Continuamos con una serie de artículos sobre moderación de contenido en los sitios del Centro de Desarrollo de Tecnologías Financieras del Banco Agrícola Ruso. En el último artículo hablamos de cómo solucionamos el problema de la moderación de texto para uno de los sitios del ecosistema para agricultores "Cultivo propio" . Puede leer un poco sobre el sitio en sí y el resultado que obtuvimos aquí .
En resumen, usamos un conjunto de un clasificador ingenuo (filtrar por diccionario) y BERT. A los textos que pasaron el filtro del diccionario se les permitió ingresar al BERT, donde también fueron revisados.
Y nosotros, junto con el Laboratorio MIPT, seguimos mejorando nuestro sitio, poniéndonos una tarea más difícil de pre-moderación de información gráfica. Esta tarea resultó ser más difícil que la anterior, ya que al procesar un lenguaje natural, se puede prescindir de utilizar modelos de redes neuronales. Con las imágenes, todo es más complicado: la mayoría de las tareas se resuelven mediante redes neuronales y la selección de su arquitectura correcta. Pero con esta tarea, como nos parece, ¡la hemos afrontado bien! Y lo que obtuvimos de esto, sigue leyendo.

¿Lo que nosotros queremos?
¡Entonces vamos! Definamos inmediatamente qué debería ser una herramienta de moderación de imágenes. Por analogía con la herramienta de moderación de texto, debería ser una especie de "caja negra". Al enviar una imagen cargada por los vendedores de productos al sitio como entrada, nos gustaría entender cómo esta imagen es aceptable para su publicación en el sitio. Por lo tanto, tenemos la tarea: determinar si la imagen es adecuada para su publicación en el sitio o no.
La tarea de moderar previamente las imágenes es común, pero la solución a menudo difiere de un sitio a otro. Por lo tanto, las imágenes de órganos internos pueden ser aceptables para foros médicos, pero no adecuadas para redes sociales. O, por ejemplo, las imágenes de cadáveres de animales cortados son aceptables en un sitio web donde se venden, pero es poco probable que les gusten a los niños que se conectan a Internet para ver Smesharikov. En cuanto a nuestro sitio, las imágenes de productos agrícolas (verduras / frutas, alimentos para animales, fertilizantes, etc.) serían aceptables para él. Por otro lado, es obvio que el tema de nuestro mercado no implica la presencia de imágenes con contenido obsceno u ofensivo variado.
Para empezar, decidimos familiarizarnos con las soluciones ya conocidas al problema e intentar adaptarlas a nuestro sitio. Por regla general, muchas tareas de moderación de contenido gráfico se reducen a resolver problemas de la clase NSFW , para los que existe un conjunto de datos de dominio público.
Para resolver problemas de NSFW, por regla general, se utilizan clasificadores basados en ResNet, que muestran una precisión de calidad> 93%.
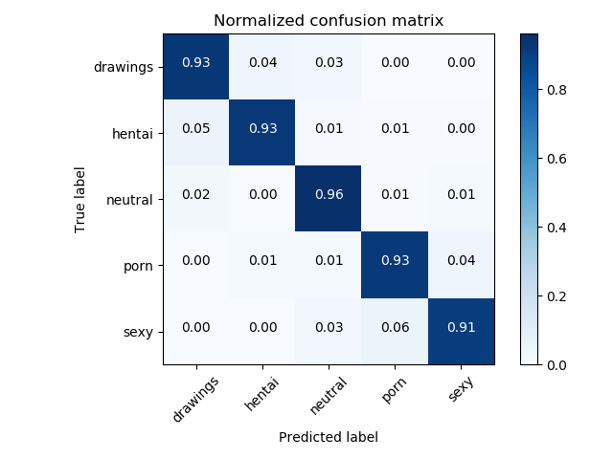
Matriz de errores del clasificador NSFW original
Ok, digamos que tenemos un buen modelo y un conjunto de datos listo para usar para NSFW, pero ¿será esto suficiente para determinar la aceptabilidad de la imagen para el sitio? Resultó que no. Después de discutir este enfoque inicial con el modelo NSFW con los propietarios de nuestro sitio, nos dimos cuenta de que es necesario definir un poco más de categorías, a saber:
- ( , )
- ( , , , . )
- ( )
Es decir, todavía teníamos que componer nuestro propio conjunto de datos y pensar en qué otros modelos podrían ser útiles.
Aquí es donde nos encontramos con un problema común de aprendizaje automático: la falta de datos. Se debe al hecho de que nuestro sitio fue creado no hace mucho tiempo, y no hay ejemplos negativos en él, es decir, marcado como inaceptable. Para solucionarlo, el método de aprendizaje de pocos disparos viene en nuestra ayuda . La esencia de este método es que podemos reentrenar, por ejemplo, ResNet en pequeños conjuntos de datos que reunimos y obtener una precisión mayor que si hiciéramos un clasificador desde cero y solo usando nuestro pequeño conjunto de datos.
¿Cómo lo hiciste?
A continuación se muestra un esquema general de nuestra solución, comenzando desde la imagen de entrada y terminando con el resultado de detectar varias categorías, si se alimenta una imagen de Apple a la entrada.

Esquema general de la solución
Consideremos cada parte del esquema con más detalle.
Etapa 1: detector de graffiti
Esperamos que los productos con texto en los paquetes se carguen en nuestro sitio y, en consecuencia, surge la tarea de detectar inscripciones e identificar su significado.
En la primera etapa, usamos la biblioteca OpenCV Text Detection para encontrar las etiquetas en los paquetes.
OpenCV Text Detection es una herramienta de reconocimiento óptico de caracteres (OCR) para Python. Es decir, reconoce y "lee" texto incrustado en imágenes.

Ejemplo de funcionamiento del detector EAST
Puedes ver un ejemplo de detección de inscripciones en la foto. Para identificar el cuadro delimitador, usamos el modelo EAST, pero aquí el lector puede sentir una trampa, ya que este modelo está entrenado para reconocer textos en inglés, y en nuestras imágenes los textos están en ruso. Por eso, además, se utiliza un modelo de clasificación binario (graffiti / no graffiti) basado en ResNet, que ha sido entrenado con la calidad requerida en nuestros datos. Tomamos ResNet-18, ya que este modelo demostró ser el mejor a la hora de elegir una arquitectura.
En nuestra tarea, nos gustaría distinguir las fotos donde las inscripciones son inscripciones en el empaque de productos de los grafitis. Por lo tanto, decidimos dividir todas las fotos con texto en dos clases: graffiti y no graffiti. La
precisión del modelo obtenido fue del 95% en una muestra predispuesta:
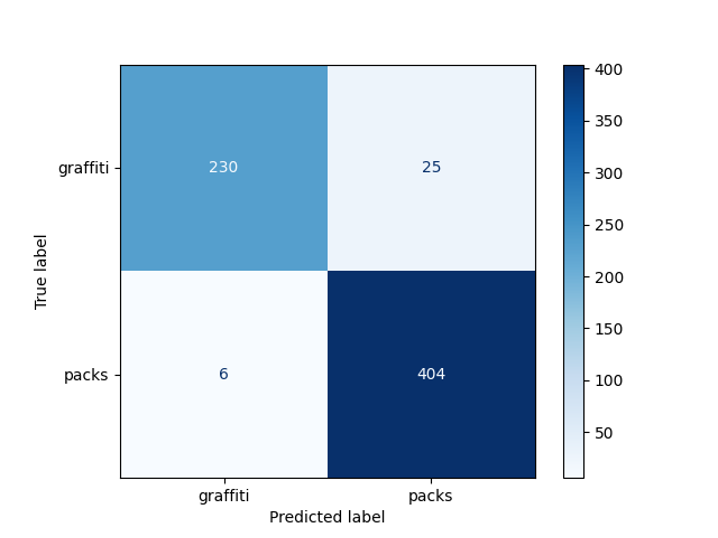
Matriz de errores del detector de graffiti ¡
Nada mal! Ahora podemos aislar el texto en la foto y con una buena probabilidad de entender si es adecuado para su publicación. Pero, ¿y si no hay texto en la foto?
Etapa 2: detector NSFW
Si no encontramos texto en la imagen, esto no significa que sea inaceptable, por lo tanto, a continuación queremos evaluar cómo el contenido de la imagen se corresponde con la temática del sitio.
En esta etapa, la tarea es asignar la imagen a una de las categorías:
- drogas
- porno (porno)
- animales
- fotos que pueden causar rechazo (incluidos dibujos) (gore / drawing_gore)
- hentai (hentai)
- imágenes neutrales (neutral)
Es importante que el modelo devuelva no solo la categoría, sino también el grado de confianza de los algoritmos en ella.
Se utilizó un modelo basado en NSFW para la clasificación. Está entrenada de tal manera que divide la foto en 7 clases y solo una de ellas esperamos ver en el sitio. Por tanto, solo dejamos fotos neutrales.
El resultado de tal modelo es 97% (en términos de precisión)

matriz de error del detector NSFW
Etapa 3: detector de personas
Pero incluso después de haber aprendido a filtrar NSFW, el problema aún no se puede considerar resuelto. Por ejemplo, una foto de una persona no entra en la categoría NSFW ni en la categoría de foto con texto, pero tampoco nos gustaría ver esas imágenes en el sitio. Luego agregamos a nuestra arquitectura un modelo de detección humana: Detector de disparo único (en adelante, SSD).
La selección de personas o algún otro objeto previamente conocido también es una tarea popular con una amplia gama de aplicaciones. Usamos el modelo nvidia_ssd listo para usar de pytorch.

Un ejemplo del algoritmo SSD
Los resultados del modelo son más bajos (precisión - 96%):

Matriz de errores del detector humano
resultados
Evaluamos la calidad de nuestro instrumento utilizando métricas ponderadas de F1, Precisión y Recuperación. Los resultados se presentan en la tabla:
| Métrica | Precisión obtenida |
| F1 ponderado | 0,96 |
| Precisión ponderada | 0,96 |
| Recuperación ponderada | 0,96 |
Y aquí hay algunos ejemplos más ilustrativos de su trabajo:
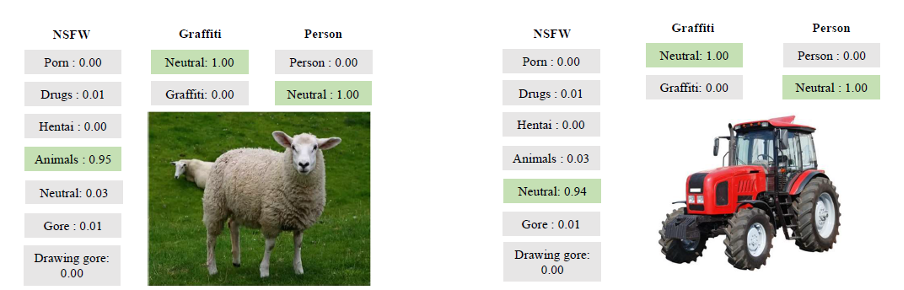
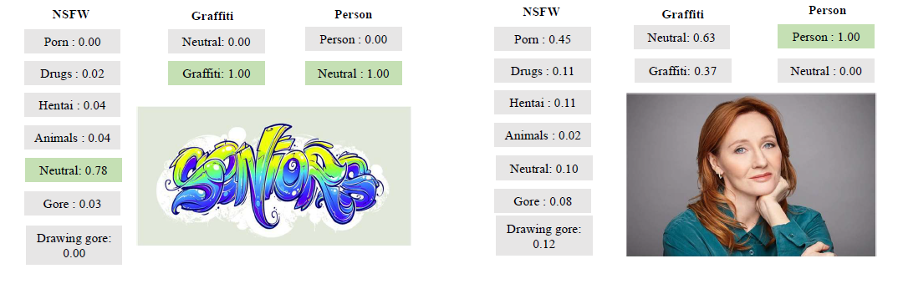
Ejemplos de la herramienta
Conclusión
En el proceso de resolución, usamos todo un "zoológico" de modelos que a menudo se usan para tareas de visión por computadora. Aprendimos a "leer" texto de fotos, encontrar personas y distinguir contenido inapropiado.
Finalmente, me gustaría señalar que el problema considerado es útil desde el punto de vista de la adquisición de experiencia y el uso de modelos clásicos modificados. Estas son algunas de las ideas que obtuvimos:
- Puede solucionar el problema de la escasez de datos utilizando el método de aprendizaje de pocos disparos: los modelos grandes se pueden entrenar con la precisión requerida en sus propios datos
- : ,
- , ,
- , , . , , ,
- A pesar de que la tarea de moderación de imágenes es bastante popular, su solución, como en el caso de los textos, puede diferir de un sitio a otro, ya que cada uno de ellos está diseñado para una audiencia diferente. En nuestro caso, por ejemplo, además de contenido inapropiado, también detectamos animales y personas
¡Gracias por su atención y nos vemos en el próximo artículo!