Suele suceder cuando hay muchas conversiones, su precio es aceptable y las ventas no crecen e incluso caen. Aquí los análisis "antes de la ganancia por clic" ya no son suficientes para averiguar el motivo. Y luego el análisis "antes de la ganancia del gerente" viene al rescate. Porque no importa cuán idealmente esté configurada la publicidad, los clientes primero interactúan con los gerentes y solo luego toman una decisión. El éxito de su negocio depende de la calidad del trabajo de los empleados.
Los sistemas de análisis tradicionales utilizan CRM para registrar el hecho de una venta / contacto con un gerente. Sin embargo, este enfoque solo resuelve parcialmente el problema: evalúa la eficiencia del empleado "en el resultado final". Es decir, muestra ventas y conversión, pero deja la comunicación con el cliente “por la borda”. Pero el resultado depende del nivel de comunicación.
Para llenar el vacío, hemos desarrollado una herramienta que vinculará automáticamente cada llamada al gerente que la manejó. No tiene que usar CRM ni servicios de terceros. De hecho, nuestro sistema pone una etiqueta "nombre del administrador" en cada llamada entrante.
Por lo tanto, los jefes del departamento de ventas / servicio al cliente controlarán la calidad del trabajo, encontrarán áreas problemáticas y desarrollarán análisis. La segmentación rápida de las llamadas a los gerentes que las reciben ayudará en esto.
Formulación del problema
La tarea que nos planteamos es la siguiente: dejar que el sistema conozca los patrones de habla de todos los gerentes que pueden recibir llamadas. Luego, para una nueva llamada, debe etiquetar al administrador, cuya voz es la más "similar" en la conversación de la lista de conocidos.
En este caso, se considera a priori que la nueva llamada telefónica es exitosa. Es decir, la conversación entre el gerente y el cliente realmente tuvo lugar. Hablando informalmente, esta tarea se puede atribuir a la clase de tareas de "enseñar con un profesor", es decir, clasificación.
Como objetos, de alguna manera grabaciones de audio vectorizadas (digitalizadas), donde solo suena la voz del gerente. Las respuestas son etiquetas de clase (nombres de los gerentes). Entonces la tarea del algoritmo de etiquetado es:
- Extracción de funciones significativas de archivos de audio
- Elegir el algoritmo de clasificación más adecuado
- Aprender el algoritmo y guardar modelos de administrador
- Evaluar la calidad del algoritmo y modificar sus parámetros
- Etiquetar (clasificar) nuevas llamadas
Algunas de estas tareas se dividen en subtareas separadas. Esto se debe a las condiciones específicas en las que debe operar el algoritmo. Las llamadas telefónicas suelen ser ruidosas. Un cliente dentro de una conversación puede comunicarse con varios gerentes. Además, no se realizará en absoluto y las llamadas a menudo incluyen IVR, etc.
Por ejemplo, la tarea de etiquetar nuevas llamadas se puede dividir en:
- Verificación de la llamada para el éxito (el hecho de que hay una llamada)
- División de estéreo en pistas mono
- Filtrado de ruido
- Identificación de áreas con habla (filtrando música y otros sonidos extraños)
En el futuro, hablaremos de cada una de estas subtareas por separado. Mientras tanto, formularemos las restricciones técnicas que imponemos a los datos de entrada, la solución resultante, así como al propio algoritmo de clasificación.
Restricciones de la solución
La necesidad de restricciones está dictada en parte por la técnica y los requisitos de la complejidad de la implementación, y también por el equilibrio entre la universalidad del algoritmo y la precisión de su funcionamiento.
Limitaciones del archivo de entrada y los archivos de muestra de entrenamiento:
- Formato: wav u wave (puede volver a codificar a mp3)
- Posteriormente, el estéreo debe dividirse en 2 pistas: el operador y el cliente
- Frecuencia de muestreo: 16.000 Hz y superior
- Profundidad de bits: desde 16 bits y más
- El archivo para entrenar al modelo debe tener al menos 30 segundos de duración y contener solo la voz de un gerente específico
- , , ,
Todos los requisitos anteriores, excepto el último, se formularon como resultado de una serie de experimentos que se llevaron a cabo en la etapa de configuración de los algoritmos. Esta combinación ha demostrado ser la más eficaz en términos de minimizar la probabilidad de error, es decir, clasificación errónea en condiciones de fácil ajuste.
Por ejemplo, es obvio que cuanto más largo sea el archivo en el conjunto de entrenamiento, más preciso será el clasificador. Pero más difícil es encontrar un archivo de este tipo en el registro de llamadas (nuestro ejemplo de entrenamiento). Por lo tanto, la duración de 30 segundos es un compromiso entre la precisión y la complejidad de los ajustes. El último requisito (éxito) es necesario. El sistema no debe etiquetar a un gerente a una llamada en la que en realidad no hubo conversación.
Las limitaciones del algoritmo llevaron a la siguiente solución:
- , . « ». . - , .
- . , , .
El primer requisito provino de la experimentación. Luego resultó que el administrador "desconocido" complica la arquitectura de la solución. Para ello es necesario seleccionar umbrales después de los cuales el empleado será clasificado como “no reconocido”. Además, el administrador "desconocido" reduce la precisión en 10 puntos porcentuales.
Además, aparece un error del segundo tipo cuando un gerente conocido se clasifica como desconocido. La probabilidad de tal error es del 7 al 10%, dependiendo del número de errores conocidos. Este requisito se puede llamar esencial. Obliga al sintonizador de algoritmos a indicar todos los administradores en la muestra de entrenamiento. Y también introducir modelos de nuevos empleados allí y eliminar a los que renuncian.
El segundo requisito proviene de consideraciones prácticas y la arquitectura del algoritmo que estamos utilizando. En resumen, el algoritmo rompe el audio analizado en fragmentos de voz y "compara" cada uno con todos los modelos de administrador capacitado uno por uno.
Como resultado, se asigna una "mini-etiqueta" a cada uno de los mini-fragmentos. Con este enfoque, existe una alta probabilidad de que algunos de los fragmentos se reconozcan incorrectamente. Por ejemplo, si siguen siendo ruidosos o su longitud es demasiado corta.
Luego, si todas las "mini-etiquetas" se muestran en la solución final, además de la etiqueta del administrador real, se mostrarán muchas "basura". Por lo tanto, solo se muestra la etiqueta más "frecuente".
Descripción de datos de entrada / salida
Dividiremos los datos de entrada en 2 tipos:
Datos a la entrada del algoritmo para generar modelos de gerentes (datos para entrenamiento):
- Archivo de audio + etiqueta de clase
Datos a la entrada del algoritmo de etiquetado (datos para prueba / funcionamiento normal):
- Datos externos (archivo de audio)
- Datos internos (modelos guardados)
La salida también se divide en 2 tipos:
- Datos de salida del algoritmo de generación del modelo
- Modelos de gerentes capacitados
- Salida del algoritmo de etiquetado
- Etiqueta de administrador
A la entrada del algoritmo en cualquier modo de su funcionamiento, se recibe un archivo de audio que cumple con los requisitos. Están en la sección de "restricciones".
En la entrada del algoritmo de generación del modelo, se permite que varios archivos de entrada correspondan a una clase (administrador). Pero un archivo no puede corresponder a varios administradores. El nombre de la etiqueta de la clase se puede colocar en el nombre del archivo. O simplemente cree un directorio separado para cada empleado.
El algoritmo de entrenamiento de modelos basado en datos de entrada genera muchos modelos que se pueden cargar durante el entrenamiento. Su número corresponde al número de etiquetas diferentes en el conjunto de archivos de audio.
Por lo tanto, si hay archivos M que están marcados con n diferentes etiquetas de clase, el algoritmo crea n modelos de gerentes en la etapa de capacitación:
- Model_manager_1.pkl
- Model_manager_2.pkl
- ...
- Model_manager_n.pkl
donde en lugar de " manager _... " es el nombre de la clase.
La entrada al algoritmo de etiquetado es un archivo de audio sin etiquetar, en el que a priori hay una conversación entre un gerente y un cliente, así como n modelos de empleados. Como resultado, el algoritmo devuelve una etiqueta: el nombre de la clase del administrador más "plausible".
Preprocesamiento de datos
Los archivos de audio están preprocesados. Es secuencial y se ejecuta tanto en modo de etiquetado como en modo de entrenamiento de modelos:
- Verificación del éxito de la llamada, solo en la etapa de etiquetado
- Dividir estéreo en 2 pistas mono y seguir trabajando solo con la pista del operador
- Digitalización: extracción de parámetros de señales de audio
- Filtrado de ruido
- Eliminación de pausas "largas": identificación de fragmentos con sonido
- Filtrar fragmentos que no son de voz: eliminar música, fondo, etc.
- Fusión de fragmentos con habla (solo en la etapa de entrenamiento)
No nos detendremos en la etapa de verificación del éxito. Este es un tema para un artículo separado. En definitiva, la esencia del escenario es que la llamada se clasifica según si en ella hay una conversación de "personas vivas". Por "personas vivas" nos referimos a un cliente y un gerente, no a un asistente de voz, música, etc.
El éxito de una llamada se verifica utilizando un clasificador especialmente capacitado con un umbral externo: "la duración mínima de una conversación después de la cual la llamada se considera exitosa".
En la segunda etapa, el archivo estéreo se divide en 2 pistas: el administrador y el cliente. El procesamiento adicional se lleva a cabo solo para la pista del empleado.
En la etapa de digitalización, los parámetros de la "característica" se extraen de la pista del operador, que son una representación digital de la señal. En Calltouch utilizamos componentes de tiza-cepstral. Además, los parámetros se extraen en un fragmento muy pequeño, que se denomina ancho de ventana (0,025 segundos). Todas las funciones se normalizan al mismo tiempo.
nfft=2048 //
appendEnergy = False
def get_MFCC(sr,audio): // , sr=16000 -
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, 26, nfft, 0, 1000, appendEnergy)
features = preprocessing.scale(features)
return features
count = 1
features = np.asarray(()) //
for path in file_paths: //
path = path.strip()
sr,audio = read(source + path) //
vector = get_MFCC (sr, audio) #
if features.size == 0:
features = vector
else:
features = np.vstack((features, vector))En la salida, cada archivo de audio se convierte en una matriz, en la que las características mel-cepstrales de cada fragmento de 0.025 segundos se registran línea por línea.
El procesamiento posterior del archivo consiste en filtrar el ruido, eliminar pausas largas (no pausas entre sonidos) y buscar el habla. Estas tareas se pueden realizar utilizando varias herramientas. En nuestra solución, usamos métodos de la biblioteca pyaudioanalysis:
clear_noise(fname,outname,ch_n) # .- fname - archivo de entrada
- outname - archivo de salida
- ch_n - número de canales
En la salida, obtenemos el archivo outname, que contiene el sonido, limpiado del ruido, del archivo fname.
silenceRemoval(x, Fs, stWin, stStep) # « »- x - matriz de entrada (señal digitalizada)
- Fs - frecuencia de muestreo
- stWin - ancho de la ventana de extracción de características
- stStep - tamaño de paso de desplazamiento
En la salida, obtenemos una matriz de la forma:
[l_1, r_1]
[l_2, r_2]
[l_3, r_3]
…
[l_N, r_N]
donde l_i es el tiempo de inicio del i-ésimo segmento (seg), r_i es el tiempo de finalización del i-ésimo segmento (seg ).
detect_audio_segment(x,thrs) # .- x - matriz de entrada (señal digitalizada)
- hrs: duración mínima (en segundos) del fragmento de voz detectado
En la salida, obtenemos esos fragmentos [L_i, r_i] , que contienen discurso que duró desde THR segundos.
Como resultado del preprocesamiento, el archivo de audio de entrada se convierte a la forma de una matriz:
[l_1, r_1]
[l_2, r_2]
[l_3, r_3]
…
[l_N, r_N],
donde cada fragmento es un intervalo de tiempo del archivo de voz borrado.
Por lo tanto, podemos emparejar cada fragmento con una matriz de características (características cepstrales pequeñas), que se utilizará para entrenar el modelo y en la etapa de marcado.
Métodos / algoritmos utilizados
Como se señaló anteriormente, nuestra solución se basa en la biblioteca pyaudioanalysis.py escrita en Python 2.7. Dado que nuestra solución general está implementada en Python 3.7, algunas de las funciones de la biblioteca se han modificado y adaptado para esta versión del lenguaje.
En general, el algoritmo de la herramienta para etiquetado de administradores se puede dividir en 2 partes:
- Capacitación para administradores de modelos
- Etiquetado
Una descripción más detallada de cada parte se ve así.
Capacitación para administradores de modelos:
- Cargando la muestra de entrenamiento
- Preprocesamiento de datos
- Contando el número de clases
- Creando un modelo de administrador para cada una de las clases
- Guardando el modelo
Etiquetado:
- Carga de llamadas
- Comprobando el éxito de la llamada
- Preprocesar una llamada exitosa
- Cargando todos los modelos de gerente capacitado
- Clasificación de cada fragmento de la llamada procesada
- Encontrar el modelo de gerente más probable
- Etiquetado
Ya hemos comentado en detalle las tareas del preprocesamiento de datos. Ahora veamos los métodos para crear modelos de administrador.
Usamos el algoritmo GMM (Gaussian Mixture Model) como modelo . Modela nuestros datos bajo el supuesto de que son realizaciones de una variable aleatoria con una distribución que se describe mediante una mezcla de gaussianos, cada uno con su propia varianza y su propia expectativa matemática.
Se sabe que el algoritmo más común para encontrar los parámetros óptimos de dicha mezcla es el algoritmo EM (Expectation Maximization) . Divide el difícil problema de maximizar la probabilidad de una variable aleatoria multidimensional en una serie de problemas de maximización de menor dimensión.
Como resultado de una serie de experimentos, llegamos a los siguientes parámetros del algoritmo GMM:
gmm = GMM(n_components = 16, n_iter = 200, covariance_type='diag',n_init = 3)Este modelo se crea para cada gerente y luego se capacita; sus parámetros se ajustan a datos específicos.
gmm.fit(features)A continuación, el modelo se guarda para ser utilizado en la etapa de etiquetado:
picklefile = path[path.find('/')+1:path.find('.')]+".gmm"
pickle.dump(gmm,open(dest + picklefile,'wb'))En la etapa de etiquetado, cargamos los modelos previamente guardados:
gmm_files = [os.path.join(modelpath,fname) for fname in
os.listdir(modelpath) if fname.endswith('.gmm')]modelpath es el directorio donde guardamos los modelos.
models = [pickle.load(open(fname,'rb'),encoding='latin1') for fname in gmm_files]Y cargue también los nombres de los modelos (estas son nuestras etiquetas):
speakers = [fname.split("/")[-1].split(".gmm")[0] for fname
in gmm_files]El archivo de audio cargado, para el que necesita etiquetar, está vectorizado y preprocesado. Además, cada fragmento con el discurso se compara con los modelos entrenados y el ganador se determina en términos del logaritmo máximo de probabilidad:
log_likelihood = np.zeros(len(models)) #
for i in range(len(models)):
gmm = models[i] #
scores = np.array(gmm.score(vector))
log_likelihood[i] = scores.sum() # i –
winner = np.argmax(log_likelihood) #
print("\tdetected as - ", speakers[winner])Como resultado, nuestro algoritmo tiene aproximadamente la siguiente conclusión:
comienza en: 1.92 termina en: 8.72
[-10400.93604115 -12111.38278205]
detectado como - Olga
comienza en: 9.22 termina en: 15.72
[-10193.80504138 -11911.11095894]
detectado como - Olga
comienza en: 26.7 termina en: 29,82
[-4,867.97641331 -5,506.44233563]
detectada como - Ivan
comienza en: 33.34 extremos en: 47,14
[-21,143.02629011 -24,796.44582627]
detecta como - Ivan
comienza en: 52,56 extremos en: 59,24
[-10916.83282132 -12,124.26855 starts538]
detectado como - Olga
starts538 in: 116.32 termina en:
134.56 [-36764.94876054 -34810.38959083]
detectado como - Olga
comienza en: 151.18 termina en: 154.86
[-8041.33666572 -6859.14253903]
detectado como - Olga
comienza en: 159.7 termina en: 162.92
[-6421.72235531 -5983.90538059]
detectado como - Olga
comienza en: 185.02 termina en: 208.7
…
comienza en: 442.04 termina en:
445.5 [-7451.0289772 -6286.66.66 ]
detectado como - Olga
*******
GANADOR - Olga
Este ejemplo asume que hay al menos 2 clases - [Olga, Ivan] . El archivo de audio se corta en segmentos [1.92, 8.72], [9.22, 15.72],…, [442.04, 445.5] y se determina el modelo más adecuado para cada uno de los segmentos.
El logaritmo de probabilidad acumulativa se muestra entre paréntesis junto a cada fragmento:[-10400.93604115 -12111.38278205] , el primer elemento es la probabilidad de Olga y el segundo es Ivan . Dado que el primer argumento es mayor que el segundo, este segmento se clasifica como Olga . El ganador final se determina por la mayoría de los "votos" de los fragmentos.
resultados
Inicialmente, diseñamos el algoritmo asumiendo que un administrador "desconocido" puede estar presente en las llamadas entrantes, es decir, que su modelo no está presente en la muestra de entrenamiento.
Para detectar tal usuario, necesitamos ingresar alguna métrica en el vector log_likelihood . Tal que algunos de sus valores indiquen que lo más probable es que este fragmento no esté adecuadamente descrito por ninguno de los modelos existentes. Sugerimos la siguiente métrica como prueba:
Leukl=(log_likelihood-np.min(log_likelihood))/(np.max(log_likelihood)-np.min(log_likelihood))
-sorted(-np.array(Leukl))[1]<TEste valor indica cuán "uniformemente" se distribuyen las puntuaciones en el vector log_likelihood . La uniformidad de las estimaciones (su cercanía entre sí) significa que todos los modelos se comportan igual y no hay un líder claro.
Esto sugiere que lo más probable es que todos los modelos estén equivocados y que tengamos un gerente que no estaba en la etapa de capacitación. La relación entre T y la calidad de la clasificación se muestra en las figuras.
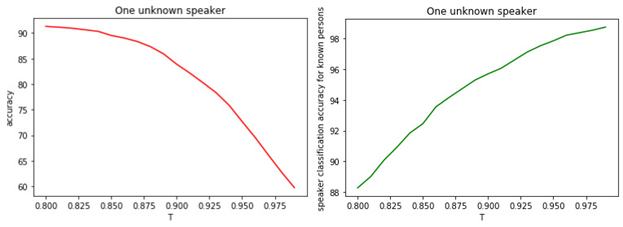
Figura: 1.
a) Precisión de la clasificación binaria de gestores conocidos y desconocidos.
b) La veracidad de la clasificación de gerentes famosos.

Figura: 2.
a) La proporción de administradores reconocidos asignados a la clase de administradores reconocidos.
b) La proporción de gerentes desconocidos asignados a la clase de conocidos.
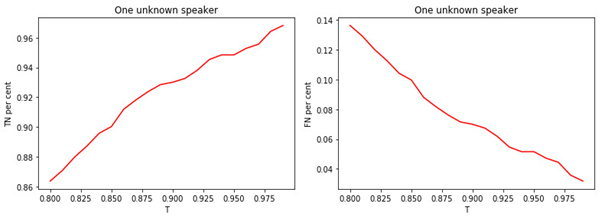
Figura: 3.
a) La proporción de administradores desconocidos asignados a la clase de desconocidos.
b) La proporción de administradores notorios asignados a la clase de incógnitas.
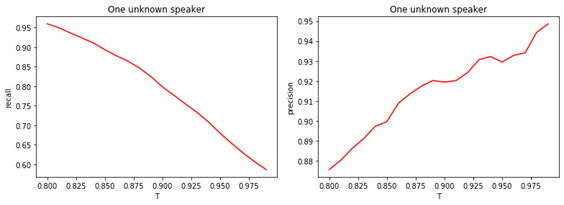
Figura: 4.
a) Integridad de la clasificación binaria (recuperación).
b) Precisión de clasificación binaria (precisión).
La relación entre el valor del umbral T y la calidad de la clasificación (marcado) es obvia. Cuanto mayor sea la T (cuanto más estrictas sean las condiciones para asignar a un gerente a la clase de incógnitas), es menos probable que un gerente conocido sea clasificado como desconocido. Sin embargo, es más probable que "extrañe" a un gerente desconocido.
El valor umbral óptimo es 0,8 . Porque clasificamos a gerentes reconocidos con una precisión de aproximadamente el 90%y determinar las "incógnitas" con una precisión del 81% . Si asumimos que todos los gerentes nos son "familiares", entonces la precisión será de aproximadamente el 98% .
conclusiones
En el artículo describimos las ideas generales del funcionamiento de nuestra herramienta de identificación de gerentes en convocatorias. Por supuesto, no pretendemos que nuestro algoritmo sea óptimo y no sea capaz de mejorar.
Se basa en una serie de supuestos que no siempre se cumplen en la práctica. Por ejemplo, podemos encontrarnos con un gerente desconocido si no hay datos sobre él. O dos o más gerentes pueden mantener una conversación con un cliente "en partes iguales". Desde el punto de vista del algoritmo, se pueden proponer las siguientes direcciones para mejoras adicionales:
- Elegir un modelo de algoritmo diferente al de GMM
- Optimización de los parámetros de GMM
- Seleccionar una métrica diferente para detectar un nuevo administrador
- Busque las características más significativas de la señal de voz.
- Combinación de diferentes herramientas de preprocesamiento de audio y optimización de parámetros de estos métodos