Hoy tenemos una conversación física y técnica con Mikhail Burtsev , el jefe del laboratorio de redes neuronales del MIPT. Sus intereses de investigación incluyen modelos de aprendizaje de redes neuronales, sistemas neurocognitivos y neurohíbridos, la evolución de sistemas adaptativos y algoritmos evolutivos, neurocontroladores y robótica. Todo esto se discutirá.

- ¿Cómo empezó la historia del Laboratorio de Redes Neuronales y Deep Learning en Phystech?
- En 2015, participé en una iniciativa de la Agencia de Iniciativas Estratégicas (ASI) llamada "Flota de prospectiva": esta es una plataforma de varios días para la discusión en el marco de la Iniciativa Técnica Nacional. El tema clave fueron las tecnologías que deben desarrollarse para que las empresas aparezcan en Rusia con el potencial de tomar posiciones de liderazgo en los mercados globales. El mensaje principal fue que es extremadamente difícil ingresar a los mercados formados, pero las tecnologías abren nuevos territorios y nuevos mercados, y es precisamente en ellos donde debemos ingresar.
Entonces navegamos en un barco a motor a lo largo del Volga y discutimos qué tecnologías podrían ayudar a crear tales mercados y romper las barreras tecnológicas actuales. Y en esta discusión sobre el futuro, ha crecido el tema con los asistentes personales. Está claro que ya hemos comenzado a usarlos: Alexa, Alice, Siri ... y era obvio que existen barreras técnicas en el entendimiento entre humanos y computadoras. Por otro lado, se han acumulado muchos desarrollos de investigación, por ejemplo en el campo del aprendizaje por refuerzo, en el procesamiento del lenguaje natural. Y quedó claro: muchas tareas difíciles se están resolviendo cada vez mejor con la ayuda de las redes neuronales.
Y solo estaba investigando sobre algoritmos de redes neuronales. Basándonos en los resultados de las discusiones de la Flota Foresight, formulamos el concepto de un proyecto de desarrollo tecnológico para el futuro cercano, que luego se transformó en el proyecto iPavlov. Este fue el comienzo de mi interacción con Phystech.
Con más detalle, hemos formulado tres tareas. Infraestructura: creación de una biblioteca abierta para realizar diálogos con el usuario. El segundo es realizar investigaciones sobre el procesamiento del lenguaje natural. Más la solución de problemas empresariales específicos .
Sberbank actuó como socio y el proyecto en sí se formó bajo el ala de la Iniciativa Técnica Nacional.
, 2015 -: deephack.me — , , - , . Open Data Science.
A principios de 2018, publicamos el primer repositorio de nuestra biblioteca abierta DeepPavlov, y en los últimos dos años hemos visto un aumento constante de sus usuarios (se centra en ruso e inglés): tenemos alrededor del 50% de las instalaciones de EE. UU., 20-30% de Rusia. En general, resultó ser un proyecto de código abierto bastante exitoso.
No solo estamos desarrollando, sino también tratando de contribuir a la agenda de investigación global sobre IA conversacional. Al darnos cuenta de la necesidad de competencia académica en esta área, lanzamos la serie Conversational AI Challenges como parte de NeuIPS, la conferencia líder en aprendizaje automático.
Además, no solo organizamos concursos, sino que también participamos. Entonces, el equipo de nuestro laboratorio participó el año pasado en una competencia de Amazon llamada Premio Alexa, creando un chat bot con el que una persona estaría interesada en hablar durante 20 minutos.
La próxima competencia comenzará en noviembre.
Se trata de una competencia universitaria, y el núcleo de los participantes estaba formado por estudiantes y personal universitario. Había 350 equipos en total, siete fueron seleccionados para la cima y tres fueron invitados en base a los resultados del año pasado; hemos llegado a la cima.
Nuestro sistema de diálogo realizó alrededor de 100 mil diálogos con usuarios en los Estados Unidos y al final tuvo una calificación de alrededor de 3.35-3.4 sobre 5, lo cual es bastante bueno. Esto sugiere que logramos formar un equipo de clase mundial en MIPT en un tiempo bastante corto.
Ahora el laboratorio está llevando a cabo proyectos con diferentes empresas, entre las grandes se encuentran Huawei y Sberbank. Proyectos en diferentes direcciones: AutoML, teoría de redes neuronales y, por supuesto, nuestra dirección principal - PNL.
- Sobre las tareas que solían ser difíciles para el aprendizaje automático: ¿por qué despegó el aprendizaje profundo para resolver estos problemas?
- Difícil de decir. Ahora describiré mi intuición de una manera ligeramente simplificada. La cuestión es que si el modelo tiene muchos parámetros, sorprendentemente puede generalizar bien los resultados a nuevos datos. En el sentido de que el número de parámetros puede ser acorde con el número de ejemplos. Por la misma razón, el aprendizaje automático clásico ha resistido durante mucho tiempo la presión de las redes neuronales; parece que no debería salir nada bueno en esta situación.
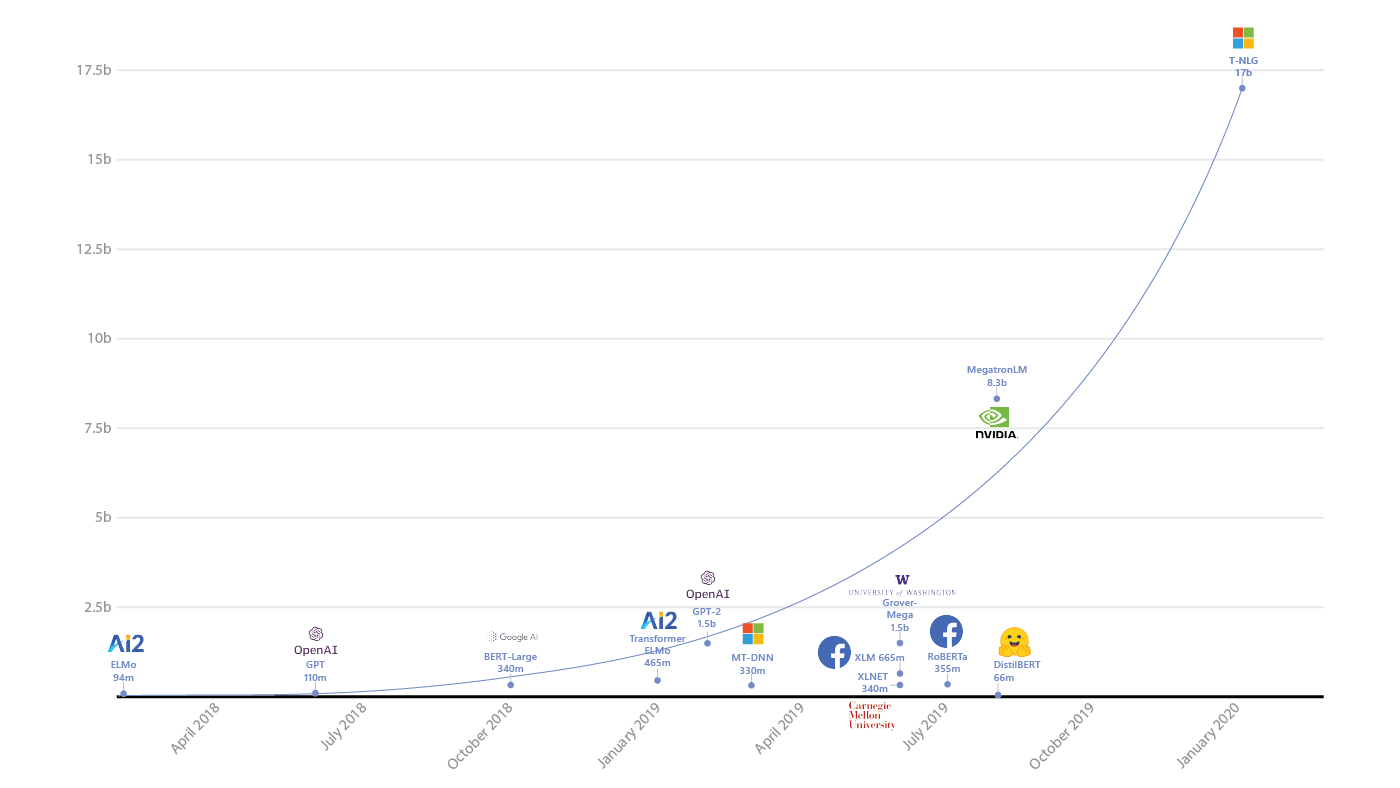
El aumento de parámetros en los modelos de aprendizaje profundo ( fuente )
Sorprendentemente, este no es el caso. Ivan Skorokhodov de nuestro laboratorio mostró ( .pdf ) que casi cualquier patrón bidimensional se puede encontrar en el espacio de la función de pérdida de la red neuronal.
Puede elegir un plano de modo que cada punto de este plano corresponda a un conjunto de parámetros de la red neuronal. Y su pérdida corresponderá a un patrón arbitrario y, en consecuencia, puede captar redes neuronales tales que caerán directamente en esta imagen.
Un resultado muy divertido. Esto sugiere que incluso con restricciones tan absurdas, la red neuronal puede aprender la tarea que se le asigna. Ese es el tipo de intuición aquí, sí.

Ejemplos de patrones del artículo de Ivan Skorokhodov.
- En los últimos años se ha notado un avance significativo en el campo del aprendizaje profundo, pero ¿ya se vislumbra el horizonte donde nos hundiremos en el límite de los indicadores?

El crecimiento del tamaño de los modelos de IA y los recursos que consumen (fuente: openai.com/blog/ai-and-compute/ )
- En PNL, el límite aún no se siente, aunque parece que, por ejemplo, en el aprendizaje por refuerzo, algo ya ha comenzado resbalón. Es decir, no ha habido cambios cualitativos en los últimos dos años. Hubo un gran auge de Atari a AlphaGo con la hibridación con Monte Carlo Tree Search, pero ahora no hay un avance directo.
Pero en la PNL es al revés: redes recurrentes, redes convolucionales y, finalmente, la arquitectura del transformador y la propia GPT ( uno de los modelos de transformador más nuevos e interesantes, a menudo utilizado para generar textos - nota del autor) Es ya un desarrollo puramente extenso. Y luego parece que aún queda margen para lograr algo nuevo. Por lo tanto, en PNL, la barra de arriba aún no es visible. Aunque, por supuesto, es casi imposible predecir nada aquí.
- Si imaginamos el desarrollo de lenguajes y marcos para el aprendizaje automático, entonces pasamos de escribir (condicionalmente) en puro numpy, scikit-learn a tensorflow, keras: los niveles de abstracción crecieron. ¿Qué sigue para nosotros?
— , : - . , , low level high level code: numpy . , , NLP : .
- Tensorflow / Pytorch — : .
- : NLP- — DeepPavlov.
- : — DeepPavlov Dream .
- Un sistema para cambiar entre habilidades / canalizaciones, incluido nuestro agente DeepPavlov.
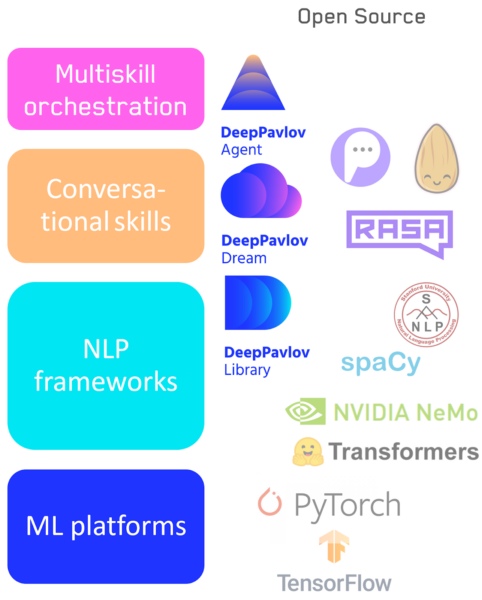
Pila de tecnología de IA conversacional
Las diferentes aplicaciones y tareas requieren una flexibilidad de herramientas diferente y, por lo tanto, no creo que ningún elemento de esta jerarquía desaparezca. Tanto los sistemas de bajo nivel como los de alto nivel evolucionarán cuando sea necesario. Por ejemplo, las bibliotecas visuales que no están disponibles para los programadores, pero también las bibliotecas de bajo nivel para los desarrolladores, no irán a ninguna parte.
- ¿Se están llevando a cabo ahora experimentos sociales por analogía con el clásico test de Turing, donde las personas deben entender si una red neuronal está frente a ellos o una persona?
- Estos experimentos se llevan a cabo con regularidad. En el Alexa Challenge, una persona tenía que evaluar la calidad de una conversación, mientras que no sabía con quién estaba hablando: un bot o una persona. Hasta ahora, desde el punto de vista de una conversación en vivo, la diferencia entre una máquina y una persona es significativa, pero está disminuyendo cada año. Por cierto, nuestro artículo sobre esto acaba de publicarse en AI Magazine.
Fuera de la comunidad científica, esto se hace con regularidad. Recientemente, alguien entrenó a una modelo de GPT, creó una cuenta de Twitter para ella y comenzó a publicar respuestas. Mucha gente se registró, la cuenta ganó popularidad y nadie sabía que era una red neuronal.
Un formato tan corto, como en Twitter, cuando las formulaciones son generales y "profundas", se adapta bien al sistema de inferencia de redes neuronales.
- ¿Qué áreas consideras más prometedoras, dónde esperar un salto?
- ( Risas .) Podría decir que es en la unificación de todas mis direcciones favoritas donde habrá un salto. Intentaré describir con más detalle en el marco de la problematización. Tenemos los modelos GPT basados en transformadores de corriente: no tienen ningún propósito en la vida, solo generan texto similar al humano, completamente sin objetivo. Y no pueden vincularlo a la situación y los objetivos en el contexto del mundo mismo.
Y una de las formas es crear un vínculo de una visión lógica del mundo a GPT, que ha leído mucho, mucho texto, y en él hay, de hecho, muchas conexiones lógicas. Por ejemplo, mediante la hibridación con Wikidata (este es un gráfico que describe el conocimiento sobre el mundo, en la parte superior se encuentran los artículos de Wikipedia).
Si pudiéramos conectar los dos para que GPT pueda utilizar la base de conocimientos, sería un salto adelante.
El segundo enfoque al problema de la falta de objetivo de los modelos de PNL se basa en la integración de la comprensión de los objetivos humanos en ellos. Si tenemos un modelo que puede impulsar un modelo de lenguaje generativo vinculado a un gráfico de conocimiento, entonces podríamos entrenarlo para ayudar a una persona a lograr sus objetivos. Y dicho asistente debe comprender a la persona a través de la PNL, los objetivos de la persona y la situación; luego, debe planificar acciones. Y en la planificación, el aprendizaje por refuerzo funciona mejor.
Cómo combinar y optimizar todo esto es una cuestión abierta.
Y el último es la búsqueda de arquitecturas de redes neuronales. Cuando, por ejemplo, utilizamos enfoques evolutivos, buscamos en el espacio de arquitecturas que sean óptimas para una tarea determinada. Pero todo esto no se decidirá hoy, hay demasiado espacio para buscar.
De la buena noticia: el hardware está evolucionando muy rápidamente y, quizás, esto nos permitirá en 5-10 años combinar modelos de lenguaje de redes neuronales, gráficos de conocimiento y aprendizaje por refuerzo. Y entonces daremos un salto cuántico en la comprensión del hombre por parte de la máquina.
Con la ayuda de dicho asistente, será posible lanzar la solución de otras tareas: análisis de imágenes, análisis de registros médicos o la situación económica, selección de bienes.
Por lo tanto, diría que desde un punto de vista científico, en los próximos cinco años veremos un rápido desarrollo en el campo de la hibridación; hay muchas tareas interesantes.
Chicos, la escasez de personal será enorme y existe una gran posibilidad de obtener resultados nuevos e interesantes, y también de influir en el desarrollo de la industria. Conéctese, ¡necesita aprovechar el momento!( El autor apoya activamente esta respuesta, porque se ocupa precisamente de esos sistemas ) .
- ¿Cómo empezar a bucear en el aprendizaje profundo?
- La forma más fácil, me parece, es tomar un curso en una escuela de aprendizaje profundo : inicialmente estaba destinado a estudiantes de secundaria, pero será bastante adecuado para estudiantes. En general, esta es una gran empresa, ayudé con la programación y di conferencias introductorias allí.
También recomiendo ver los cursos introductorios de las universidades, hacer tareas; hay muchas cosas en Internet. La mejor de todas las herramientas para "jugar" es Colab de Google, hay millones de ejemplos de tareas, puede resolverlo y ejecutar las soluciones más modernas, sin instalar ningún software en su computadora.
Otra forma es competir en Kaggle. Y también únete a Open Data Science, una comunidad de habla rusa para la ciencia de datos, donde existen varios canales de aprendizaje profundo. Siempre hay personas que están listas para ayudar con consejos y códigos.
Éstas son las formas principales.
ID de líder : amigos, para la selección ahora lanzada para el acelerador para la promoción de proyectos de IA, hemos pensado una opción de inicio de sesión para desarrolladores independientes. No, esto no cambia las condiciones básicas bajo las cuales solo los equipos participan en el intensivo. Pero tenemos muchas preguntas de personas que no tienen su propio proyecto ahora, pero quieren participar (y estos no son solo programadores, los diseñadores tienen un gran interés en los proyectos de IA). Y encontramos una solución: ayudaremos a reunir un equipo y personas de ideas afines a través de un hackatón en línea gratuito . Comenzará el 10 de octubre a las 12:00 y finalizará exactamente un día después. En él, el bot lo distribuirá en equipos y luego, bajo su liderazgo, pasará por las principales etapas del desarrollo del proyecto y lo enviará al Archipiélago 20.35. Todos los detalles están en su cuenta personal, solo necesita registrarse a tiempo.