
Nuestro mundo genera cada vez más información. Una parte es fugaz y se pierde tan rápido como se recoge. El otro debería almacenarse por más tiempo, mientras que el otro está diseñado "para siglos", al menos así es como lo vemos desde el presente. Los flujos de información se instalan en los centros de datos a tal velocidad que cualquier enfoque nuevo, cualquier tecnología diseñada para satisfacer esta "demanda" interminable se está volviendo rápidamente obsoleta.
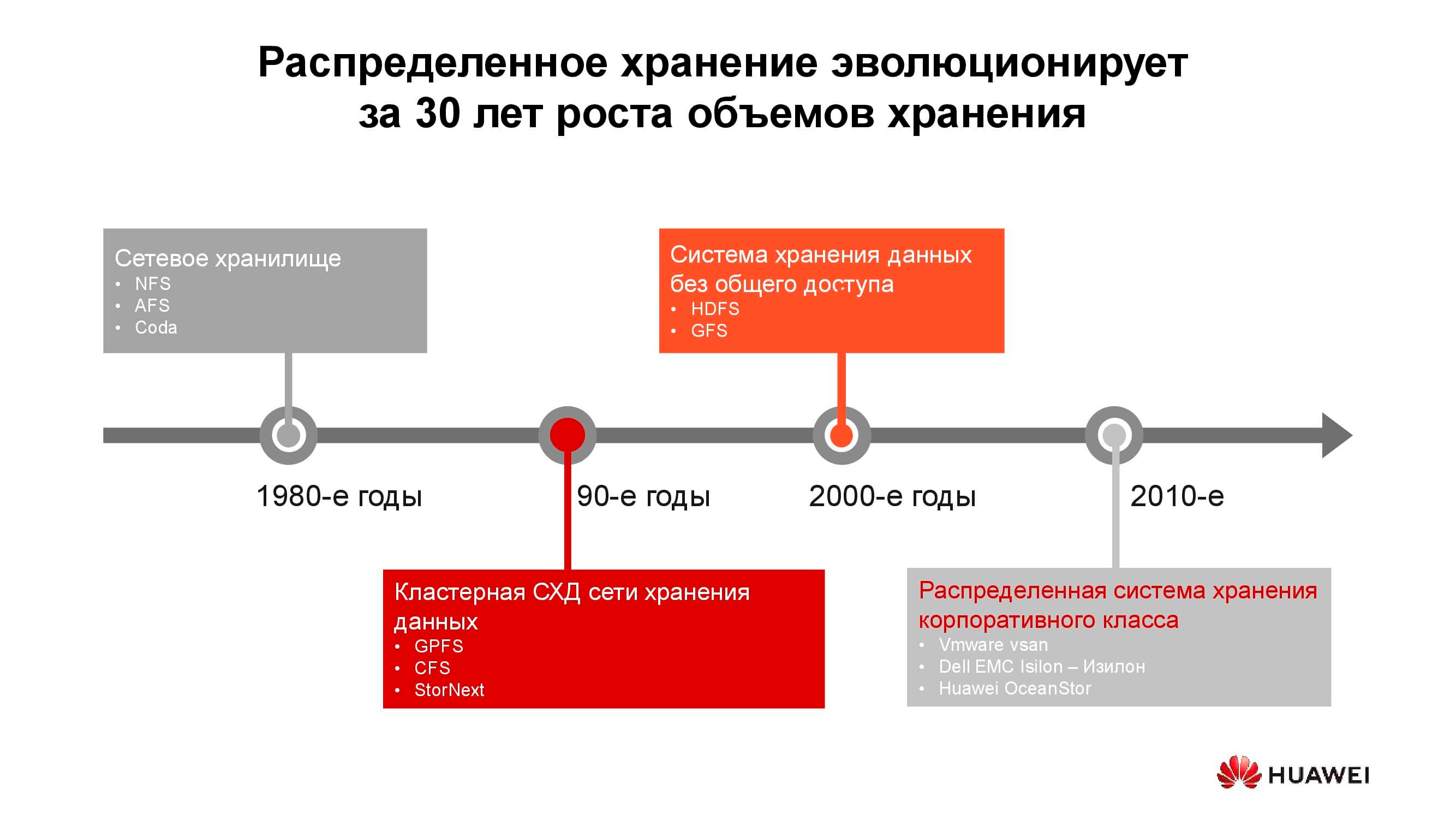
40 años de desarrollo de sistemas de almacenamiento distribuido
Los primeros almacenamientos conectados a la red aparecieron en la forma habitual en la década de 1980. Muchos de ustedes se han encontrado con NFS (Network File System), AFS (Andrew File System) o Coda. Una década más tarde, la moda y la tecnología han cambiado, y los sistemas de archivos distribuidos han dado paso a los sistemas de almacenamiento en clúster basados en GPFS (General Parallel File System), CFS (Clustered File Systems) y StorNext. Como base, se utilizaron almacenamientos en bloque de arquitectura clásica, sobre los cuales se creó un único sistema de archivos utilizando una capa de software. Estas y otras soluciones similares todavía están en uso, ocupan su propio nicho y tienen una gran demanda.
Con el cambio de milenio, el paradigma del almacenamiento distribuido cambió un poco y los sistemas con la arquitectura SN (Shared-Nothing) tomaron la iniciativa. Hubo una transición del almacenamiento en clúster al almacenamiento en nodos separados, que, por regla general, eran servidores clásicos con software que proporciona un almacenamiento confiable; sobre tales principios se construyen, digamos, HDFS (Hadoop Distributed File System) y GFS (Global File System).
Más cerca de la década de 2010, los conceptos detrás del almacenamiento distribuido se reflejan cada vez más en productos comerciales completos como VMware vSAN, Dell EMC Isilon y nuestro Huawei OceanStor.... Detrás de las plataformas mencionadas ya no hay una comunidad de entusiastas, sino proveedores específicos que son responsables de la funcionalidad, soporte, servicio del producto y garantizan su posterior desarrollo. Estas soluciones son las más solicitadas en varias áreas.
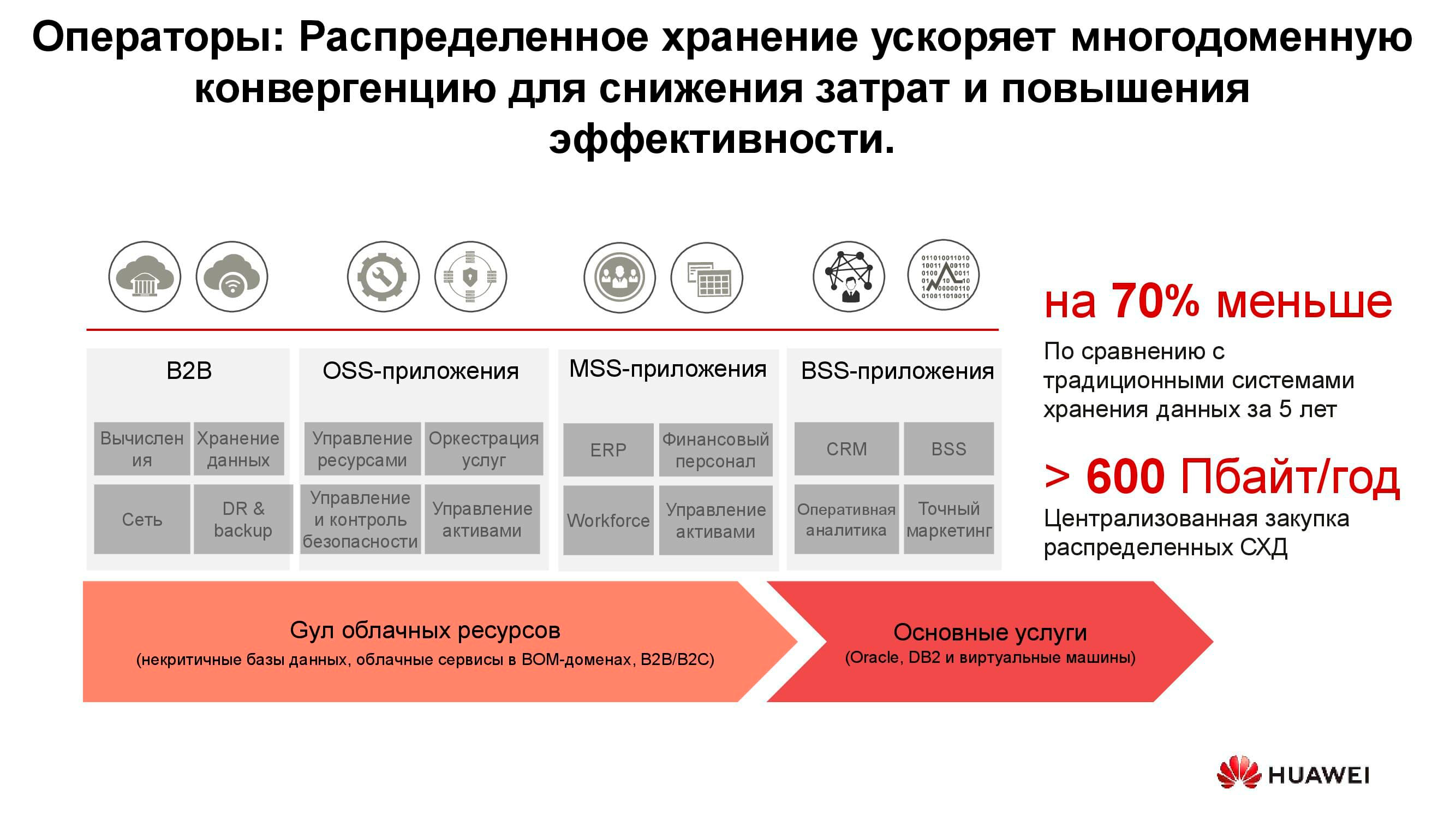
Operadores de telecomunicaciones
Quizás uno de los consumidores más antiguos de sistemas de almacenamiento distribuido son los operadores de telecomunicaciones. El diagrama muestra qué grupos de aplicaciones producen la mayor parte de los datos. OSS (Operations Support Systems), MSS (Management Support Services) y BSS (Business Support Systems) son tres capas de software complementarias necesarias para proporcionar servicio a los suscriptores, informes financieros al proveedor y soporte operativo a los ingenieros del operador.
A menudo, los datos de estas capas están fuertemente mezclados entre sí, y para evitar la acumulación de copias innecesarias, se utilizan almacenamientos distribuidos, que acumulan toda la cantidad de información proveniente de la red de trabajo. Los almacenamientos se combinan en un pool común, al que se refieren todos los servicios.
Nuestros cálculos muestran que la transición de los sistemas de almacenamiento clásicos a los sistemas de almacenamiento en bloque le permite ahorrar hasta un 70% del presupuesto solo eliminando los sistemas de almacenamiento dedicados de la clase alta y utilizando servidores convencionales de arquitectura clásica (generalmente x86) que trabajan en conjunto con software especializado. Los operadores de telefonía móvil han comenzado a adquirir este tipo de soluciones en grandes volúmenes. En particular, los operadores rusos han estado utilizando este tipo de productos de Huawei durante más de seis años.
Sí, una serie de tareas no se pueden realizar mediante sistemas distribuidos. Por ejemplo, con mayores requisitos de rendimiento o compatibilidad con protocolos más antiguos. Pero al menos el 70% de los datos que procesa el operador pueden ubicarse en un grupo distribuido.
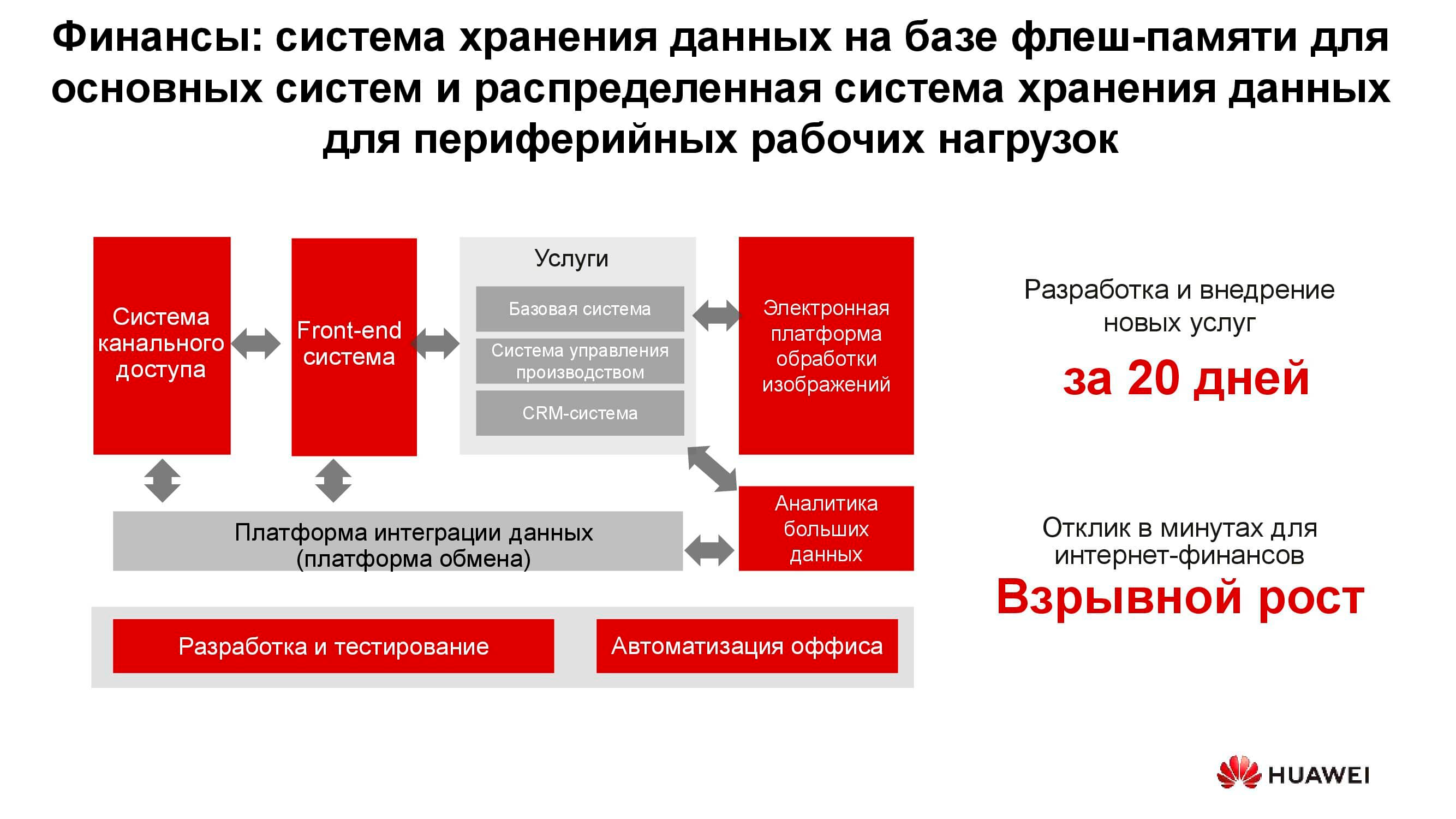
Sector bancario
En cualquier banco, existen muchos sistemas de TI diferentes, desde el procesamiento hasta un sistema bancario automatizado. Esta infraestructura también trabaja con una gran cantidad de información, mientras que la mayoría de las tareas no requieren un mayor rendimiento y confiabilidad de los sistemas de almacenamiento, por ejemplo, desarrollo, pruebas, automatización de procesos de oficina, etc. Aquí, el uso de sistemas de almacenamiento clásicos es posible, pero cada año es cada vez menos rentable. Además, en este caso, no hay flexibilidad para gastar recursos de almacenamiento, cuyo rendimiento se calcula a partir de la carga máxima.
Cuando se utilizan sistemas de almacenamiento distribuidos, sus nodos, que de hecho son servidores normales, se pueden convertir en cualquier momento, por ejemplo, en una granja de servidores y utilizarse como plataforma informática.
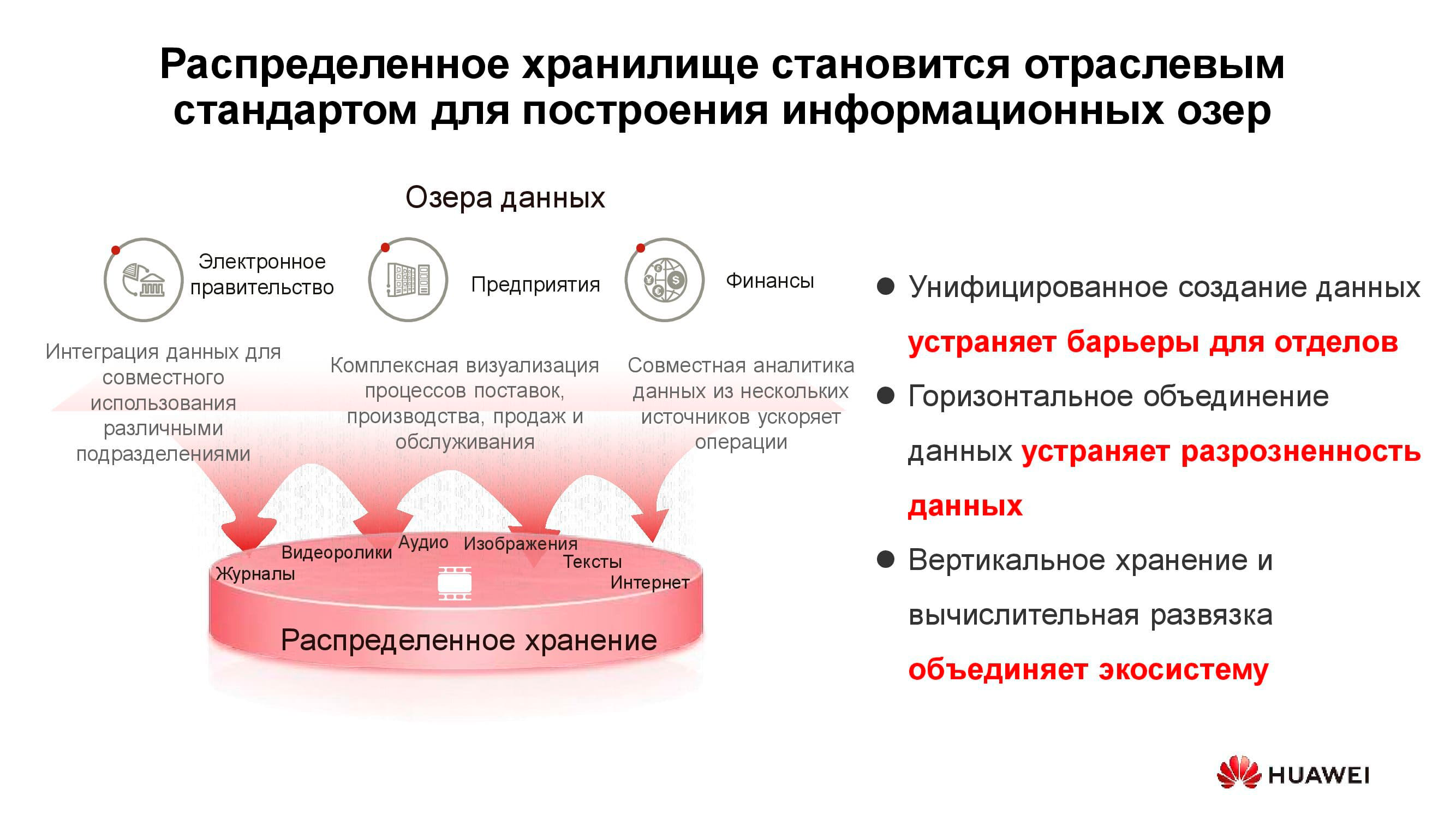
Lagos de datos
El diagrama anterior muestra una lista de consumidores típicos de servicios de lago de datos . Estos pueden ser servicios de gobierno electrónico (por ejemplo, "Gosuslugi"), empresas digitalizadas, estructuras financieras, etc. Todos necesitan trabajar con grandes cantidades de información heterogénea.
El funcionamiento de los sistemas de almacenamiento clásicos para resolver estos problemas es ineficaz, ya que se requiere tanto el acceso de alto rendimiento a las bases de datos de bloques como el acceso regular a las bibliotecas de documentos escaneados almacenados como objetos. Por ejemplo, aquí se puede vincular un sistema de pedidos a través de un portal web. Para implementar todo esto en una plataforma de almacenamiento clásica, necesitará un gran conjunto de equipos para diferentes tareas. Un sistema de almacenamiento universal horizontal bien puede cubrir todas las tareas enumeradas anteriormente: solo necesita crear varios grupos en él con diferentes características de almacenamiento.

Generadores de nueva información
La cantidad de información almacenada en el mundo crece aproximadamente un 30% al año. Esta es una buena noticia para los proveedores de almacenamiento, pero ¿cuál es y será la principal fuente de estos datos?
Hace diez años, las redes sociales se convirtieron en tales generadores, lo que requirió la creación de una gran cantidad de nuevos algoritmos, soluciones de hardware, etc. Ahora hay tres motores principales de crecimiento en los volúmenes de almacenamiento. El primero es la computación en nube. Actualmente, alrededor del 70% de las empresas utilizan los servicios en la nube de una forma u otra. Estos pueden ser sistemas de correo electrónico, copias de seguridad y otras entidades virtualizadas.
El segundo impulsor son las redes de quinta generación. Se trata de nuevas velocidades y nuevos volúmenes de transferencia de datos. Predecimos que la adopción generalizada de 5G conducirá a una caída en la demanda de tarjetas de memoria flash. No importa cuánta memoria haya en el teléfono, todavía se agota, y si hay un canal de 100 megabits en el dispositivo, no es necesario almacenar fotos localmente.
El tercer grupo de razones de la creciente demanda de sistemas de almacenamiento incluye el rápido desarrollo de la inteligencia artificial, la transición a la analítica de big data y la tendencia hacia la automatización universal de todo lo que es posible.
Una característica del "tráfico nuevo" es su falta de estructura... Necesitamos almacenar estos datos sin especificar su formato. Es necesario solo para lecturas posteriores. Por ejemplo, un sistema de puntuación bancaria para determinar el monto del préstamo disponible observará las fotos que publique en las redes sociales, determinando si visita con frecuencia el mar y los restaurantes, y al mismo tiempo estudiará los extractos de sus documentos médicos disponibles. Estos datos, por un lado, son globales y, por otro, carecen de uniformidad.

Un océano de datos no estructurados
¿Qué problemas conlleva la aparición de "nuevos datos"? El más importante de ellos, por supuesto, es la cantidad de información en sí y el tiempo de almacenamiento estimado. Un automóvil autónomo moderno sin conductor genera hasta 60 TB de datos todos los días a partir de todos sus sensores y mecanismos. Para desarrollar nuevos algoritmos de movimiento, esta información debe procesarse en el mismo día, de lo contrario comenzará a acumularse. Además, debe almacenarse durante mucho tiempo: decenas de años. Solo entonces, en el futuro, será posible sacar conclusiones basadas en grandes muestras analíticas.
Un dispositivo de secuenciación genética genera alrededor de 6 TB por día. Y los datos recopilados con su ayuda no implican su eliminación en absoluto, es decir, hipotéticamente, deberían almacenarse para siempre.
Finalmente, todas las mismas redes de quinta generación. Además de la información real transmitida, dicha red en sí misma es un gran generador de datos: registros de acciones, registros de llamadas, resultados intermedios de interacciones máquina a máquina, etc.
Todo esto requiere el desarrollo de nuevos enfoques y algoritmos para almacenar y procesar información. Y aparecen esos enfoques.
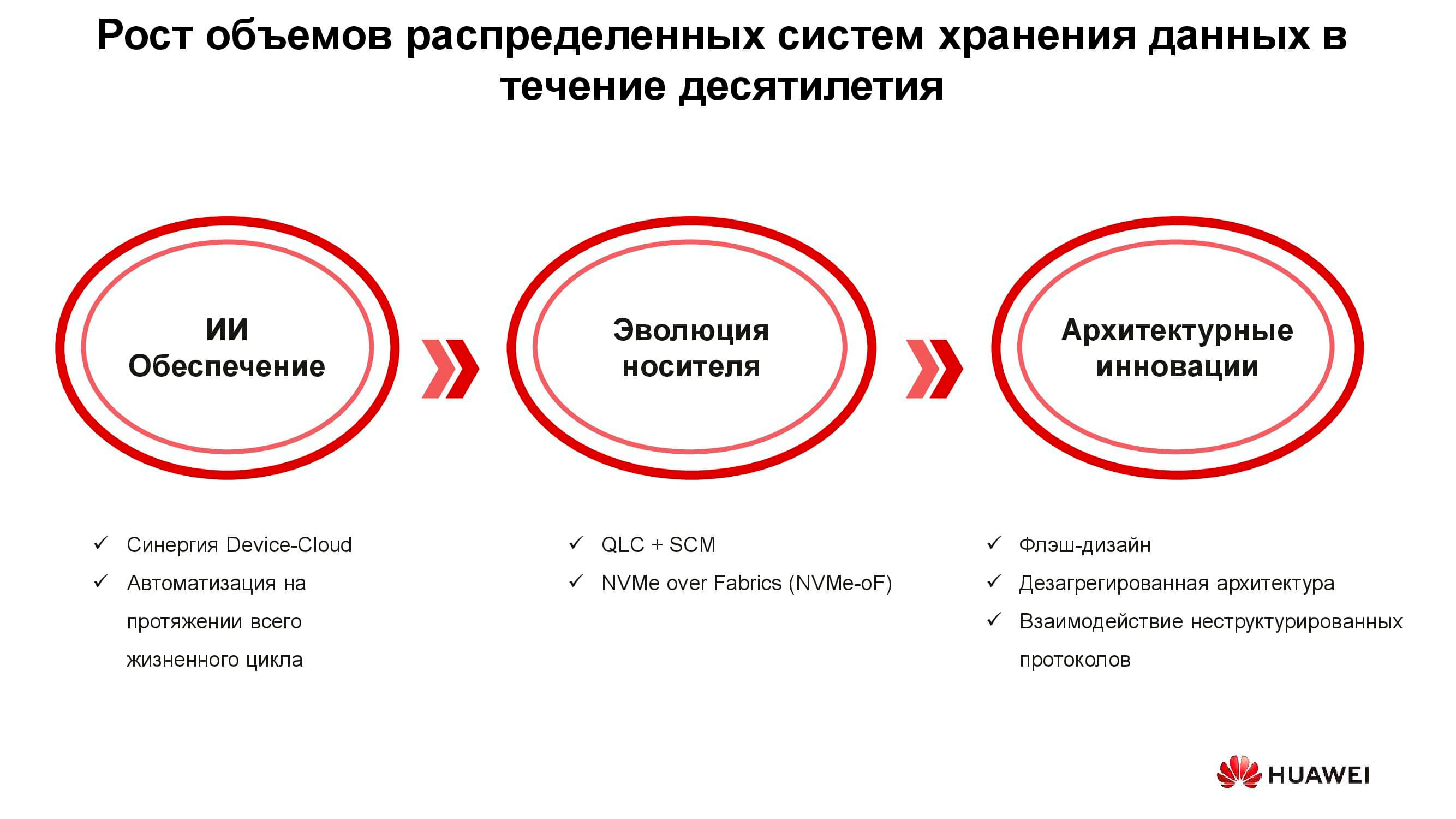
Tecnologías de una nueva era
Hay tres grupos de soluciones diseñadas para hacer frente a los nuevos requisitos de los sistemas de almacenamiento: la introducción de la inteligencia artificial, la evolución técnica de los medios de almacenamiento y las innovaciones en el campo de la arquitectura de sistemas. Comencemos con la IA.

En las nuevas soluciones de Huawei, la inteligencia artificial ya se utiliza a nivel del propio almacenamiento, que está equipado con un procesador de IA que permite al sistema analizar de forma independiente su estado y predecir fallas. Si el sistema de almacenamiento está conectado a una nube de servicios que tiene capacidades computacionales significativas, la inteligencia artificial puede procesar más información y mejorar la precisión de sus hipótesis.
Además de las fallas, dicha IA puede predecir las cargas máximas futuras y el tiempo restante hasta que se agote la capacidad. Esto le permite optimizar el rendimiento y escalar el sistema incluso antes de que ocurran eventos no deseados.

Ahora sobre la evolución de los soportes de datos. Las primeras unidades flash se fabricaron con tecnología SLC (celda de un solo nivel). Los dispositivos basados en él eran rápidos, fiables, estables, pero tenían una capacidad pequeña y eran muy caros. El aumento de volumen y la reducción de precio se logró mediante ciertas concesiones técnicas, por lo que se redujo la velocidad, confiabilidad y vida útil de los variadores. Sin embargo, la tendencia no afectó a los propios sistemas de almacenamiento, que, debido a varios trucos arquitectónicos, en general, se han vuelto más productivos y más confiables.
Pero, ¿por qué necesitaba sistemas de almacenamiento All-Flash? ¿No fue suficiente simplemente reemplazar las viejas unidades de disco duro en un sistema que ya está en uso por nuevas SSD del mismo factor de forma? Se necesitó esto para utilizar de manera eficiente todos los recursos de las nuevas unidades de estado sólido, lo que era simplemente imposible en los sistemas antiguos.
Huawei, por ejemplo, ha desarrollado una gama de tecnologías para abordar este desafío, una de las cuales es FlashLink , que maximiza las interacciones entre el disco y el controlador.
La identificación inteligente ha hecho posible descomponer datos en múltiples flujos y hacer frente a una serie de fenómenos indeseables como WA (amplificación de escritura). Al mismo tiempo, nuevos algoritmos de recuperación, en particular RAID 2.0+, aumentó la velocidad de reconstrucción, reduciendo su tiempo a valores completamente insignificantes.
Fallo, hacinamiento, "recolección de basura": estos factores tampoco afectan el rendimiento del sistema de almacenamiento gracias a una modificación especial de los controladores.
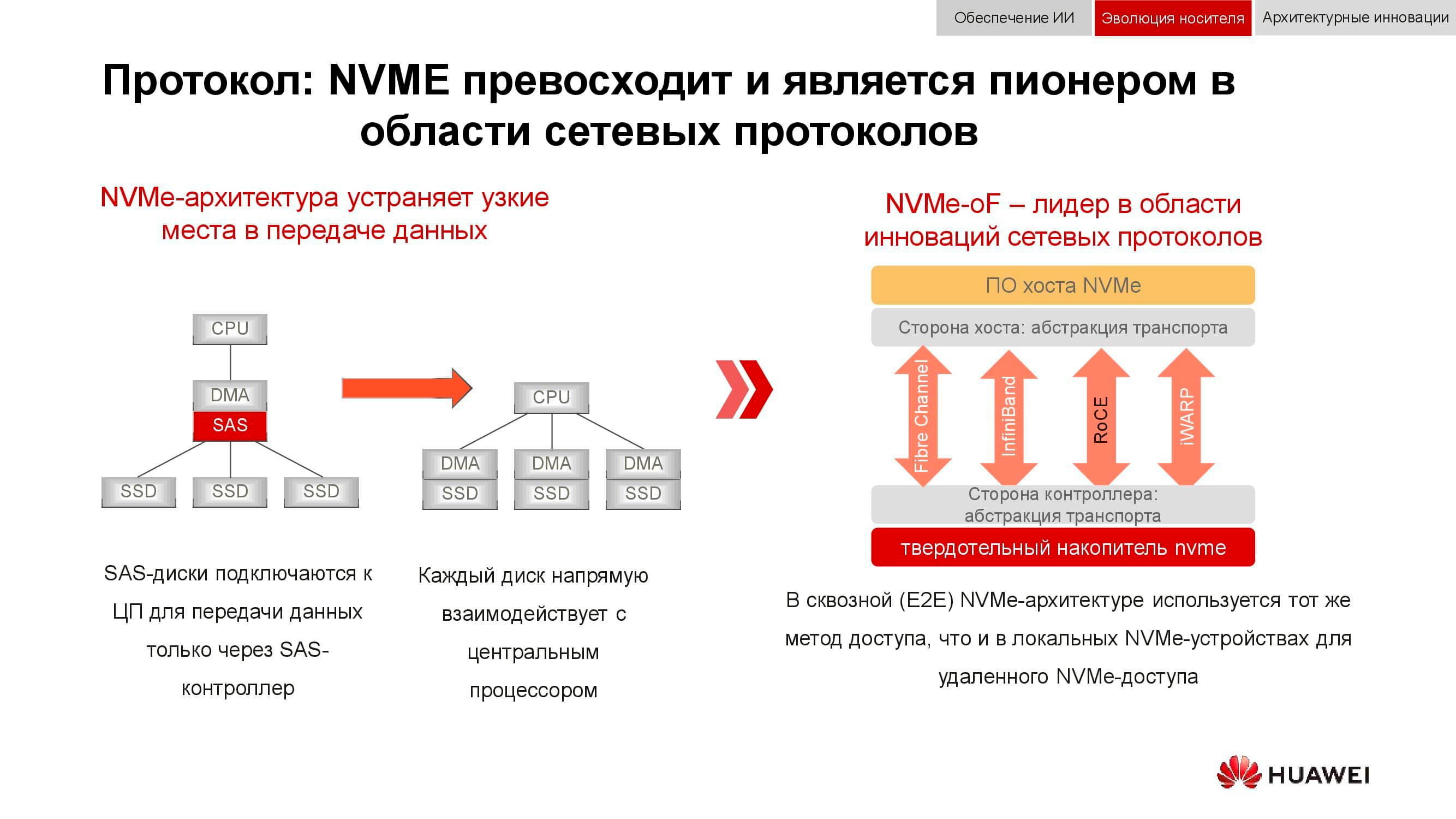
Y el almacenamiento de datos en bloque se está preparando para NVMe . Recuerde que el esquema clásico para organizar el acceso a los datos funcionaba de la siguiente manera: el procesador accedía al controlador RAID a través del bus PCI Express. Eso, a su vez, interactuó con discos mecánicos a través de SCSI o SAS. El uso de NVMe en el backend aceleró significativamente todo el proceso, pero tenía un inconveniente: las unidades tenían que estar conectadas directamente al procesador para proporcionar acceso directo a la memoria.
La siguiente fase de desarrollo tecnológico que estamos viendo ahora es el uso de NVMe-oF (NVMe sobre tejidos). En cuanto a las tecnologías de bloque de Huawei, ya son compatibles con FC-NVMe (NVMe sobre canal de fibra) y con el enfoque NVMe sobre RoCE (RDMA sobre Ethernet convergente). Los modelos de prueba son bastante funcionales, quedan varios meses antes de su presentación oficial. Tenga en cuenta que todo esto también aparecerá en los sistemas distribuidos, donde la "Ethernet sin pérdidas" tendrá una gran demanda.
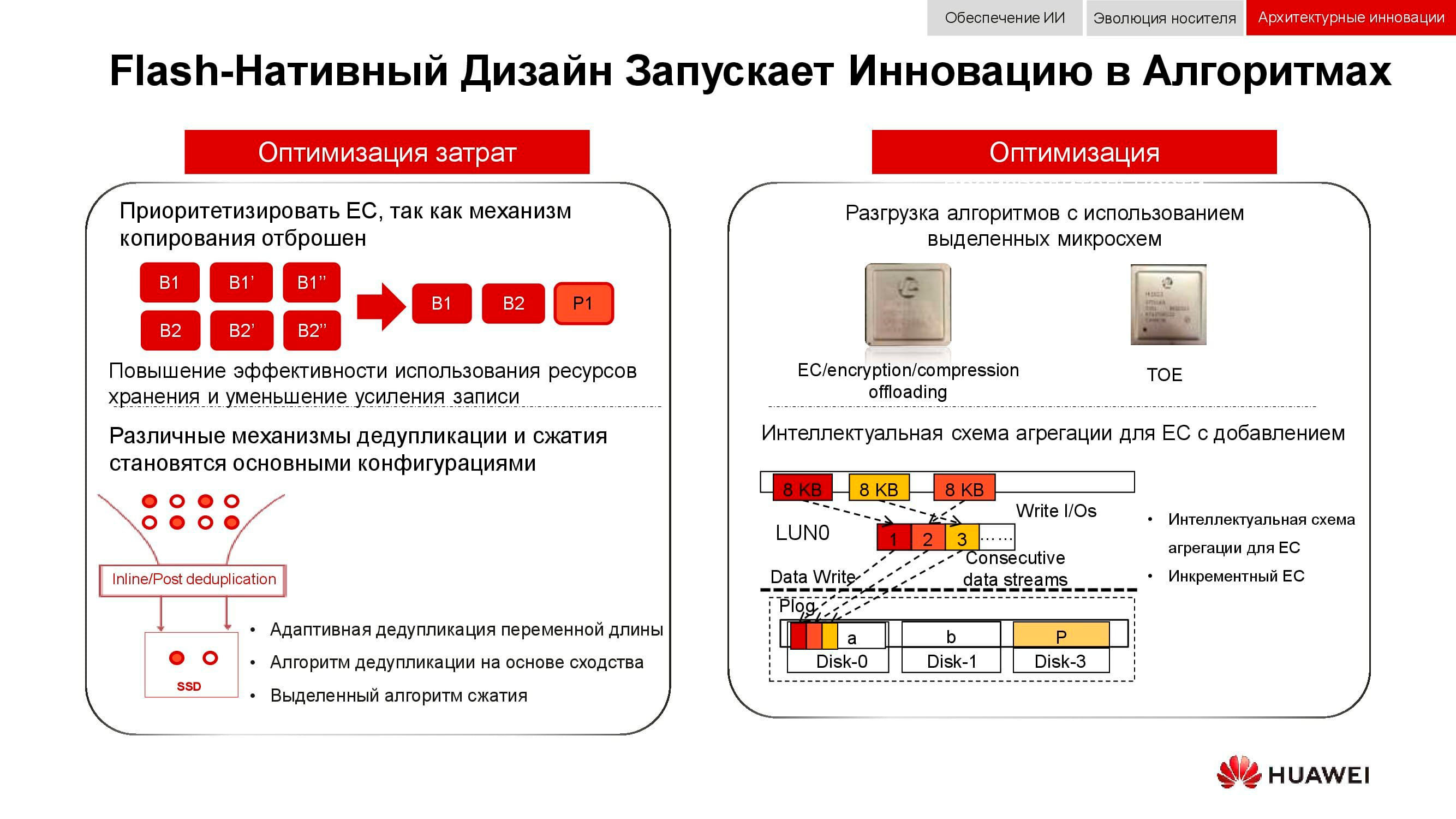
Una forma adicional de optimizar el trabajo del almacenamiento distribuido es un rechazo total de la duplicación de datos. Las soluciones de Huawei ya no usan n copias, como en el RAID 1 habitual, y cambian por completo al mecanismo EC(Codificación de borrado). Un paquete matemático especial calcula bloques de control a intervalos regulares, lo que le permite restaurar datos intermedios en caso de pérdida.
Los mecanismos de deduplicación y compresión se están volviendo obligatorios. Si en los sistemas de almacenamiento clásicos estamos limitados por la cantidad de procesadores instalados en los controladores, entonces en los sistemas de almacenamiento escalables distribuidos cada nodo contiene todo lo que necesita: discos, memoria, procesadores e interconexión. Estos recursos son suficientes para que la deduplicación y la compresión tengan un impacto mínimo en el rendimiento.
Y sobre métodos de optimización de hardware. Aquí, fue posible reducir la carga en los procesadores centrales con la ayuda de microcircuitos dedicados adicionales (o bloques dedicados en el propio procesador), que desempeñan el papel de TOE(TCP / IP Offload Engine) o abordar los problemas matemáticos de EC, deduplicación y compresión.
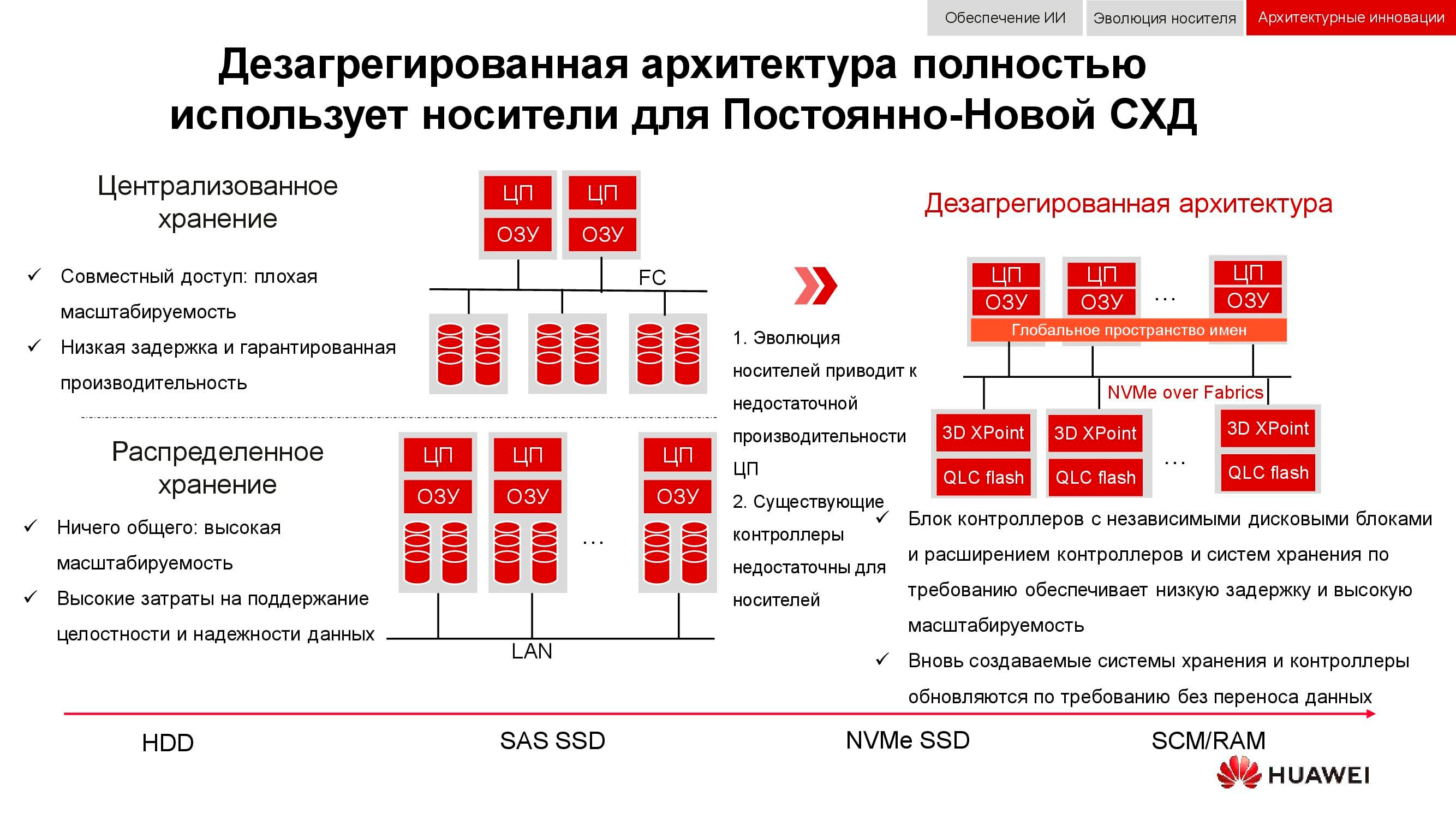
Los nuevos enfoques para el almacenamiento de datos están incorporados en una arquitectura desagregada (distribuida). En los sistemas de almacenamiento centralizado, hay una fábrica de servidores que está conectada a través de Fibre Channel a una SAN con una gran cantidad de arreglos. Las desventajas de este enfoque son la dificultad de escalar y proporcionar niveles de servicio garantizados (rendimiento o latencia). Los sistemas hiperconvergentes utilizan los mismos hosts para almacenar y procesar información. Esto proporciona una escalabilidad prácticamente ilimitada, pero implica altos costos para mantener la integridad de los datos.
En contraste con los dos anteriores, la arquitectura desagregada implica la separación del sistema en una estructura informática y un sistema de almacenamiento horizontal . Esto proporciona los beneficios de ambas arquitecturas y le permite escalar casi indefinidamente solo al elemento que carece de rendimiento.
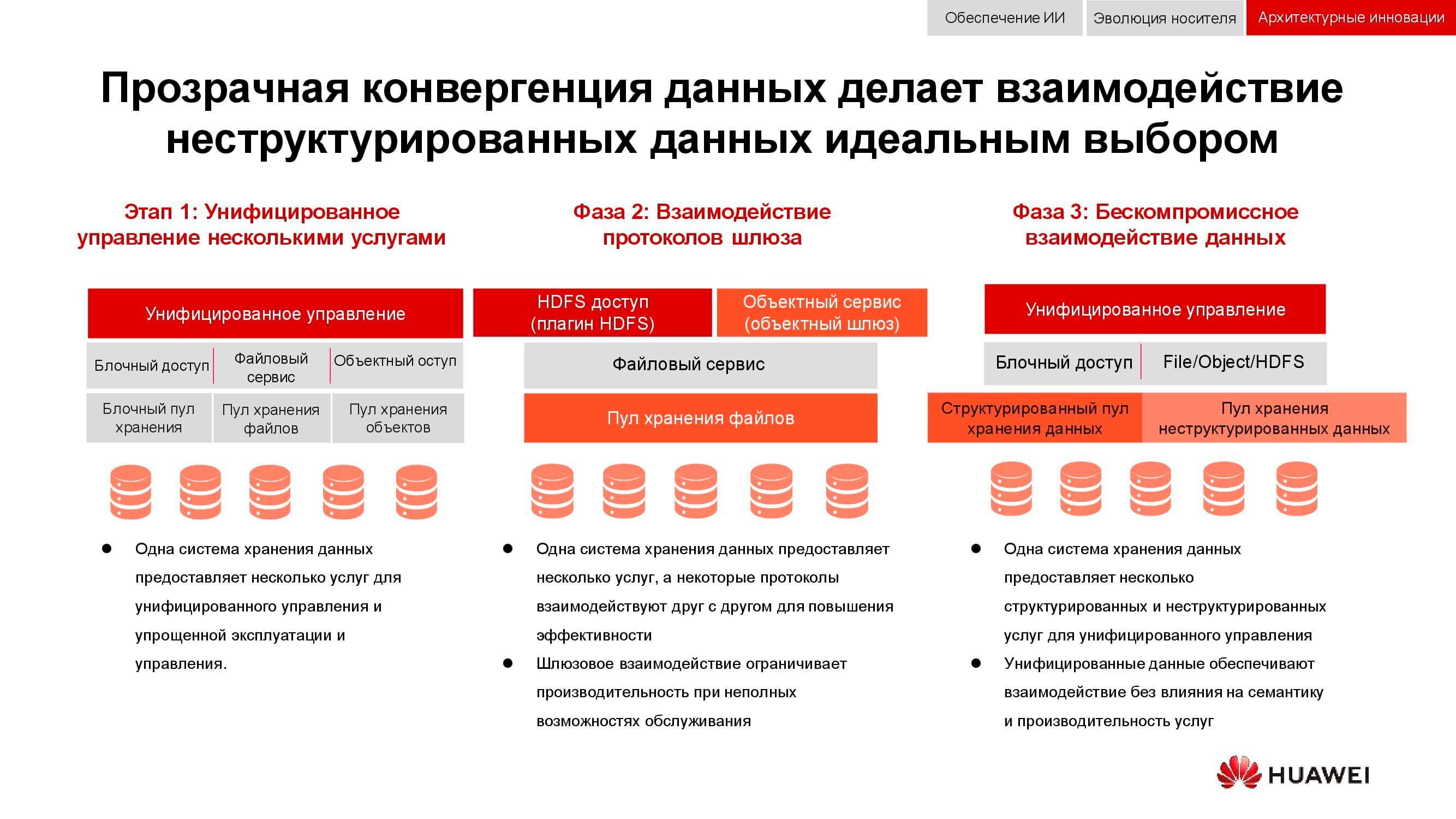
De la integración a la convergencia
Una tarea clásica, cuya relevancia solo ha crecido en los últimos 15 años, es la necesidad de proporcionar simultáneamente almacenamiento en bloque, acceso a archivos, acceso a objetos, operación de granjas para big data, etc. La guinda del pastel también puede ser, por ejemplo, un sistema de respaldo en cinta magnética.
En la primera etapa, solo fue posible unificar la gestión de estos servicios. Los sistemas de almacenamiento de datos heterogéneos se bloquearon en algún software especializado, a través del cual el administrador asignó recursos de los grupos disponibles. Pero dado que estos grupos eran diferentes en hardware, la migración de la carga entre ellos era imposible. En un nivel superior de integración, la consolidación se llevó a cabo a nivel de puerta de enlace. Si hubiera un acceso a un archivo compartido, se podría enviar a través de diferentes protocolos.
El método de convergencia más avanzado de que disponemos ahora implica la creación de un sistema híbrido universal. Exactamente lo que debería ser nuestro OceanStor 100D . La accesibilidad utiliza los mismos recursos de hardware, lógicamente divididos en diferentes grupos, pero permitiendo la migración de cargas de trabajo. Todo esto se puede hacer a través de una única consola de gestión. De esta manera, logramos implementar el concepto de “un centro de datos, un sistema de almacenamiento”.
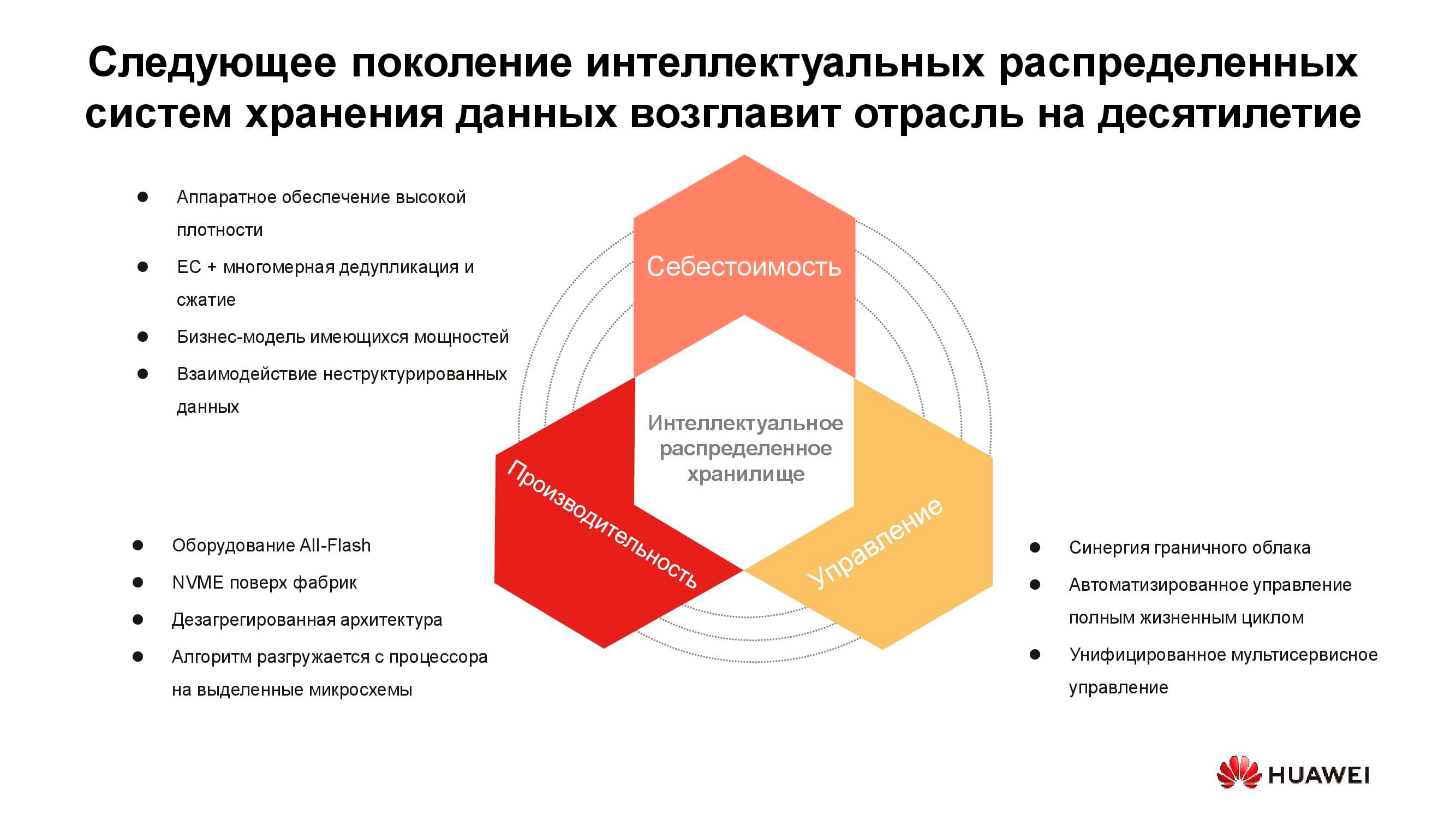
El costo de almacenar información ahora determina muchas decisiones arquitectónicas. Y si bien se puede colocar de manera segura a la vanguardia, hoy estamos discutiendo el almacenamiento en vivo con acceso activo, por lo que también se debe considerar el rendimiento. Otra propiedad importante de los sistemas distribuidos de próxima generación es la unificación. Después de todo, nadie quiere tener varios sistemas dispares controlados desde diferentes consolas. Todas estas cualidades están plasmadas en la nueva serie de productos OceanStor Pacific de Huawei .
Almacenamiento masivo de una nueva generación
OceanStor Pacific cumple los requisitos de confiabilidad al nivel de "seis nueves" (99,9999%) y se puede utilizar para crear centros de datos de la clase HyperMetro. Con una distancia de hasta 100 km entre dos centros de datos, los sistemas demuestran un retraso adicional de 2 ms, lo que hace posible construir sobre su base cualquier solución resistente a desastres, incluidas aquellas con servidores de quórum.
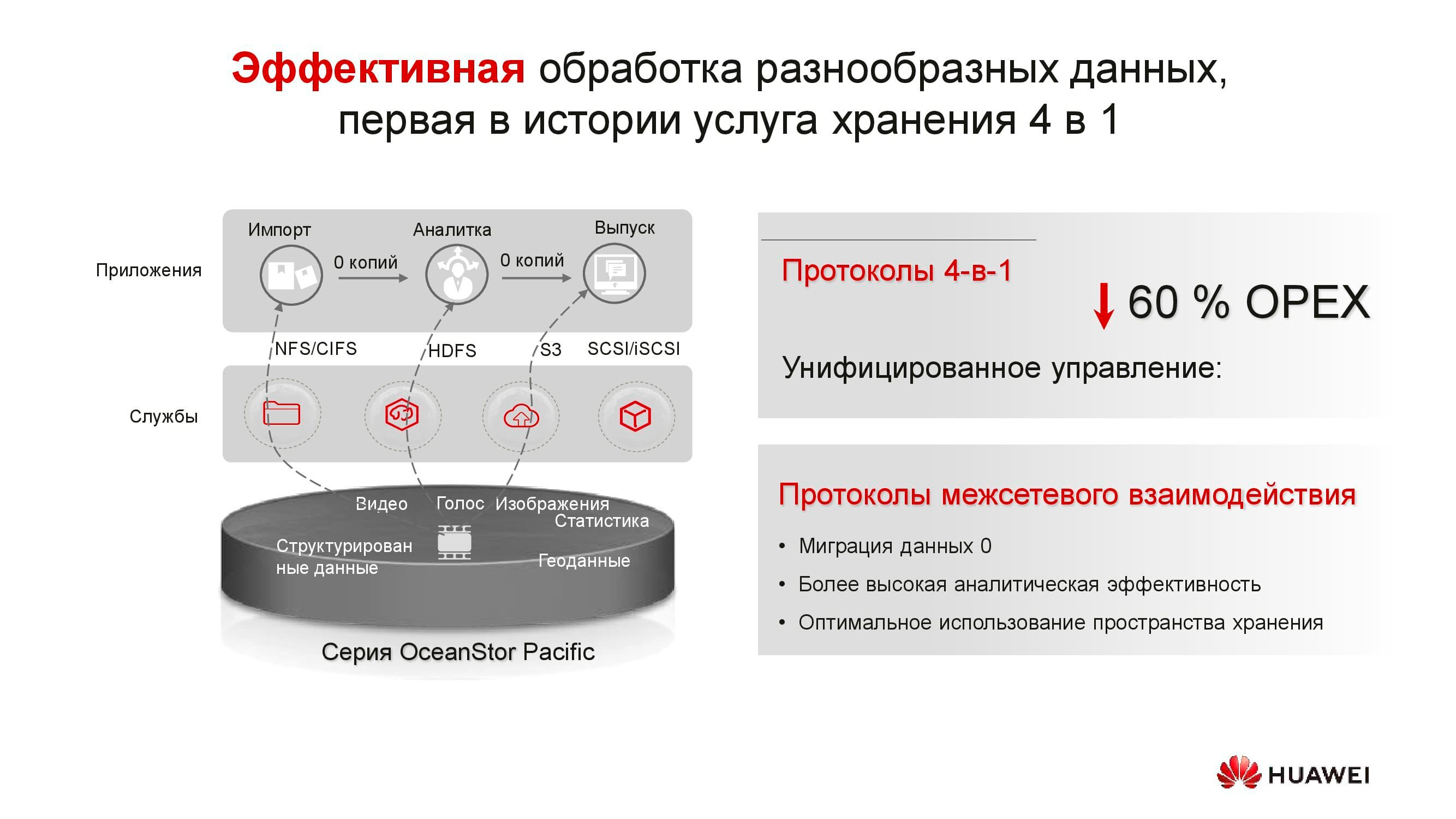
Los productos de la nueva serie demuestran la versatilidad de protocolos. OceanStor 100D ya admite acceso a bloques, acceso a objetos y acceso a Hadoop. El acceso a archivos se implementará en un futuro próximo. No es necesario conservar varias copias de los datos si se pueden entregar a través de diferentes protocolos.
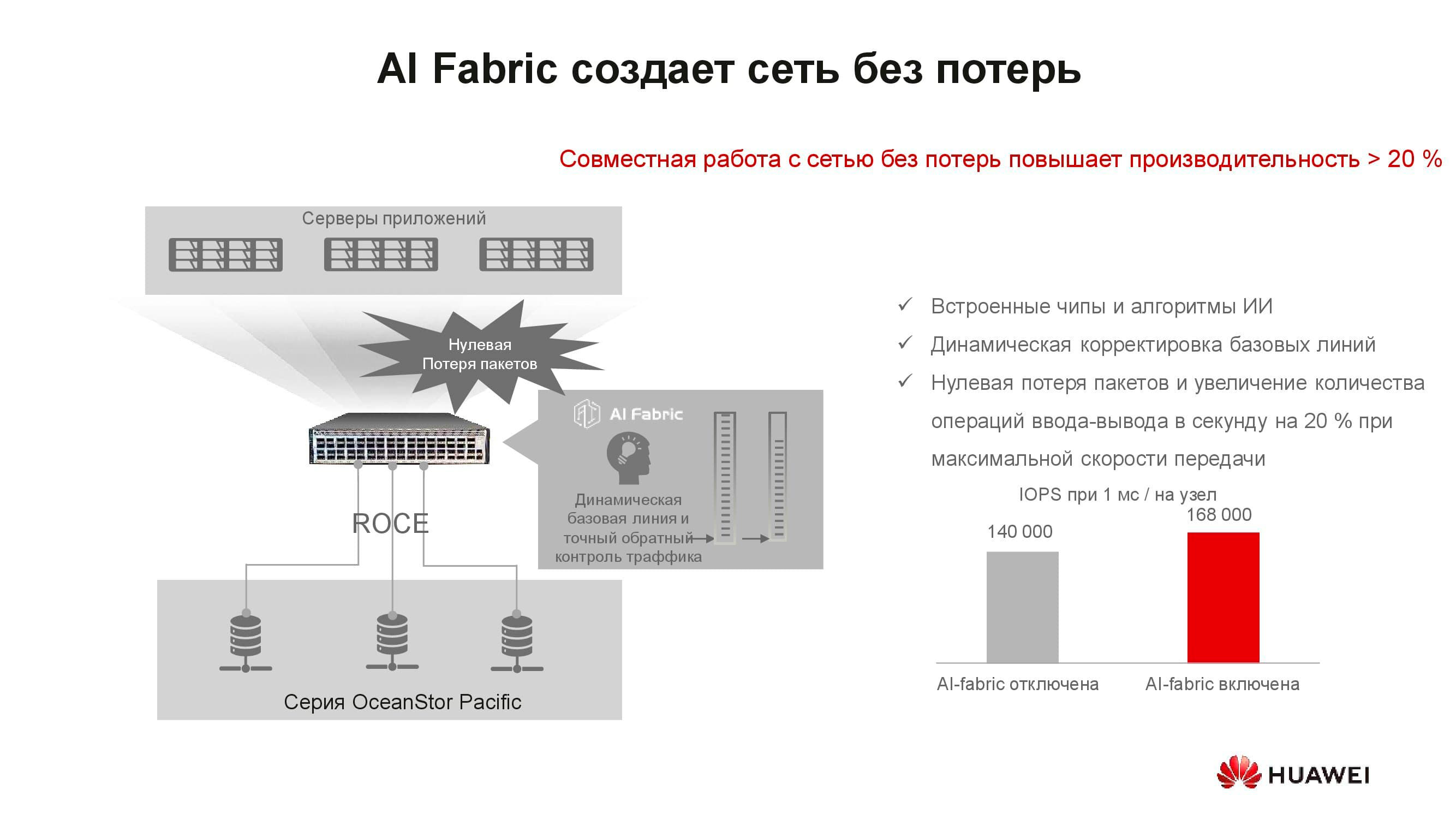
Al parecer, ¿qué tiene que ver el concepto de "red sin pérdidas" con el almacenamiento? El hecho es que los sistemas de almacenamiento distribuido se construyen sobre la base de una red rápida que admite los algoritmos adecuados y el mecanismo RoCE. AI Fabric compatible con nuestros conmutadores ayuda a aumentar aún más la velocidad de la red y reducir la latencia . Las ganancias en el rendimiento del almacenamiento con la activación de AI Fabric pueden ser de hasta un 20%.
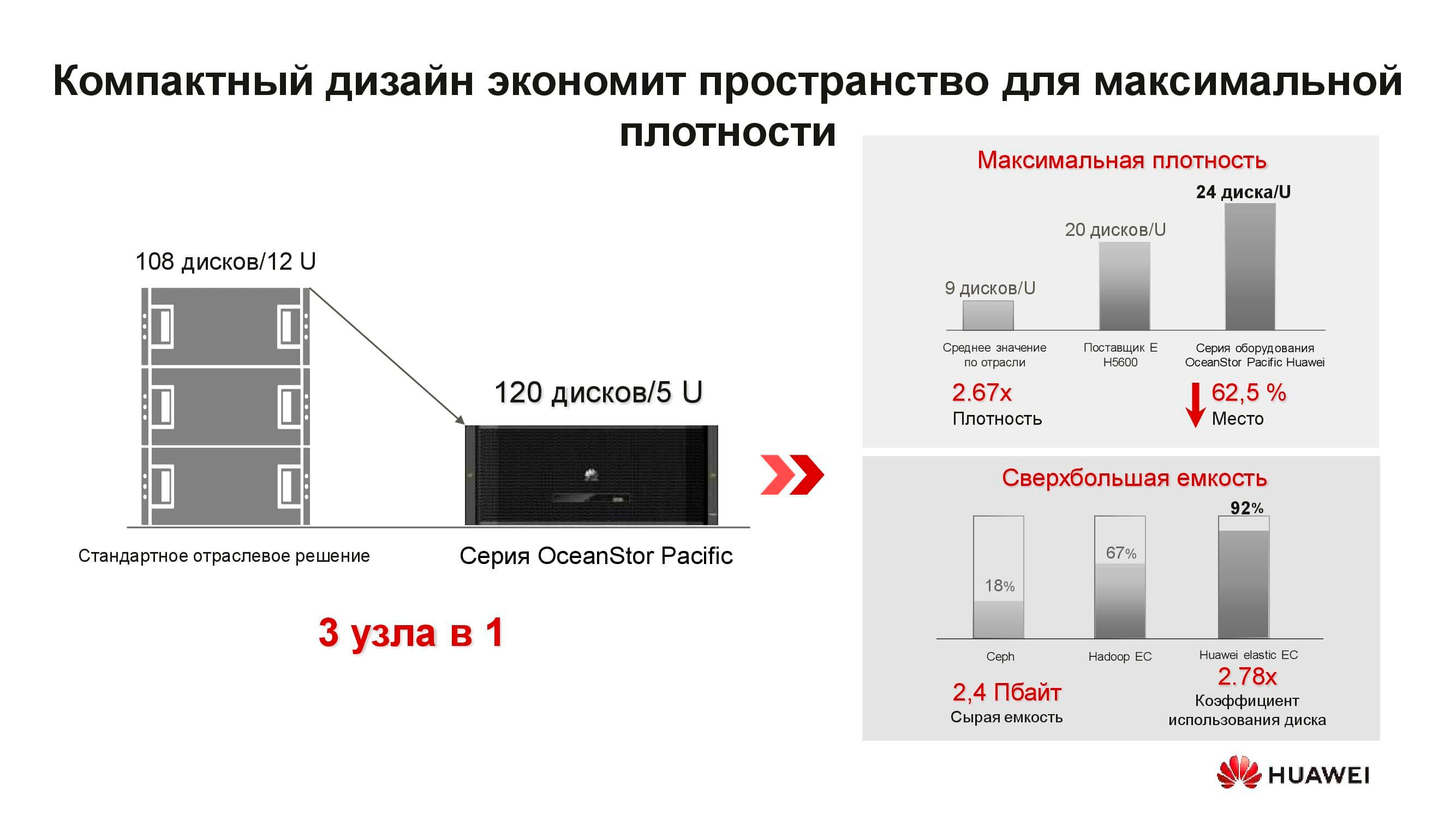
¿Qué es el nuevo nodo de almacenamiento distribuido de OceanStor Pacific? La solución 5U incluye 120 unidades y puede reemplazar tres nodos clásicos, lo que ahorra más del doble de espacio en rack. Debido a la negativa a almacenar copias, la eficiencia de las unidades aumenta significativamente (hasta + 92%).
Estamos acostumbrados al hecho de que el almacenamiento definido por software es un software especial instalado en un servidor clásico. Pero ahora, para lograr parámetros óptimos, esta solución arquitectónica también requiere nodos especiales. Consta de dos servidores basados en procesadores ARM, que gestionan una matriz de unidades de 3 pulgadas.
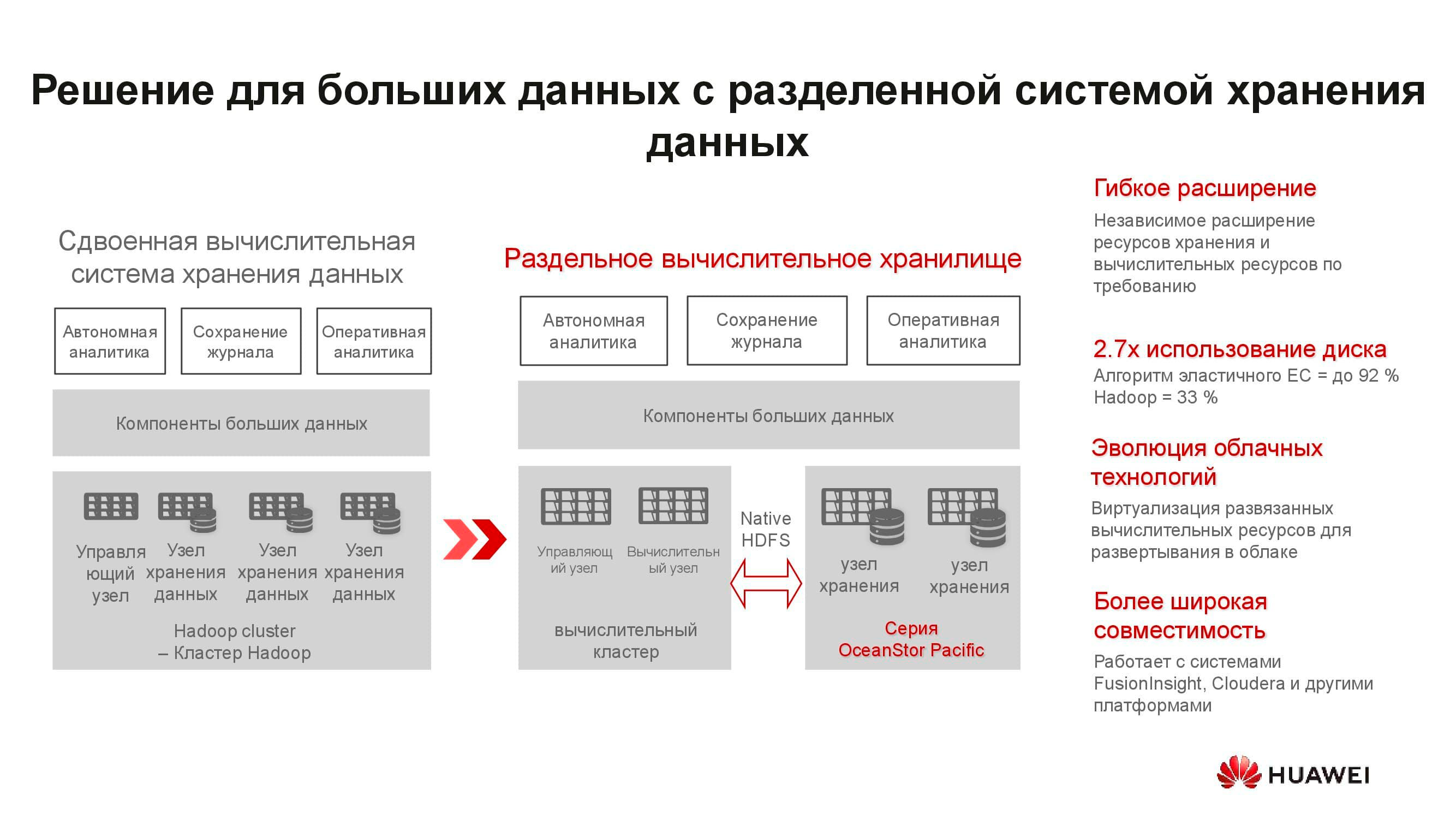
Estos servidores no son adecuados para soluciones hiperconvergentes. En primer lugar, hay pocas aplicaciones para ARM y, en segundo lugar, es difícil mantener el equilibrio de carga. Proponemos pasar al almacenamiento separado: un clúster computacional, representado por servidores clásicos o en rack, opera por separado, pero se conecta a los nodos de almacenamiento de OceanStor Pacific, que también realizan sus tareas directas. Y se justifica a sí mismo.
Por ejemplo, tomemos una solución clásica de almacenamiento de big data hiperconvergente que ocupa 15 racks de servidores. Al separar la carga de trabajo entre los servidores informáticos separados y los nodos de almacenamiento OceanStor Pacific, separándolos entre sí, ¡la cantidad de racks necesarios se reducirá a la mitad! Esto reduce el costo de operación del centro de datos y reduce el costo total de propiedad. En un mundo donde el volumen de información almacenada crece en un 30% por año, estas ventajas no están dispersas.
***
Puede obtener más información sobre las soluciones y escenarios de Huawei para su uso en nuestro sitio web o comunicándose directamente con los representantes de la empresa.