
En este sentido, los DBMS funcionan de acuerdo con los mismos principios: " dijeron que cavaran y yo cavo ". Su solicitud no solo puede ralentizar los procesos vecinos, ocupando constantemente los recursos del procesador, sino también "eliminar" toda la base de datos por completo, "consumiendo" toda la memoria disponible. Por lo tanto, es responsabilidad del desarrollador protegerse contra la recursividad infinita .
En PostgreSQL, la capacidad de utilizar consultas recursivas a través ha
WITH RECURSIVEaparecido desde tiempos inmemoriales en la versión 8.4, pero todavía puede encontrar consultas "indefensas" potencialmente vulnerables. ¿Cómo salvarse de este tipo de problemas?
No escriba consultas recursivas
Y escribe no recursivo. Respetuosamente tuyo K.O.De hecho, PostgreSQL proporciona una gran cantidad de funciones que puede utilizar para evitar la recursividad.
Utilice un enfoque fundamentalmente diferente para la tarea
A veces puede simplemente mirar el problema "desde el otro lado". Di un ejemplo de tal situación en el artículo "SQL HowTo: 1000 y una forma de agregación" : multiplicar un conjunto de números sin usar funciones de agregación personalizadas:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY --
i DESC
LIMIT 1;Tal solicitud se puede reemplazar con una variante de expertos en matemáticas:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;Utilice generate_series en lugar de bucles
Digamos que nos enfrentamos a la tarea de generar todos los prefijos posibles para una cadena
'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T;Exactamente, ¿necesita recursividad aquí? ... Si usa
LATERALy generate_series, entonces ni siquiera los CTE son necesarios:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;Cambiar la estructura de la base de datos
Por ejemplo, tiene una tabla de publicaciones en el foro con enlaces a quién respondió a alguien o un hilo en una red social :
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to);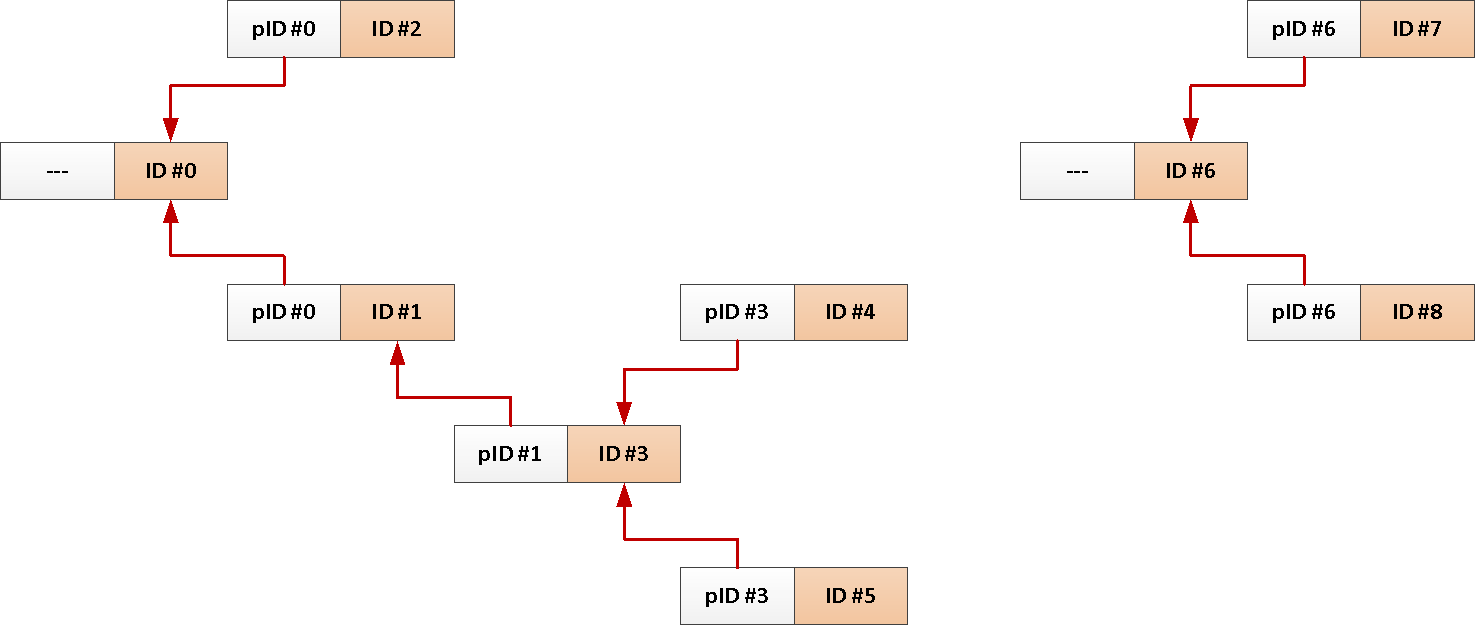
Bueno, una solicitud típica para descargar todos los mensajes sobre un tema se parece a esto:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;Pero como siempre necesitamos todo el asunto del mensaje raíz, ¿por qué no agregar su identificador a cada publicación automáticamente?
--
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
--
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id --
ELSE ( -- ,
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins();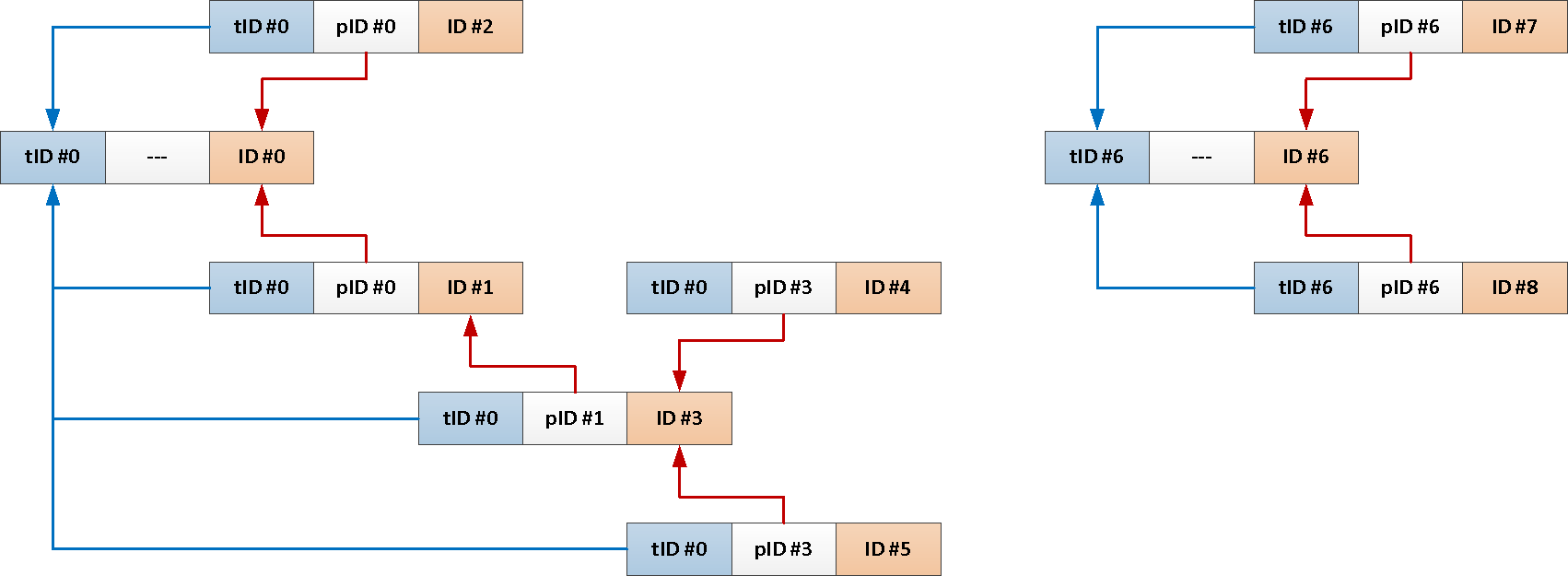
Ahora toda nuestra consulta recursiva se puede reducir a esto:
SELECT
*
FROM
message
WHERE
theme_id = $1;Usar "restricciones" aplicadas
Si por alguna razón no podemos cambiar la estructura de la base de datos, veamos en qué podemos confiar para que incluso la presencia de un error en los datos no dé lugar a una recursividad infinita.
Contador de "profundidad" de recursividad
Simplemente aumentamos el contador en uno en cada paso de la recursividad hasta que se alcanza el límite, que consideramos obviamente inadecuado:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 --
)Ventaja: cuando intentamos hacer un bucle, no haremos más que el límite especificado de iteraciones "en profundidad".
Contra: No hay garantía de que no procesaremos el mismo registro nuevamente, por ejemplo, a profundidades de 15 y 25, y luego habrá cada +10. Y nadie prometió nada sobre "amplitud".
Formalmente, tal recursión no será infinita, pero si en cada paso el número de registros aumenta exponencialmente, todos sabemos bien cómo termina ...

Guardián del "camino"
Uno por uno, agregamos todos los identificadores de objetos que encontramos a lo largo de la ruta de recursividad en una matriz, que es una "ruta" única:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) --
)Ventaja: si hay un bucle en los datos, no procesaremos el mismo registro una y otra vez dentro de la misma ruta.
Contra: Pero al mismo tiempo podemos omitir, literalmente, todos los registros sin repetir.
Limitación de la longitud de la ruta
Para evitar la situación de recursividad "vagando" a una profundidad incomprensible, podemos combinar los dos métodos anteriores. O, si no queremos admitir campos innecesarios, complemente la condición de continuación de recursividad con una estimación de la longitud de la ruta:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
)¡Elige el método a tu gusto!