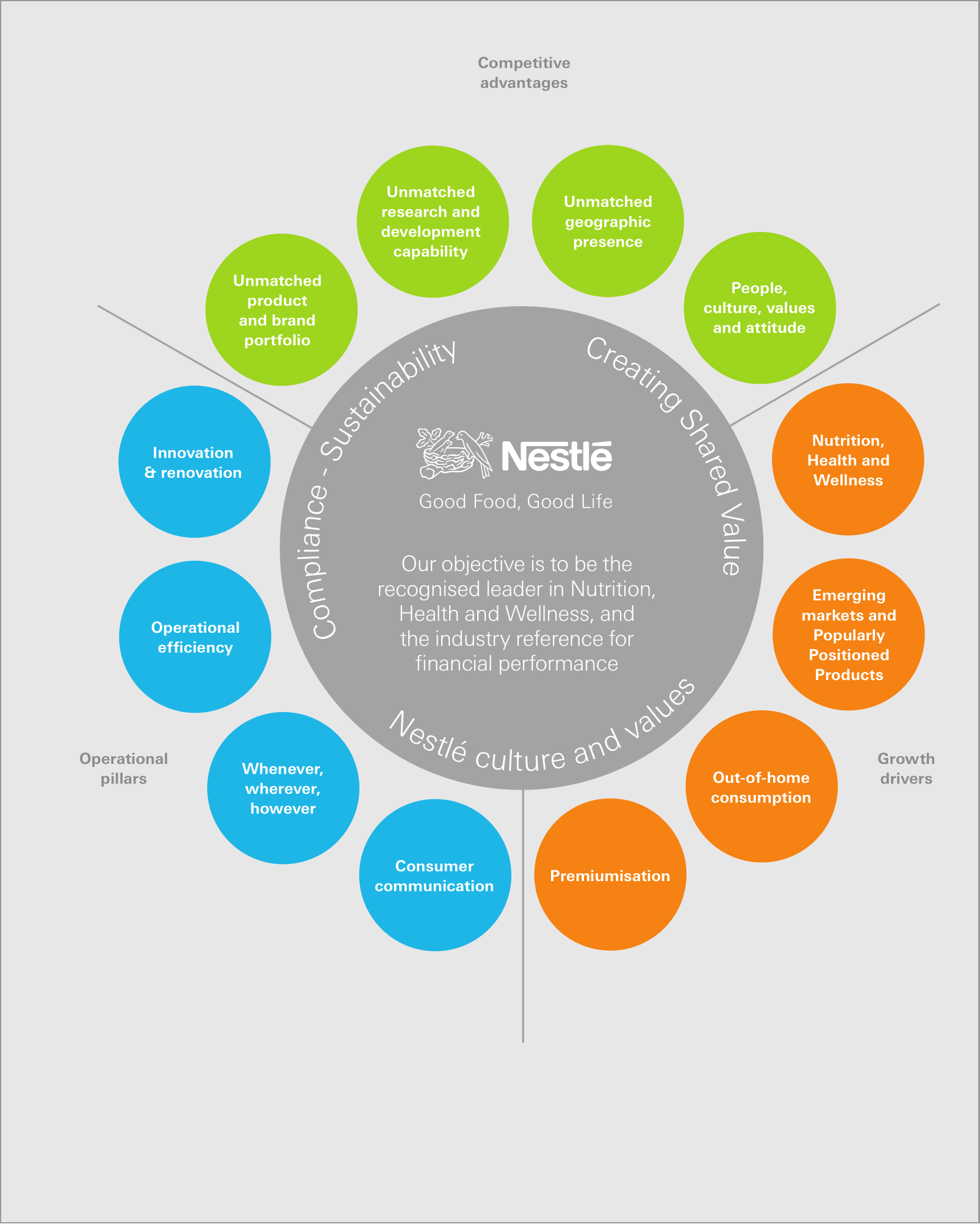
Hay más texto adjunto a esta página del que es visible. En particular, se puede encontrar lo siguiente en el contenido asociado a él:
KitKat celebró su 75 cumpleaños en 2010, pero sigue siendo joven y moderno con más de 2,5 millones de seguidores en Facebook. Sus productos se venden en más de 70 países y las ventas están creciendo bien en países desarrollados y mercados emergentes como Oriente Medio, India y Rusia. Japón es el segundo mercado más grande de la empresa.
Este texto está fuera de la página, por lo que la mayoría de los visores de PDF no lo mostrarán. Sin embargo, los datos están ahí y se pueden recuperar mediante programación.
Esto a veces sucede debido a decisiones de última hora para reemplazar o eliminar texto durante el proceso de aprobación.
Personajes pequeños o invisibles
A veces, se pueden encontrar caracteres muy pequeños o incluso invisibles en la página PDF. Por ejemplo, aquí hay una página del informe de Nestlé de 2012.

La página tiene un pequeño texto blanco sobre un fondo blanco que dice:
Logotipo de Wyeth Nutrition Identidad Orientación a los mercados
Vevey Octobre 2012 RCC / CI & D
A veces, esto se hace para mejorar la accesibilidad, con el mismo propósito que la etiqueta alt en HTML.
Demasiados espacios
A veces, se insertan espacios adicionales entre letras de palabras en PDF. Esto probablemente se hace con fines de kerning (cambiar el espacio entre caracteres).
Por ejemplo, el informe de Hikma Pharma de 2013 contiene el siguiente texto:

Si lo copia, obtenemos:
ch a i r m a n ' s s tat em en tEn general, es difícil resolver el problema de la reconstrucción del texto original. Nuestro enfoque más exitoso es el uso de reconocimiento óptico de caracteres, OCR.
No hay suficientes espacios
A veces, al PDF le faltan espacios o se ha reemplazado por un carácter diferente.
Ejemplo 1: El siguiente extracto es del Informe Anual de la SEB 2017.

Texto extraído:
TenyearsafterthefinancialcrisisstartedEjemplo 2: El informe de Eurobank 2013 contiene lo siguiente:

Texto extraído:
On_April_7,_2013,_the_competent_authoritiesNuevamente, OCR es la mejor opción para estas páginas.
Fuentes integradas
PDF funciona con fuentes de una manera complicada, por decirlo suavemente. Para comprender cómo se almacenan los datos de texto en PDF, primero debemos comprender los glifos, los nombres de glifos y las fuentes.
- Un glifo es un conjunto de instrucciones que describen cómo dibujar un carácter o una letra.
- – , . , « » ™ «» «».
- – . , , , «», .
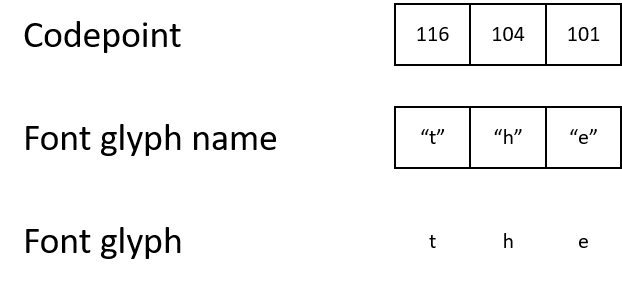
En PDF, los caracteres se almacenan como números, códigos de caracteres [puntos de código]. Para comprender lo que se debe mostrar en la pantalla, el renderizador debe seguir la cadena desde el código del carácter hasta el nombre del glifo y luego hasta el glifo en sí.
Por ejemplo, un PDF puede contener un código de carácter 116, que se asigna al nombre del glifo "t", que a su vez se asigna a un glifo que describe cómo mostrar el carácter "t".
La mayoría de los PDF utilizan la codificación de caracteres estándar. Una codificación de caracteres es un conjunto de reglas que asignan significado a los propios códigos de caracteres. Por ejemplo:
- ASCII y Unicode utilizan el código de carácter 116 para representar la letra "t".
- Unicode asigna el código de carácter 9786 al glifo "carita blanca", que se muestra como ☺, pero ASCII no define dicho código.
Sin embargo, un documento PDF a veces utiliza su propia codificación de caracteres y fuentes especiales. Puede sonar extraño, pero el documento puede indicar la letra "t" con el código de carácter 1. Asignará el código de carácter 1 al nombre de glifo "c1", que se asignará a un glifo que describe cómo mostrar la letra "t".
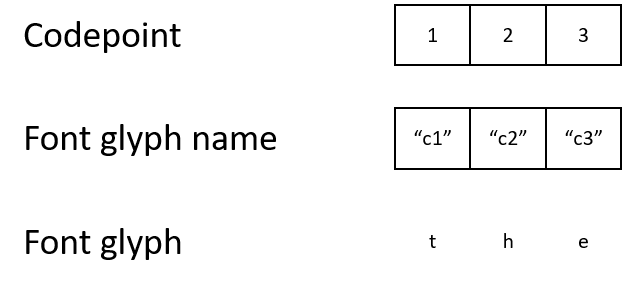
Si bien el resultado final no es diferente al de un humano, la máquina se confundirá con estos códigos de caracteres. Si los códigos de caracteres no coinciden con la codificación estándar, es casi imposible comprender mediante programación qué significan los códigos 1, 2 o 3.
¿Por qué un PDF incluiría fuentes y codificación no estándar?
- Una de las razones es dificultar la extracción de texto.
- – . , PDF . PDF , .
Una forma de evitar esto es extraer glifos de fuente del documento, ejecutarlos a través de OCR y asignar la fuente a Unicode. Esto le permitirá traducir la codificación relacionada con la fuente a Unicode, por ejemplo: el código de carácter 1 corresponde al nombre "c1", que, según el glifo, debería significar "t", que corresponde al código Unicode 116.
El mapa de codificación que acaba de done, el que coincide con los números 1 y 116, se llama tarjeta ToUnicode en el estándar PDF. Los documentos PDF pueden contener sus propias tarjetas ToUnicode, pero esto no es obligatorio.
Reconocimiento de palabras y párrafos
Reconstruir párrafos e incluso palabras de la sopa simbólica amorfa de archivos PDF es una tarea abrumadora.
Un documento PDF contiene una lista de caracteres en una página y el consumidor debe reconocer las palabras y los párrafos. Los seres humanos son naturalmente eficaces en esto porque la lectura es una habilidad común.
El algoritmo de agrupación más utilizado es comparar el tamaño, la posición y la alineación de los caracteres para determinar qué es una palabra o un párrafo.
Las implementaciones más simples de tales algoritmos pueden alcanzar fácilmente la complejidad O (n²), lo que puede llevar mucho tiempo procesar páginas densamente empaquetadas.
Orden de texto y párrafos
Reconocer el orden del texto y de los párrafos es un desafío por dos razones.
Primero, a veces simplemente no hay una respuesta correcta. Mientras que los documentos con un conjunto tipográfico regular con una columna tienen una secuencia de lectura natural, los documentos con una disposición de elementos más llamativa son más difíciles de determinar. Por ejemplo, no está del todo claro si el siguiente inserto debe aparecer antes, después o en el medio del artículo al lado del cual se encuentra: En

segundo lugar, incluso cuando la respuesta es clara para una persona, las computadoras pueden ser muy difíciles de determinar el orden exacto de los párrafos, incluso usando IA. Puede encontrar esta declaración un poco atrevida, pero en algunos casos la secuencia correcta de párrafos solo se puede determinar al comprender el contenido del texto.
Considere esta disposición de componentes en dos columnas, que describe la preparación de una ensalada de verduras.

En el mundo occidental, es razonable suponer que la lectura es de izquierda a derecha y de arriba a abajo. Por tanto, sin estudiar el contenido del texto, podemos reducir todas las opciones a dos: ABCD y ACB D.
Habiendo estudiado el contenido, entendiendo lo que allí dice, y sabiendo que las verduras se lavan antes de rebanar, podemos entender que el orden correcto sería ACB D. Es extremadamente difícil determinar esto algorítmicamente.
En este caso, "en la mayoría de los casos" funciona el enfoque que se basa en el orden en el que se almacena el texto dentro del documento PDF. Suele seguir el orden en el que se inserta el texto en el momento de la creación. Cuando grandes porciones de texto contienen muchos párrafos, generalmente siguen el orden que pretendía el autor.
Imágenes incrustadas
A menudo, parte del contenido de un documento (o todo el documento) es la imagen escaneada. En tales casos, no contiene datos de texto y debe recurrir a OCR.
Por ejemplo, el Informe anual de Yell 2011 solo está disponible como escaneo:

¿Por qué no reconocer todo?
Si bien OCR puede ayudar con algunos de los problemas descritos, también tiene sus inconvenientes.
- Largo tiempo de procesamiento. Ejecutar OCR en un escaneo de PDF generalmente toma un orden de magnitud más (o incluso más) que extraer texto directamente de PDF.
- Dificultades con caracteres y glifos no estándar. Es difícil para los algoritmos de OCR trabajar con nuevos caracteres: emoticonos, asteriscos, círculos, cuadrados (en listas), superíndices, símbolos matemáticos complejos, etc.
- . , PDF-, , . .
Hasta ahora, no hemos mencionado lo difícil que es confirmar que el texto se extrajo correctamente o como se esperaba. Hemos descubierto que es mejor ejecutar un conjunto extenso de pruebas que estudien métricas básicas (longitud del texto, longitud de la página, proporción de palabras a espacios) y más complejas (porcentaje de palabras en inglés, porcentaje de palabras no reconocidas, porcentaje de números), así como monitorear advertencias como caracteres sospechosos o inesperados.
¿Qué podemos recomendar para extraer texto de PDF? En primer lugar, asegúrese de que el texto no tenga una fuente más conveniente.
Si los datos que le interesan están solo en formato PDF, entonces es importante comprender que este problema parece simple solo a primera vista y puede que no sea posible resolverlo con una precisión del 100%.