
Amazon SageMaker ofrece algo más que la capacidad de administrar portátiles en Jupyter, sino un servicio configurable que le permite crear, entrenar, optimizar e implementar modelos de aprendizaje automático. Un error común, especialmente al comenzar con SageMaker, es que necesita SageMaker Notebook Instance o SageMaker (Studio) Notebook para usar estos servicios. De hecho, puede ejecutar todos los servicios directamente desde su computadora local o incluso desde su IDE favorito.
Antes de continuar, comprendamos cómo interactuar con los servicios de Amazon SageMaker. Tiene dos API:
SageMaker Python SDK : una API de Python de alto nivel que abstrae el código para crear, entrenar e implementar modelos de aprendizaje automático. En particular, proporciona evaluadores para algoritmos integrados o de primera clase, y también admite marcos como TensorFlow, MXNET, etc. En la mayoría de los casos, lo usará para interactuar con tareas interactivas de aprendizaje automático.
SDK de AWSEs una API de bajo nivel que se utiliza para interactuar con todos los servicios de AWS compatibles, no necesariamente para SageMaker. AWS SDK está disponible para los lenguajes más populares como Java, Javascript, Python (boto), etc. En la mayoría de los casos, utilizará esta API para cosas como crear recursos de automatización o interactuar con otros servicios de AWS que no son compatibles con el SDK de SageMaker Python.
¿Por qué medio ambiente local?
El costo es lo primero que me viene a la mente, pero también la flexibilidad de usar su IDE nativo y la capacidad de trabajar sin conexión y ejecutar tareas en la nube de AWS cuando esté listo juegan un papel importante.
Cómo funciona el entorno local
Usted escribe el código para construir el modelo, pero en lugar de una instancia de SageMake Notebook o SageMaker Studio Notebook, lo hace en su máquina local en Jupyter o desde su IDE. Luego, cuando todo esté listo, comenzará a entrenar en instancias de SageMaker en AWS. Después del entrenamiento, el modelo se almacenará en AWS. Luego puede ejecutar la implementación o la conversión por lotes desde su máquina local.
Configurando el entorno con conda
Se recomienda configurar un entorno virtual Python. En nuestro caso, usaremos conda para administrar entornos virtuales, pero puede usar virtualenv. Una vez más, Amazon SageMaker usa conda para administrar entornos y paquetes. Se asume que ya tiene instalado conda, si no, vaya aquí .
Crea un nuevo entorno de conda
conda create -n sagemaker python=3Activamos y verificamos el entorno

Instalación de los paquetes necesarios
Para instalar paquetes, use los comandos
condao pip. Elijamos la opción con conda .
conda install -y pandas numpy matplotlibInstalación de paquetes de AWS
Instale AWS SDK para Python (boto), awscli y SageMaker Python SDK. El SDK de SageMaker Python no está disponible como paquete conda, así que lo usaremos aquí
pip.
pip install boto3 awscli sagemakerSi es la primera vez que usa awscli, debe configurarlo. Aquí puedes ver cómo hacerlo.
La segunda versión del SDK de SageMaker Python se instalará de forma predeterminada. Asegúrese de verificar los cambios importantes en la segunda versión del SDK.
Instalación de Jupyter y construcción del núcleo
conda install -c conda-forge jupyterlab
python -m ipykernel install --user --name sagemakerVerificamos el entorno y comprobamos las versiones
Inicie Jupyter a través de jupyter lab y seleccione el núcleo
sagemakerque creamos anteriormente.
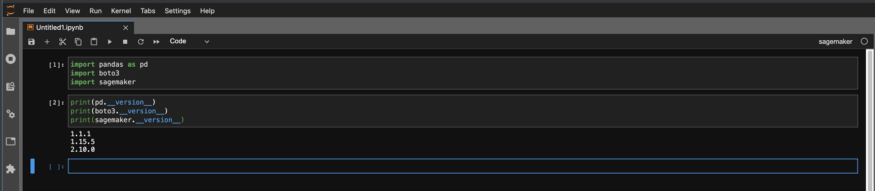
Luego, verifique las versiones en el cuaderno para asegurarse de que sean las que desea.
Creamos y formamos
Ahora puede comenzar a crear su modelo localmente y comenzar a aprender en AWS cuando esté listo.
Importar paquetes
Importe los paquetes necesarios y especifique el rol. La diferencia clave aquí es que debe especificar
arnroles directamente , no get_execution_role(). Dado que está ejecutando todo desde su máquina local con credenciales de AWS y no una instancia de notebook con una función, la función get_execution_role()no funcionará.
from sagemaker import image_uris # Use image_uris instead of get_image_uri
from sagemaker import TrainingInput # Use instead of sagemaker.session.s3_input
region = boto3.Session().region_name
container = image_uris.retrieve('image-classification',region)
bucket= 'your-bucket-name'
prefix = 'output'
SageMakerRole='arn:aws:iam::xxxxxxxxxx:role/service-role/AmazonSageMaker-ExecutionRole-20191208T093742'Crea un tasador
Cree un evaluador y establezca hiperparámetros como lo haría normalmente. En el siguiente ejemplo, entrenamos un clasificador de imágenes utilizando el algoritmo de clasificación de imágenes incorporado. También especifica el tipo de instancia de Stagemaker y la cantidad de instancias que desea utilizar para el entrenamiento.
s3_output_location = 's3://{}/output'.format(bucket, prefix)
classifier = sagemaker.estimator.Estimator(container,
role=SageMakerRole,
instance_count=1,
instance_type='ml.p2.xlarge',
volume_size = 50,
max_run = 360000,
input_mode= 'File',
output_path=s3_output_location)
classifier.set_hyperparameters(num_layers=152,
use_pretrained_model=0,
image_shape = "3,224,224",
num_classes=2,
mini_batch_size=32,
epochs=30,
learning_rate=0.01,
num_training_samples=963,
precision_dtype='float32')
Canales de aprendizaje
Especifique los canales de aprendizaje de la forma en que lo hace siempre, tampoco hay cambios en comparación con cómo lo haría en la copia de su cuaderno.
train_data = TrainingInput(s3train, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data = TrainingInput(s3validation, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
train_data_lst = TrainingInput(s3train_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data_lst = TrainingInput(s3validation_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data,
'train_lst': train_data_lst, 'validation_lst': validation_data_lst}Empezamos a entrenar
Inicie la tarea de entrenamiento en SageMaker llamando al método de ajuste, que iniciará el entrenamiento en sus instancias de SageMaker AWS.
classifier.fit(inputs=data_channels, logs=True)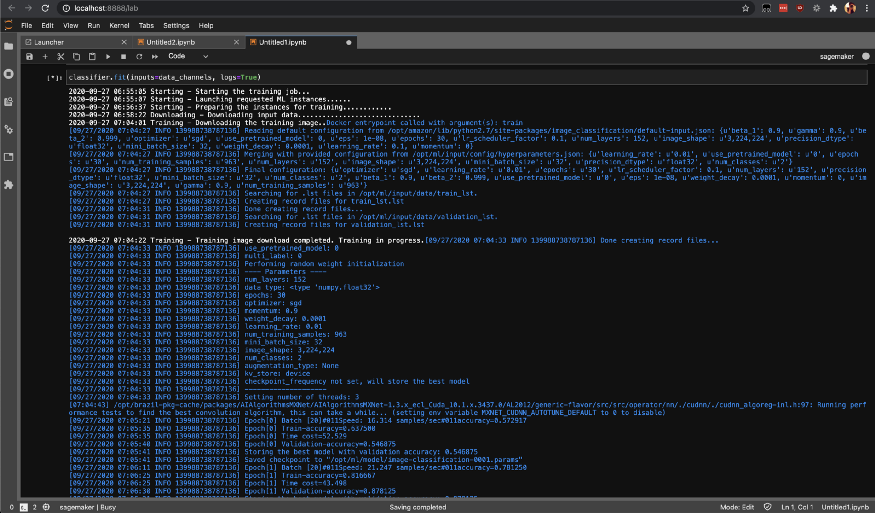
Puede comprobar el estado de los trabajos de formación con list-training-jobs .
Eso es todo. Hoy descubrimos cómo configurar localmente el entorno de SageMaker y crear modelos de aprendizaje automático en una máquina local usando Jupyter. Además de Jupyter, puede hacer lo mismo desde su propio IDE.
¡Feliz aprendizaje!
