- ¿De qué vamos a hablar exactamente? No selecciones y uniones primitivas, creo que la mayoría de ustedes ya las conocen.
Hablaremos sobre el uso real de las bases de datos, qué dificultades puede enfrentar y qué necesita saber como desarrollador backend. Habrá mucha información, aquí está el contenido. No es necesario que conozca a fondo y directamente los detalles de cada uno de estos puntos, pero debe saber que este punto existe.

Y necesita saber cómo se resuelven los problemas para que cuando tenga la tarea de construir una estructura, guardar datos, sepa qué modelo de datos elegir y cómo guardarlo. O suponga que tiene un problema, ve que la base de datos está inactiva, es lenta o tiene problemas de datos, inconsistencia. Entonces tienes que entender dónde excavar. Es decir, necesita saber qué conceptos existen y desde qué lado abordar los problemas.

Primero, hablaremos de datos. ¿Qué es esto de todos modos? Hay muchos hechos a nuestro alrededor, mucha información, pero hasta que no se hayan recopilado de alguna manera, son inútiles para nosotros. Los recopilamos, estructuramos y almacenamos. Y es esta estructuración almacenada la que se llama datos, y lo que la almacena se llama base de datos. Pero si bien estos datos solo se recopilan en algún lugar, también son básicamente inútiles para nosotros. Por lo tanto, hay una capa por encima de las bases de datos: el DBMS. Esto es lo que nos permite recuperar datos, almacenarlos y analizarlos. Así, convertimos los datos que recibimos en información que ya podemos mostrarle al usuario. El usuario adquiere conocimientos y los aplica.

Discutiremos cómo estructurar información y hechos, almacenarlos, en qué forma de datos, en qué modelo. Y cómo conseguirlos para que muchos usuarios puedan acceder simultáneamente a los datos y obtener el resultado correcto, para que nuestro conocimiento final que aplicaremos sea verdadero y correcto.

Primero, hablaremos de bases de datos relacionales. Creo que muchos de ustedes conocen el modelo relacional. Es un modelo del tipo de tablas y relaciones entre tablas. Imagina que tenemos un messenger en el que escribimos datos y mensajes entre usuarios. Podemos escribirlos todos en una tabla tan grande y voluminosa, amplia, donde tendremos muchos datos repetitivos: de quién, quién, a quién, en qué chat. Y podemos escribir todo esto en varias tablas, es decir, normalizar nuestros datos, llevarlos a la tercera forma normal.
Hay notas y referencias en las diapositivas. No profundizaremos en todos los conceptos ahora. Intentaré no hablar de conceptos técnicos que puedan resultarle desconocidos. Pero todo lo que digo lo encontrarás en las notas de diapositivas. Incluida la normalización, también habrá una referencia, puede leerla si no está familiarizado con este concepto.

En términos generales, la normalización es el desglose de los datos en tablas con el objetivo de estructurarlos más. Por ejemplo, ahora hay una tabla de usuarios, chat de mensajería y mensajes. Esta estructura asegura que los mensajes de exactamente los usuarios que conocemos y de los chats que conocemos se grabarán aquí. Es decir, aseguramos la integridad de los datos. Nos aseguramos de que siempre podamos recopilar la imagen completa. Pero al mismo tiempo, almacenamos, por ejemplo, en la tabla de mensajes solo ID, solo identificadores. Por lo tanto, reducimos el tamaño general de la base de datos, haciéndola más pequeña. En consecuencia, facilitamos la escritura en esta base de datos. No necesitamos escribir constantemente en muchas tablas. Simplemente escribimos en una tabla con el especialista en identificación.

Si hablamos de normalización, generalmente se simplifica mucho la visión del sistema, porque es muy gráfico, y enseguida nos queda claro qué relaciones tenemos entre qué tablas.
Reducimos el número de errores a la hora de escribir datos, porque si escribimos un mensaje en el messenger y aún no tenemos ese usuario, entonces tendremos que crear uno. Pero la imagen final, los datos generales, permanecerán completos.
Ya he dicho sobre la reducción del tamaño de la base de datos. No tenemos que escribir todos los datos sobre el usuario en la tabla de mensajes cada vez. Para ver el perfil, simplemente podemos ir a la tabla de usuarios.
También advertí sobre una dependencia inconsistente. Estos son solo enlaces a ID de otras tablas, los identificadores son valores únicos dentro de una tabla. De otra manera, se llaman claves primarias, y cuando tenemos un enlace a estas claves primarias, entonces el enlace en otra tabla se llama clave foránea.
Esta estructura también protege nuestros datos de una eliminación accidental. No podemos eliminar un usuario, porque, por ejemplo, tiene un mensaje. Esta es una red tan pequeña pero de seguridad.
Parecería que hemos hecho una excelente estructura, todo está claro, todo es dependiente, todo es integral. ¿Con qué más necesitas trabajar?

Imaginemos que realmente lo ponemos en funcionamiento, tenemos muchos usuarios y, en consecuencia, muchos mensajes. Se comunican constantemente entre sí. ¿Qué está pasando en nuestra tabla de mensajes? Está en constante crecimiento. Y para buscar en los que no son datos, necesitamos iterar constantemente a través de absolutamente todos los mensajes, verificar si son de este usuario o no, en este chat o no, y solo luego mostrarlos.
Naturalmente, cuantos más usuarios, más mensajes, más tardarán las consultas de búsqueda. Necesitamos una solución que nos permita buscar rápidamente mensajes en la tabla.
En tal caso, se utilizan índices para acelerar la búsqueda. La asociación más simple con índices es el contenido de un libro. Si necesita encontrar información en un libro, puede hojear el libro o puede ir a la tabla de contenido. Los índices son una especie de tabla de contenido.
También hay un buen ejemplo con una guía telefónica. Puede hacer clic en una letra en su teléfono e inmediatamente se le enviará una referencia a los apellidos que comiencen con esta letra. Los índices de bases de datos funcionan de manera muy similar. Veamos nuestra tabla con mensajes y cómo obtendremos estos datos.

Preste atención a cómo trabajaremos con los datos. No con las filas que tenemos en la tabla, sino en general. Los índices se crean sobre la base de las consultas que realiza.
Imaginemos que principalmente realizamos solicitudes por chat, es decir, averiguamos qué mensajes hay en este chat. Construyamos el índice exactamente en la columna de chat. Los índices de la base de datos son una estructura separada. La mesa es independiente de ella. Es decir, puede eliminar y reconstruir el índice en cualquier momento, y la tabla no sufrirá esto.
Aquí puedes ver que hemos seleccionado, ponemos un índice en la columna, y tenemos una estructura separada, que ya ha reducido ligeramente el número de entradas, porque ya hay varios mensajes en el chat 11. El DBMS proporciona una búsqueda rápida en esta pequeña mesa de chat. ¿Cómo está hecho? Naturalmente, la búsqueda no es una simple búsqueda. Hay muchos algoritmos de búsqueda rápida, veremos uno de los algoritmos más populares que se utilizan por defecto en la mayoría de las bases de datos. Es un árbol equilibrado.

¿Como funciona? Tenemos un número de chat, este es un valor entero y el árbol se construye según el siguiente principio: cuanto menos a la izquierda del nodo, más valores a la derecha del nodo. ¿Qué nos da tal estructura? Si observa las hojas de resumen de este árbol, todos los valores de la parte inferior están ordenados. Esta es una gran ventaja en las ganancias de productividad. Ahora te mostraré por qué.
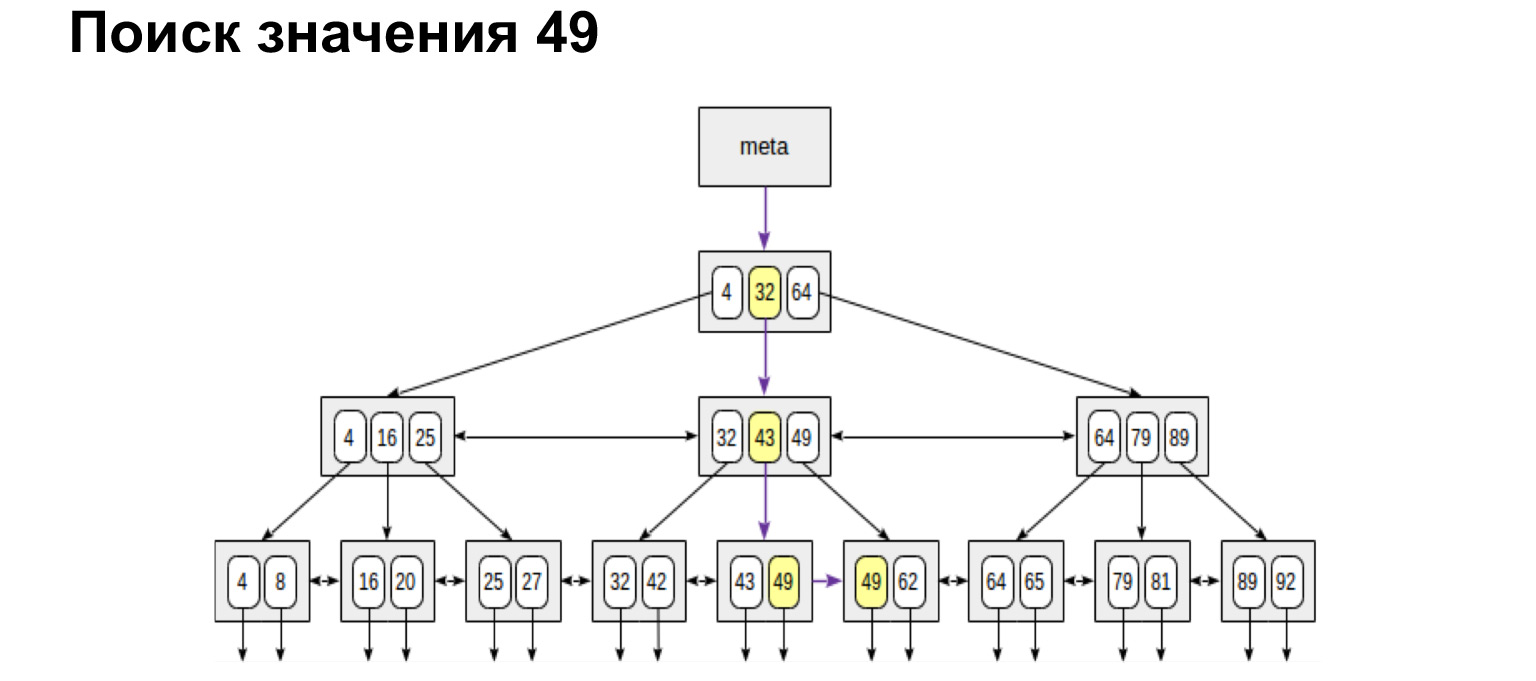
Por ejemplo, buscamos un valor. Es muy fácil buscar un significado. Bajamos por el árbol o hacia la izquierda, hacia la derecha, dependiendo de si este valor es mayor o menor.
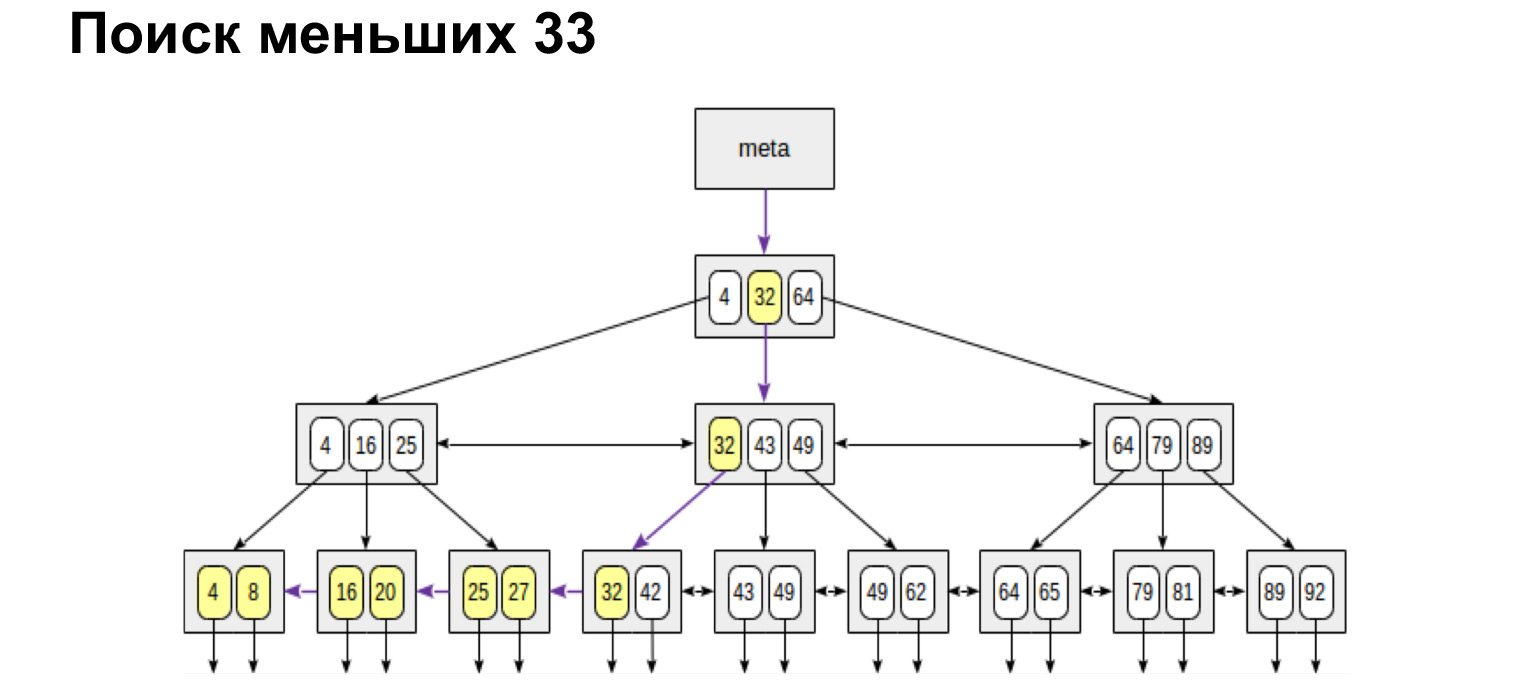
Y si queremos encontrar, por ejemplo, un rango, entonces mire lo simple y rápido que resulta. Alcanzamos el valor y luego seguimos los enlaces en las hojas, ya siguiendo los valores ordenados, solo vamos al final.
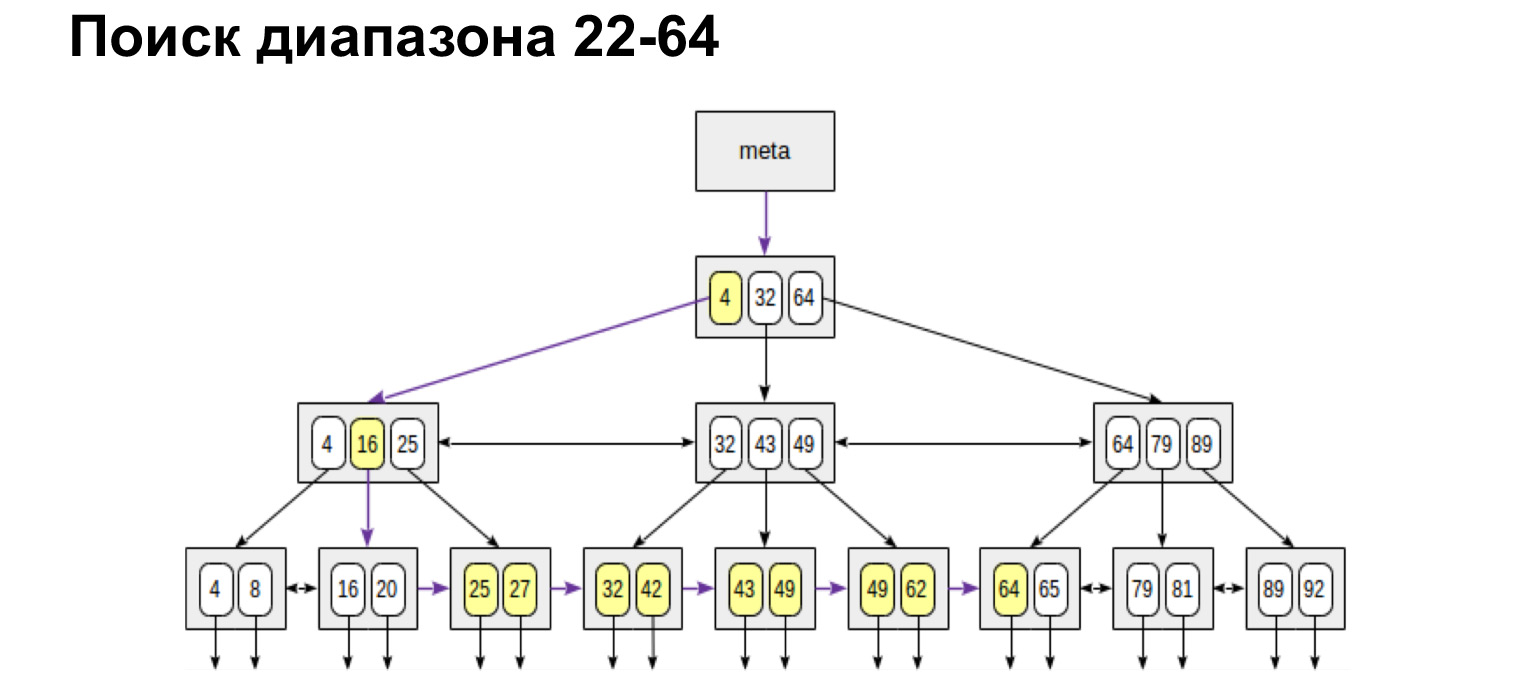
Si necesitamos un rango definido desde y hasta, hacemos exactamente lo mismo. Encontramos el valor inicial y seguimos los enlaces de las hojas hasta el valor máximo. Caminamos por el árbol solo una vez. Es muy conveniente, muy rápido.
De la misma forma buscaremos los valores máximo y mínimo. Camine completamente a la izquierda, completamente a la derecha. También recibiremos una lista ordenada. Es decir, si solo necesitamos obtener todos los chats de manera ordenada, llegamos al primero y pasamos por las hojas hasta el valor más a la derecha, obtenemos una lista ordenada. Es por este principio que la base de datos busca muy rápidamente en la tabla de índice las filas que necesitamos seleccionar y las devuelve.
¿Qué es importante saber aquí? Parecería una estructura genial: ahora construiremos para cada columna de acuerdo con dicho árbol y buscaremos. ¿Por qué crees que no funcionará? ¿Por qué no tendremos un aumento de velocidad si construimos un árbol para cada columna? (...)
Nuestras selecciones realmente se acelerarán. Cada vez que necesitamos revisar algún valor, vamos al índice, encontramos allí un enlace a los valores mismos. Los índices suelen contener exactamente las referencias a las cadenas, no las cadenas en sí. Y para seleccionarlo funciona perfectamente. Pero tan pronto como queramos configurar los datos de la tabla, actualizar o eliminar datos, todos estos árboles deberán reconstruirse.
De hecho, eliminar no reconstruirá, sino que simplemente fragmentará este árbol, y terminaremos con muchos valores vacíos. Habrá un árbol enorme con valores vacíos. Pero es con la actualización y con la creación que estos árboles se reconstruirán cada vez. Como resultado, obtendremos una gran sobrecarga sobre toda esta estructura. Y en lugar de obtener datos rápidamente y acelerar la base de datos, ralentizaremos nuestras consultas.
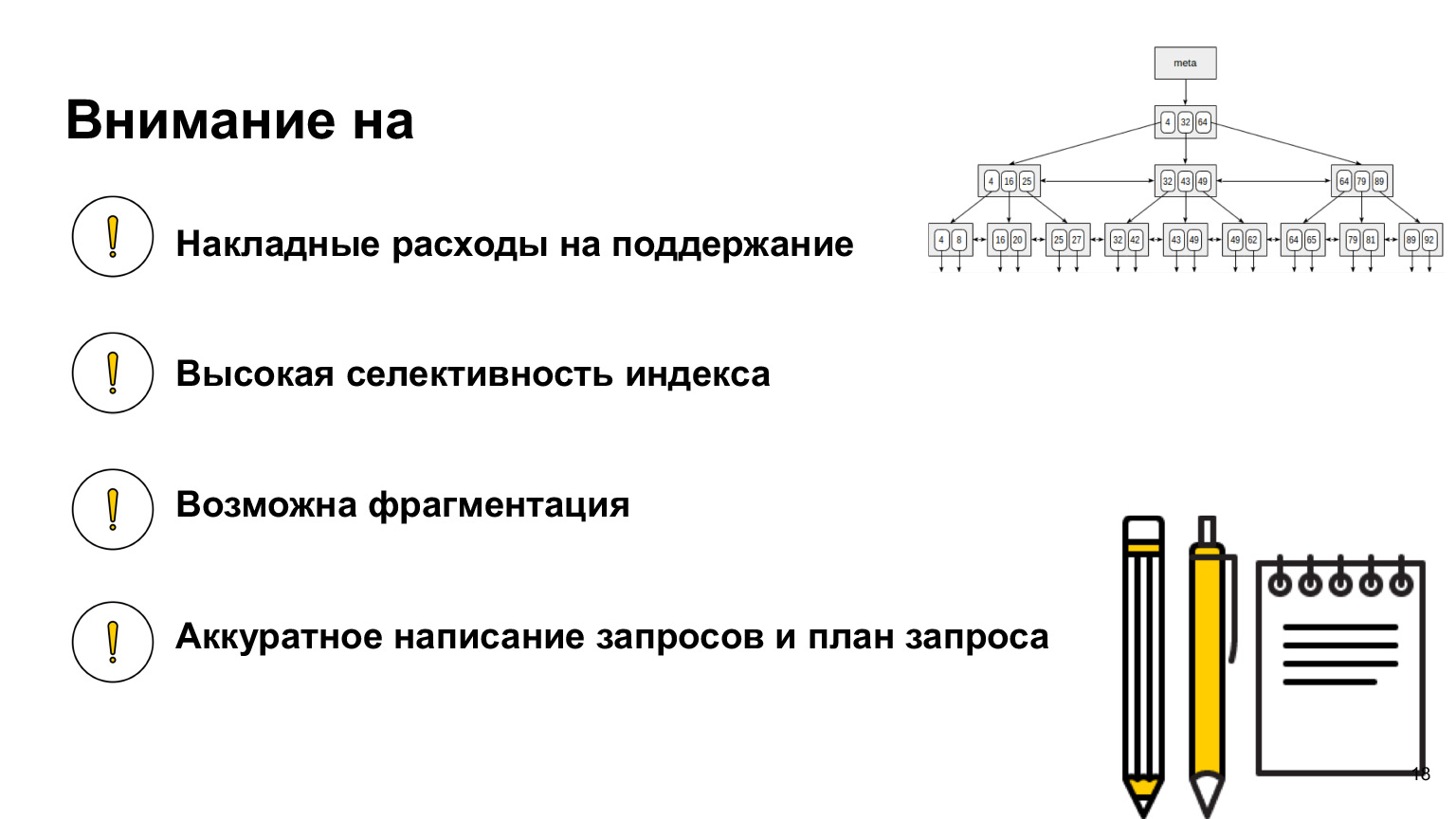
¿Qué más es importante saber? Cuando trabaje con una base de datos, busque y lea qué índices existen en ella, porque cada base de datos tiene sus propias implementaciones, sus propios índices diferentes. Hay índices para acelerar, hay índices para garantizar la integridad. Uno de los más simples es solo la clave principal. Este también es un índice único. Y con respecto a su base de datos, vea cómo funciona, cómo trabajar con ella, porque este es el tipo de conocimiento que le ayudará a escribir las consultas más óptimas.
Discutimos qué tener en cuenta la sobrecarga de mantener índices al insertar datos. Olvidé decir que cuando construyes un índice, debe ser muy selectivo. Qué significa eso?
Miremos este árbol. Entendemos que si el índice se establece en verdadero falso, entonces obtendremos dos enormes trozos de madera a la izquierda y a la derecha. Y, en el mejor de los casos, revisamos el 50% de la tabla, lo que en realidad no es muy eficiente. Es mejor hacer un índice en aquellas columnas que tienen los valores más diferentes. Esto acelerará nuestras selecciones.
Dije sobre la fragmentación; al eliminar datos, debes tenerlo en cuenta. Si a menudo tenemos eliminaciones en los datos contenidos en el índice, es posible que sea necesario desfragmentarlo y esto también debe monitorearse. También es importante comprender que está creando un índice no basado en las columnas que tiene, sino en cómo usa esos datos. Y las consultas que incluyen índices deben escribirse con mucho cuidado. ¿Qué significa ordenado? Cuando escribe una consulta, envíela a la base de datos, no se envía directamente a la base de datos, sino a una cierta capa de software llamada programador de consultas.
El planificador tiene una determinada tabla de correspondencia de cuánto cuesta la operación y qué tan cara es. En el ejemplo de PostgreSQL, hay tablas técnicas especiales que recopilan información sobre sus datos, sobre sus tablas. El planificador mira qué consulta tiene, qué datos se almacenan en la tabla pg_stat. Esta es solo una tabla que almacena información general sobre cuántos datos tiene y qué columnas hay en su tabla, qué índices hay en ella. En base a esto, mira los planes para la ejecución de su consulta, calcula cuánto tiempo de acuerdo con qué plan tomará la consulta y elige el más óptimo.

Si desea ver el tiempo de ejecución previsto para su consulta, puede utilizar la operación Explicar. Si desea la ejecución real, puede utilizar Explicar analizar. ¿Cual es la diferencia? Como dije, el programador calcula inicialmente el tiempo de ejecución en función del tiempo estimado para cada operación. Por lo tanto, el tiempo real puede diferir según la máquina y la naturaleza de sus datos. Entonces, si desea la ejecución real, entonces, por supuesto, es mejor usar Explicar analizar.
Puede ver un ejemplo en esta diapositiva. Muestra que a veces las consultas basadas en su columna que tienen índices pueden no usar el índice de escaneo, sino solo un escaneo completo en toda la tabla. Esto sucede si tenemos una selectividad de índice baja y si el planificador piensa que una consulta de escaneo completo en la mesa será más rentable.
Imaginemos que tenemos nuestro messenger y queremos en la lista de chat, por ejemplo, mostrar el nombre del chat o la cantidad de mensajes no leídos. Si cada vez que abrimos un chat, recalculamos todos los datos de todos los chats, será muy poco rentable.
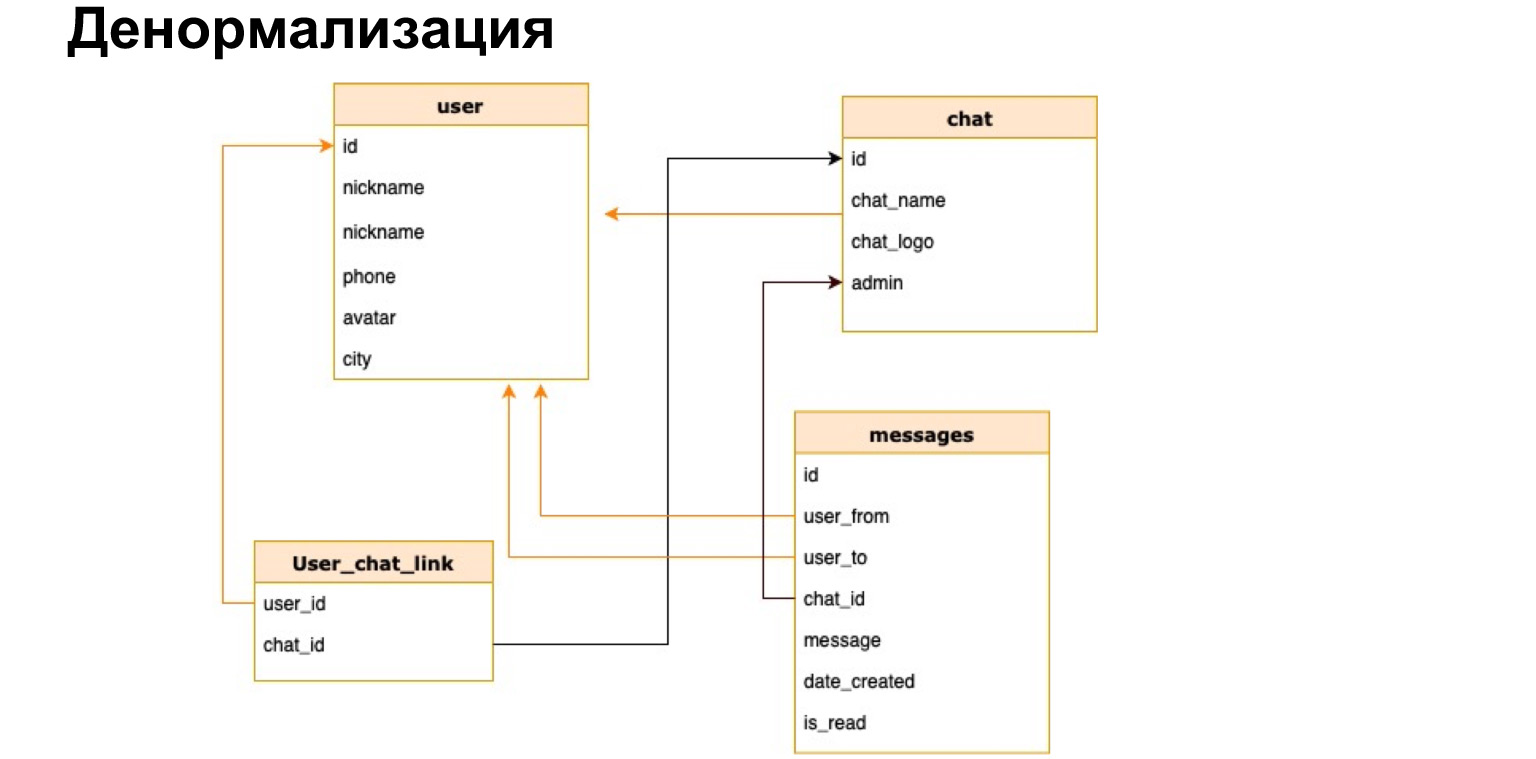
Existe tal cosa: la desnormalización. Se trata de una copia de los datos más recientes utilizados o un cálculo previo de los datos necesarios y guardarlos en una tabla.
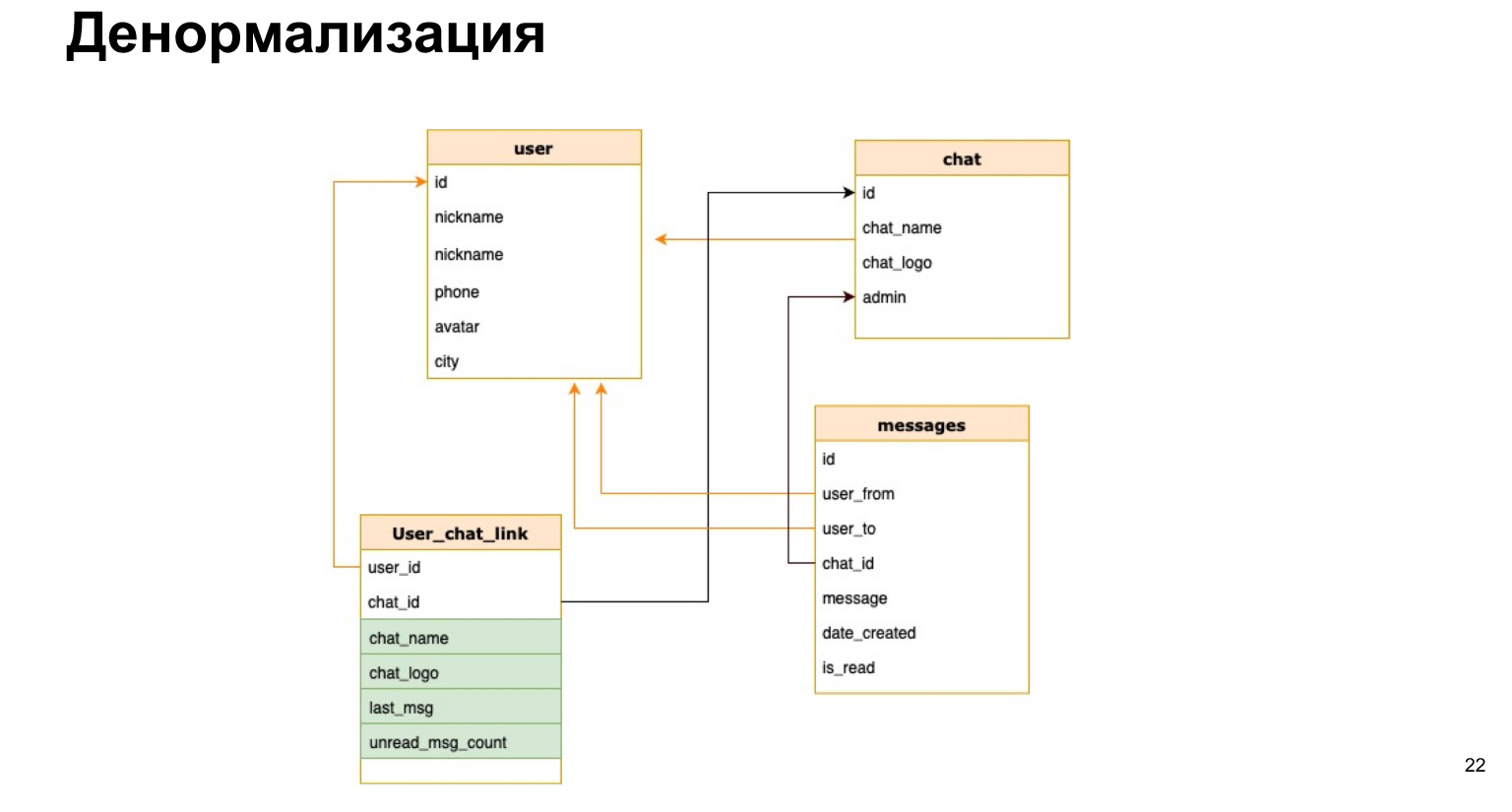
Así es como podría verse la relación entre el usuario y el chat. Es decir, además del ID de usuario y el ID del chat, guardaremos brevemente el nombre del chat, el registro del chat y la cantidad de mensajes no leídos allí. Así, cada vez no necesitaremos cargar todas nuestras tablas, hacer selecciones y recalcular todo esto.

¿Cuál es el plus de la desnormalización? Aceleramos el proceso de muestreo de datos. Es decir, nuestras selecciones se procesan lo más rápido posible, damos a los usuarios una respuesta lo más rápido posible.
La dificultad es que cada vez que agregamos nuevos datos, necesitamos recalcular todas estas columnas y la probabilidad de error es muy alta. Es decir, si nuestras selecciones se vuelven mucho más simples y no necesitamos unirnos todo el tiempo, entonces nuestra actualización y creación se vuelven muy engorrosas, porque necesitamos colgar los disparadores allí, recalcular y no olvidar nada.
Por lo tanto, solo debe usar la desnormalización cuando realmente la necesite. Y como ahora seguimos toda esta lógica, primero debe normalizar los datos, ver cómo los usará, ajustar los índices. Si tienes consultas que crees que no están funcionando bien, echa un vistazo a Explicar antes de desnormalizar. Descubra cómo se realizan realmente, cómo los realiza el planificador. Y solo entonces, cuando ya haya llegado a la conclusión de que la desnormalización todavía es necesaria, podrá hacerlo. Pero existe tal práctica, y la desnormalización de datos se usa a menudo en proyectos reales.
Vayamos más lejos. Incluso si estructuró bien los datos, eligió un modelo de datos, lo recopiló, desnormalizó todo, elaboró índices, todavía muchas cosas en el mundo de la TI pueden salir mal.
El software puede fallar, la energía puede fallar, el hardware o la red pueden fallar. También hay una segunda clase de problemas: muchos usuarios utilizan nuestras bases de datos simultáneamente. Pueden actualizar los mismos datos al mismo tiempo. Debemos poder resolver todos estos problemas.
Echemos un vistazo a ejemplos específicos de lo que se trata.

Imaginemos que hay dos usuarios que quieren reservar una sala de reuniones. El usuario 1 ve que la sala de reuniones está libre en este momento y comienza a reservarla. Se abre la ventana y piensa a cuál de mis colegas llamaré. Mientras piensa, el usuario 2 también ve que la sala de reuniones está libre y abre una ventana de edición para él.
Como resultado, cuando el usuario 1 guardó estos datos, se fue y piensa que todo está bien, la sala de reuniones está reservada. Pero en este momento, el usuario 2 sobrescribe sus datos y resulta que la sala de chat está asignada al usuario 2. Esto se denomina conflicto de datos. Y debemos poder mostrar estos conflictos a las personas y resolverlos de alguna manera. Es en este lugar donde tendremos regrabación.

¿Cómo hacerlo? Simplemente podemos bloquear la sala de reuniones por un tiempo mientras el usuario 1 está pensando. Si guardó los datos, no permitiremos que el usuario 2 haga esto. Si publicó los datos y no los guardó, el usuario 2 podrá reservar una reunión. Podrías ver una imagen similar cuando compras entradas de cine. Se le dan 15 minutos para pagar los boletos, de lo contrario, se los entregan nuevamente a otras personas que también pueden tomarlos y pagarlos.
Aquí hay otro ejemplo que nos mostrará lo importante que es asegurarnos de que nuestras operaciones se lleven a cabo por completo. Digamos que quiero transferir dinero de la cuenta bancaria 1 a la cuenta 2. En este momento tengo tres operaciones. Verifico que tengo fondos suficientes, deduzco fondos de mi primera cuenta y los deposito en la segunda cuenta. Está claro que si en alguno de estos momentos tengo un fallo, algo saldrá mal.
Por ejemplo, si en esta etapa se produce otra transacción que lee datos, entonces los fondos en mi cuenta ya no serán suficientes, no podré realizar otras operaciones. Si ocurre un problema en el segundo momento, entonces, por ejemplo, retiramos dinero de una cuenta, pero no pusimos dinero en la segunda. Resulta que, como resultado, mi cuenta bancaria, todas mis cuentas, se reducirán en alguna cantidad. Este dinero no se puede devolver de ninguna manera.
Para resolver estos problemas, existe el concepto de transacción: una ejecución atómica e integral de las tres operaciones simultáneamente.
¿Cómo lo hace la base de datos? Escribe todos estos cambios en un registro específico y los aplica solo cuando se confirma nuestra transacción. Por tanto, garantizamos que todas estas operaciones se realizarán en su conjunto o no se realizarán en absoluto.
Si en algún momento de este tiempo tenemos una falla, entonces no se deducirá dinero de la primera cuenta y, en consecuencia, no lo perderemos.
Las transacciones tienen cuatro propiedades, cuatro requisitos para ellas. Estos son atomicidad, consistencia, aislamiento y durabilidad: atomicidad, consistencia, aislamiento y persistencia de los datos. ¿Cuáles son estas propiedades?
- La atomicidad o atomicidad es una garantía de que la operación que estás realizando se completará en su totalidad, que no se realizará parcialmente. Por lo tanto, nos aseguramos de que la coherencia general de los datos en nuestra base de datos sea tanto antes como después de la operación.
- Consistency — -, . (Integrity). - , , Integrity Error, : , . . — , .
, , , , . . .
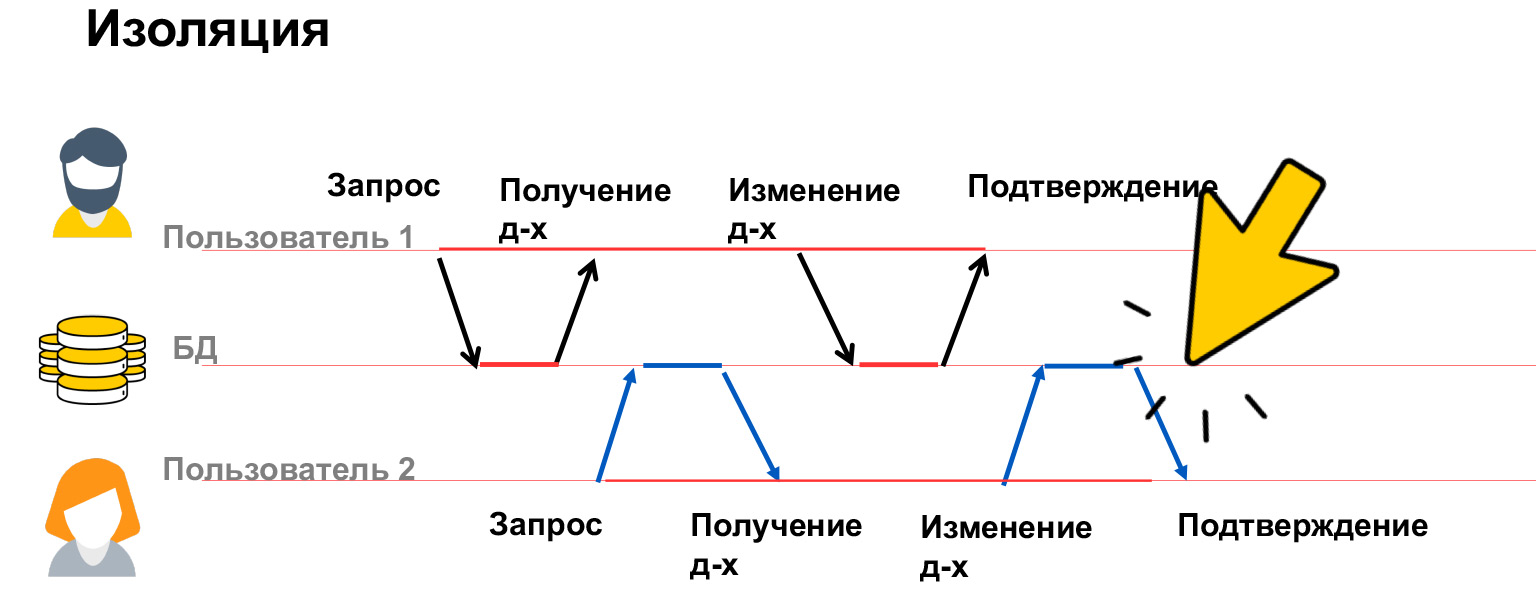
- Isolation — , . . , .
- Durability — , , , , .
Hablemos un poco más sobre aislamiento. El aislamiento de transacciones es una propiedad muy cara, se gastan muchos recursos en ella, por eso tenemos varios niveles de aislamiento en nuestras bases de datos. Veamos qué problemas pueden ser, y en base a esto, ya discutiremos cómo solucionarlos.
Hay cuatro clases principales de problemas: actualización perdida, lectura sucia, lectura no repetible y lectura fantasma. Miremos más de cerca.
Una actualización perdida es como en el ejemplo de las salas de chat, cuando el usuario 1 ha sobrescrito datos y no lo sabe. Es decir, no bloqueamos los datos que este usuario está cambiando y, en consecuencia, recibimos su sobrescritura.
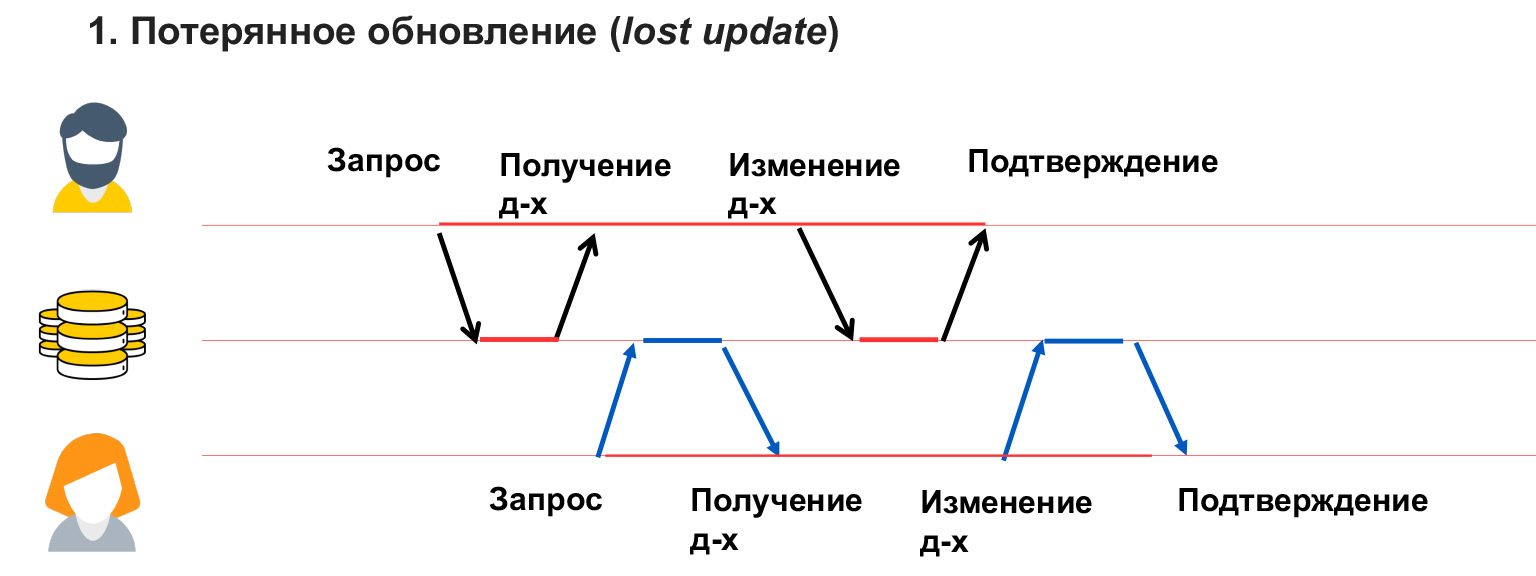
Un problema de lectura sucia ocurre cuando un usuario ve cambios temporales por parte de otro usuario, que luego pueden revertirse o simplemente hacerse temporalmente.

En este caso, el usuario 1 escribió algo en la base de datos. El usuario 2 en ese momento estaba calculando algo a partir de ahí y construyendo análisis sobre estos datos. Y el usuario 1 encontró un error, una inconsistencia y está deshaciendo estos datos. Así, la analítica que anotó el usuario 2 será falsa, incorrecta, porque los datos a partir de los cuales calculó ya no están ahí. También necesita poder resolver este problema.
Una lectura no repetible es cuando tenemos un usuario con 1 transacción larga. Obtiene datos de la base de datos y, en este momento, el usuario 2 cambia parte de los mismos datos.
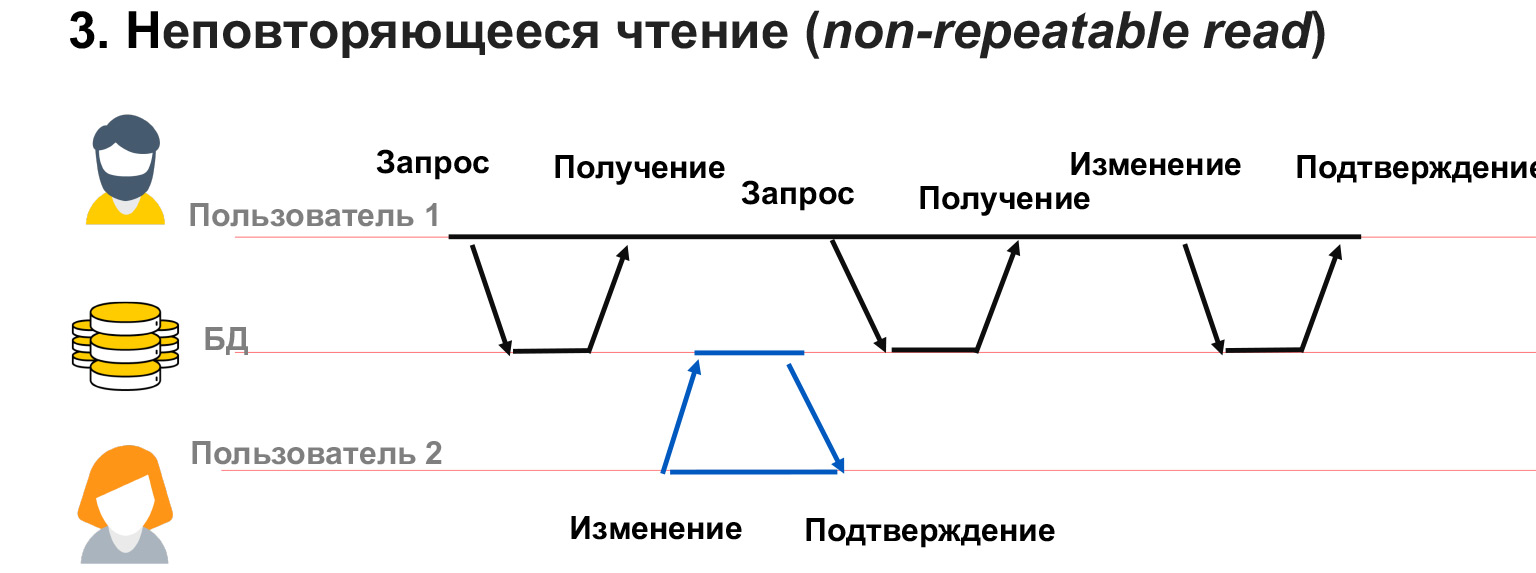
En este caso, resulta que el usuario 1 no ha bloqueado los cambios en los datos que tiene. Y a pesar de que él mismo obtuvo una instantánea de los datos, cuando se le pide la misma selección nuevamente, puede obtener diferentes valores en estas líneas. Por lo tanto, tendrá un conflicto, un desajuste en los datos que escribe.

Puede ocurrir un problema similar si el usuario 2 ha agregado o eliminado datos. Es decir, el usuario 1 hizo una solicitud y luego, después de una segunda solicitud de los mismos datos, tenía o desaparecía filas. En este caso, dentro del marco de la transacción, es muy difícil entender qué hacer con ellos, cómo procesarlos en absoluto.

Para resolver estos problemas, existen cuatro niveles de aislamiento. El primer nivel y el más bajo es Lectura no confirmada. Esto es lo que PostgreSQL describe como Sin bloqueo. Cuando leemos o escribimos datos, no impedimos que otros usuarios lean o escriban esos datos. Resulta que no estamos bloqueando ningún cambio. Los cuatro de estos problemas aún pueden ocurrir. Pero, ¿contra qué protege este nivel de aislamiento? Garantiza que se ejecutarán todas las transacciones que lleguen a la base de datos. Si dos usuarios comienzan a ejecutar consultas simultáneamente con los mismos datos, ambas transacciones se ejecutarán secuencialmente.
¿Para qué sirve esto? Este nivel de aislamiento se usa muy raramente en la práctica, pero puede ser útil, por ejemplo, cuando hay una gran consulta analítica y desea leer en la segunda consulta y ver en qué etapa se encuentra su analítica, qué datos ya se han registrado y cuáles no. Y luego la segunda solicitud, que es para depurar, depurar, verificar, se ejecuta solo en este nivel de aislamiento. Y ve todos los cambios en su primera solicitud analítica, que eventualmente puede revertirse. O no revertido, pero en el momento actual se puede ver el estado del sistema.

Leer comprometidos, leer datos comprometidos. Este nivel de aislamiento se utiliza de forma predeterminada en la mayoría de las bases de datos relacionales, incluidas PostgreSQL y Oracle. Garantiza que nunca lea datos sucios. Es decir, otra transacción nunca ve las etapas intermedias de la primera transacción. La ventaja es que funciona muy bien para consultas pequeñas y breves. Garantizamos que nunca tendremos una situación en la que veamos algunas partes de los datos, datos incompletos. Por ejemplo, aumentamos el salario de todo un departamento y no vemos cuando solo una parte de la gente recibió un aumento, y la segunda parte está sentada con un salario no indexado. Porque si tenemos una situación así, es lógico que nuestro analista "se vaya" inmediatamente.
¿Contra qué no protege este nivel de aislamiento? No protege contra el hecho de que los datos que ha seleccionado se pueden cambiar. Para consultas pequeñas, este nivel de aislamiento es suficiente, pero para consultas grandes y largas, análisis complejos, por supuesto, puede usar niveles más complejos que bloquean sus tablas.
El nivel de aislamiento de lectura repetible protege contra los primeros tres problemas que discutimos con usted. Esto y la actualización perdida cuando volvimos a grabar nuestra sala de chat; Lectura sucia: lectura de datos no comprometidos; y estos datos no repetibles de lectura - lectura actualizados por otras transacciones.

¿Cómo se proporciona? Bloqueando la mesa, es decir, bloqueando nuestra selección. Cuando tomamos la selección en nuestra transacción, parece una instantánea de los datos. Y en este momento no vemos los cambios de otros usuarios, todo el tiempo trabajamos con esta instantánea de datos. La desventaja es que bloqueamos datos y, en consecuencia, tenemos menos solicitudes paralelas que pueden trabajar con datos. Este es un aspecto muy importante. Y, en general, ¿por qué hay tantos niveles de aislamiento?
Cuanto más alto es el nivel, más bloques y menos usuarios pueden trabajar con la base de datos en paralelo. Cada transacción ve una instantánea específica de los datos que no se pueden cambiar. Pero pueden aparecer nuevos datos. Por tanto, este nivel de aislamiento no nos salva de la aparición de nuevos datos que sean adecuados para seleccionar.
Hay un nivel de aislamiento más: serialización. Esto a menudo se conoce como pedido. Este es un bloqueo de datos completo en la mesa. Se salva de la lectura fantasma, es decir, de leer solo los datos que hemos agregado o eliminado, porque bloqueamos la tabla, no permitimos escribir en ella. Y cumplimos nuestras solicitudes de manera integral.

Esto es muy útil para consultas analíticas grandes y complejas donde la precisión y la integridad de los datos son críticas. No resultará que en algún momento leamos los datos del usuario, y luego aparecieron nuevas estadísticas en otra tabla y resultó que no estaba sincronizada.
Este es el nivel de aislamiento más alto. Tiene el mayor número de bloqueos y la menor paralelización de consultas posible.
¿Qué necesita saber sobre las transacciones? Que nos simplifiquen la vida, porque se implementan a nivel DBMS y solo necesitamos hacer correctamente nuestras consultas, formarlas correctamente, para que los datos eventualmente sean consistentes. Y bloquear exactamente los datos con los que trabajan nuestros usuarios. Hay que tener en cuenta que es malo bloquear todo, en todas partes. Dependiendo del sistema que tenga y de quién lee / escribe cuánto, tendrá un nivel diferente de aislamiento. Si desea el sistema más rápido posible que cometa algunos errores, puede elegir el nivel mínimo de aislamiento. Si tiene un sistema bancario que debe garantizar que los datos sean consistentes, que todo esté hecho y no se pierda nada, entonces, por supuesto, debe elegir el nivel de aislamiento máximo.
Ya hemos avanzado bastante en la comprensión de cómo estructurar la base de datos y qué puede suceder. Vayamos más lejos.
¿Qué tan seguro es almacenar una base de datos? Ciertamente no es seguro. Si le pasa algo, perdemos todos los datos. Si hay una copia de seguridad, podemos implementarla, pero luego habrá tiempo de inactividad del sistema. Si nuestra red se rompe o el nodo deja de estar disponible, el sistema también estará inactivo durante algún tiempo, en tiempo de inactividad.
¿Como puede ésto ser resuelto? Existe tal concepto: la replicación. Se trata de una duplicación de la base de datos en otros nodos y servidores.

Esta es exactamente una duplicación completa, una copia de la base de datos. ¿Cómo podemos utilizar este mecanismo?
Primero, si algo le sucedió a la base de datos, podemos redirigir las solicitudes a otra copia de la base de datos, lo cual es lógico en principio. Esta es la aplicación principal. ¿De qué otra manera podemos usar esto?
Imaginemos que el usuario está lejos del servidor. Podemos distribuir servidores de tal manera que cubramos el número máximo de usuarios y les proporcionemos solicitudes lo más rápido posible. Cada uno de estos servidores tendrá la misma copia que los demás, pero las solicitudes volverán a los usuarios más rápido.

Otro uso muy popular es el equilibrio de carga. Dado que tenemos copias idénticas de los datos, no podemos leer de nuestra cabeza, ni de una base de datos, sino de diferentes. Por lo tanto, descargamos nuestro servidor.

También tenemos el concepto de consultas OLTP y consultas OLAP. ¿Lo que es? OLTP: consultas breves sobre transacciones. OLAP es analítica a largo plazo. Aquí es cuando tomamos una combinación enorme, una selección enorme, fusionamos todo y es muy importante para nosotros que en este momento todos los datos estén bloqueados, para que no haya cambios y la base de datos esté completa.
Para tales situaciones, puede realizar análisis en una copia separada de la base de datos. Entonces no afectaremos a nuestros usuarios, ellos también pueden hacer entradas en la base de datos, solo entonces estas entradas llegarán a nuestra copia.
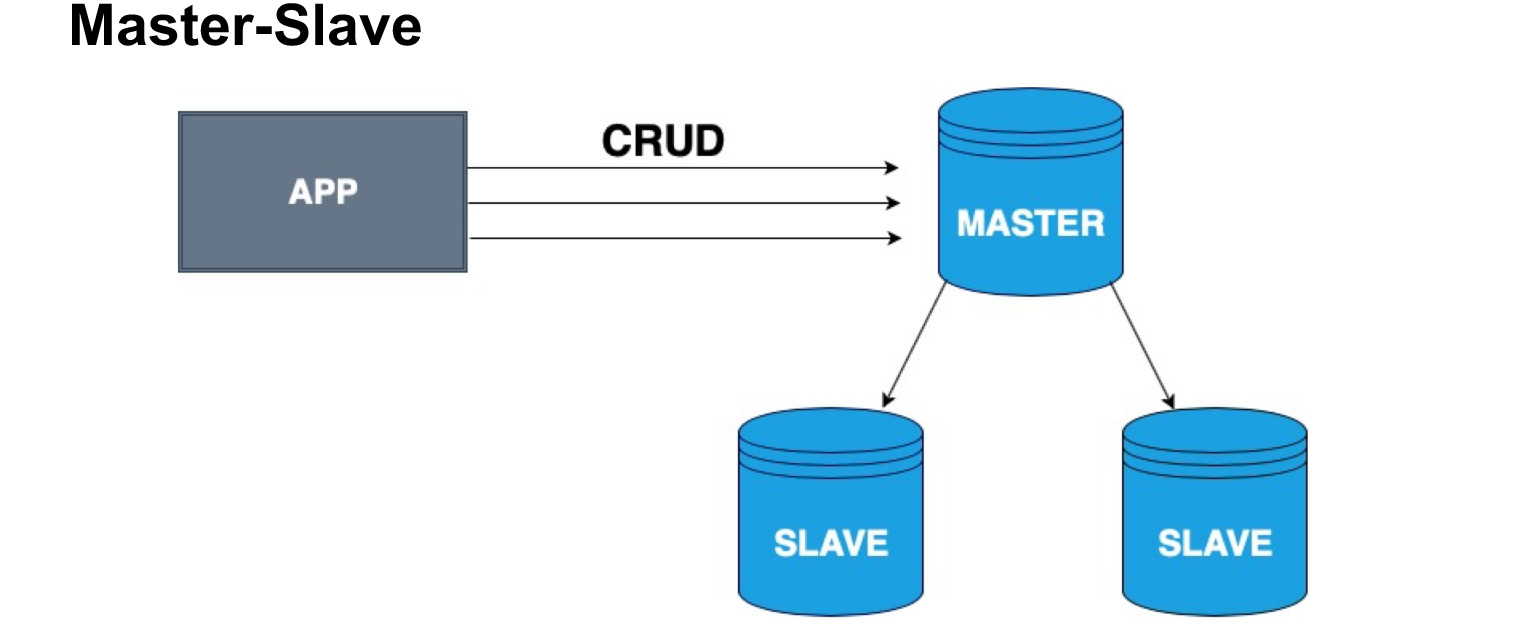
Para distribuir correctamente copias de bases de datos, se introduce el concepto de nodo maestro y nodo esclavo, maestro y esclavo. El esclavo a menudo se llama réplica o seguidor. Maestro: el nodo en el que nuestro usuario, nuestra aplicación, escribe. El maestro aplica todos los cambios, mantiene un registro de cambios y envía este registro al esclavo. El esclavo no acepta cambios de los usuarios, solo aplica los cambios al registro del maestro. Tenga en cuenta que Master no envía una copia cada vez, pero envía cambios. El esclavo pasa por alto estos cambios y recibe la misma copia de los datos que en el maestro.
Un parámetro muy importante de un sistema replicado es que las solicitudes se ejecutan de forma sincrónica o asincrónica. ¿Qué es una solicitud síncrona? Esto es cuando el Maestro envía una solicitud a una réplica síncrona, a un Esclavo sincrónico, y espera que el Esclavo diga "Sí, acepté" y devuelve la confirmación al Maestro. Solo entonces el Maestro devolverá la respuesta al usuario. Si la réplica es asincrónica, el maestro envía una solicitud a la réplica, pero inmediatamente le dice al usuario que "Eso es, lo anoté". Vamos a ver cómo funciona.
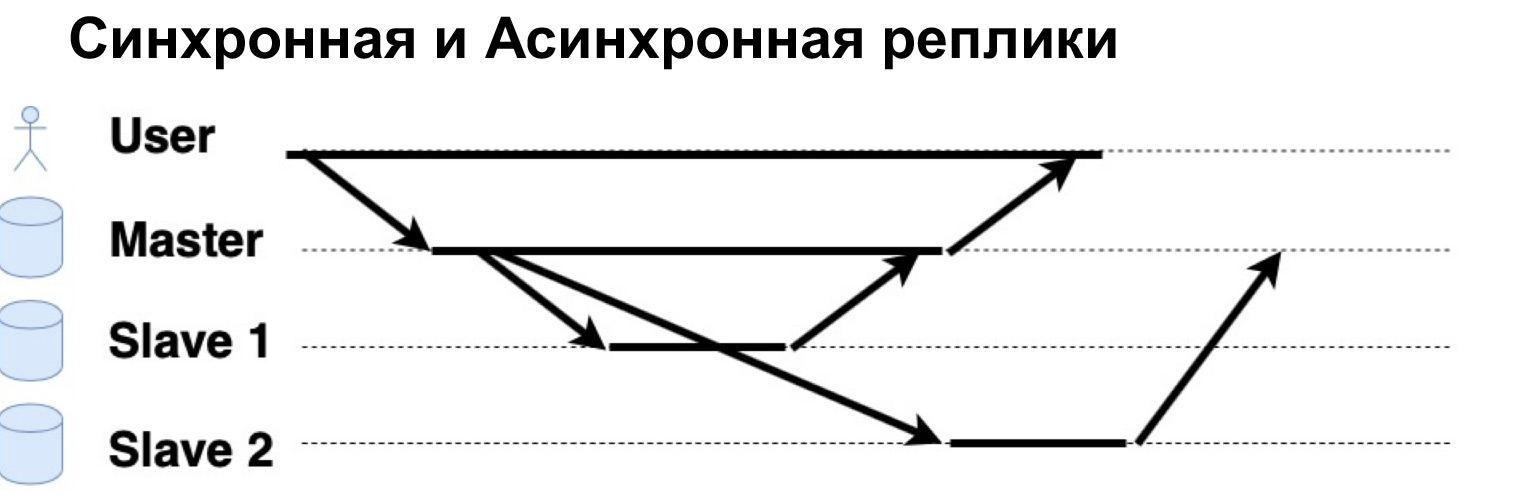
Hay un usuario que ha escrito datos en Master. El Maestro los envió a dos réplicas, esperó una respuesta de una réplica sincrónica e inmediatamente dio una respuesta al usuario. Una réplica asincrónica grabó y le dijo al Maestro: "Sí, está bien, los datos están escritos".
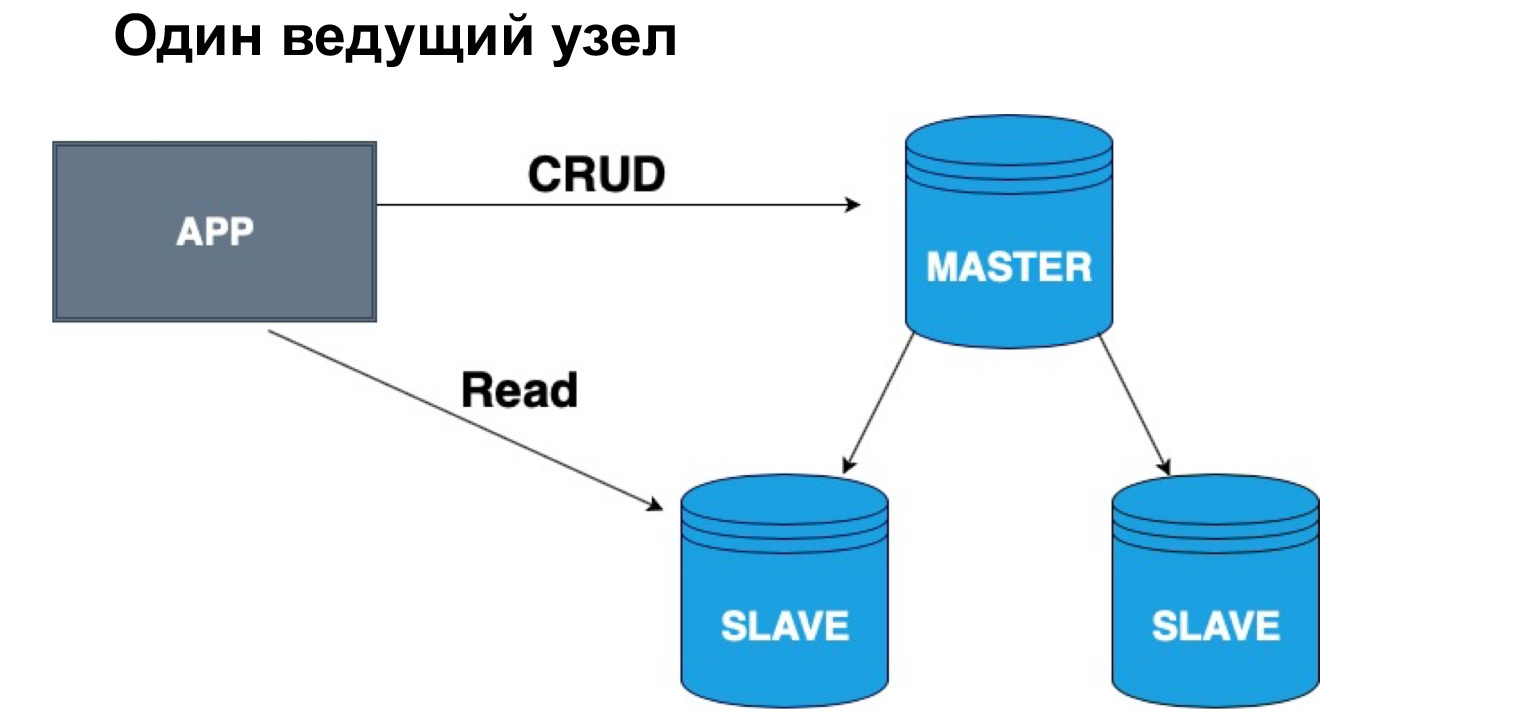
En términos de tal jerarquía, maestro y esclavo, podemos tener una cabeza o varias. Si tenemos un nodo maestro, es muy conveniente escribir en él, pero puede leer desde una réplica sincrónica. ¿Por qué exactamente de sincrónico? Porque una réplica sincrónica asegura que los datos estén actualizados con la máxima precisión.
Cuando se aplica una consulta a los datos, una operación desde el registro, también lleva tiempo. Por lo tanto, si para ti es importante el cien por ciento de precisión de los datos que deseas recibir, debes ir a leer, a seleccionar en el Master. Si no cree que los datos lleguen con un ligero retraso, puede leer desde el esclavo sincrónico. Si no es absolutamente crítico con la relevancia de los datos, puede leer, incluso desde la réplica asíncrona, descargando así el maestro y la réplica síncrona de las solicitudes.
La replicación también puede tener varios maestros. Diferentes aplicaciones pueden escribir a diferentes cabezas, y estos maestros luego resuelven los conflictos entre sí.
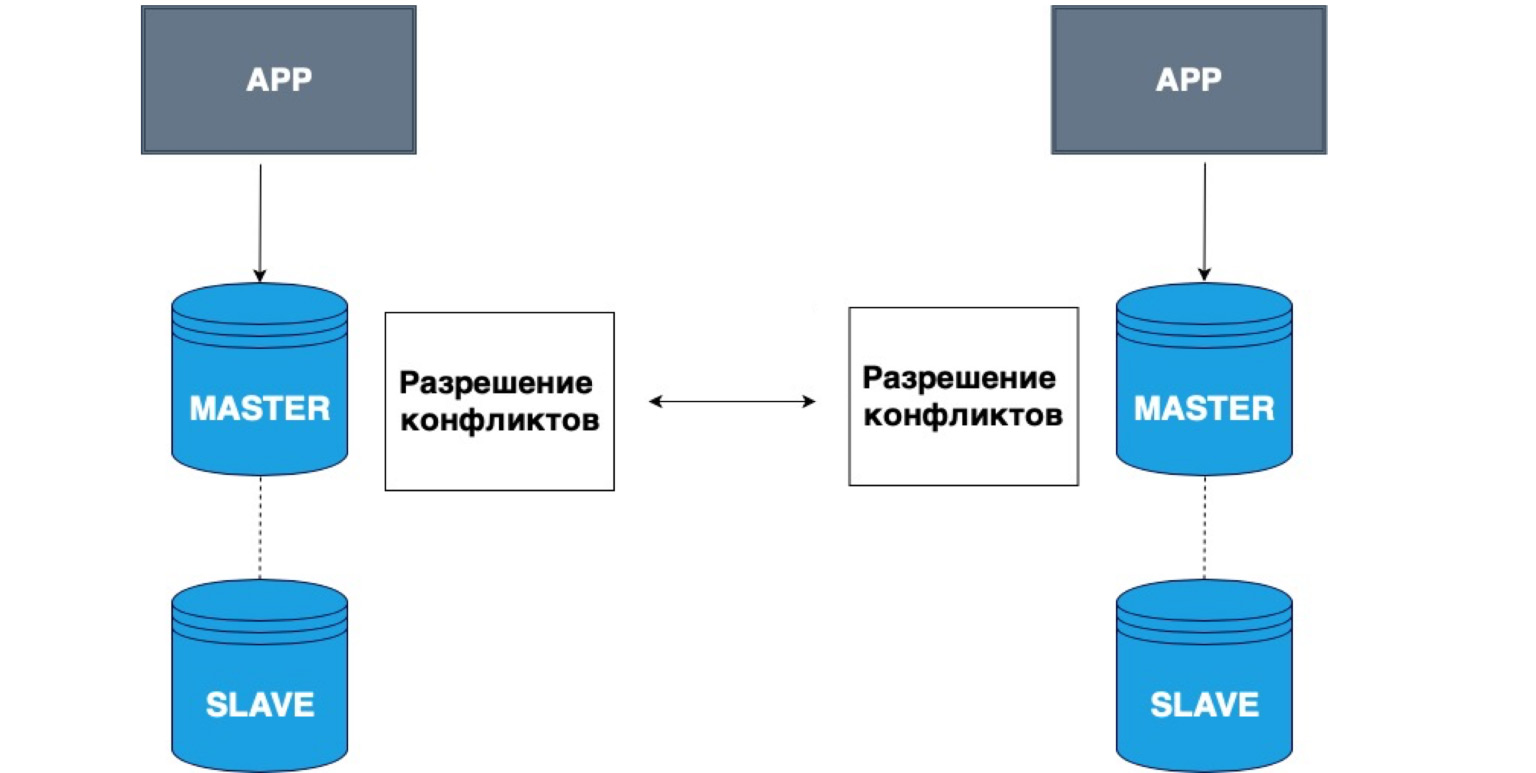
Un ejemplo muy simple del uso de estos datos son todo tipo de aplicaciones fuera de línea. Por ejemplo, tiene un calendario en su teléfono. Se ha desconectado de la red y ha registrado un evento en el calendario. En este caso, su almacenamiento local, su teléfono, es Master. Ha almacenado los datos en sí mismo, y cuando aparezca la red maestra, su copia local y la copia en el servidor resolverán los conflictos y combinarán estos datos.
Este es un ejemplo muy simple de tal replicación. A menudo se utiliza para la edición colaborativa de documentos en línea o cuando existe una probabilidad muy alta de perder la red.
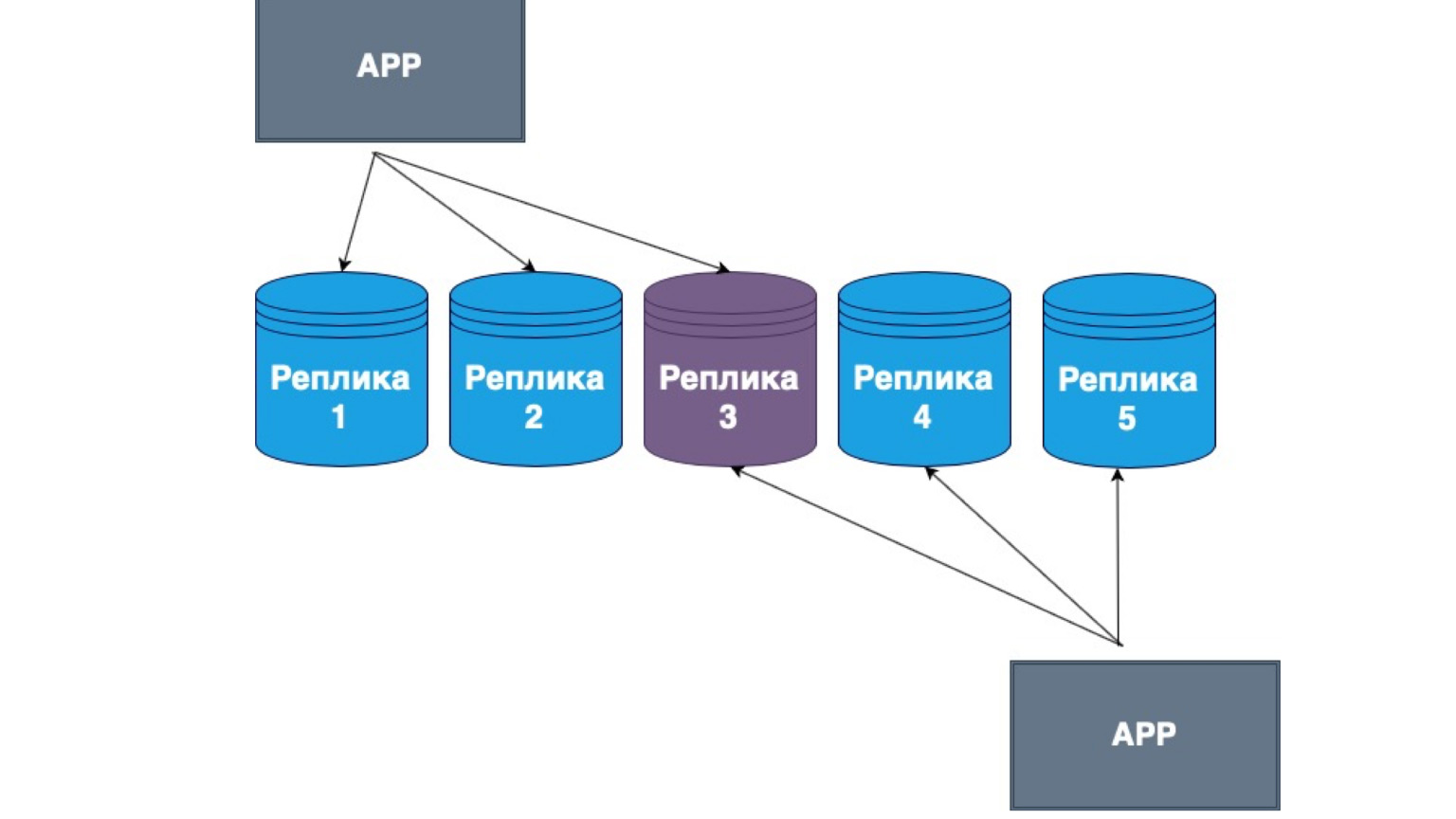
También existen réplicas sin maestro. ¿Lo que es? Esta es la replicación, en la que el propio cliente envía datos a la mayoría de las réplicas y también los lee de la mayoría de las réplicas. Aquí puede ver que nuestra réplica del medio es la intersección de nuestra lectura y actualización.
Es decir, garantizamos que cada vez que leemos los datos, entraremos en al menos una de las réplicas, en la que el dato sea más relevante. Y entre sí, las réplicas construyen un mecanismo de intercambio de información con el registro principal de cambios y conflictos entre réplicas. En este caso, muy a menudo es el cliente gordo el que se implementa. Si recibió datos de una réplica que contiene cambios más recientes que otra, simplemente envía los datos a otra réplica o resuelve el conflicto.

¿Qué es importante saber sobre la replicación? El punto principal de la replicación es la tolerancia a fallas del sistema, la alta disponibilidad de su servidor. Pase lo que pase con la base de datos, el sistema estará disponible, sus usuarios podrán escribir datos, y cuando se restaure la conexión con el Maestro o con otra réplica, también se restaurarán todos los datos.
La replicación es muy útil para descargar servidores y redistribuir las solicitudes de lectura del maestro a las réplicas. Podemos escalar esta lectura, crear más réplicas de lectura y hacer que nuestro sistema sea aún más rápido. También puede replicar consultas analíticas complejas a largo plazo que requieren una gran cantidad de bloqueos y pueden afectar la disponibilidad del sistema.
Usando aplicaciones fuera de línea como ejemplo, analizamos cómo puede almacenar dichos datos y resolver conflictos. En el caso de una réplica sincrónica, puede haber un retraso de replicación, es decir, un retraso de tiempo. En el caso de una réplica asincrónica, casi siempre está ahí. Es decir, cuando lee datos de una réplica asincrónica, debe comprender que es posible que no sean relevantes.
De acuerdo con la jerarquía, olvidé decir que cuando hay un maestro que está esperando una respuesta de una réplica sincrónica, es lógico suponer que si todas las réplicas son sincrónicas y algunas de repente dejan de estar disponibles, nuestro sistema no podrá guardar la solicitud. Luego, el maestro nos escribirá al primer esclavo sincrónico, recibirá una respuesta, solicitará el segundo esclavo, no recibirá respuesta y, como resultado, tendrá que revertir toda la transacción.
Por lo tanto, en tales sistemas, como regla, una réplica se hace sincrónica y el resto asincrónica. La réplica síncrona garantiza que sus datos aún estén en otro lugar. Es decir, además del Master, con el que puede pasar algo, garantizamos que hay al menos un nodo más que contiene una copia completa de exactamente el mismo log de transacciones, los mismos datos.
La réplica asincrónica, por otro lado, no garantiza la integridad de los datos. Si solo tenemos réplicas asincrónicas y el maestro se ha desconectado, es posible que se queden atrás, es posible que los datos aún no hayan llegado. En tales casos, como regla, construyen una jerarquía tal que o tenemos Master, una réplica sincrónica y el resto son asincrónicos, o tenemos Master y todas las réplicas son asincrónicas, si la persistencia de datos no es importante para nosotros.
Hay un "pero": todas las réplicas deben tener la misma configuración. Si hablamos de PostgreSQL como ejemplo, deben tener la misma versión de PostgreSQL en sí, porque diferentes versiones de la base de datos pueden tener diferente formato de registro de operaciones. Y si la réplica proviene de una versión diferente, es posible que simplemente no lea las operaciones que escribió la otra base.
¿Qué es una réplica? Ésta es una copia completa de todos los datos. Digamos que hay tantos datos que el servidor no puede manejarlos. ¿Cuál es la primera solución?
La primera solución es comprar una máquina más cara con más memoria, una CPU más grande y un disco más grande. Esta decisión será correcta en su mayor parte, siempre y cuando no enfrente el problema del alto costo del hierro. Algún día será demasiado caro comprar un coche nuevo, o simplemente no habrá ningún lugar donde crecer. Hay una gran cantidad de datos que es simplemente físicamente imposible de caber en una máquina.
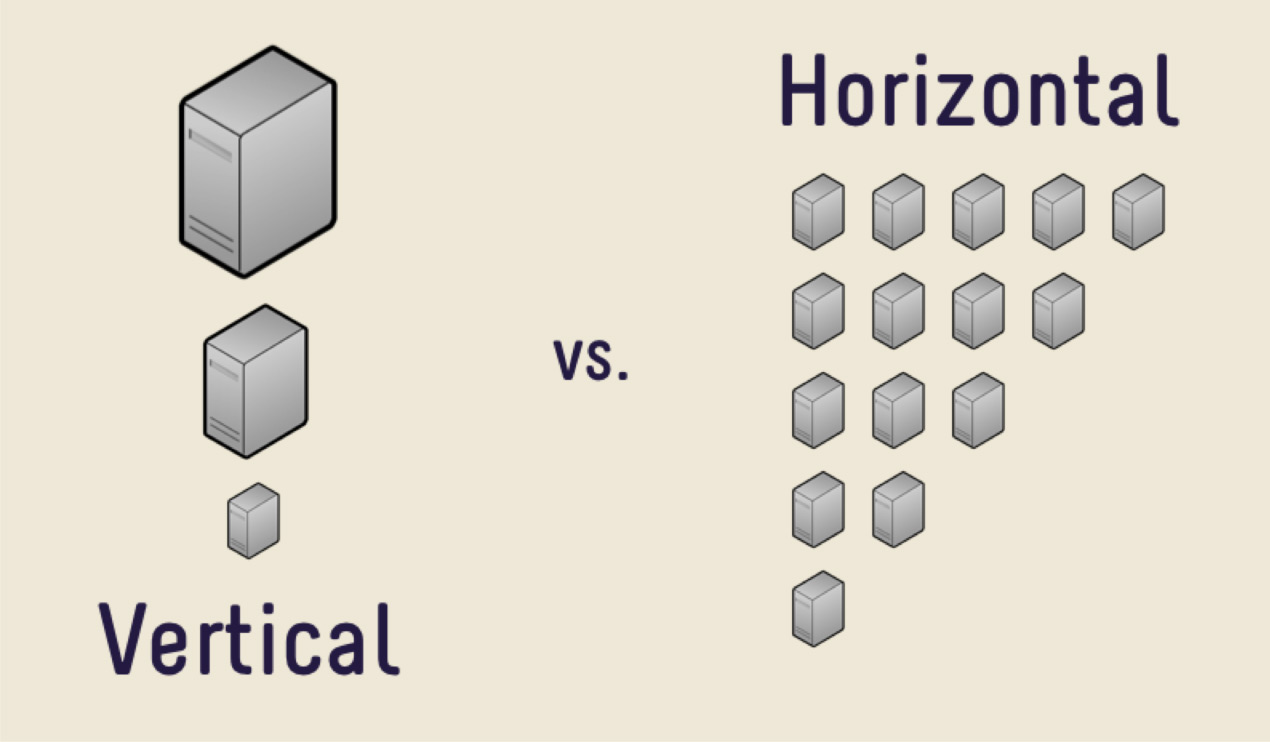
En tales casos, puede utilizar la escala horizontal. Lo que vimos anteriormente, el aumento del rendimiento por máquina, es el escalado vertical. El aumento del número de máquinas es de escala horizontal.
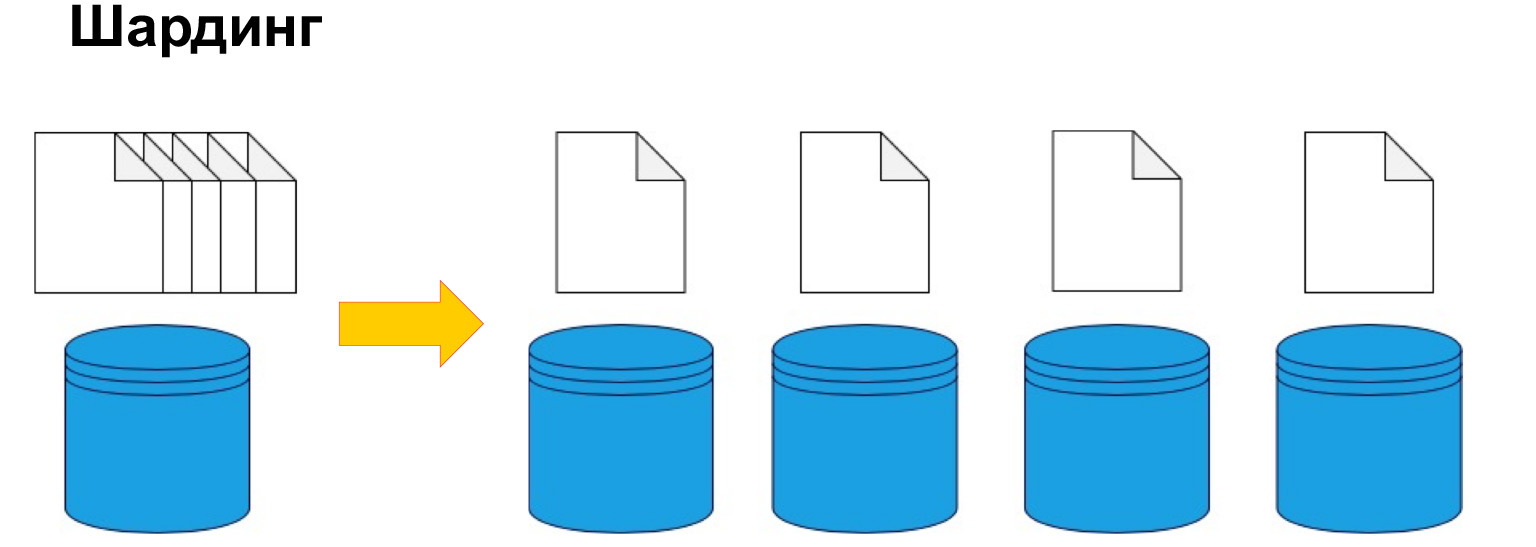
Para dividir los datos por máquina, se usa fragmentación o, en otras palabras, particionamiento. Es decir, dividir los datos en secciones y bloques por clave, por ID, por fecha. Hablaremos de esto más a fondo, este es uno de los parámetros clave, pero el punto es precisamente dividir los datos según un determinado criterio y enviarlos a diferentes máquinas. Por lo tanto, nuestras máquinas pueden volverse menos eficientes, pero el sistema aún puede funcionar y recibir datos de diferentes máquinas.
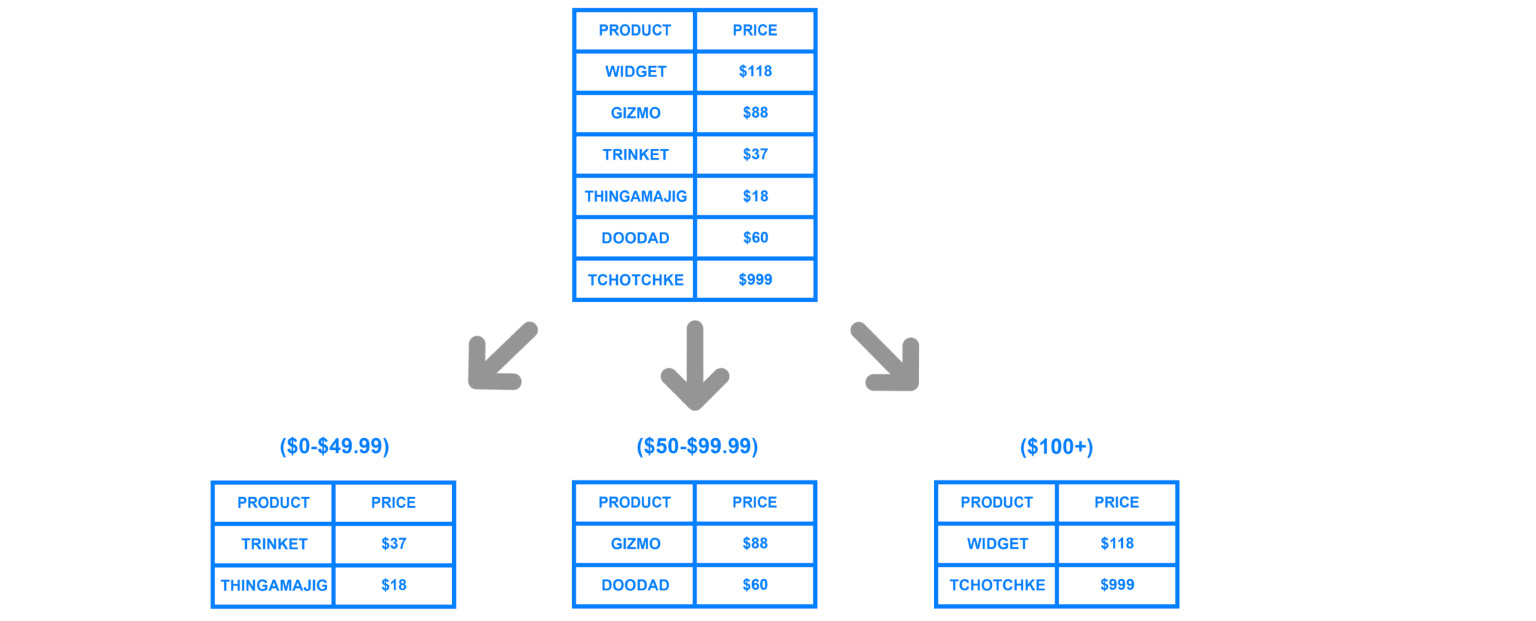
Para comprender en general dónde están los datos, necesita una determinada tabla de correspondencia del fragmento, nuestra copia y datos.
Hay ocasiones en las que no se utiliza un almacén de datos especial y el cliente simplemente recorre cada fragmento por turno y comprueba si hay datos que coincidan con su solicitud.
Hay una capa de software especial que almacena cierto conocimiento sobre qué fragmento se encuentra en qué rango de datos. Y, en consecuencia, va exactamente allí, hasta el mismo nodo donde se encuentran los datos necesarios.

Hay un cliente gordo. Esto es cuando no cosimos al cliente en una capa separada, sino que cosimos en él los datos sobre cómo se fragmentan nuestros datos.
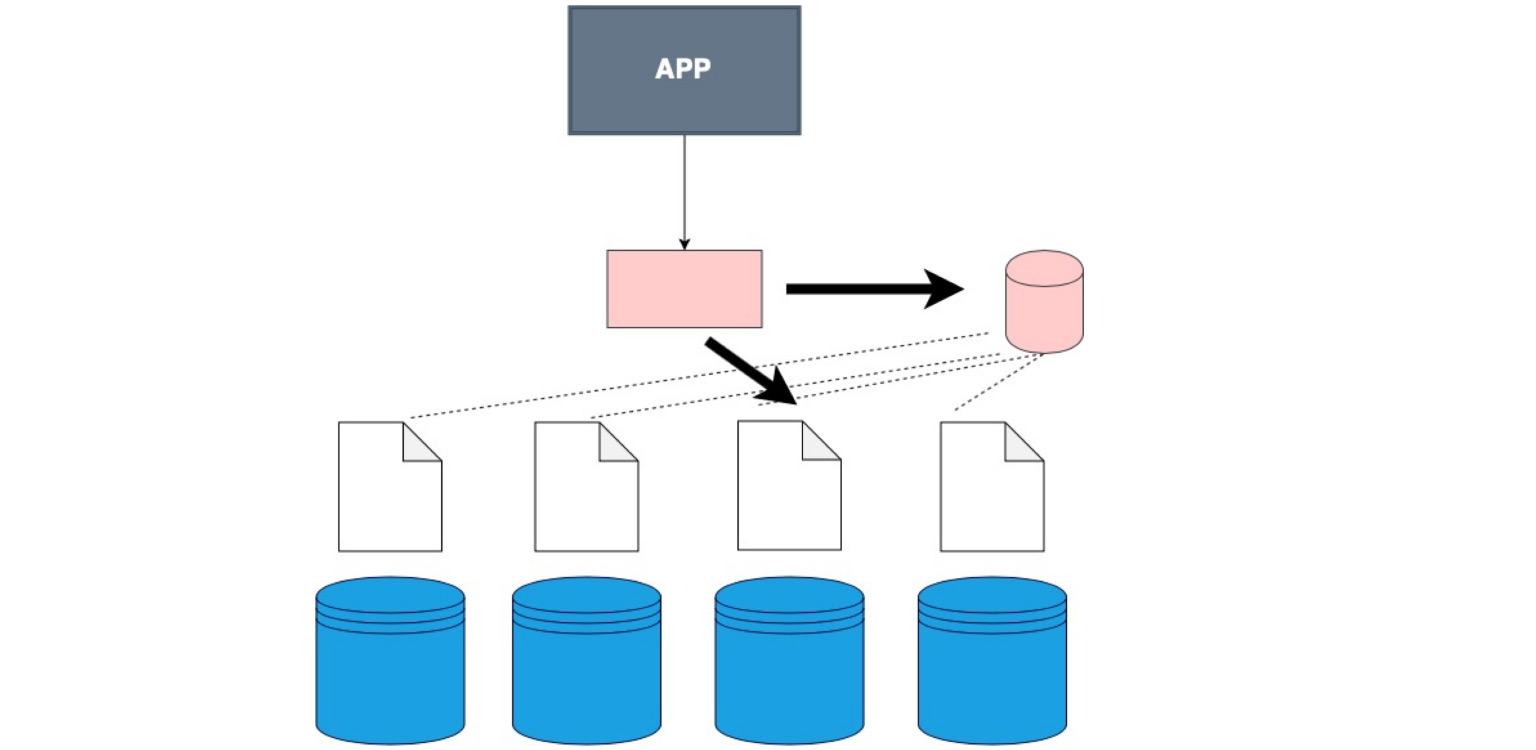
Este es el caso. Por cierto, es el más utilizado. Lo bueno es que nuestra aplicación, nuestro cliente, incluso el código que escribes, no sabe que la tabla está fragmentada, aunque lo indicamos en la configuración, en la propia base de datos. Simplemente le decimos - seleccione, y ya en la base de datos, hay una división en fragmentos y una comprensión de dónde seleccionar. Aquí, en el propio código, define de dónde leer los datos.
Existen servicios especiales que ayudan a estructurar y actualizar en general la información. Es difícil mantenerlo coherente y relevante. Hemos seleccionado algo, hemos registrado nuevos datos. O algo ha cambiado y necesitamos enrutar nuestras solicitudes de manera muy correcta. Hay servicios especiales para coordinar solicitudes. Uno de ellos es Zookeper. Puedes ver cómo funcionan en general. Una estructura muy interesante. Ahorraron mucho tiempo y nervios a los desarrolladores.
¿Qué es importante, qué aspectos a tener en cuenta al realizar particiones? Es importante comprender qué clave usaremos para dividir en fragmentos. Recopilar todos estos datos es bastante caro, por lo que es muy importante no equivocarse acerca de cómo se utilizarán potencialmente los datos en el futuro. Si hicimos la fragmentación bien y correctamente, entonces con las consultas más utilizadas siempre sabremos a qué réplica ir.
Por ejemplo, si, de acuerdo con los ID del usuario, almacenamos todos sus datos en ciertas réplicas, entendemos que podemos llegar a esta réplica y hacer todas las uniones en ella. Pero mantenerlo por identificación no es la mejor idea. Ahora te diré por qué.
Si identificamos incorrectamente la clave en la partición, si tenemos una consulta muy compleja, entonces realmente tenemos que ir a diferentes fragmentos, combinar todos los datos y solo luego dárselos a la aplicación. Afortunadamente, la mayoría de los DBMS hacen esto por nosotros. Pero, ¿qué tipo de gastos generales se producirían con consultas mal escritas? ¿O en fragmentación, que está rota en el nodo incorrecto?
Acerca de las identificaciones. Si el sistema funciona solo con nuevos usuarios y tenemos un aumento en los ID, entonces todas las solicitudes irán al último nodo.
¿Lo que pasa? Las otras tres máquinas en funcionamiento permanecerán inactivas. Y este automóvil simplemente se quemará, el llamado punto caliente. Este es el cuello de botella de su sistema potencial, el lugar que incluso puede rechazar las conexiones.
Por lo tanto, cuando definimos la clave de fragmentación, es muy importante comprender qué tan equilibrados estarán estos nodos. Los hash se utilizan con mucha frecuencia, es una disposición de datos más o menos neutral y equilibrada. Pero si tiene una función hash en una clave, entonces no podrá seleccionar, por ejemplo, por rangos. Es lógico, porque los rangos no se pueden dividir en diferentes fragmentos.
Por fecha, lo mismo. Si, por ejemplo, dispersamos análisis y creamos fragmentos por fecha, entonces, por supuesto, un fragmento de hace diez años no se utilizará en absoluto. No es rentable para nosotros. Y siempre es muy caro reconstruir los datos y endurecerlos.
Responderé a la pregunta que vino antes. ¿Qué es mejor hacer: definir índices o crear fragmentos? Índices, por supuesto.
Mira, los fragmentos son máquinas separadas con toda una infraestructura elevada. Y este componente intermedio contiene algo parecido a índices. Hay una búsqueda rápida por parámetros: dónde, dónde ir. Aquí está la proporción. Pero si hay fragmentación, la imagen final será así:

hay aplicaciones, una especie de cabeza que sabe a dónde ir. Y hay fragmentos, en cada uno de los cuales se configura una réplica. Esta es una sobrecarga realmente grande si no hay muchos datos. Es decir, debe recurrir a la fragmentación solo cuando realmente haya alcanzado el límite de escala vertical, cuando comprar una máquina más cara no sea relevante para sus datos o ingresos. Luego puede comprar varios autos diferentes y más baratos y construir una arquitectura de este tipo en ellos.
Creo que para qué sirven las réplicas está claro: como los fragmentos están rotos, son piezas de bases de datos, pero son algo únicas. Se encuentran solo en estos lugares. También los dividimos en copias, lo que hace que nuestros nodos sean tolerantes a fallas y estén asegurados contra problemas.

Lo más importante: la fragmentación se usa exactamente donde no solo desea dividir los datos en una clasificación, sino exactamente donde realmente hay muchos datos.
Ahora, profundicemos un poco más en los modelos de datos y veamos cómo se pueden almacenar los datos.
Las bases de datos relacionales que analizamos antes tienen una gran cantidad de ventajas, porque, en primer lugar, son muy comunes y comprensibles para todos. Muestran visualmente la relación entre los objetos y proporcionan integridad.
Pero hay una desventaja: requieren una estructura clara. Hay una tabla en la que debemos empujar todos los datos. Si observa toda la información y los hechos que recopilamos en general, son muy diferentes. Es decir, podemos trabajar con datos de productos, con datos de usuarios, mensajes, etc. Estos datos realmente requieren una estructura e integridad claras. Una base de datos relacional es ideal para ellos.
Pero supongamos que tenemos, por ejemplo, un registro de operaciones o una descripción de objetos, donde cada objeto tiene características diferentes. Nosotros, por supuesto, podemos escribir esto en un jason en una base de datos relacional y alegrarnos de que crezca con nosotros sin fin.
Y podemos mirar otros esquemas, en otros sistemas de almacenamiento. NoSQL es una abreviatura muy llamativa, incluso directamente provocativa: "no SQL". ¿Cómo ocurrió?
Cuando las personas se enfrentaron al hecho de que las bases de datos relacionales no tienen éxito en todas partes, organizaron una conferencia que necesitaba un hashtag y, por lo tanto, se les ocurrió #NoSQL. Echó raíces. Más tarde empezaron a decir no "no SQL", sino "no solo SQL". Es cualquier cosa que no sea relacional: una gran familia de bases de datos diferentes que no están tan rígidamente estructuradas, esquemáticas y tabulares como las bases de datos relacionales.
La familia de modelos de datos no relacionales se divide en cuatro tipos: bases de datos de valor clave, orientadas a documentos, columnas y gráficas. Consideremos cada uno de estos puntos, averigüe qué datos es mejor almacenar en cuál de ellos y para qué se utilizan.

Valor clave. Este es el más simple. Aquí está el diccionario, aquí está la proporción. Esta es una base de datos en la que los datos se almacenan por claves, y no importa qué hay debajo de una clave en particular. Tenemos la clave en sí y los datos pueden ser estructuras simples y mucho más complejas. Lo bueno de esta base de datos es que, como un índice, busca datos muy rápidamente. Esta es la razón por la que el valor clave se usa con mucha frecuencia para la caché. La ventaja es que nuestro valor puede ser diferente en diferentes claves.
Podemos usar la clave, por ejemplo, para almacenar sesiones de usuario. El usuario hizo clic, escribimos esto en valor. Es un modelo sin esquema, de datos sin un esquema específico, estructura de valores. Debido a que es una estructura muy simple, es rápido y fácil de escalar. Ya tenemos las claves y podemos fragmentarlas muy fácilmente, hacer sus hashes. Es una de las bases de datos más escalables.
Algunos ejemplos son Redis, Memcached, Amazon DynamoDB, Riak, LevelDB. Puede ver las funciones de implementación de los almacenamientos de valores-clave.

Las bases de datos de documentos son muy similares al valor clave en algunos de sus usos. Pero su unidad es un documento. Esta es una estructura tan compleja mediante la cual podemos seleccionar ciertos datos, realizar operaciones masivas: inserción masiva, actualización masiva.
Cada documento puede almacenar en sí mismo, como regla, XML, JSON o BSON: JSON almacenado en binario. Pero ahora casi siempre es JSON o BSON. Esto también es como un par clave-valor, puede imaginarlo como una tabla en la que cada fila tiene ciertas características, y podemos obtener algo de ella usando estas claves.
La ventaja de las bases de datos orientadas a documentos: tienen una disponibilidad y flexibilidad de datos muy alta. En cualquier documento, en cualquier JSON, puede escribir absolutamente cualquier conjunto de datos. Y se utilizan con mucha frecuencia, por ejemplo, cuando necesita crear un catálogo y cuando cada producto del catálogo puede tener características diferentes.
O, por ejemplo, perfiles de usuario. Alguien indicó su película favorita, alguien, su comida favorita. Para no pegar todo en un campo, que almacenará no está claro qué, podemos escribir todo en JSON de una base de documentos.
Otro modelo que es conveniente para almacenar datos son las bases de datos en columnas. También se denominan bases de datos en columnas.

Esta es una estructura muy interesante que se utiliza, a mi parecer, en casi todos los proyectos grandes y complejos. Tal base de datos implica que almacenamos datos en el disco no en líneas, sino en columnas. Se utiliza para búsquedas muy rápidas sobre una gran cantidad de datos. Como regla general, para análisis, cuando necesita seleccionar valores solo de ciertas columnas.
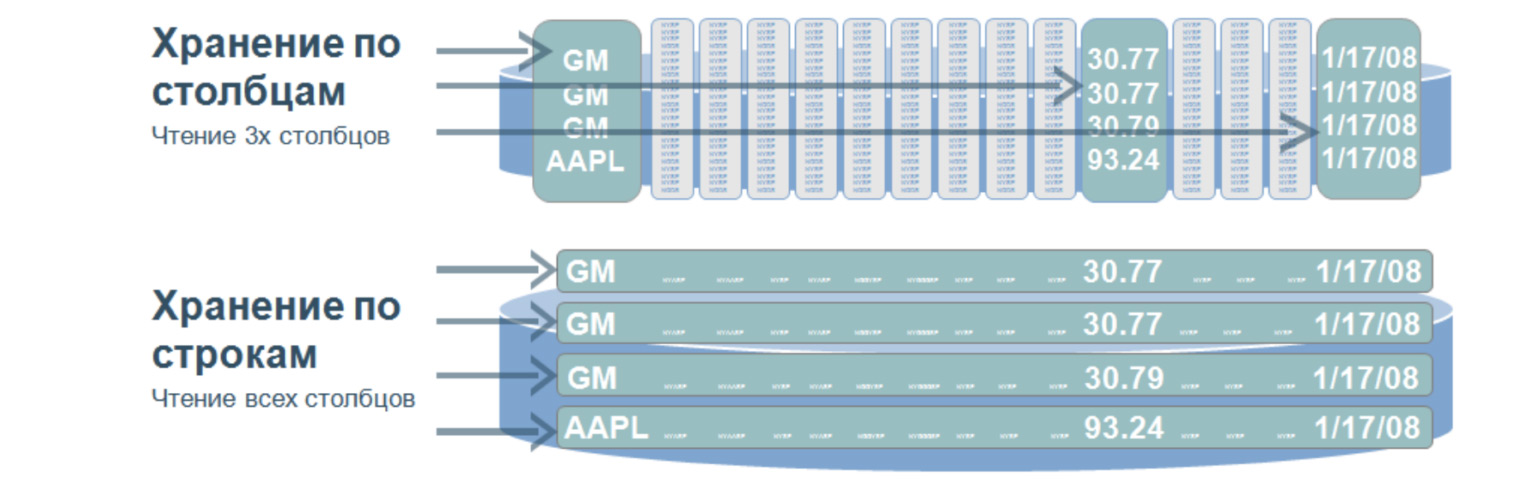
Imaginemos que tenemos una mesa enorme. Y si almacenamos datos en líneas, entonces sería lo que está debajo: una gran cantidad de líneas. Para seleccionar incluso tres parámetros de esta tabla, necesitamos recorrer toda la tabla. Y cuando almacenamos valores por columnas, cuando seleccionamos por tres valores, necesitamos pasar por solo tres de esas líneas, hablando en términos generales, porque nuestras columnas están escritas así. Pasando por estas tres líneas, inmediatamente obtenemos el número de serie del valor que necesitamos y lo obtenemos de las otras columnas.
¿Cuál es la ventaja de estas bases de datos? Debido a que buscan una pequeña cantidad de datos, tienen una velocidad de procesamiento de consultas muy alta y una gran flexibilidad de datos, porque podemos agregar cualquier cantidad de columnas sin cambiar la estructura. Aquí, no como en las bases de datos relacionales, no necesitamos forzar nuestros datos en ciertos marcos.
Los columnar más populares son probablemente Cassandra, HBase y ClickHouse. Pruébelos. Es muy interesante invertir la proporción de filas y columnas en tu cabeza. Y esto es un acceso realmente eficiente y rápido a grandes cantidades de datos.

También existe una familia de bases de datos de gráficos. También contienen nodos y bordes. Los bordes se utilizan para mostrar relaciones, al igual que en las bases de datos relacionales. Pero las bases de los gráficos pueden crecer infinitamente en diferentes direcciones. Por tanto, es más flexible. Tiene una velocidad de búsqueda muy alta, porque no es necesario seleccionar y unir todas las tablas. Nuestro nodo tiene inmediatamente bordes que muestran la relación con todos los diferentes objetos.
¿Para qué se utilizan estas bases de datos? La mayoría de las veces, solo para mostrar la relación. Por ejemplo, en las redes sociales, puedes responder a la pregunta de quién sigue a quién. Inmediatamente tenemos enlaces a todos los seguidores de la persona adecuada. Aún muy a menudo, estas bases de datos se utilizan para identificar esquemas de fraude, porque esto también está asociado con la demostración de la relación de las transacciones entre sí. Por ejemplo, puede rastrear cuándo se usó la misma tarjeta bancaria en otra ciudad o cuándo alguien más ingresó a la cuenta de otro usuario desde la misma dirección IP.
Son estas relaciones complejas las que ayudan a resolver situaciones inusuales que a menudo se utilizan para analizar tales interacciones y relaciones.
Las bases de datos no relacionales no reemplazan a las bases de datos relacionales. Son simplemente diferentes. Diferente formato de datos y diferente lógica de su trabajo, ni peor ni mejor. Es solo un enfoque diferente para otros datos. Y sí, las bases de datos no relacionales se utilizan mucho. No es necesario que les tengas miedo, al contrario, debes probarlos.
Si crea un caché, entonces, por supuesto, tome algún tipo de Redis, una clave-valor simple y rápida. Si tiene una gran cantidad de registros para analizar, puede colocarlos en ClickHouse o en alguna base de columnas, que luego será muy conveniente para buscar. O escríbalo en la base del documento, porque puede haber un significado diferente de documentos. Esto también puede resultar útil para la selección.
Elija un modelo de datos en función de los datos que utilizará. Ya sea relacional o no relacional. Describe los datos. De esta manera, puede encontrar el almacenamiento más adecuado que puede escalar en el futuro.

Hoy ha aprendido mucho sobre varios problemas y formas de almacenar datos. Repetiré una vez más lo que dije al principio: no es necesario que sepas todo en detalle, no es necesario ahondar en una sola cosa. Si está interesado, por supuesto que puede. Pero es importante saber si existe, qué enfoques existen y cómo se puede pensar. Si necesita tolerancia a fallas, tiene sentido hacer una réplica. Supongamos que anoté los datos, pero no los vi. Entonces, probablemente, mi comentario dio un retraso. No es necesario reinventar la rueda; ya existen muchas soluciones listas para usar para diferentes tareas. Amplíe sus horizontes, y si aparece un error o algún otro problema, comprenderá exactamente dónde ocurrió el error por las características del error, y podrá encontrar una solución a través del motor de búsqueda. Gracias por su atención.