Tarea
Dado: un proyecto basado en OpenWRT (y está basado en BuildRoot) con un repositorio adicional conectado como fuente. Objetivo: fusionar un repositorio adicional con el principal.
Antecedentes
Hacemos enrutadores y, un día, queríamos brindarles a los clientes la posibilidad de incluir sus aplicaciones en el firmware. Para no sufrir con la asignación del SDK, la cadena de herramientas y las dificultades que lo acompañan, decidimos poner todo el proyecto en github en un repositorio privado. Estructura del repositorio:
/target //
/toolchain // gcc, musl
/feeds //
/package //
...
Se decidió trasladar algunas de las aplicaciones de nuestro propio desarrollo del repositorio principal al adicional, para que nadie espíe. Lo hicimos todo, lo pusimos en github y se puso bueno.
Mucha agua ha pasado por debajo del puente desde entonces ...
El cliente se ha ido durante mucho tiempo, el repositorio se ha eliminado de github y la idea misma de dar acceso a los clientes al repositorio está podrida. Sin embargo, dos repositorios permanecieron en el proyecto. Y todos los scripts / aplicaciones, de una forma u otra relacionadas con git, se ven obligados a complicarse para trabajar con tal estructura. En pocas palabras, es deuda técnica. Por ejemplo, para garantizar la reproducibilidad de las versiones, debe enviar al repositorio principal un archivo, versión secundaria, con un hash del segundo repositorio. Por supuesto, el guión lo hace, y no es muy difícil. Pero hay una docena de estos guiones y todos son más complicados de lo que podrían ser. En general, tomé la decisión deliberada de fusionar el repositorio secundario con el primario. Al mismo tiempo, se estableció la condición principal: mantener la reproducibilidad de las liberaciones.
Una vez que se establece tal condición, los métodos de fusión triviales, como enviar todo desde el secundario por separado y luego, desde arriba, hacer una confirmación de fusión de dos árboles independientes, no funcionarán. Tienes que abrir el capó y ensuciarte las manos.
Estructura de datos de Git
Primero, ¿cómo es un repositorio de git? Esta es una base de datos de objetos. Los objetos son de tres tipos: blobs, árboles y confirmaciones. Todos los objetos se direccionan mediante el hash sha1 de su contenido. Un blob es, estúpidamente, datos sin atributos adicionales. Un árbol es una lista ordenada de enlaces a árboles y blobs de la forma “<derecha> <tipo> <hash> <nombre>” (donde <tipo> es blob o árbol). Por lo tanto, un árbol es como un directorio en el sistema de archivos y un blob es como un archivo. Una confirmación contiene el nombre del autor y el autor de la confirmación, la fecha de creación y adición, un comentario, un hash de árbol y un número arbitrario (generalmente uno o dos) de enlaces a las confirmaciones principales. Estos enlaces a las confirmaciones de los padres convierten la base del objeto en un dígrafo acíclico (entre los extranjeros, conocido como DAG).Leer en detalleaquí :
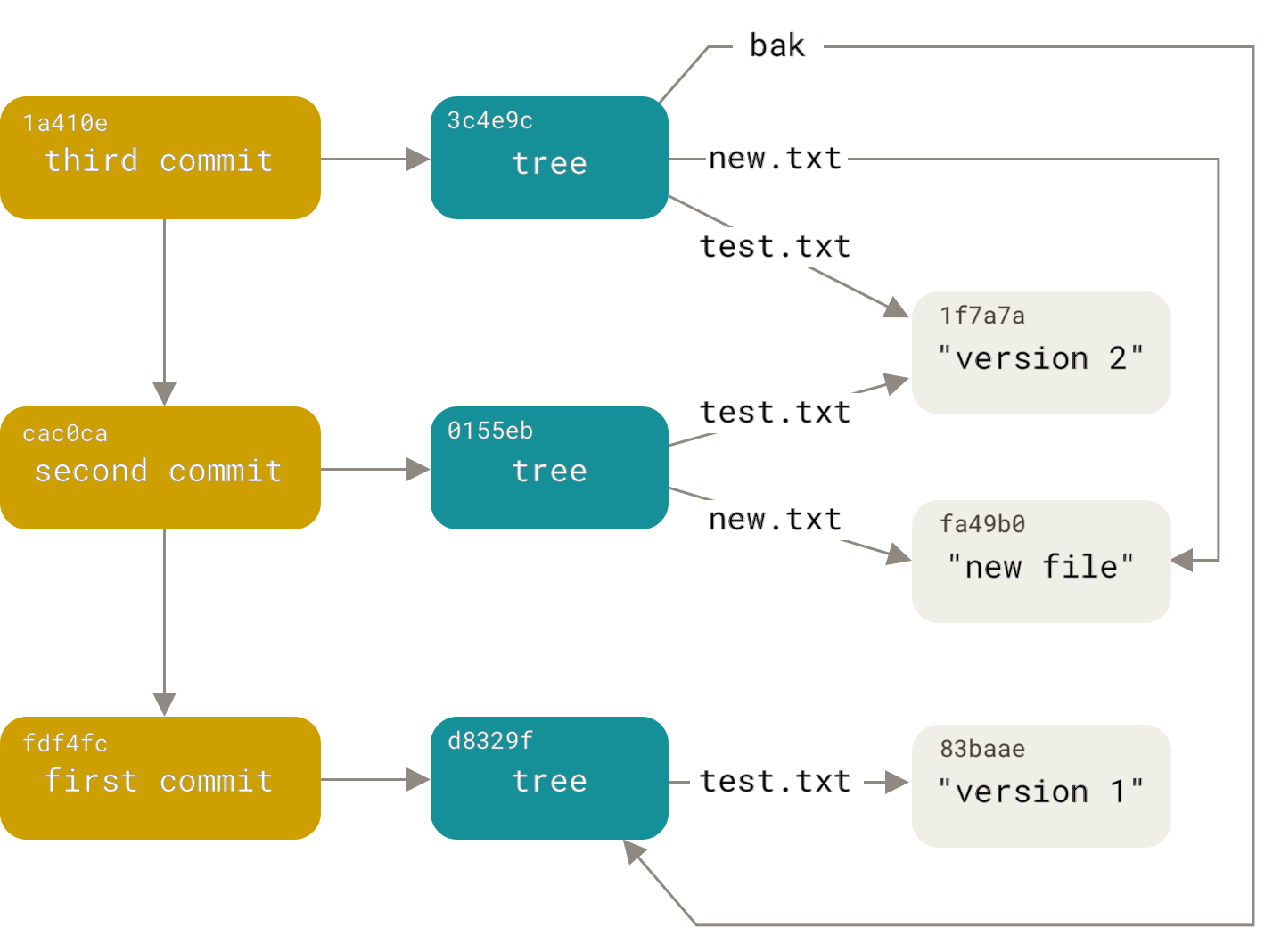
Así, nuestra tarea se ha transformado en la tarea de construir un nuevo dígrafo, repitiendo la estructura del antiguo. Pero con el reemplazo de las confirmaciones del archivo secundario.version por confirmaciones del repositorio adicional, el

proceso de desarrollo está lejos del clásico gitflow. Entregamos todo al maestro, tratando de no romperlo al mismo tiempo. Hacemos construcciones a partir de ahí. Si es necesario, hacemos ramas estabilizadoras, que luego volvemos a fusionar con el maestro. En consecuencia, el gráfico del repositorio parece un tronco desnudo de una secuoya trenzado con enredaderas.
Análisis
La tarea, naturalmente, se divide en dos etapas: análisis y síntesis. Dado que para la síntesis es obviamente necesario ejecutar desde el mismo momento de asignar el repositorio secundario a todas las etiquetas y ramas, insertando confirmaciones desde el segundo repositorio, luego, en la etapa de análisis, necesita encontrar lugares donde insertar las confirmaciones secundarias y estas propias confirmaciones. Por lo tanto, debe crear un gráfico reducido, donde los nodos serán las confirmaciones del gráfico principal que cambian el archivo secundario.version (confirmaciones clave). Además, si los nodos de este git se refieren a los padres, en el nuevo gráfico, se necesitan referencias a los descendientes. Creo una tupla con nombre:
node = namedtuple(‘Node’, [‘primary_commit’, ‘secondary_commit’, ‘children’])
reserva necesaria
, . , .
Lo pongo en el diccionario:
master_tip = repo.commit(‘master’)
commit_map = {master_tip : node(master_tip, get_sec_commit(master_tip), [])}Pongo todas las confirmaciones que cambian la versión secundaria allí:
for c in repo.iter_commits(all=True, path=’secondary.verion’) :
commit_map[c] = node(c, get_sec_commit(c), [])Y construyo un algoritmo recursivo simple:
def build_dag(commit, commit_map, node):
for p in commit.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
build_dag(p, commit_map, commit_map[p])
else :
build_dag(p, commit_map, node)Es decir, por así decirlo, estiro los nudos clave en el pasado y los relaciono con los nuevos padres.
Lo ejecuto y ... RuntimeError se superó la profundidad máxima de recursividad
¿Cómo sucedió? ¿Hay demasiadas confirmaciones? git log y wc ¿ sabe la respuesta. Las confirmaciones totales desde la división son aproximadamente 20,000, y las que afectan a la versión secundaria, casi 700. La receta es conocida, se necesita una versión no recursiva.
def build_dag(master_tip, commit_map, master_node):
to_process = [(master_tip, master_node)]
while len(to_process) > 0:
c, node = to_process.pop()
for p in c.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
to_process.append(p, commit_map[p])
else :
to_process.append(p, node)(¡Y dijiste que todos estos algoritmos son necesarios solo para que pase la entrevista!) Lo
lanzo y ... funciona. Un minuto, cinco, veinte ... No, no puedes tardar tanto. Yo paro. Aparentemente, cada confirmación y cada ruta se procesan muchas veces. ¿Cuántas ramas hay en el árbol? Resultó que hay 40 ramas en el árbol y, en consecuencia,diferentes caminos solo del maestro. Y hay muchos caminos que conducen a una parte importante de las confirmaciones clave. Como no tengo miles de años en la tienda, necesito cambiar el algoritmo para que cada confirmación se procese exactamente una vez. Para hacer esto, agrego un conjunto, donde marco cada confirmación procesada. Pero hay un pequeño problema: con este enfoque, algunos de los enlaces se perderán, ya que diferentes rutas con diferentes confirmaciones clave pueden pasar por las mismas confirmaciones, y solo la primera llegará más lejos. Para solucionar este problema, reemplazo el conjunto con un diccionario, donde las claves son confirmaciones y los valores son listas de confirmaciones clave accesibles:
def build_dag(master_tip, commit_map, master_node):
processed_commits = {}
to_process = [(master_tip, master_node, [])]
while len(to_process) > 0:
c, node, path = to_process.pop()
p_node = commit_map.get(c)
if p_node :
commit_map[p].children.append(p_node)
for path_c in path :
if all(p_node.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(p_node)
path = []
node = p_node
processed_cmmts[c] = []
for p in c.parents :
if p != root_commit and and p not in processed_cmmts :
newpath = path.copy()
newpath.append(c)
to_process.append((p, node, newpath,))
else :
p_node = commit_map.get(p)
if p_node is None :
p_nodes = processed_cmmts.get(p, [])
else :
p_nodes = [p_node]
for pn in p_nodes :
node.children.append(pn)
if all(pn.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[c]) :
processed_cmmts[c].append(pn)
for path_c in path :
if all(pn.trunk_commit != nc.trunk_commit
for nc in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(pn)Como resultado de este ingenioso intercambio de memoria durante un tiempo, el gráfico se construye en 30 segundos.
Síntesis
Ahora tengo un commit_map con nodos clave vinculados a un gráfico a través de enlaces secundarios. Por conveniencia, lo transformaré en una secuencia de pares (ancestro, descendiente) . La secuencia debe garantizar que todos los pares en los que se produce un nodo como hijo se ubiquen antes que cualquier par en el que se produzca un nodo como antepasado. Luego, solo necesita revisar esta lista y confirmar primero las confirmaciones desde el repositorio principal y luego desde el adicional. Aquí debemos recordar que la confirmación contiene un enlace al árbol, que es el estado del sistema de archivos. Dado que el repositorio adicional contiene subdirectorios adicionales en el directorio package /, entonces será necesario crear nuevos árboles para todas las confirmaciones. En la primera versión, escribí blobs en archivos y le pedí al git que creara un índice en el directorio de trabajo. Sin embargo, este método no resultó muy productivo. Todavía hay 20.000 confirmaciones y cada una debe confirmarse nuevamente. Por tanto, el rendimiento importa mucho. Una pequeña investigación sobre los aspectos internos de GitPython me llevó a la clase gitdb.LooseObjectDB , que permite el acceso directo a los objetos del repositorio de git. Con él, los blobs y árboles (y cualquier otro objeto también) de un repositorio se pueden escribir directamente en otro. Una propiedad maravillosa de la base de datos de objetos git es que la dirección de cualquier objeto es un hash de sus datos. Por lo tanto, el mismo blob tendrá la misma dirección, incluso en diferentes repositorios.
secondary_paths = set()
ldb = gitdb.LooseObjectDB(os.path.join(repo.git_dir, 'objects'))
while len(pc_pairs) > 0:
parent, child = pc_pairs.pop()
for c in all_but_last(repo.iter_commits('{}..{}'.format(
parent.trunk_commit, child.trunk_commit), reverse = True)) :
newparents = [new_commits.get(p, p) for p in c.parents]
new_commits[c] = commit_primary(repo, newparents, c, secondary_paths)
newparents = [new_commits.get(p, p) for p in child.trunk_commit.parents]
c = secrepo.commit(child.src_commit)
sc_message = 'secondary commits {}..{} <devonly>'.format(
parent.src_commit, child.src_commit)
scm_details = '\n'.join(
'{}: {}'.format(i.hexsha[:8], textwrap.shorten(i.message, width = 70))
for i in secrepo.iter_commits(
'{}..{}'.format(parent.src_commit, child.src_commit), reverse = True))
sc_message = '\n\n'.join((sc_message, scm_details))
new_commits[child.trunk_commit] = commit_secondary(
repo, newparents, c, secondary_paths, ldb, sc_message)El compromiso funciona en sí mismo:
def commit_primary(repo, parents, c, secondary_paths) :
head_tree = parents[0].tree
repo.index.reset(parents[0])
repo.git.read_tree(c.tree)
for p in secondary_paths :
# primary commits don't change secondary paths, so we'll just read secondary
# paths into index
tree = head_tree.join(p)
repo.git.read_tree('--prefix', p, tree)
return repo.index.commit(c.message, author=c.author, committer=c.committer
, parent_commits = parents
, author_date=git_author_date(c)
, commit_date=git_commit_date(c))
def commit_secondary(repo, parents, sec_commit, sec_paths, ldb, message):
repo.index.reset(parents[0])
if len(sec_paths) > 0 :
repo.index.remove(sec_paths, r=True, force = True, ignore_unmatch = True)
for o in sec_commit.tree.traverse() :
if not ldb.has_object(o.binsha) :
ldb.store(gitdb.IStream(o.type, o.size, o.data_stream))
if o.path.find(os.sep) < 0 and o.type == 'tree': # a package root
repo.git.read_tree('--prefix', path, tree)
sec_paths.add(p)
return repo.index.commit(message, author=sec_commit.author
, committer=sec_commit.committer
, parent_commits=parents
, author_date=git_author_date(sec_commit)
, commit_date=git_commit_date(sec_commit))
Como puede ver, las confirmaciones del repositorio secundario se agregan de forma masiva. Al principio, me aseguré de que se agregaran confirmaciones individuales, pero (¡de repente!) Resultó que a veces una confirmación de clave más nueva contiene una versión anterior del repositorio secundario (en otras palabras, la versión se revierte). En tal situación, el método iter_commit pasa y devuelve una lista vacía. Como resultado, el repositorio es incorrecto. Por lo tanto, solo tuve que confirmar la versión actual.
La historia de la aparición del generador all_but_last es interesante. Omití la descripción, pero hace exactamente lo que esperas. Al principio solo había un desafío
repo.iter_commits('{}..{}^'.format(parent.trunk_commit, child.trunk_commit), reverse = True)En general, todo terminó bien. El guión completo cabía en 300 líneas y se ejecutó en aproximadamente 6 horas. Moraleja: GitPython es conveniente para hacer todo tipo de cosas interesantes con los repositorios, pero es mejor tratar la deuda técnica de manera oportuna.