- ¡Hola! Déjeme decirle qué problemas tiene que resolver cuando necesita preparar su servicio para cargas de varios cientos de gigabits, o incluso terabits por segundo. Encontramos este problema por primera vez en 2018, cuando nos preparábamos para las retransmisiones de la Copa Mundial de la FIFA.
Comencemos con qué son los protocolos de transmisión y cómo funcionan: la opción de descripción general más superficial.

Cualquier protocolo de transmisión se basa en un manifiesto o una lista de reproducción. Es un pequeño archivo de texto que contiene metainformación sobre el contenido. Describe el tipo de contenido: transmisión en vivo o transmisión VoD (video a pedido). Por ejemplo, en el caso de un directo es un partido de fútbol o una conferencia online, como lo tenemos ahora contigo, y en el caso de VoD, tu contenido está preparado con antelación y se encuentra en tus servidores, listo para ser distribuido a los usuarios. El mismo archivo describe la duración del contenido, información sobre DRM.

También describe variaciones de contenido: pistas de video, pistas de audio, subtítulos. Las pistas de video se pueden representar en diferentes códecs. Por ejemplo, H.264 universal es compatible con cualquier dispositivo. Con él, puede reproducir videos en cualquier plancha de su hogar. O hay códecs HEVC y VP9 más modernos y eficientes que le permiten transferir 4K con soporte HDR.
Las pistas de audio también se pueden presentar en diferentes códecs con diferentes velocidades de bits. Y puede haber varios de ellos: la pista de audio original de la película en inglés, traducción al ruso, intershum o, por ejemplo, una grabación de un evento deportivo directamente desde el estadio sin comentaristas.

¿Qué hace el jugador con todo esto? La tarea del jugador es, en primer lugar, elegir aquellas variaciones de contenido que puede reproducir, simplemente porque no todos los códecs son universales, no todos se pueden reproducir en un dispositivo en particular.
Después de eso, debe seleccionar la calidad de video y audio a partir de los cuales comenzará a reproducir. Puede hacer esto basándose en las condiciones de la red, si las conoce, o basándose en alguna heurística muy simple. Por ejemplo, comience a jugar con baja calidad y, si la red lo permite, aumente lentamente la resolución.
También en esta etapa, selecciona la pista de audio desde la que comenzará a reproducir. Suponga que tiene inglés en su sistema operativo. Luego, puede seleccionar la pista de audio en inglés predeterminada. Quizás te resulte más conveniente.
Después de eso, comienza a formar enlaces a segmentos de video y audio. De hecho, se trata de enlaces HTTP habituales, al igual que en todos los demás escenarios de Internet. Y comienza a descargar segmentos de audio y video, ponerlos en el búfer uno tras otro y reproducirlos sin problemas. Dichos segmentos de video suelen tener una duración de 2, 4, 6 segundos, quizás 10 segundos, dependiendo de su servicio.

¿Cuáles son los puntos importantes aquí en los que debemos pensar cuando diseñamos nuestra CDN? En primer lugar, tenemos una sesión de usuario.
No podemos simplemente darle un archivo a un usuario y olvidarnos de ese usuario. Vuelve constantemente y descarga segmentos nuevos y nuevos a su búfer.
Es importante comprender aquí que el tiempo de respuesta del servidor también es importante. Si estamos mostrando algún tipo de transmisión en vivo en tiempo real, entonces no podemos hacer un búfer grande simplemente porque el usuario quiere ver el video lo más cerca posible del tiempo real. En principio, su búfer no puede ser grande. En consecuencia, si el servidor no tiene tiempo para responder mientras el usuario tiene tiempo para ver el contenido, el video simplemente se congelará en algún momento. Además, el contenido es bastante pesado. La tasa de bits estándar para Full HD 1080p es de 3-5 Mbps. En consecuencia, en un servidor gigabit, no puede atender a más de 200 usuarios al mismo tiempo. Y esta es una imagen perfecta porque, por regla general, los usuarios no siguen sus solicitudes de manera uniforme a lo largo del tiempo.

¿En qué momento un usuario interactúa realmente con su CDN? La interacción ocurre principalmente en dos lugares: cuando el jugador descarga el manifiesto (lista de reproducción) y cuando descarga segmentos.
Ya hemos hablado de manifiestos, estos son pequeños archivos de texto. No hay problemas particulares con la distribución de dichos archivos. Si lo desea, distribúyalos desde al menos un servidor. Y si son segmentos, constituyen la mayor parte de su tráfico. Hablaremos de ellos.
La tarea de todo nuestro sistema se reduce al hecho de que queremos formar el enlace correcto a estos segmentos y sustituir el dominio correcto de algunos de nuestros hosts CDN allí. En este punto, usamos la siguiente estrategia: inmediatamente en la lista de reproducción le damos el host CDN deseado, donde irá el usuario. Este enfoque carece de muchas desventajas, pero tiene un matiz importante. Debe asegurarse de tener un mecanismo para alejar al usuario de un host a otro sin problemas durante la reproducción sin interrumpir la visualización. De hecho, todos los protocolos de transmisión modernos tienen esta capacidad, tanto HLS como DASH la admiten. Un matiz: con bastante frecuencia, incluso en bibliotecas de código abierto muy populares, tal posibilidad no se implementa, aunque existe según el estándar. Nosotros mismos tuvimos que enviar paquetes a la biblioteca de código abierto de Shaka,es javascript, utilizado para el reproductor web, para jugar DASH.
Hay un esquema más, el esquema anycast, cuando usa un solo dominio y lo proporciona en todos los enlaces. En este caso, no necesita pensar en ningún matiz: regala un dominio y todos están felices. (...)
Ahora hablemos de cómo formaremos nuestros enlaces.
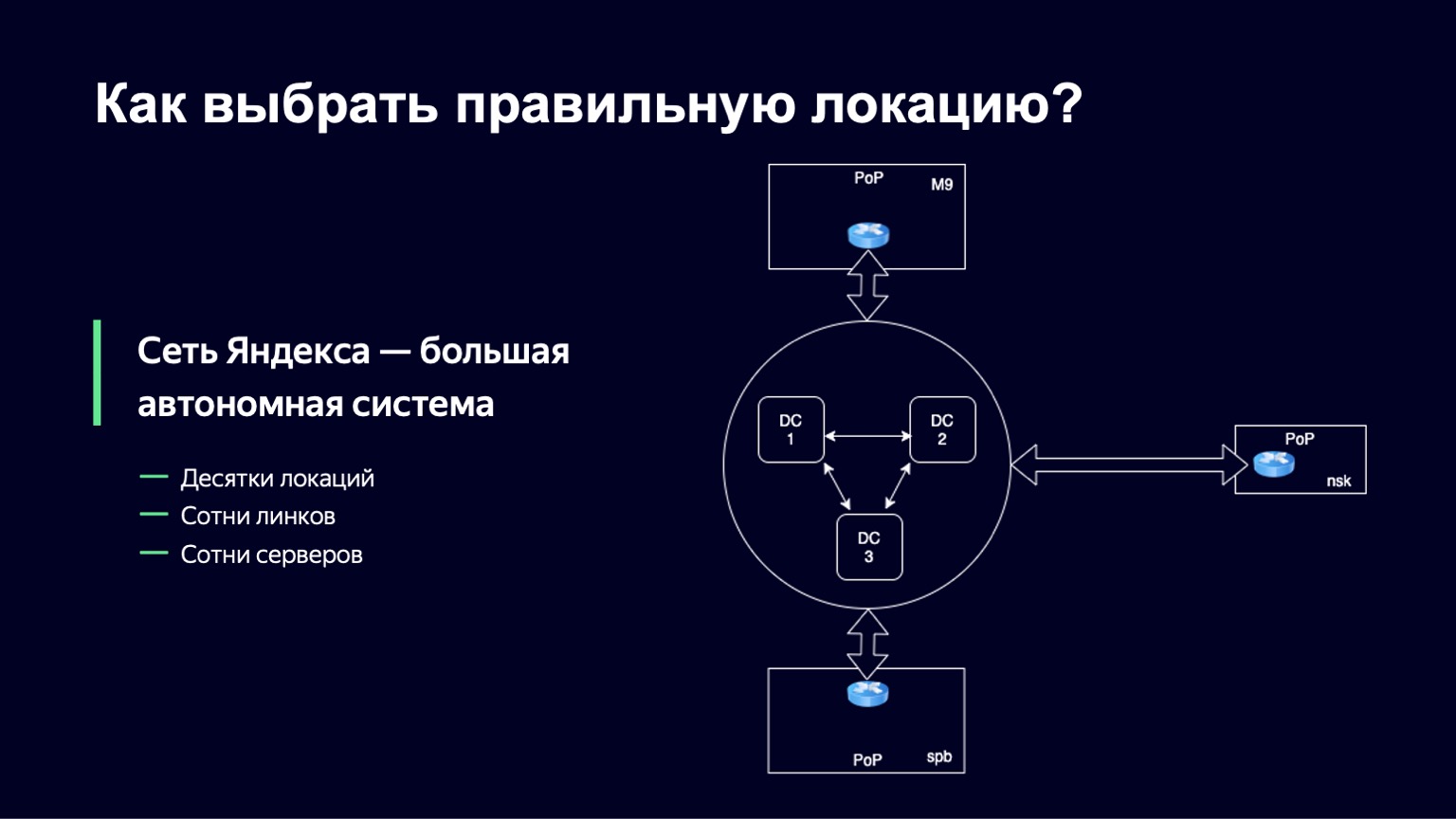
Desde el punto de vista de la red, cualquier gran empresa está organizada como un sistema autónomo y, a menudo, ni siquiera uno. De hecho, un sistema autónomo es un sistema de redes IP y enrutadores que son controlados por un solo operador y proporcionan una única política de enrutamiento con la red externa, con Internet. Yandex no es una excepción. La red Yandex también es un sistema autónomo, y la comunicación con otros sistemas autónomos se lleva a cabo fuera de los centros de datos de Yandex en los puntos de presencia. Los cables físicos de Yandex, cables físicos de otros operadores llegan a estos puntos de presencia, y son conmutados in situ, en equipos de hierro. Es en esos puntos que tenemos la oportunidad de poner varios de nuestros servidores, discos duros, SSD. Aquí es donde dirigiremos el tráfico de usuarios.
A este conjunto de servidores lo llamaremos ubicación. Y en cada una de esas ubicaciones, tenemos un identificador único. Lo usaremos como parte del nombre de dominio de los hosts en este sitio y solo para identificarlo de manera única.
Hay varias docenas de sitios de este tipo en Yandex, hay varios cientos de servidores en ellos y enlaces de varios operadores llegan a cada ubicación, por lo que también tenemos varios cientos de enlaces.
¿Cómo elegiremos a qué ubicación enviar a un usuario en particular?

No hay muchas opciones en esta etapa. Solo podemos usar la dirección IP para tomar decisiones. Un equipo de tráfico de Yandex independiente nos ayuda con esto, que sabe todo sobre cómo funcionan el tráfico y la red en la empresa, y es ella quien recopila las rutas de otros operadores para que usemos este conocimiento en el proceso de equilibrar a los usuarios.
Recopila un conjunto de rutas usando BGP. No hablaremos de BGP en detalle, es un protocolo que permite a los participantes de la red en las fronteras de sus sistemas autónomos anunciar qué rutas puede servir su sistema autónomo. El equipo de tráfico recopila toda esta información, agrega, analiza y construye un mapa completo de toda la red, que usamos para equilibrar.
Recibimos del Equipo de Tráfico un conjunto de redes y enlaces IP a través de los cuales podemos atender a los clientes. A continuación, debemos comprender qué subred IP es adecuada para un usuario en particular.
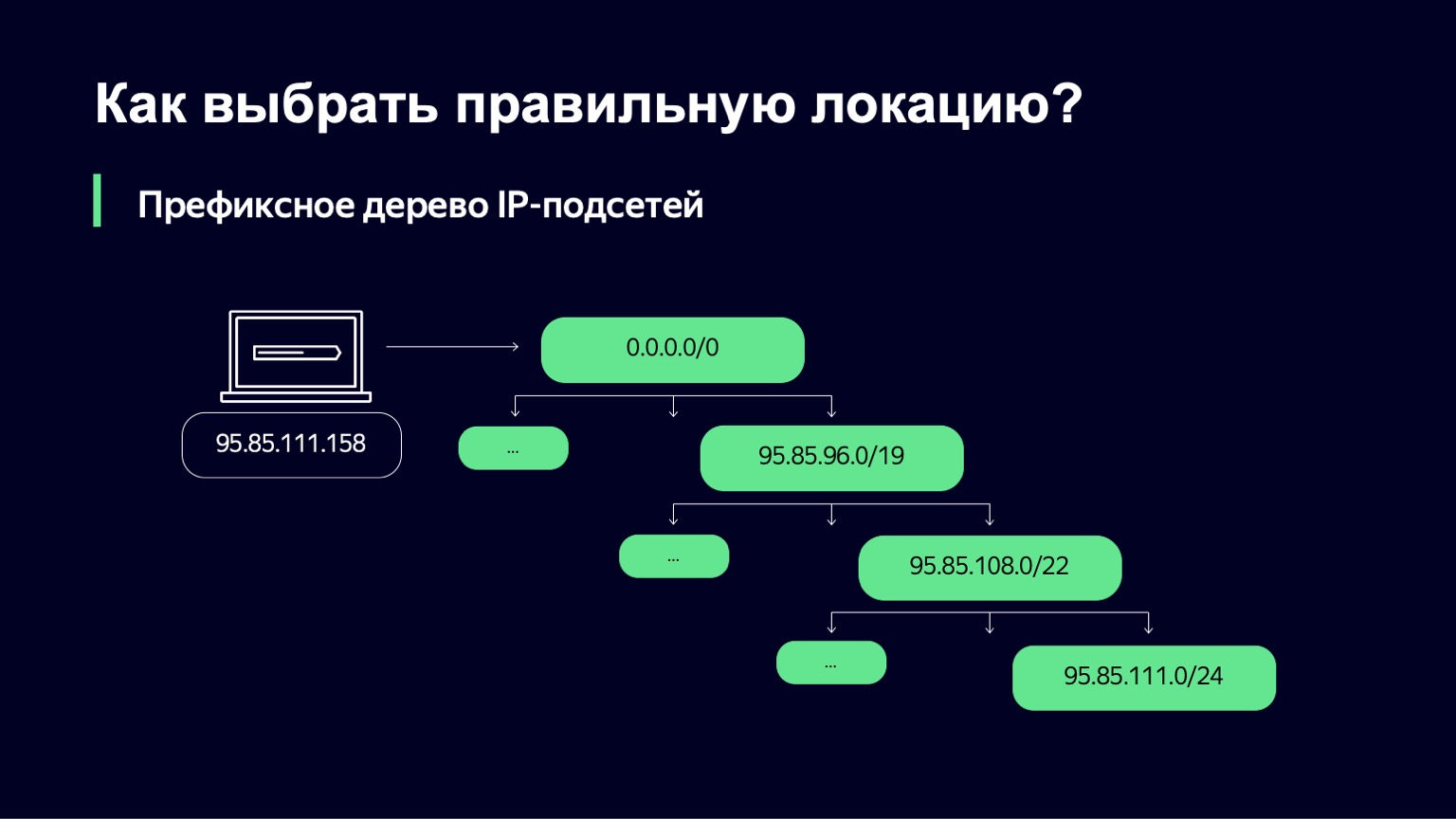
Hacemos esto de una manera bastante simple: construimos un árbol de prefijos. Y luego nuestra tarea es usar la dirección IP del usuario como clave para encontrar qué subred se asemeja más a esta dirección IP.
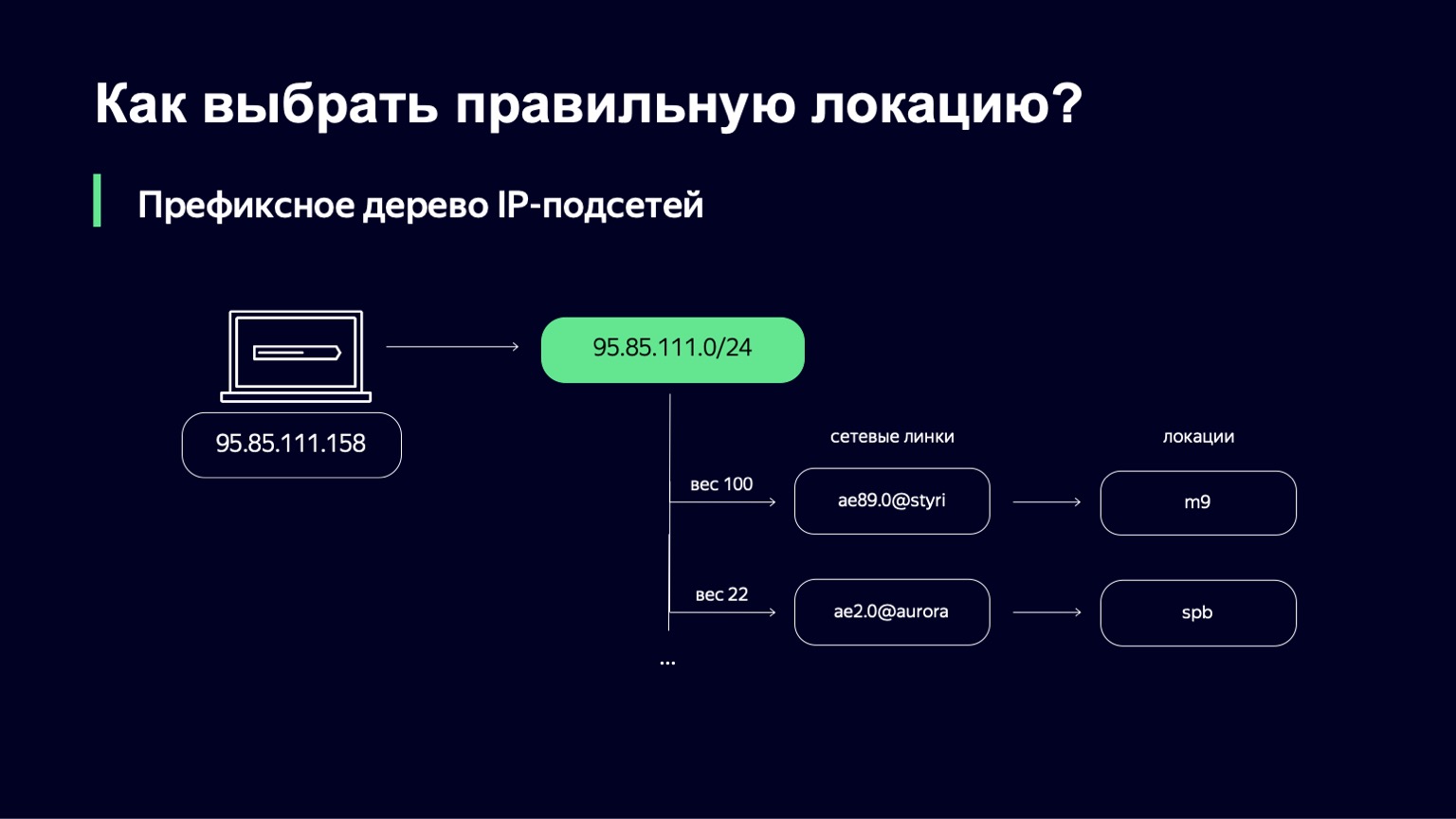
Cuando lo encontramos, tenemos una lista de enlaces, sus pesos y, mediante enlaces, podemos determinar de forma única la ubicación a la que enviaremos al usuario.

¿Cuál es el peso en este lugar? Esta es una métrica que le permite administrar la distribución de usuarios en diferentes ubicaciones. Podemos tener enlaces, por ejemplo, de diferentes capacidades. Podemos tener un enlace de 100 Gigabit y un enlace de 10 Gigabit en el mismo sitio. Obviamente, queremos enviar más usuarios al primer enlace, porque tiene más capacidad. Este peso tiene en cuenta la topología de la red, ya que Internet es un gráfico complejo de equipos de red interconectados, su tráfico puede ir por diferentes rutas y esta topología también debe tenerse en cuenta.
Asegúrese de ver cómo los usuarios descargan datos. Esto se puede hacer tanto en el servidor como en el cliente. En el servidor, estamos recopilando activamente las conexiones de los usuarios en los registros de información de TCP, observando el tiempo de ida y vuelta. Desde el lado del usuario, estamos recopilando activamente registros de rendimiento del navegador y el reproductor. Estos registros de rendimiento contienen información detallada sobre cómo se descargaron los archivos de nuestro CDN.
Si analizamos todo esto, de forma agregada, entonces con la ayuda de estos datos podemos mejorar los pesos que fueron seleccionados en la primera etapa por el Equipo de Tráfico.

Digamos que hemos seleccionado un enlace. ¿Podemos enviar usuarios allí en esta etapa? No podemos, porque el peso es bastante estático durante un largo período de tiempo y no tiene en cuenta ninguna dinámica real de la carga. Queremos determinar en tiempo real si ahora podemos usar un enlace que está, digamos, cargado al 80%, cuando hay un enlace de prioridad ligeramente menor cerca que solo está cargado al 10%. Lo más probable es que, en este caso, solo queramos utilizar el segundo.

¿Qué más hay que tener en cuenta en este lugar? Debemos tener en cuenta el ancho de banda del enlace, entender su estado actual. Puede funcionar o estar técnicamente defectuoso. O quizás queramos llevarlo al servicio para no dejar que los usuarios vayan allí y lo sirvan, expandirlo, por ejemplo. Siempre debemos tener en cuenta la carga actual de este enlace.
Aquí hay algunos matices interesantes. Puede recopilar información sobre la carga de enlaces en varios puntos, por ejemplo, en equipos de red. Esta es la forma más precisa, pero su problema es que en el equipo de red no puede obtener un período de actualización rápido para esta descarga. Por ejemplo, en Yandex, el equipo de red es bastante variado y no podemos recopilar estos datos más de una vez por minuto. Si el sistema es bastante estable en términos de carga, esto no es un problema en absoluto. Todo funcionará genial. Pero tan pronto como tiene afluencias repentinas de carga, simplemente no tiene tiempo para reaccionar y esto conduce, por ejemplo, a la caída de paquetes.
Por otro lado, sabe cuántos bytes se enviaron al usuario. Puede recopilar esta información en las propias máquinas de distribución, hacer un contador de bytes directamente. Pero no será tan exacto. ¿Por qué?
Hay otros usuarios en nuestro CDN. No somos el único servicio que utiliza estas máquinas dispensadoras. Y en el contexto de nuestra carga, la carga de otros servicios no es tan significativa. Pero incluso en nuestro contexto, puede ser bastante notable. Sus distribuciones no pasan por nuestro circuito, por lo que no podemos controlar este tráfico.
Otro punto: incluso si piensa en la máquina emisora que ha enviado tráfico a un enlace específico, esto está lejos de ser un hecho, porque BGP como protocolo no le da tal garantía. Y hay formas de aumentar la probabilidad de que adivines, pero ese es un tema para otra discusión.

Digamos que calculamos las métricas, recopilamos todo. Ahora necesitamos un algoritmo para tomar una decisión al equilibrar. Debe tener cuatro propiedades importantes:
- Proporcionar el ancho de banda del enlace.
- Evite la sobrecarga del enlace, simplemente porque si ha cargado un enlace al 95% o 98%, los búferes del equipo de red comienzan a desbordarse, los paquetes se caen, comienzan las retransmisiones y los usuarios no obtienen nada bueno de esto.
- Para advertir sobre las cargas de "bebido", hablaremos de esto un poco más adelante.
“En un mundo ideal, sería genial si pudiéramos aprender a reciclar un enlace a un cierto nivel que creemos que es correcto. Por ejemplo, 85% de descarga.

Tomamos la siguiente idea como base. Tenemos dos clases diferentes de sesiones de usuario. La primera clase son las sesiones nuevas, cuando el usuario acaba de abrir la película, aún no ha visto nada y estamos tratando de averiguar dónde enviarla. O la segunda clase, cuando tenemos una sesión actual, el usuario ya está servido en el enlace, ocupa una cierta parte del ancho de banda, es servido en un servidor específico.
¿Qué vamos a hacer con ellos? Introducimos un valor probabilístico para cada clase de la sesión. Tendremos un valor llamado Slowdown, que determina el porcentaje de nuevas sesiones que no permitiremos en este enlace. Si Slowdown es cero, entonces aceptamos todas las sesiones nuevas, y si es del 50%, entonces cada segunda sesión, aproximadamente, nos negamos a servir en este enlace. Al mismo tiempo, nuestro algoritmo de equilibrio en un nivel superior comprobará las alternativas para este usuario. Drop: lo mismo, solo para las sesiones actuales. Podemos sacar algunas de las sesiones de usuario del sitio en otro lugar.
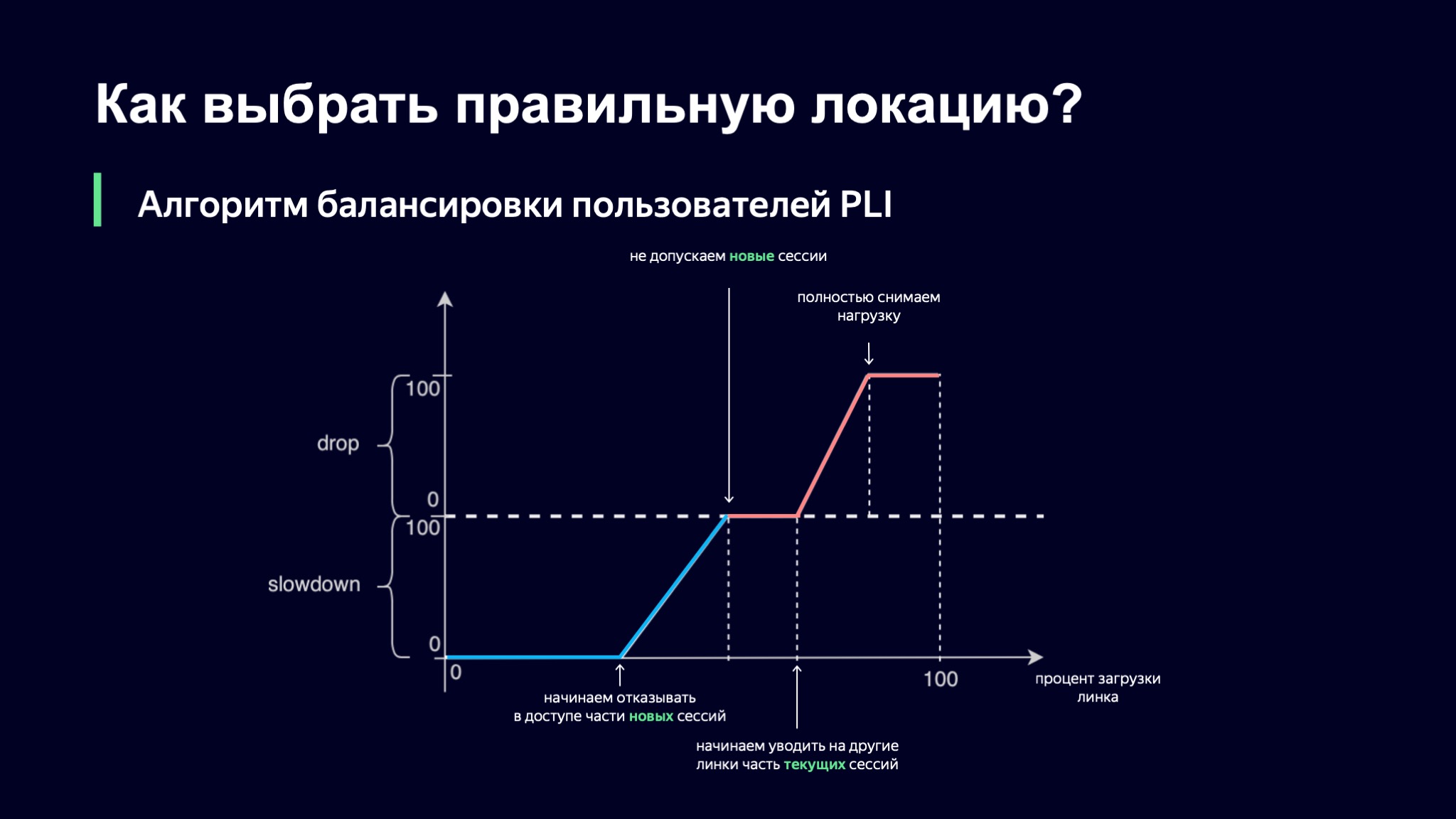
¿Cómo elegimos cuál será el valor de nuestras métricas probabilísticas? Tomemos el porcentaje de carga del enlace como base, y luego nuestra primera idea fue esta: usemos la interpolación lineal por partes.
Tomamos una función de este tipo, que tiene varios puntos de refracción, y observamos el valor de nuestros coeficientes usándola. Si el nivel de descarga del enlace es mínimo, entonces todo está bien, Slowdown y Drop son iguales a cero, dejamos entrar a todos los nuevos usuarios. Tan pronto como el nivel de carga supera un cierto umbral, comenzamos a negar el servicio a algunos usuarios en este enlace. En algún momento, si la carga continúa creciendo, simplemente dejamos de lanzar nuevas sesiones.
Aquí hay un matiz interesante: las sesiones actuales tienen prioridad en este esquema. Creo que está claro por qué sucede esto: si tu usuario ya te proporciona un patrón de carga estable, no quieres llevarlo a ningún lado, porque de esta forma aumentas la dinámica del sistema, y cuanto más estable el sistema, más fácil nos resulta controlarlo.
Sin embargo, la descarga puede seguir creciendo. En algún momento, podemos empezar a eliminar algunas de las sesiones o incluso eliminar por completo la carga de este enlace.
De esta forma lanzamos este algoritmo en los primeros partidos de la Copa Mundial de la FIFA. Probablemente sea interesante ver qué tipo de imagen vimos. Ella estaba sobre lo siguiente.
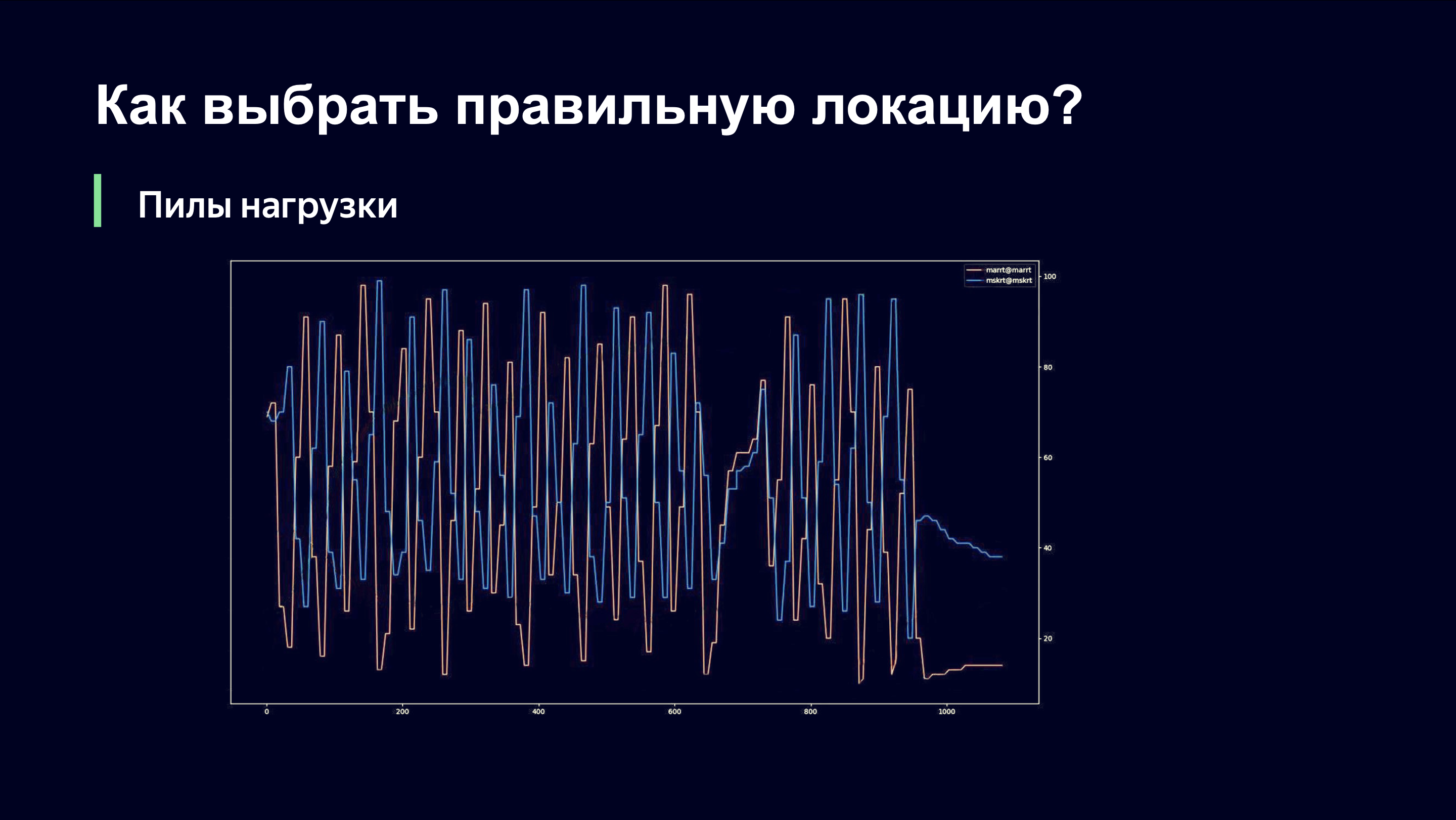
Incluso a simple vista, un observador externo puede comprender que probablemente algo anda mal aquí y preguntarme: "Andrey, ¿estás bien?" Y si fueras mi jefe, correrías por la habitación y gritarías: “¡Andrey, Dios mío! ¡Hazlo todo atrás! ¡Devuélvelo todo como estaba! " Te contamos qué está pasando aquí.
En el eje X, el tiempo, en el eje Y, observamos el nivel de carga del enlace. Hay dos enlaces que sirven al mismo sitio. Es importante entender que en este momento solo usamos el esquema de monitoreo de carga del enlace que se quita del equipo de red y, por lo tanto, no pudimos responder rápidamente a la dinámica de carga.
Cuando enviamos usuarios a uno de los enlaces, hay un fuerte aumento en el tráfico en ese enlace. El enlace está sobrecargado. Quitamos la carga y nos encontramos en el lado derecho de la función que vimos en el gráfico anterior. Y comenzamos a eliminar usuarios antiguos y dejamos de admitir nuevos. Necesitan ir a algún lugar y, por supuesto, van al siguiente enlace. La última vez pudo haber sido una prioridad menor, pero ahora la tienen en prioridad.
El segundo enlace repite la misma imagen. Aumentamos bruscamente la carga, notamos que el enlace está sobrecargado, eliminamos la carga y estos dos enlaces están en antifase en términos del nivel de carga.
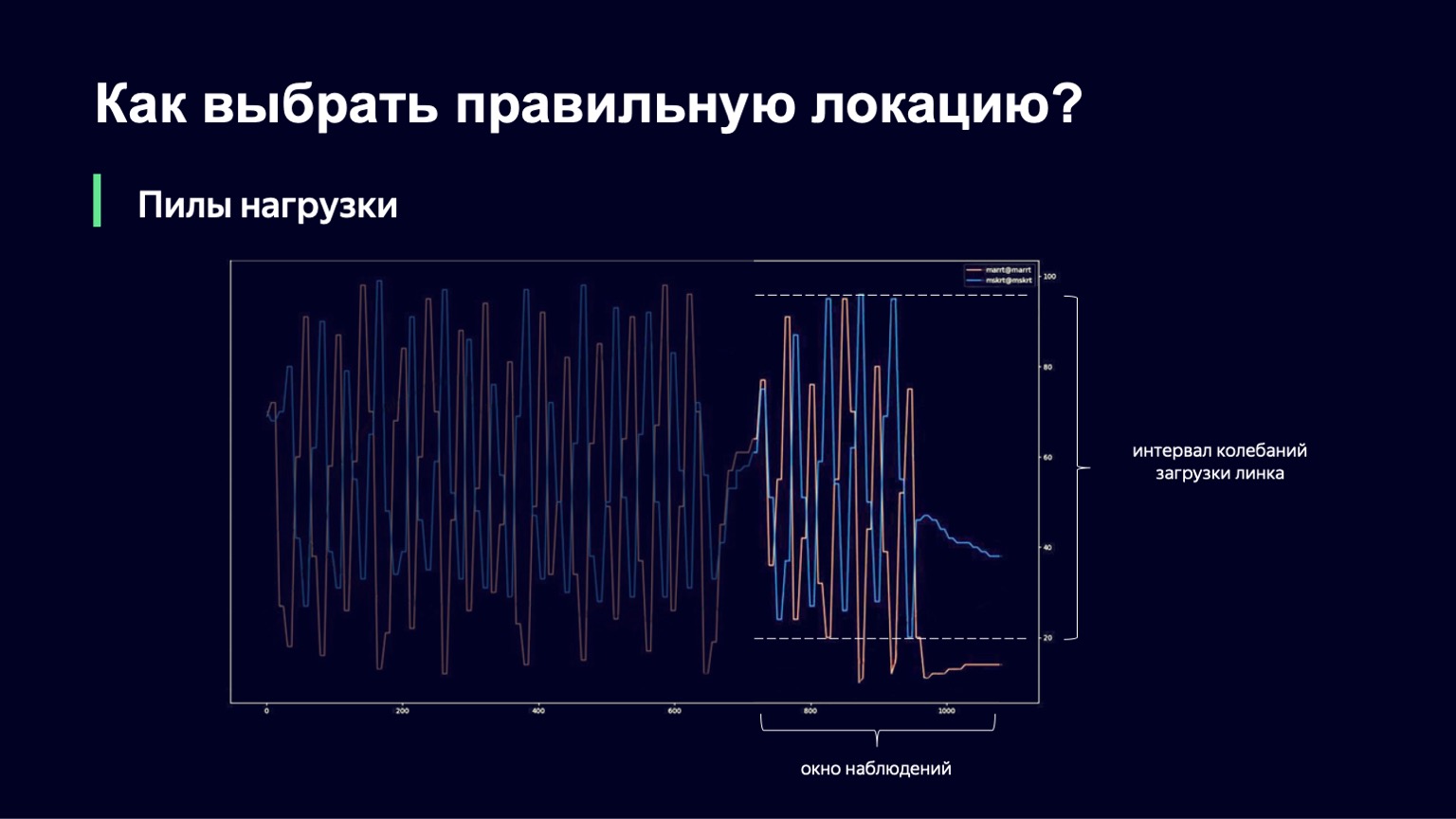
¿Qué se puede hacer? Podemos analizar la dinámica del sistema, notar esto con un gran aumento de carga y humedecerlo un poco. Eso es exactamente lo que hicimos. Tomamos el momento actual, llevamos la ventana de observación al pasado durante unos minutos, por ejemplo, 2-3 minutos, y observamos cuánto cambia la carga del enlace en este intervalo. La diferencia entre los valores mínimo y máximo se denominará intervalo de oscilación de este enlace. Y si este intervalo de oscilación es grande, agregaremos amortiguación, aumentando así nuestra Ralentización y comenzando a ejecutar menos sesiones.
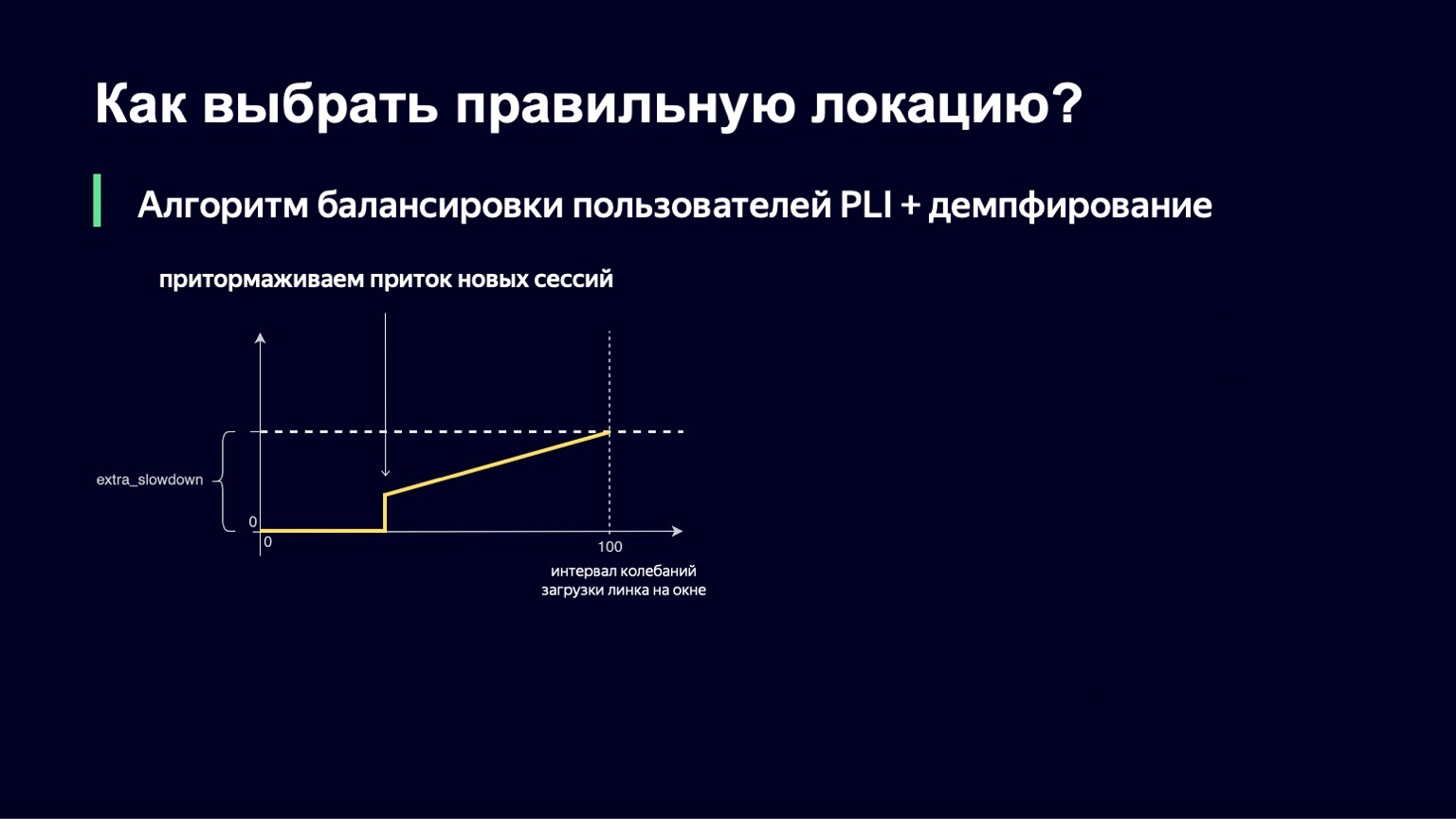
Esta función se ve casi igual que la anterior, con un poco menos de fracturas. Si tenemos un pequeño intervalo para descargar oscilaciones, no agregaremos ningún extra_slowdown. Y si el intervalo de oscilación comienza a crecer, entonces extra_slowdown toma valores distintos de cero, luego lo agregaremos al Slowdown principal.
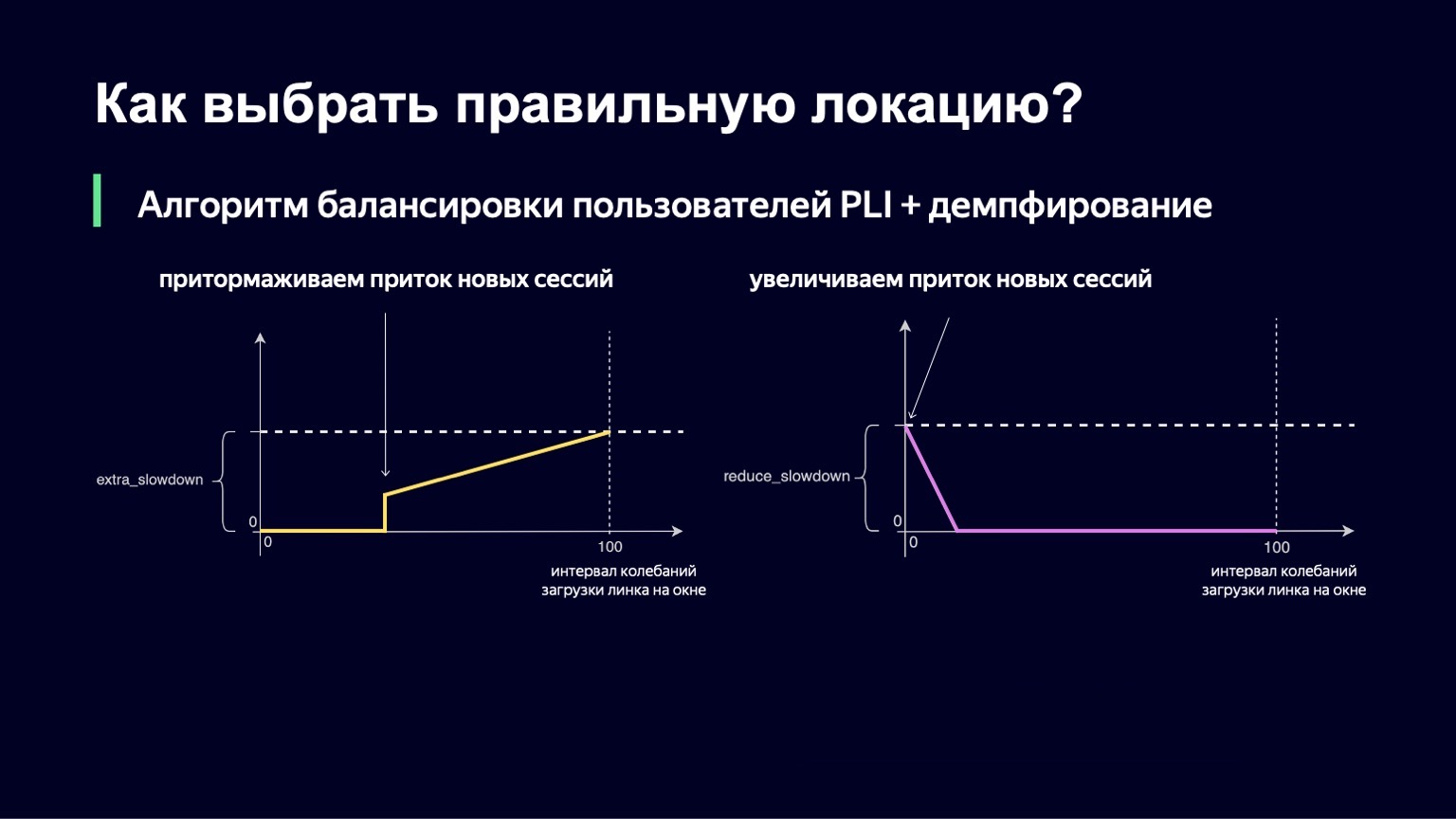
La misma lógica funciona con valores bajos del intervalo de oscilación. Si tiene una mínima vacilación en el enlace, entonces, por el contrario, desea dejar entrar un poco más de usuarios allí, reducir la ralentización y, por lo tanto, utilizar mejor su enlace.
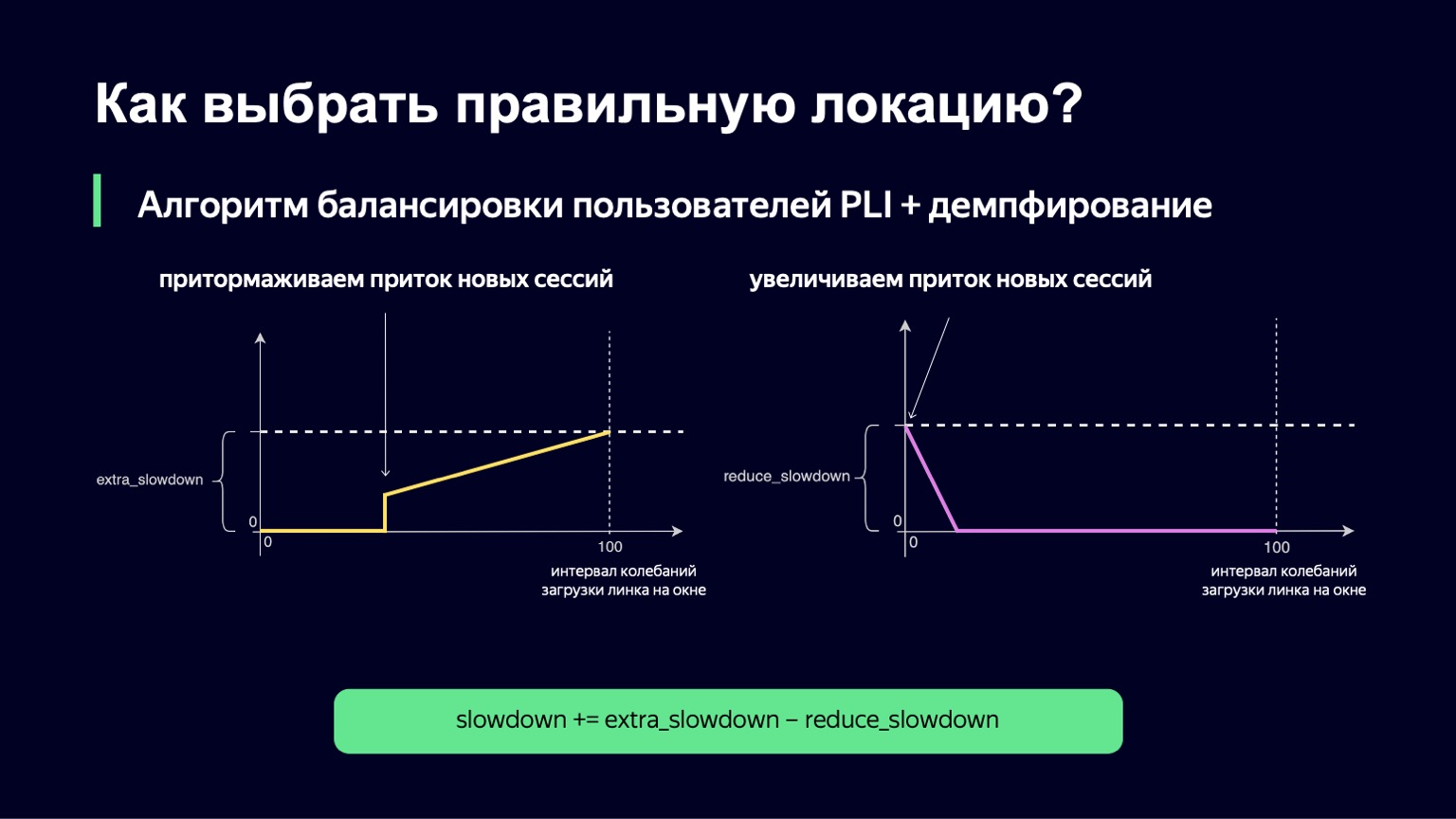
También hemos implementado esta parte. La fórmula final se ve así. Al mismo tiempo, garantizamos que ambos valores, extra_slowdown y reduce_slowdown, nunca tienen un valor distinto de cero al mismo tiempo, por lo que solo uno de ellos funciona de manera efectiva. De esta forma, esta fórmula de equilibrio ha sobrevivido a todos los partidos principales de la Copa Mundial de la FIFA. Incluso en los partidos más populares, trabajó bastante bien: estos son "Rusia - Croacia", "Rusia - España". Durante estos partidos, distribuimos un récord para los volúmenes de tráfico de Yandex: 1,5 terabits por segundo. Lo pasamos con calma. Desde entonces, la fórmula no ha cambiado de ninguna manera, porque no ha habido ese tráfico en nuestro servicio desde entonces, hasta cierto momento.
Entonces nos sobrevino una pandemia. La gente fue enviada a sentarse en casa, y en casa hay buena Internet, TV, tableta y mucho tiempo libre. El tráfico a nuestros servicios comenzó a crecer de forma orgánica, bastante rápida y significativa. Ahora este tipo de carga, como lo fue durante el Mundial, es nuestra rutina diaria. Desde entonces, hemos expandido un poco nuestros canales con operadores, pero, sin embargo, comenzamos a pensar en la próxima iteración de nuestro algoritmo, qué debería ser y cómo podemos utilizar mejor nuestra red.

¿Cuáles son las desventajas de nuestro algoritmo anterior? No hemos resuelto dos problemas. No nos hemos deshecho por completo de las cargas de "sierra". Hemos mejorado mucho la imagen y la amplitud de estas fluctuaciones es mínima, el período ha aumentado mucho, lo que también permite una mejor utilización de la red. Pero de todos modos aparecen de vez en cuando, permanecen. No hemos aprendido a utilizar la red al nivel que nos gustaría. Por ejemplo, no podemos usar la configuración para establecer el nivel de carga de enlace máximo deseado de 80-85%.

¿Qué pensamientos tenemos para la próxima iteración del algoritmo? ¿Cómo imaginamos la utilización ideal de la red? Una de las áreas prometedoras, al parecer, es la opción cuando tiene un solo lugar para tomar decisiones sobre el tráfico. Usted recopila todas las métricas en un solo lugar, allí entra una solicitud de usuario para descargar segmentos, y en cualquier momento tiene un estado completo del sistema, es muy fácil para usted tomar decisiones.
Pero aquí hay dos matices. Primero, no es costumbre en Yandex escribir "puntos comunes de toma de decisiones", simplemente porque con nuestros niveles de carga, con nuestro tráfico, ese lugar se convierte rápidamente en un cuello de botella.
Hay un matiz más: en Yandex también es importante escribir sistemas tolerantes a fallas. A menudo cerramos por completo los centros de datos, mientras que su componente debería seguir funcionando sin errores, sin interrupciones. Y de esta forma, este único lugar se convierte, de hecho, en un sistema distribuido que necesitas controlar, y esta es una tarea un poco más difícil que la que nos gustaría resolver en este lugar.

Definitivamente necesitamos métricas rápidas. Sin ellos, lo único que puede hacer para evitar el sufrimiento del usuario es subutilizar la red. Pero eso tampoco nos conviene.
Si observa nuestro sistema en un nivel alto, queda claro que nuestro sistema es un sistema dinámico con retroalimentación. Tenemos una carga personalizada, que es una señal de entrada. La gente viene y va. Tenemos una señal de control, los mismos dos valores que podemos cambiar en tiempo real. Para tales sistemas dinámicos con retroalimentación, la teoría del control automático se ha desarrollado durante mucho tiempo, varias décadas. Y son sus componentes los que nos gustaría utilizar para estabilizar nuestro sistema.
Miramos el filtro de Kalman. Esto es algo tan interesante que le permite construir un modelo matemático del sistema y, con métricas ruidosas o en ausencia de algunas clases de métricas, mejorar el modelo usando su sistema real. Y luego tomar una decisión sobre un sistema real basado en un modelo matemático. Desafortunadamente, resultó que no tenemos muchas clases de métricas que podamos usar y este algoritmo no se puede aplicar.
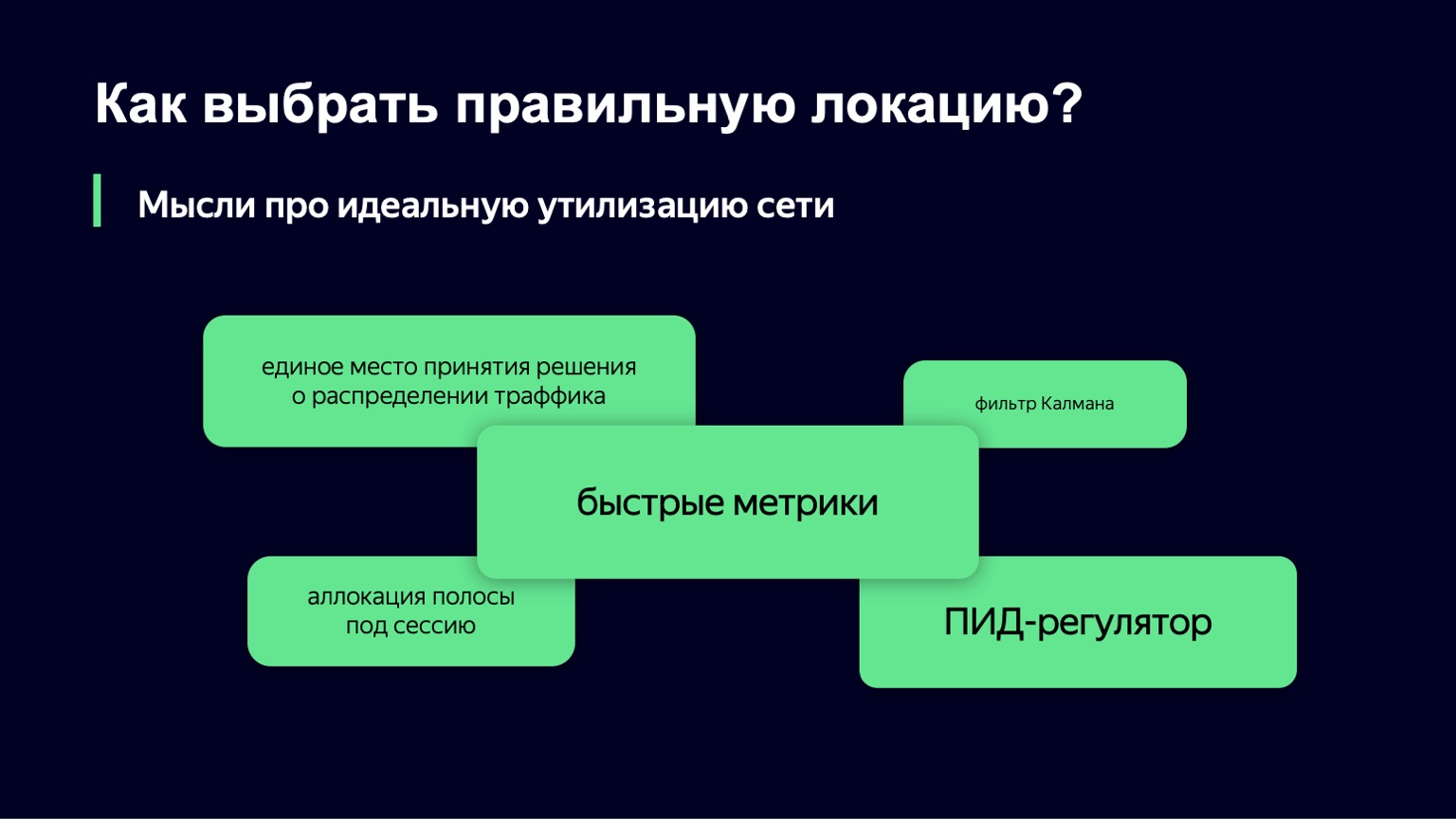
Nos acercamos por el otro lado, tomamos como base otro componente de esta teoría: el controlador PID. No sabe nada sobre tu sistema. Su tarea es conocer el estado ideal del sistema, es decir, nuestro nivel de carga deseado y el estado actual del sistema, por ejemplo, el nivel de carga. Considera que la diferencia entre estos dos estados es un error y, utilizando sus algoritmos internos, controla la señal de control, es decir, nuestros valores de Slowdown y Drop. Su propósito es minimizar el error en el sistema.
Probaremos este controlador PID en producción día a día. Quizás en unos meses podamos contarte los resultados.
En esto probablemente terminaremos sobre la red. Me gustaría mucho contarte cómo distribuimos el tráfico dentro de la propia ubicación, cuando ya lo hemos elegido entre los hosts. Pero no hay tiempo para eso. Este es probablemente un tema para un gran informe separado.

Por lo tanto, en la próxima serie, aprenderá cómo utilizar de manera óptima la caché en los hosts, qué hacer con el tráfico caliente y frío, así como de dónde proviene el tráfico cálido, cómo el tipo de contenido afecta el algoritmo para su distribución y qué video da el mayor impacto de caché en el servicio y quién. quien canta una canción.
Tengo otra historia interesante. En la primavera, como saben, comenzó la cuarentena. Yandex ha tenido durante mucho tiempo una plataforma educativa llamada Yandex.Tutorial, que permite a los maestros cargar videos y lecciones. Los estudiantes vienen allí y miran el contenido. Durante la pandemia, Yandex comenzó a apoyar a las escuelas, invitarlas activamente a su plataforma para que los estudiantes puedan estudiar de forma remota. Y en algún momento vimos un crecimiento bastante bueno en el tráfico, una imagen bastante estable. Pero en una de las noches de abril, vimos algo como lo siguiente en las listas.
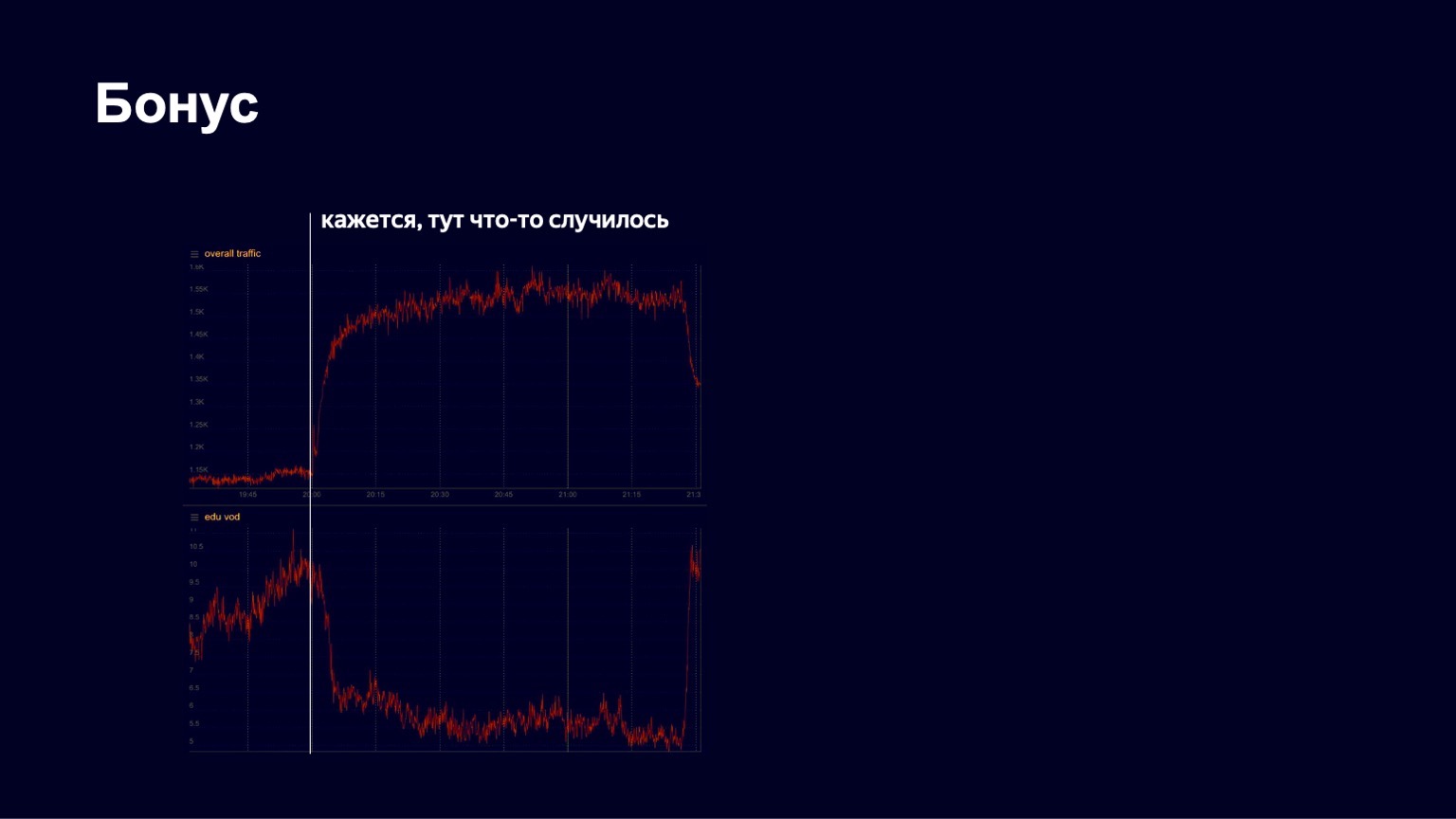
A continuación se muestra una imagen del tráfico en el contenido educativo. Vimos que cayó bruscamente en algún momento. Comenzamos a entrar en pánico, a descubrir qué estaba pasando en general, qué estaba roto. Luego notamos que el tráfico general al servicio comenzó a crecer. Evidentemente, ha ocurrido algo interesante.
De hecho, en ese momento sucedió lo siguiente.
Así de rápido baila el hombre.
Comenzó el concierto de Little Big, y todos los estudiantes se fueron para verlo. Pero después del final del concierto, regresaron y continuaron estudiando con éxito. Vemos esas imágenes con bastante frecuencia en nuestro servicio. Por tanto, creo que nuestro trabajo es bastante interesante. ¡Gracias a todos! Probablemente terminaré con esto sobre CDN.