
El artículo analiza el problema de la limpieza de imágenes que se acumulan en los registros de contenedores (Docker Registry y sus análogos) en la realidad de las canalizaciones de CI / CD modernas para aplicaciones nativas de la nube entregadas a Kubernetes. Se dan los principales criterios de relevancia de las imágenes y las consiguientes dificultades en la automatización de la limpieza, el ahorro de espacio y la satisfacción de las necesidades de los equipos. Finalmente, usando un ejemplo de un proyecto de código abierto específico, le diremos cómo se pueden superar estas dificultades.
Introducción
La cantidad de imágenes en el registro de contenedores puede crecer rápidamente, ocupando más espacio de almacenamiento y, en consecuencia, aumentando significativamente su costo. Para controlar, limitar o mantener un crecimiento aceptable del espacio ocupado en el registro, se acepta:
- use un número fijo de etiquetas para las imágenes;
- limpiar imágenes de cualquier forma.
La primera limitación a veces es válida para equipos pequeños. Si los desarrolladores tienen suficiente etiqueta permanente (
latest, main, test, borisetc.), el registro no se hinchará en tamaño y puede ser un largo tiempo de no pensar en la limpieza. Después de todo, todas las imágenes irrelevantes están deshilachadas y simplemente no queda trabajo por limpiar (todo lo hace un recolector de basura habitual).
Sin embargo, este enfoque restringe severamente el desarrollo y rara vez se aplica a los proyectos de CI / CD en la actualidad. La automatización se ha convertido en una parte integral del desarrolloque le permite probar, implementar y ofrecer nuevas funciones a los usuarios mucho más rápido. Por ejemplo, en todos nuestros proyectos, se crea automáticamente una canalización de CI en cada confirmación. Construye una imagen, la prueba, la implementa en varios circuitos de Kubernetes para depurar y verificar el resto, y si todo va bien, los cambios llegan al usuario final. Y esto no es ciencia espacial durante mucho tiempo, sino la vida cotidiana para muchos, probablemente para usted, ya que está leyendo este artículo.
Dado que se eliminan errores y se desarrollan nuevas funcionalidades en paralelo, y se pueden realizar lanzamientos varias veces al día, es obvio que el proceso de desarrollo va acompañado de una cantidad significativa de confirmaciones, lo que significa una gran cantidad de imágenes en el registro.... Como resultado, surge la cuestión de organizar una limpieza del registro eficaz. eliminación de imágenes irrelevantes.
Pero, ¿cómo saber si una imagen está actualizada?
Criterios de relevancia de la imagen
En la gran mayoría de los casos, los criterios principales serán los siguientes:
1. El primero (el más obvio y el más crítico de todos) son las imágenes que se utilizan actualmente en Kubernetes . Eliminar estas imágenes puede generar costos de tiempo de inactividad importantes para la producción (por ejemplo, es posible que se requieran imágenes durante la replicación) o anular los esfuerzos del equipo que está involucrado en la depuración en cualquiera de los circuitos. (Por esta razón, incluso creamos un exportador de Prometheus especial que monitorea la ausencia de tales imágenes en cualquier clúster de Kubernetes).
2. El segundo (menos obvio, pero también muy importante y nuevamente relacionado con la operación): imágenes que deben revertirse en caso de problemas graves problemasen la versión actual. Por ejemplo, en el caso de Helm, estas son las imágenes que se utilizan en las versiones guardadas de la versión. (Por cierto, el límite predeterminado en Helm es de 256 revisiones, ¿pero casi nadie tiene la necesidad de guardar una cantidad tan grande de versiones? ..) Después de todo, para esto, en particular, almacenamos versiones para que pueda luego uso, es decir "Retroceda" a ellos si es necesario.
3. En tercer lugar, las necesidades de los desarrolladores : todas las imágenes que están asociadas con su trabajo actual. Por ejemplo, si estamos considerando PR, entonces tiene sentido dejar la imagen correspondiente al último compromiso y, digamos, el compromiso anterior: de esta manera el desarrollador puede volver rápidamente a cualquier tarea y trabajar con los últimos cambios.
4. Cuarto: imágenes quecorresponden a las versiones de nuestra aplicación , es decir son el producto final: v1.0.0, 20.04.01, sierra, etc.
NB: Los criterios aquí definidos se formularon en base a la experiencia de interactuar con decenas de equipos de desarrollo de diferentes empresas. Sin embargo, por supuesto, dependiendo de las características específicas de los procesos de desarrollo y la infraestructura utilizada (por ejemplo, no se utiliza Kubernetes), estos criterios pueden diferir.
Elegibilidad y soluciones existentes
Los servicios de registro de contenedores populares, por regla general, ofrecen sus propias políticas de limpieza de imágenes: en ellos puede definir las condiciones bajo las cuales se elimina una etiqueta del registro. Sin embargo, estas condiciones están limitadas por parámetros como nombres, tiempo de creación y número de etiquetas *.
* Depende de las implementaciones específicas del registro de contenedores. Consideramos las posibilidades de las siguientes soluciones: Azure CR, Docker Hub, ECR, GCR, GitHub Packages, GitLab Container Registry, Harbour Registry, JFrog Artifactory, Quay.io, a partir de septiembre de 2020.
Este conjunto de parámetros es suficiente para satisfacer el cuarto criterio, es decir, seleccionar imágenes que coincidan con las versiones. Sin embargo, para todos los demás criterios, uno tiene que elegir algún tipo de solución de compromiso (política más estricta o, a la inversa, respetuosa), según las expectativas y las capacidades financieras.
Por ejemplo, el tercer criterio, relacionado con las necesidades de los desarrolladores, se puede resolver organizando procesos dentro de los equipos: denominación específica de imágenes, mantenimiento de listas de permisos especiales y acuerdos internos. Pero, en última instancia, aún debe automatizarse. Y si las posibilidades de las soluciones listas para usar no son suficientes, debe hacer algo por su cuenta.
La situación es similar con los dos primeros criterios: no se pueden satisfacer sin recibir datos del sistema externo, aquel donde se implementan las aplicaciones (en nuestro caso, es Kubernetes).
Ilustración de un flujo de trabajo en Git
Supongamos que trabaja de esta manera en Git: el
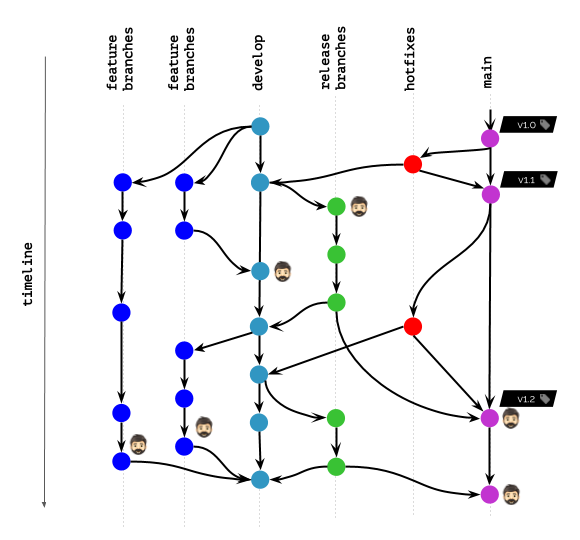
icono con una cabeza en el diagrama marca las imágenes de contenedor que están actualmente implementadas en Kubernetes para cualquier usuario (usuarios finales, probadores, administradores, etc.) o que los desarrolladores usan para depurar y metas similares.
¿Qué sucede si las políticas de depuración le permiten conservar (no eliminar) imágenes solo para los nombres de etiqueta especificados ?

Evidentemente, este escenario no agradará a nadie.
¿Qué cambiará si las políticas le permiten no eliminar imágenes durante un intervalo de tiempo determinado / número de confirmaciones recientes ?

El resultado ha mejorado mucho, pero todavía está lejos de ser ideal. Después de todo, todavía tenemos desarrolladores que necesitan imágenes en el registro (o incluso implementadas en K8s) para depurar errores ...
Resumiendo la situación actual en el mercado: las funciones disponibles en los registros de contenedores no ofrecen suficiente flexibilidad a la hora de limpiar, y el principal motivo es que no hay posibilidad interactuar con el mundo exterior . Resulta que los equipos que necesitan esta flexibilidad se ven obligados a implementar de forma independiente la eliminación de imágenes "fuera" mediante la API de Docker Registry (o la API nativa de la implementación correspondiente).
Sin embargo, buscábamos una solución universal que automatizara la limpieza de imágenes para diferentes equipos utilizando diferentes registros ...
Nuestro camino hacia la limpieza de imagen universal
¿De dónde viene esta necesidad? El hecho es que no somos un grupo separado de desarrolladores, sino un equipo que sirve a muchos de ellos a la vez, ayudando a resolver de manera integral los problemas de CI / CD. Y la principal herramienta técnica para esto es la utilidad werf de código abierto . Su peculiaridad es que no realiza una única función, sino que acompaña los procesos de entrega continua en todas las etapas: desde el montaje hasta el despliegue.
La publicación de imágenes en el registro * (inmediatamente después de su creación) es una función obvia de dicha utilidad. Y dado que las imágenes se guardan allí para su almacenamiento, entonces, si su almacenamiento no es ilimitado, debe ser responsable de su limpieza posterior. Se discutirá más a fondo cómo logramos el éxito en esto, cumpliendo con todos los criterios especificados.
* Aunque los registros en sí pueden ser diferentes (Docker Registry, GitLab Container Registry, Harbour, etc.), sus usuarios enfrentan los mismos problemas. La solución universal en nuestro caso no depende de la implementación del registro, ya que se ejecuta fuera de los propios registros y ofrece el mismo comportamiento para todos.
A pesar de que estamos usando werf como ejemplo de implementación, esperamos que los enfoques utilizados sean útiles para otros equipos que enfrentan dificultades similares.
Entonces, tomamos el externoimplementación de un mecanismo para limpiar imágenes, en lugar de las capacidades que ya están integradas en los registros de contenedores. El primer paso fue usar la API de Docker Registry para crear las mismas políticas primitivas por el número de etiquetas y el momento de su creación (mencionado anteriormente). Se ha agregado una lista de permitidos a estos en función de las imágenes utilizadas en la infraestructura implementada , es decir, Kubernetes. Para esto último, fue suficiente a través de la API de Kubernetes para revisar todos los recursos implementados y obtener una lista de valores
image.
Esta solución trivial cerró el problema más crítico (criterio n. ° 1), pero fue solo el comienzo de nuestro viaje para mejorar el mecanismo de limpieza. El siguiente paso, y mucho más interesante, fue la decisión de asociar las imágenes publicadas con el historial de Git .
Esquemas de etiquetado
Para empezar, elegimos un enfoque en el que la imagen final debe almacenar la información necesaria para la limpieza y construimos el proceso sobre esquemas de etiquetado. Al publicar una imagen, el usuario seleccionó una opción de etiquetado específica (
git-branch, git-commito git-tag) y usó el valor correspondiente. En los sistemas de CI, estos valores se establecieron automáticamente en función de las variables del entorno. Básicamente, la imagen final se asoció con una primitiva de Git específica , almacenando los datos necesarios para la limpieza en etiquetas.
Este enfoque dio como resultado un conjunto de políticas que permitieron que Git se usara como la única fuente de verdad:
- Al eliminar una rama / etiqueta en Git, las imágenes asociadas en el registro también se eliminaron automáticamente.
- La cantidad de imágenes asociadas con las etiquetas y confirmaciones de Git podría controlarse mediante la cantidad de etiquetas utilizadas en el esquema elegido y la hora en que se creó la confirmación asociada.
En general, la implementación resultante satisfizo nuestras necesidades, pero pronto nos esperaba un nuevo desafío. El hecho es que durante el uso de esquemas de etiquetado para primitivas de Git, encontramos una serie de deficiencias. (Dado que su descripción está más allá del alcance de este artículo, cualquiera puede leer los detalles aquí ). Entonces, después de decidir pasar a un enfoque más eficiente para el etiquetado (etiquetado basado en contenido), tuvimos que revisar la implementación de la limpieza de imágenes.
Nuevo algoritmo
¿Por qué? Cuando se etiqueta como basada en contenido, cada etiqueta puede acomodar múltiples confirmaciones en Git. Al limpiar imágenes, ya no puede confiar únicamente en la confirmación en la que se agregó la nueva etiqueta al registro.
Para el nuevo algoritmo de limpieza, se decidió alejarse de los esquemas de etiquetado y construir el proceso en metaimágenes , cada una de las cuales almacena un montón de:
- la confirmación sobre la que se realizó la publicación (no importa si la imagen se agregó, cambió o se mantuvo igual en el registro del contenedor);
- y nuestro identificador interno correspondiente a la imagen construida.
En otras palabras, las etiquetas publicadas estaban vinculadas a las confirmaciones en Git .
Configuración final y algoritmo general
Al configurar la limpieza, los usuarios ahora tienen acceso a las políticas mediante las cuales se realiza la selección de imágenes actualizadas. Cada una de estas políticas se define:
- múltiples referencias, es decir Etiquetas de Git o ramas de Git que se utilizan durante el rastreo;
- y el límite de las imágenes requeridas para cada referencia del conjunto.
Para ilustrar, así es como comenzó a verse la configuración de política predeterminada:
cleanup:
keepPolicies:
- references:
tag: /.*/
limit:
last: 10
- references:
branch: /.*/
limit:
last: 10
in: 168h
operator: And
imagesPerReference:
last: 2
in: 168h
operator: And
- references:
branch: /^(main|staging|production)$/
imagesPerReference:
last: 10
Esta configuración contiene tres políticas que cumplen con las siguientes reglas:
- Guarde una imagen para las últimas 10 etiquetas de Git (antes de la fecha en que se creó la etiqueta).
- No guarde más de 2 imágenes publicadas en la última semana, para no más de 10 sucursales con actividad durante la última semana.
- Guardar 10 imágenes para cada rama
main,stagingyproduction.
El algoritmo final se reduce a los siguientes pasos:
- Obtención de manifiestos del registro de contenedores.
- Excluyendo imágenes utilizadas en Kubernetes porque ya los hemos preseleccionado al sondear la API de K8s.
- Escaneando el historial de Git y excluyendo imágenes para políticas específicas.
- Eliminando las imágenes restantes.
Volviendo a nuestra ilustración, esto es lo que sucede con werf:
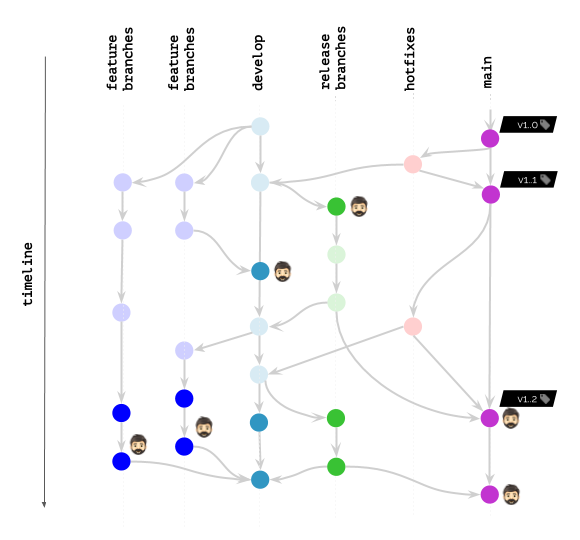
Sin embargo, incluso si no usa werf, un enfoque similar para la limpieza avanzada de imágenes, en una implementación u otra (de acuerdo con el enfoque preferido para etiquetar imágenes), también se puede aplicar en otros sistemas. / utilidades. Para hacer esto, basta con recordar los problemas que surgen y encontrar esas oportunidades en tu pila que te permitan construir su solución de la manera más fluida. Esperamos que el camino que hemos recorrido ayude a analizar su caso particular con nuevos detalles y pensamientos.
Conclusión
- Tarde o temprano, la mayoría de los equipos se enfrentan al problema del desbordamiento del registro.
- Al buscar soluciones, en primer lugar, es necesario determinar los criterios para la relevancia de la imagen.
- Las herramientas que ofrecen los populares servicios de registro de contenedores permiten una limpieza muy simple que no tiene en cuenta el "mundo exterior": las imágenes utilizadas en Kubernetes y las características específicas de los flujos de trabajo en equipo.
- Un algoritmo flexible y eficiente debe comprender los procesos de CI / CD, operar no solo con datos de imagen de Docker.
PD
Lea también en nuestro blog: