( NLP) por Tim Dettmers, Ph.D. El aprendizaje profundo (DL) es un área con una alta demanda de potencia informática, por lo que su elección de GPU determinará fundamentalmente su experiencia en esta área. Pero, ¿qué propiedades es importante considerar al comprar una nueva GPU? ¿Memoria, núcleos, núcleos tensoriales? ¿Cómo tomar la mejor decisión en términos de relación calidad-precio? En este artículo, analizaré en detalle todas estas preguntas, conceptos erróneos comunes, le brindaré una comprensión intuitiva de la GPU, así como algunos consejos para ayudarlo a tomar la decisión correcta.
Este artículo está escrito para brindarle diferentes niveles de comprensión de la GPU, incl. nueva serie Ampere de NVIDIA. Tienes una opción:
- Si no está interesado en los detalles de la GPU, qué hace exactamente que la GPU sea rápida y qué es lo único que tienen las nuevas GPU de la serie NVIDIA RTX 30 Ampere, puede omitir el comienzo del artículo, hasta los gráficos sobre velocidad y velocidad por costo de $ 1, así como la sección de recomendaciones. Este es el núcleo de este artículo y el contenido más valioso.
- Si está interesado en preguntas específicas, entonces cubrí las más frecuentes en la última parte del artículo.
- Si necesita una comprensión profunda de cómo funcionan las GPU y los núcleos tensores, lo mejor que puede hacer es leer este artículo de principio a fin. Dependiendo de su conocimiento de temas específicos, puede saltarse uno o dos capítulos.
Cada sección está precedida por un breve resumen para ayudarlo a decidir si leerlo en su totalidad o no.
Contenido
GPU?
GPU,
/ L1 /
Ampere
Ampere
Ampere
Ampere / RTX 30
GPU
GPU
GPU
11 ?
11 ?
GPU-
GPU
GPU?
PCIe 4.0?
PCIe 8x/16x?
RTX 3090, 3 PCIe?
4 RTX 3090 4 RTX 3080?
GPU ?
NVLink, ?
. ?
?
?
Intel GPU?
?
AMD GPU + ROCm - NVIDIA GPU + CUDA?
, – GPU?
,
Este artículo está estructurado de la siguiente manera. Primero explico qué hace que una GPU sea rápida. Describiré la diferencia entre procesadores y GPU, núcleos tensoriales, ancho de banda de memoria, jerarquía de memoria de GPU y cómo se relaciona todo con el rendimiento en las tareas de GO. Estas explicaciones pueden ayudarlo a comprender mejor qué parámetros de GPU necesita. Luego, daré estimaciones teóricas del rendimiento de la GPU y su correspondencia con algunas pruebas de velocidad de NVIDIA para obtener datos de rendimiento confiables sin sesgos. Describiré las características únicas de las GPU de la serie NVIDIA RTX 30 Ampere a tener en cuenta al comprar. Luego, daré recomendaciones de GPU para opciones con 1-2 chips, 4, 8 y clústeres de GPU. Luego habrá una sección de respuestas a las preguntas más frecuentes que me hicieron en Twitter.También disipará conceptos erróneos comunes y destacará varios problemas como nubes versus computadoras de escritorio, enfriamiento, AMD versus NVIDIA y otros.
¿Cómo funcionan las GPU?
Si usa mucho las GPU, es útil comprender cómo funcionan. Este conocimiento te será útil para descubrir por qué en algunos casos las GPU son más lentas y en otros más rápidas. Y luego puede comprender si necesita una GPU y qué opciones de hardware pueden competir con ella en el futuro. Puede omitir esta sección si solo desea información útil sobre el rendimiento y los argumentos para elegir una GPU en particular. La mejor explicación general de cómo funcionan las GPU se encuentra en la respuesta en Quora .
Esta es una explicación general y explica bien la pregunta de por qué las GPU son más adecuadas para GO que los procesadores. Si estudiamos los detalles, podemos comprender en qué se diferencian las GPU entre sí.
Las características de la GPU más importantes que afectan la velocidad de procesamiento
Esta sección le ayudará a pensar de forma más intuitiva sobre el rendimiento en el campo de GO. Esta comprensión le ayudará a evaluar usted mismo las GPU futuras.
Núcleos tensores
Resumen:
- Los núcleos tensoriales reducen el número de ciclos de reloj necesarios para contar multiplicaciones y sumas en 16 veces, en mi ejemplo para una matriz de 32 × 32 de 128 a 8 ciclos de reloj.
- Los núcleos tensoriales reducen la dependencia del acceso repetido a la memoria compartida al ahorrar ciclos de acceso a la memoria.
- Los núcleos tensoriales son tan rápidos que la computación ya no es un cuello de botella. El único cuello de botella es la transferencia de datos a ellos.
Hoy en día existen tantas GPU económicas que casi todo el mundo puede permitirse una GPU con núcleos tensores. Por lo tanto, siempre recomiendo GPU con núcleos tensores. Es útil comprender cómo funcionan para apreciar la importancia de estos módulos computacionales que se especializan en la multiplicación de matrices. Usando un ejemplo simple de multiplicación de matrices A * B = C, donde el tamaño de todas las matrices es 32 × 32, le mostraré cómo se ve la multiplicación con y sin núcleos tensoriales.
Para comprender esto, primero debe comprender el concepto de barras. Si el procesador funciona a 1 GHz, lo hace 10 9garrapatas por segundo. Cada reloj es una oportunidad para realizar cálculos. Pero en su mayor parte, las operaciones toman más de un ciclo de reloj. Resulta una canalización: para comenzar a realizar una operación, primero debe esperar tantos ciclos de reloj como sea necesario para completar la operación anterior. Esto también se denomina operación retrasada.
A continuación, se muestran algunas duraciones o retrasos importantes de una operación en ticks:
- Acceso a memoria global hasta 48 GB: ~ 200 ciclos de reloj.
- Acceso a memoria compartida (hasta 164 KB por multiprocesador de transmisión): ~ 20 relojes.
- Multiplicación-suma combinada (SUS): 4 compases.
- Multiplicación de matrices en núcleos tensoriales: 1 ciclo de reloj.
Además, debe saber que la unidad más pequeña de subprocesos en una GPU, un paquete de 32 subprocesos, se llama warp. Las urdimbres suelen funcionar de forma sincrónica: todos los hilos dentro de la urdimbre deben esperar entre sí. Todas las operaciones de memoria de la GPU están optimizadas para deformaciones. Por ejemplo, cargar desde la memoria global toma 32 * 4 bytes - 32 números de punto flotante, uno de esos números para cada hilo en la deformación. En un multiprocesador de transmisión (el equivalente a un núcleo de procesador para una GPU), puede haber hasta 32 warps = 1024 hilos. Los recursos de multiprocesador se comparten entre todos los warps activos. Por lo tanto, a veces necesitamos menos warps para funcionar, de modo que un warp tenga más registros, memoria compartida y recursos centrales de tensor.
Para ambos ejemplos, supongamos que tenemos los mismos recursos informáticos. En este pequeño ejemplo de multiplicación de matrices 32 × 32, utilizamos 8 multiprocesadores (~ 10% del RTX 3090) y 8 deformaciones en un multiprocesador.
Multiplicación de matrices sin núcleos tensoriales
Si necesitamos multiplicar matrices A * B = C, cada una de las cuales tiene un tamaño de 32 × 32, entonces necesitamos cargar datos desde la memoria, a la que estamos accediendo constantemente, en la memoria compartida, ya que los retrasos de acceso son aproximadamente 10 veces menores (no 200 barras y 20 barras). Un bloque de memoria en la memoria compartida a menudo se denomina mosaico de memoria o simplemente mosaico. La carga de dos números de coma flotante de 32x32 en un mosaico de memoria compartida se puede hacer en paralelo usando 2 * 32 warps. Tenemos 8 multiprocesadores con 8 warps cada uno, por lo que gracias a la paralelización, necesitamos realizar una carga secuencial desde la memoria global a la compartida, lo que tomará 200 ciclos de reloj.
Para multiplicar matrices, necesitamos cargar un vector de 32 números de la memoria compartida A y la memoria compartida B, y realizar el CMS, y luego almacenar la salida en los registros C. Dividimos este trabajo para que cada multiprocesador maneje 8 productos escalares (32 × 32 ) para calcular 8 datos de salida para C. Por qué hay exactamente 8 de ellos (en los algoritmos antiguos, 4), esta es una característica puramente técnica. Para averiguarlo, recomiendo leer el artículo de Scott Gray . Esto significa que tendremos 8 accesos a la memoria compartida, con un costo de 20 ciclos cada uno, y 8 operaciones CMS (32 en paralelo), con un costo de 4 ciclos cada uno. En total, el costo será:
200 ticks (memoria global) + 8 * 20 ticks (memoria compartida) + 8 * 4 ticks (CMS) = 392 ticks
Ahora veamos este costo para los núcleos tensoriales.
Multiplicación de matrices con núcleos tensoriales
Usando núcleos tensores, puede multiplicar matrices 4 × 4 en un ciclo. Para hacer esto, necesitamos copiar la memoria a los núcleos tensores. Como se indicó anteriormente, necesitamos leer datos de la memoria global (200 ticks) y almacenarlos en la memoria compartida. Para multiplicar matrices 32 × 32, necesitamos realizar operaciones 8 × 8 = 64 en núcleos tensoriales. Un multiprocesador contiene 8 núcleos tensores. Con 8 multiprocesadores, tenemos 64 núcleos tensoriales, ¡tantos como necesitemos! Podemos transferir datos desde la memoria compartida a los núcleos tensoriales en 1 transferencia (20 ciclos de reloj) y luego realizar todas estas 64 operaciones en paralelo (1 ciclo de reloj). Esto significa que el costo total de la multiplicación de matrices en núcleos tensoriales será:
200 ciclos (memoria global) + 20 ciclos (memoria compartida) + 1 ciclo (núcleos tensoriales) = 221 ciclos
Por lo tanto, al usar núcleos tensoriales, reducimos significativamente el costo de la multiplicación de matrices, de 392 a 221 ciclos de reloj. En nuestro ejemplo simplificado, los núcleos tensoriales han reducido el costo tanto del acceso a la memoria compartida como de las operaciones de SNS.
Aunque este ejemplo sigue aproximadamente la secuencia de pasos computacionales con y sin núcleos tensoriales, tenga en cuenta que este es un ejemplo muy simplificado. En casos reales, la multiplicación de matrices implica grandes mosaicos de memoria y secuencias de acciones ligeramente diferentes.
Sin embargo, me parece que este ejemplo deja en claro por qué el siguiente atributo, el ancho de banda de la memoria, es tan importante para las GPU con núcleos tensoriales. Dado que la memoria global es lo más caro al multiplicar matrices con núcleos tensores, nuestras GPU serían mucho más rápidas si pudiéramos reducir la latencia de acceso a la memoria global. Esto se puede hacer aumentando la velocidad del reloj de la memoria (más ciclos de reloj por segundo, pero más calor y consumo de energía) o aumentando el número de elementos que se pueden transferir a la vez (ancho del bus).
Ancho de banda de memoria
En la sección anterior, vimos qué tan rápidos son los núcleos tensoriales. Son tan rápidos que permanecen inactivos la mayor parte del tiempo, esperando que lleguen los datos de la memoria global. Por ejemplo, durante el entrenamiento para el proyecto BERT Large, donde se usaron matrices muy grandes (cuanto más grandes, mejor para los núcleos tensoriales), la utilización de los núcleos tensoriales en TFLOPS fue aproximadamente del 30%, lo que significa que el 70% del tiempo los núcleos tensoriales estuvieron inactivos.
Esto significa que al comparar dos GPU con núcleos tensores, uno de los mejores indicadores de rendimiento para cada uno es el ancho de banda de la memoria. Por ejemplo, la GPU A100 tiene un ancho de banda de 1,555 GB / s, mientras que la V100 tiene 900 GB / s. Un cálculo simple dice que el A100 será más rápido que el V100 en 1555/900 = 1,73 veces.
Memoria compartida / caché L1 / registros
Dado que el factor que limita la velocidad es la transferencia de datos a la memoria de los núcleos tensoriales, debemos recurrir a otras propiedades de la GPU, lo que nos permite acelerar la transferencia de datos a ellos. Asociados con esto están la memoria compartida, la caché L1 y el número de registros. Para comprender cómo la jerarquía de la memoria acelera las transferencias de datos, es útil comprender cómo se multiplica la matriz en la GPU.
Para la multiplicación de matrices, usamos una jerarquía de memoria que va de la memoria global lenta a la memoria compartida local rápida y luego a los registros ultrarrápidos. Sin embargo, cuanto más rápida es la memoria, más pequeña es. Por lo tanto, necesitamos dividir las matrices en matrices más pequeñas y luego multiplicar estos mosaicos más pequeños en la memoria compartida local. Entonces sucederá rápidamente y más cerca del multiprocesador de transmisión (PM), el equivalente al núcleo del procesador. Los núcleos tensoriales nos permiten dar un paso más: tomamos todos los mosaicos y cargamos algunos de ellos en núcleos tensoriales. La memoria compartida procesa los mosaicos de matriz de 10 a 50 veces más rápido que la memoria global de la GPU, y los registros del núcleo tensor lo procesan 200 veces más rápido que la memoria global de la GPU.
Aumentar el tamaño de los mosaicos nos permite reutilizar más memoria. Escribí sobre esto en detalle en mi artículo TPU vs GPU . En TPU, hay un mosaico muy, muy grande para cada núcleo tensor. Las TPU pueden reutilizar mucha más memoria con cada nueva transferencia desde la memoria global, lo que las hace un poco más eficientes en el manejo de la multiplicación de matrices en comparación con las GPU.
Los tamaños de los mosaicos están determinados por la cantidad de memoria para cada PM, el equivalente a un núcleo de procesador en una GPU Según las arquitecturas, estos volúmenes son:
- Volta: 96 KB de memoria compartida / 32 KB L1
- Turing: 64 KB de memoria compartida / 32 KB L1
- Amperio: 164 KB de memoria compartida / 32 KB L1
Puede ver que Ampere tiene mucha más memoria compartida, lo que permite usar mosaicos más grandes, lo que reduce la cantidad de accesos a la memoria global. Por lo tanto, Ampere hace un uso más eficiente del ancho de banda de la memoria de la GPU. Esto aumenta el rendimiento en un 2-5%. El aumento es especialmente notable en matrices enormes.
Los núcleos de tensor de amperios tienen otra ventaja: tienen una mayor cantidad de datos comunes a varios subprocesos. Esto reduce el número de llamadas de registro. El tamaño de los registros está limitado a 64 k por PM o 255 por hilo. En comparación con Volta, Ampere Tensor Cores usa 3 veces menos registros, lo que significa que hay más Tensor Cores activos por mosaico en la memoria compartida. En otras palabras, podemos cargar 3 veces más núcleos tensoriales con el mismo número de registros. Sin embargo, dado que el ancho de banda sigue siendo un cuello de botella, el aumento de TFLOPS en la práctica será insignificante en comparación con lo teórico. Los nuevos núcleos tensoriales han mejorado el rendimiento en aproximadamente un 1-3%.
En general, se puede ver que la arquitectura Ampere se ha optimizado para usar el ancho de banda de la memoria de manera más eficiente a través de una jerarquía mejorada, desde la memoria global hasta los mosaicos de memoria compartida y los registros del núcleo tensor.
Evaluación de la efectividad de Ampere en GO
Resumen:
- Las estimaciones teóricas basadas en el ancho de banda de la memoria y la jerarquía de memoria mejorada para las GPU Ampere predicen una aceleración de 1,78 a 1,87 veces.
- NVIDIA ha publicado datos sobre medidas de velocidad para las GPU Tesla A100 y V100. Son más marketing, pero se puede construir un modelo imparcial sobre su base.
- El modelo imparcial sugiere que, en comparación con el V100, el Tesla A100 es 1,7 veces más rápido en el procesamiento del lenguaje natural y 1,45 veces más rápido en la visión por computadora.
Esta sección es para aquellos que buscan profundizar en los detalles técnicos de cómo obtuve los puntajes de rendimiento de la GPU Ampere. Si no está interesado, puede omitirlo con seguridad.
Estimaciones de velocidad teóricas en amperios
Dados los argumentos anteriores, uno esperaría que la diferencia entre las dos arquitecturas de GPU con núcleos tensoriales debería haber estado principalmente en el ancho de banda de la memoria. Los beneficios adicionales provienen de una mayor memoria compartida y caché L1, y un uso eficiente de los registros.
El ancho de banda de la GPU Tesla A100 aumenta en 1555/900 = 1,73 veces en comparación con el Tesla V100. También es razonable esperar un aumento del 2-5% en la velocidad debido a la memoria total más grande y del 1-3% debido a la mejora en los núcleos tensoriales. Resulta que la aceleración debería ser de 1,78 a 1,87 veces.
Ampere
Digamos que tenemos una sola puntuación de GPU para una arquitectura como Ampere, Turing o Volta. Es fácil extrapolar estos resultados a otras GPU de la misma arquitectura o serie. Afortunadamente, NVIDIA ya ha realizado evaluaciones comparativas que comparan el A100 y el V100 en varias tareas relacionadas con la visión por computadora y la comprensión del lenguaje natural. Desafortunadamente, NVIDIA ha hecho todo lo posible para que estos números no se puedan comparar directamente; en las pruebas usaron diferentes tamaños de paquetes de datos y diferentes números de GPU para que el A100 no pudiera ganar. Entonces, en cierto sentido, los indicadores de desempeño obtenidos son en parte honestos, en parte publicitarios. En general, se puede argumentar que el aumento en el tamaño del paquete de datos se justifica porque el A100 tiene más memoria; sin embargo,Para comparar arquitecturas de GPU, necesitamos comparar datos de rendimiento no sesgados en tareas con el mismo tamaño de paquete de datos.
Para obtener estimaciones no sesgadas, puede escalar las mediciones de V100 y A100 de dos maneras: tenga en cuenta la diferencia en el tamaño del paquete de datos o tenga en cuenta la diferencia en el número de GPU: 1 frente a 8. Tenemos suerte y podemos encontrar estimaciones similares para ambos casos en los datos proporcionados por NVIDIA.
Duplicar el tamaño del paquete aumenta el rendimiento en un 13,6% en imágenes por segundo (para redes neuronales convolucionales, CNN). Medí la velocidad de la misma tarea con la arquitectura Transformer en mi RTX Titan y, sorprendentemente, obtuve el mismo resultado: 13,5%. Esta parece ser una estimación confiable.
Al aumentar la paralelización de las redes, al aumentar la cantidad de GPU, perdemos rendimiento debido a la sobrecarga asociada con las redes. Pero la GPU A100 8x funciona mejor en redes (NVLink 3.0) en comparación con la GPU V100 8x (NVLink 2.0), otro factor confuso. Si observa los datos de NVIDIA, puede ver que para procesar el SNS, el sistema con el octavo A100 tiene un 5% menos de sobrecarga que el sistema con el octavo V10000. Esto significa que si la transición del primer A10000 al octavo A10000 le da una aceleración de, digamos, 7.0 veces, entonces la transición del primer V10000 al octavo V10000 le da una aceleración de solo 6.67 veces. Para los transformadores, esta cifra es del 7%.
Con esta información, podemos estimar la aceleración de algunas arquitecturas GO específicas directamente a partir de los datos proporcionados por NVIDIA. El Tesla A100 tiene las siguientes ventajas de velocidad sobre el Tesla V100:
- SE-ResNeXt101: 1,43 veces.
- Masked-R-CNN: 1,47 veces.
- Transformador (12 capas, traducción automática, WMT14 en-de): 1,70 veces.
Por lo tanto, para la visión por computadora, los números se obtienen por debajo de la estimación teórica. Esto puede deberse a medidas de tensor más pequeñas, la sobrecarga de las operaciones necesarias para preparar una multiplicación de matrices como img2col o FFT, u operaciones que no pueden saturar la GPU (las capas resultantes suelen ser relativamente pequeñas). También pueden ser artefactos de ciertas arquitecturas (convolución agrupada).
La valoración práctica de la velocidad del transformador es muy cercana a la teórica. Probablemente porque los algoritmos para trabajar con matrices grandes son muy sencillos. Utilizaré estimaciones prácticas para calcular la rentabilidad de una GPU.
Posibles inexactitudes de estimaciones
Las anteriores son clasificaciones comparativas para A100 y V100. En el pasado, NVIDIA degradó en secreto el rendimiento de las GPU RTX para "juegos": uso reducido de núcleos tensores, ventiladores de juegos añadidos para refrigeración y transferencia de datos prohibida entre GPU. Es posible que la serie RT 30 también haya tenido deterioros desconocidos sobre el Ampere A100.
Que más considerar en el caso del Ampere / RTX 30
Resumen:
- Ampere le permite entrenar redes basadas en matrices dispersas, lo que acelera el proceso de entrenamiento hasta dos veces.
- El entrenamiento de redes dispersas todavía se usa raramente, pero gracias a él, Ampere no se volverá obsoleto pronto.
- Ampere tiene nuevos tipos de datos de baja precisión que facilitan mucho el uso de baja precisión, pero no necesariamente aumentará la velocidad con respecto a las GPU anteriores.
- El nuevo diseño del ventilador es bueno si tiene espacio libre entre las GPU; sin embargo, no está claro si las GPU que están cerca una de la otra se enfriarán de manera efectiva.
- El diseño de 3 ranuras del RTX 3090 será un desafío para las compilaciones de 4 GPU. Las posibles soluciones son utilizar opciones de 2 ranuras o expansores PCIe.
- Los cuatro RTX 3090 necesitarán más energía que la que puede ofrecer cualquier fuente de alimentación estándar del mercado.
El nuevo NVIDIA Ampere RTX 30 tiene ventajas adicionales sobre el NVIDIA Turing RTX 20: entrenamiento escaso y procesamiento de datos mejorado por la red neuronal. El resto de las propiedades, como los nuevos tipos de datos, pueden considerarse una simple mejora de conveniencia: aceleran las cosas de la misma manera que la serie Turing, sin requerir programación adicional.
Aprendizaje escaso
Ampere le permite multiplicar matrices dispersas a alta velocidad y automáticamente. Funciona así: se toma una matriz, se corta en trozos de 4 elementos y el núcleo tensor que soporta matrices dispersas permite que dos de estos cuatro elementos sean cero. Esto da como resultado una aceleración 2x porque los requisitos de ancho de banda durante la multiplicación de matrices se reducen a la mitad.
En mi investigación, he trabajado con escasas redes de aprendizaje. El trabajo fue criticado, en particular, por el hecho de que "reduzco los FLOPS requeridos para la red, pero no aumento la velocidad debido a esto, porque las GPU no pueden multiplicar rápidamente matrices dispersas". Bueno, el soporte para la multiplicación de matrices dispersas apareció en los núcleos tensoriales, y mi algoritmo, o cualquier otro algoritmo ( enlace, enlace , enlace , enlace ), que trabaja con matrices dispersas, ahora puede funcionar el doble de rápido durante el entrenamiento.
Aunque esta propiedad se considera actualmente experimental y el entrenamiento en redes dispersas no se aplica universalmente, si su GPU es compatible con esta tecnología, entonces está listo para el futuro del entrenamiento disperso.
Cálculos de baja precisión
Ya he demostrado cómo los nuevos tipos de datos pueden mejorar la estabilidad de la retropropagación de baja fidelidad en mi trabajo. Hasta ahora, el problema de la retropropagación estable con números de punto flotante de 16 bits es que los tipos de datos regulares solo admiten el intervalo [-65,504, 65,504]. Si su gradiente va más allá de este espacio, explotará y producirá valores de NaN. Para evitar esto, generalmente escalamos los valores multiplicándolos por un número pequeño antes de retropropagar para evitar la explosión del gradiente.
El formato Brain Float 16 (BF16) usa más bits para el exponente, por lo que el rango de valores posibles es el mismo que en FP32: [-3 * 10 ^ 38, 3 * 10 ^ 38]. El BF16 tiene menos precisión, es decir menos dígitos significativos, pero la precisión del gradiente cuando se entrenan redes no es tan importante. Por lo tanto, BF16 garantiza que no tenga que escalar ni preocuparse por la explosión del gradiente. Con este formato, deberíamos ver un aumento en la estabilidad del entrenamiento a expensas de una pequeña pérdida de precisión.
Qué significa esto para usted: la precisión del BF16 puede ser más consistente que la del FP16, pero la velocidad es la misma. Con la precisión TF32, obtienes estabilidad casi como FP32 y aceleración casi como FP16. La ventaja es que al usar estos tipos de datos, puede cambiar FP32 a TF32 y FP16 a BF16, ¡sin cambiar nada en el código!
En general, estos nuevos tipos de datos pueden considerarse perezosos, en el sentido de que podría obtener todos sus beneficios utilizando los tipos de datos antiguos y un poco de programación (escalar correctamente, inicializar, normalizar, utilizar Apex). Por lo tanto, estos tipos de datos no proporcionan aceleración, pero facilitan el uso de baja fidelidad en el entrenamiento.
Nuevo diseño de ventilador y problemas de disipación de calor
El nuevo diseño de ventilador para la serie RTX 30 tiene un ventilador de aire y un ventilador de extracción de aire. El diseño en sí es ingenioso y funcionará de manera muy eficiente si hay espacio libre entre las GPU. Sin embargo, no está claro cómo se comportarán las GPU si se fuerzan unas a otras. El ventilador podrá expulsar aire de otras GPU, pero es imposible saber cómo funcionará, ya que su forma es diferente a la que tenía antes. Si planea colocar 1 o 2 GPU donde hay 4 ranuras, entonces no debería tener ningún problema. Pero si desea usar 3-4 RTX 30 GPU en paralelo, primero esperaría los informes sobre las condiciones de temperatura y luego decidí si necesitaba más ventiladores, expansores PCIe u otras soluciones.
En cualquier caso, la refrigeración por agua puede ayudar a resolver el problema del disipador de calor. Muchos fabricantes ofrecen tales soluciones para tarjetas RTX 3080 / RTX 3090, y luego no se calentarán, incluso si hay 4. Sin embargo, no compre soluciones de GPU listas para usar si desea construir una computadora con 4 GPU, ya que será muy difícil en la mayoría de los casos. Distribuir radiadores.
Otra solución al problema de la refrigeración es comprar expansores PCIe y distribuir las tarjetas dentro de la caja. Esto es muy efectivo: yo y otros estudiantes graduados de la Universidad de Vanington hemos utilizado esta opción con gran éxito. No se ve muy bien, ¡pero las GPU no se calientan! Además, esta opción le ayudará en caso de que no tenga suficiente espacio para acomodar la GPU. Si tiene espacio en su estuche, puede, por ejemplo, comprar un RTX 3090 estándar con tres ranuras y distribuirlas mediante expansores por todo el estuche. Así, es posible resolver simultáneamente el problema de espacio y refrigeración de 4 RTX 3090.

Fig. GPU 1: 4 con expansores PCIe
Tarjetas de tres ranuras y problemas de alimentación
El RTX 3090 ocupa 3 ranuras, por lo que no se pueden usar 4 cada uno con los ventiladores predeterminados de NVIDIA. Esto no es sorprendente ya que requiere 350W TDP. El RTX 3080 es solo ligeramente inferior, requiere un TDP de 320 W, y enfriar un sistema con cuatro RTX 3080 será muy difícil.
También es difícil alimentar un sistema con 4 tarjetas de 350W = 1400W. Hay fuentes de alimentación (PSU) de 1600 W, pero es posible que 200 W para el procesador y la placa base no sean suficientes. El consumo máximo de energía se produce solo a plena carga, y durante la HE, el procesador suele tener una carga ligera. Por lo tanto, una PSU de 1600 W puede ser adecuada para 4 RTX 3080, pero para 4 RTX 3090 es mejor buscar una PSU de 1700 W o más. Hoy en día, no existen fuentes de alimentación de este tipo en el mercado. Las unidades de suministro de energía de servidor o los bloques especiales para criptomineros pueden funcionar, pero pueden tener un factor de forma inusual.
Eficiencia de GPU en aprendizaje profundo
La siguiente prueba incluyó no solo comparaciones de Tesla A100 y Tesla V100: construí un modelo que se ajusta a estos datos y cuatro pruebas diferentes, donde se probaron Titan V, Titan RTX, RTX 2080 Ti y RTX 2080 ( enlace , enlace , enlace , enlace ).
También escalé los resultados de referencia para tarjetas de rango medio como RTX 2070, RTX 2060 o Quadro RTX interpolando los puntos de datos de prueba. Por lo general, en la arquitectura de la GPU, dichos datos se escalan linealmente con respecto a la multiplicación de matrices y el ancho de banda de la memoria.
Solo recopilé datos de las pruebas de entrenamiento FP16 con precisión mixta, ya que no veo ninguna razón para usar el entrenamiento con números FP32.

Figura: Figura 2: Rendimiento normalizado por RTX 2080 Ti
En comparación con RTX 2080 Ti, RTX 3090 se ejecuta 1,57 veces más rápido con redes convolucionales, 1,5 veces más rápido con transformadores y cuesta un 15% más. Resulta que el Ampere RTX 30 está mostrando una mejora significativa desde la serie Turing RTX 20.
Tasa de aprendizaje profundo de GPU por costo
¿Qué GPU sería la mejor relación calidad-precio? Todo depende del costo total del sistema. Si es caro, tiene sentido invertir en GPU más caras.
A continuación se muestran datos sobre tres ensamblajes en PCIe 3.0, que utilizo como base para el costo de los sistemas con 2 o 4 GPU. Tomo este costo base y le agrego el costo de la GPU. Calculo este último como el precio medio entre las ofertas de Amazon y eBay. Para los nuevos Amperes, solo uso un precio. En conjunto con los datos de rendimiento anteriores, esto da valores de rendimiento por dólar. Para un sistema con 8 GPU, tomo el barebone Supermicro como estándar de la industria para servidores RTX. Los gráficos que se muestran no incluyen los requisitos de memoria. Primero debe pensar qué memoria necesita y luego buscar las mejores opciones en los gráficos. Consejos de muestra para la memoria:
- Usando transformadores previamente entrenados, o entrenando un pequeño transformador desde cero> = 11 GB.
- Entrenamiento de un gran transformador o red convolucional en investigación o producción:> = 24 GB.
- Creación de prototipos de redes neuronales (transformador o red convolucional)> = 10 GB.
- Participación en concursos de Kaggle> = 8 GB.
- Visión por computadora> = 10 GB.
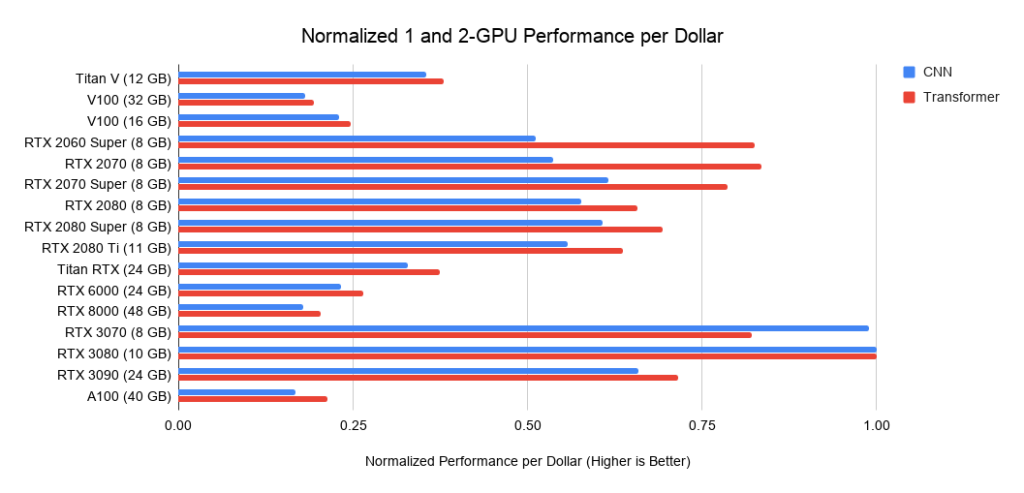
Figura:

Figura 3: Rendimiento en dólares normalizado frente a RTX 3080 . Figura 4: Rendimiento en dólares normalizado frente a RTX 3080
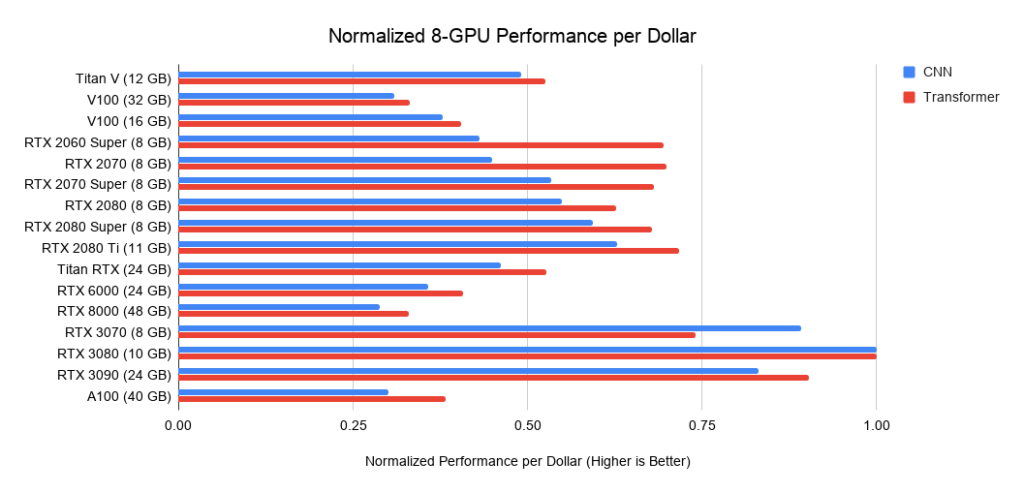
. 5: Rendimiento normalizado en dólares frente a RTX 3080.
Recomendaciones de GPU
Una vez más, quiero enfatizar: al elegir una GPU, primero asegúrese de que tenga suficiente memoria para sus tareas. Los pasos para elegir una GPU deben ser los siguientes:
- , GPU: Kaggle, , , , - .
- , .
- GPU, .
- GPU - ? , RTX 3090, ? GPU? , GPU?
Algunos de los pasos requieren que pienses en lo que quieres y que investigues un poco sobre cuánta memoria están usando otras personas que hacen lo mismo. Puedo dar algunos consejos, pero no puedo responder completamente a todas las preguntas en esta área.
¿Cuándo necesitaré más de 11 GB de almacenamiento?
Ya mencioné que cuando trabaje con transformadores, necesitará al menos 11 GB, y cuando investigue en esta área, al menos 24 GB. La mayoría de los modelos previamente entrenados tienen requisitos de memoria muy altos y han sido entrenados en una GPU RTX 2080 Ti o superior con al menos 11 GB de memoria. Por lo tanto, si tiene menos de 11 GB de memoria, el lanzamiento de algunos modelos puede resultar difícil o incluso imposible.
Otras áreas que requieren una gran cantidad de memoria son las imágenes médicas, los modelos avanzados de visión por computadora y todos con imágenes grandes.
En general, si está buscando desarrollar modelos que puedan superar a la competencia, ya sea en investigación, aplicaciones industriales o competencia de Kaggle, la memoria adicional puede brindarle una ventaja competitiva.
¿Cuándo puede arreglárselas con menos de 11 GB de memoria?
Las tarjetas RTX 3070 y RTX 3080 son potentes, pero carecen de memoria. Sin embargo, para muchas tareas esa cantidad de memoria puede no ser necesaria.
El RTX 3070 es ideal para el entrenamiento GO. Las habilidades básicas de redes para la mayoría de las arquitecturas se pueden adquirir reduciendo las redes o utilizando imágenes más pequeñas. Si tuviera que aprender GO, elegiría el RTX 3070, o incluso algunos si pudiera pagarlos.
La RTX 3080 es la tarjeta más rentable en la actualidad y, por lo tanto, es ideal para la creación de prototipos. La creación de prototipos requiere una gran cantidad de memoria y la memoria es económica. Por creación de prototipos, me refiero a la creación de prototipos en cualquier área: investigación, concursos de Kaggle, probar ideas para una startup, experimentar con código de investigación. Para todas estas aplicaciones, el RTX 3080 es el más adecuado.
Si, por ejemplo, estuviera dirigiendo un laboratorio de investigación o una startup, gastaría entre el 66% y el 80% del presupuesto total en máquinas RTX 3080 y entre el 20% y el 33% en máquinas RTX 3090 con refrigeración por agua fiable. RTX 3080 es más rentable y se puede acceder a través de Slurm... Dado que la creación de prototipos debe realizarse en modo ágil, debe realizarse con modelos y conjuntos de datos más pequeños. Y el RTX 3080 es perfecto para eso. Una vez que los estudiantes / colegas hayan construido un gran modelo de prototipo, pueden implementarlo en el RTX 3090, escalando a modelos más grandes.
Recomendaciones generales
En general, los modelos de la serie RTX 30 son muy potentes y definitivamente los recomiendo. Considere los requisitos de memoria como se indicó anteriormente, así como los requisitos de alimentación y refrigeración. Si tiene una ranura libre entre las GPU, no habrá problemas con la refrigeración. De lo contrario, proporcione las tarjetas RTX 30 con refrigeración por agua, expansores PCIe o tarjetas eficientes con ventiladores.
En general, recomendaría el RTX 3090 a cualquiera que pueda pagarlo. No solo le conviene ahora, sino que seguirá siendo muy eficaz durante los próximos 3-7 años. Es poco probable que en los próximos tres años la memoria HBM sea mucho más barata, por lo que la próxima GPU será solo un 25% mejor que la RTX 3090. En 5-7 años, probablemente veremos una memoria HBM barata, después de lo cual definitivamente necesitará actualizar la flota. ...
Si está construyendo un sistema a partir de varios RTX 3090, bríndeles suficiente refrigeración y energía.
A menos que tenga requisitos estrictos para obtener una ventaja competitiva, recomendaría el RTX 3080. Esta es una solución más rentable y proporcionará capacitación rápida para la mayoría de las redes. Si hace los trucos de memoria que desea y no le importa escribir código adicional, hay muchos trucos para meter una red de 24 GB en una GPU de 10 GB.
La RTX 3070 también es una gran tarjeta para entrenamiento y creación de prototipos GO, y es $ 200 más barata que la RTX 3080. Si no puede pagar la RTX 3080, entonces la RTX 3070 es su elección.
Si su presupuesto es ajustado y el RTX 3070 es demasiado caro para usted, puede encontrar un RTX 2070 usado en eBay por aproximadamente $ 260. Aún no está claro si saldrá el RTX 3060, pero si su presupuesto es ajustado, podría valer la pena esperar. Si su precio coincide con el de RTX 2060 y GTX 1060, entonces debería rondar los $ 250- $ 300, y debería funcionar bien.
Recomendaciones para clústeres de GPU
El diseño del clúster de GPU depende en gran medida de su uso. Para un sistema con 1024 GPU o más, lo principal será la presencia de una red, pero si no usa más de 32 GPU a la vez, entonces no tiene sentido invertir en construir una red poderosa.
En general, las tarjetas RTX bajo el acuerdo CUDA no se pueden usar en centros de datos. Sin embargo, las universidades a menudo pueden ser la excepción a esta regla. Si desea obtener dicho permiso, vale la pena comunicarse con un representante de NVIDIA. Si puede usar tarjetas RTX, entonces recomendaría el sistema estándar de 8 GPU RTX 3080 o RTX 3090 de Supermicro (si puede mantenerlos frescos). Un pequeño conjunto de 8 nodos A10000 garantiza un uso eficiente de los modelos después de la creación de prototipos, especialmente si no es posible enfriar servidores con 8 RTX 3090. En este caso, recomendaría el A10000 sobre el RTX 6000 / RTX 8000 ya que los A10000 son bastante rentables y no envejecerán rápidamente.
Si necesita entrenar redes muy grandes en un clúster de GPU (256 GPU o más), recomendaría el sistema NVIDIA DGX SuperPOD con A10000. a partir de 256 GPU, la red se vuelve esencial. Si desea expandirse más allá de las 256 GPU, necesitará un sistema altamente optimizado para el que las soluciones estándar ya no funcionarán.
Especialmente a escalas de 1.024 GPU y más, las únicas soluciones competitivas en el mercado siguen siendo Google TPU Pod y NVIDIA DGX SuperPod. A esta escala, preferiría Google TPU Pod, ya que su infraestructura de red dedicada se ve mejor que la NVIDIA DGX SuperPod, aunque en principio, los dos sistemas están bastante cerca. En aplicaciones y hardware, el sistema GPU es más flexible que el TPU, mientras que los sistemas TPU admiten modelos más grandes y escalan mejor. Por tanto, ambos sistemas tienen sus propias ventajas y desventajas.
¿Qué GPU es mejor no comprar?
No recomiendo comprar múltiples RTX Founders Editions o RTX Titans a la vez, a menos que tenga expansores PCIe para resolver sus problemas de enfriamiento. Simplemente se calentarán y su velocidad caerá drásticamente en comparación con lo que se indica en los gráficos. Las cuatro Ediciones Founders de RTX 2080 Ti se calentarán rápidamente hasta 90 ° C, bajarán la velocidad del reloj y funcionarán más lentamente que una RTX 2070 normalmente enfriada.
Recomiendo comprar un Tesla V100 o A100 solo en casos extremos, ya que está prohibido su uso en los centros de datos de las empresas. O cómprelos si necesita entrenar redes muy grandes en grandes grupos de GPU; su relación precio / rendimiento no es ideal.
Si puede pagar algo mejor, no elija tarjetas de la serie GTX 16. No tienen núcleos tensores, por lo que su rendimiento en GO es pobre. En su lugar, tomaría un RTX 2070 / RTX 2060 / RTX 2060 Super usado. Se pueden pedir prestados si su presupuesto es muy limitado.
¿Cuándo es mejor no comprar nuevas GPU?
Si ya posee un RTX 2080 Ti o mejor, actualizar a un RTX 3090 es casi inútil. Sus GPU ya son buenas y los beneficios de velocidad serán insignificantes en comparación con los problemas de energía y enfriamiento adquiridos; no vale la pena.
La única razón por la que quisiera actualizar de cuatro RTX 2080 Ti a cuatro RTX 3090 es si estuviera investigando en transformadores muy grandes u otras redes que dependen en gran medida de la potencia informática. Sin embargo, si tiene problemas de memoria, primero debe considerar varios trucos para colocar modelos grandes en la memoria existente.
Si posee uno o más RTX 2070, lo pensaría dos veces si fuera usted antes de actualizar. Estas son GPU bastante buenas. Podría tener sentido venderlos en eBay y comprar un RTX 3090 si 8GB no son suficientes para usted, como es el caso de muchas otras GPU. Si no hay suficiente memoria, se está gestando una actualización.
Respuestas a preguntas y conceptos erróneos.
Resumen:
- Los carriles PCIe y PCIe 4.0 son irrelevantes para los sistemas de doble GPU. Para sistemas con 4 GPU, prácticamente no es así.
- Enfriar el RTX 3090 y RTX 3080 será difícil. Utilice enfriadores de agua o expansores PCIe.
- NVLink solo es necesario para clústeres de GPU.
- Se pueden usar diferentes GPU en la misma computadora (por ejemplo, GTX 1080 + RTX 2080 + RTX 3090), pero la paralelización eficiente no funcionará.
- Para ejecutar más de dos máquinas en paralelo, necesita Infiniband y una red de 50 Gbps.
- Los procesadores AMD son más baratos que los procesadores Intel, y estos últimos casi no tienen ventajas.
- A pesar de los heroicos esfuerzos de los ingenieros, AMD GPU + ROCm difícilmente podrá competir con NVIDIA debido a la falta de comunidad y núcleos tensoriales equivalentes en los próximos 1-2 años.
- Las GPU en la nube son beneficiosas si se usan durante menos de un año. Después de eso, la versión de escritorio se vuelve más barata.
¿Necesito PCIe 4.0?
Usualmente no. PCIe 4.0 es ideal para un clúster de GPU. Útil si tienes una máquina con 8 GPU. En otros casos, casi no tiene ventajas. Mejora la paralelización y transfiere datos un poco más rápido. Pero la transferencia de datos no es un cuello de botella. En la visión por computadora, el cuello de botella puede ser el almacenamiento de datos, pero no la transferencia de datos PCIe de GPU a GPU. Por tanto, no hay ninguna razón para que la mayoría de la gente utilice PCIe 4.0. Posiblemente mejorará la paralelización de cuatro GPU en un 1-7%.
¿Necesito carriles PCIe 8x / 16x?
Al igual que con PCIe 4.0, generalmente no. Los carriles PCIe son necesarios para la paralelización y la transferencia rápida de datos, lo que casi nunca es un cuello de botella. Si tiene 2 GPU, 4 líneas son suficientes para ellos. Para 4 GPU, preferiría 8 líneas por GPU, pero si hay 4 líneas, el rendimiento solo disminuirá en un 5-10%.
¿Cómo meter cuatro RTX 3090 cuando cada uno ocupa 3 ranuras PCIe?
Puede comprar una de las dos opciones para una ranura o distribuirlas mediante expansores PCIe. Además del espacio, debe pensar inmediatamente en la refrigeración y una fuente de alimentación adecuada. Aparentemente, la solución más fácil sería comprar 4 x RTX 3090 EVGA Hydro Cobres con un circuito de enfriamiento de agua dedicado. EVGA ha estado fabricando versiones de tarjetas de cobre refrigeradas por agua durante muchos años, y puede confiar en la calidad de sus GPU. Quizás haya opciones más económicas.
Los expansores PCIe pueden resolver problemas de espacio y refrigeración, pero su carcasa debe tener suficiente espacio para todas las tarjetas. ¡Y asegúrese de que los extensores sean lo suficientemente largos!
¿Cómo enfriar 4 RTX 3090 o 4 RTX 3080?
Consulte la sección anterior.
¿Puedo usar varios tipos de GPU diferentes?
Sí, pero no podrá paralelizar eficazmente el trabajo. Me imagino un sistema que ejecute 3 RTX 3070 + 1 RTX 3090. Por otro lado, la paralelización entre cuatro RTX 3070 funcionará muy rápidamente si coloca su modelo en ellos. Y una razón más por la que puede necesitarlo es el uso de GPU antiguas. Funcionará, pero la paralelización será ineficaz, ya que las GPU más rápidas esperarán las GPU más lentas en los puntos de sincronización (generalmente en una actualización de gradiente).
¿Qué es NVLink y lo necesito?
Por lo general, no necesita NVLink. Es una comunicación de alta velocidad entre múltiples GPU. Es necesario si tiene un clúster de 128 o más GPU. En otros casos, casi no tiene ventajas sobre la transferencia de datos PCIe estándar.
No tengo dinero ni siquiera para tus recomendaciones más baratas. ¿Qué hacer?
Definitivamente comprando una GPU usada. RTX 2070 ($ 400) y RTX 2060 ($ 300) usados funcionarán bien. Si no puede pagarlos, la siguiente mejor opción sería una GTX 1070 usada ($ 220) o una GTX 1070 Ti ($ 230). Si eso es demasiado caro, busque una GTX 980 Ti usada (6GB $ 150) o GTX 1650 Super ($ 190). Si eso también es caro, es mejor que utilice los servicios en la nube. Por lo general, proporcionan a las GPU un límite de tiempo o de energía, después del cual debe pagar. Cambie los servicios hasta que pueda pagar su propia GPU.
¿Qué se necesita para paralelizar un proyecto entre dos máquinas?
Para acelerar el trabajo mediante la paralelización entre dos máquinas, necesita tarjetas de red de 50 Gbps o más. Recomiendo instalar al menos EDR Infiniband, es decir, una tarjeta de red con una velocidad de al menos 50 Gbps. Dos tarjetas EDR con cable en eBay te costarán $ 500.
En algunos casos, puede funcionar con Ethernet de 10 Gbps, pero esto generalmente solo funciona para ciertos tipos de redes neuronales (ciertas redes convolucionales) o para ciertos algoritmos (Microsoft DeepSpeed).
¿Los algoritmos de multiplicación de matrices dispersas son adecuados para cualquier matriz dispersa?
Aparentemente no. Dado que se requiere que una matriz tenga 2 ceros por cada 4 elementos, las matrices dispersas deben estar bien estructuradas. Probablemente sea posible modificar ligeramente el algoritmo procesando 4 valores como una representación comprimida de dos valores, pero esto significará que la multiplicación exacta de matrices dispersas por Ampere no estará disponible.
¿Necesito un procesador Intel para ejecutar varias GPU?
No recomiendo usar un procesador Intel, a menos que esté sobrecargando el procesador en los concursos de Kaggle (donde el procesador está cargado con cálculos de álgebra lineal). E incluso para tales competencias, los procesadores AMD son excelentes. Los procesadores AMD son en promedio más baratos y mejores para GO. Para una compilación de 4 GPU, Threadripper es mi elección definitiva. En nuestra universidad, hemos recopilado decenas de sistemas basados en este tipo de procesadores, y todos funcionan perfectamente, sin quejas. Para sistemas con 8 GPU, tomaría el procesador con el que su fabricante tenga experiencia. La confiabilidad del procesador y PCIe en sistemas de 8 tarjetas es más importante que la velocidad o la rentabilidad.
¿Es importante la forma de la carcasa para el enfriamiento?
No. Por lo general, las GPU se enfrían perfectamente si hay incluso pequeños espacios entre las GPU. Diferentes carcasas pueden darle una diferencia de 1-3 ° C, y diferentes espacios entre tarjetas pueden brindarle una diferencia de 10-30 ° C. En general, si hay espacios entre sus tarjetas, no hay problema con la refrigeración. Si no hay espacios, necesita los ventiladores adecuados (ventilador de soplado) u otra solución (refrigeración por agua, expansores PCIe). En cualquier caso, el tipo de carcasa y sus ventiladores no importan.
¿AMD GPU + ROCm captará alguna vez NVIDIA GPU + CUDA?
No en los próximos años. Hay tres problemas: núcleos tensoriales, software y comunidad.
Los cristales de la GPU de AMD son buenos: excelente rendimiento en FP16, excelente ancho de banda de memoria. Pero la ausencia de núcleos tensores o su equivalente lleva a que su rendimiento se resienta en comparación con la GPU de NVIDIA. Y sin la implementación de núcleos tensoriales en el hardware, las GPU de AMD nunca serán competitivas. Según los rumores, para 2020 está prevista alguna clase de tarjeta para centros de datos con un análogo de núcleos tensores, pero aún no hay datos exactos. Si solo tienen una tarjeta con el equivalente a Tensor Cores para servidores, eso significaría que pocas personas pueden pagar las GPU de AMD, lo que le da a NVIDIA una ventaja competitiva.
Digamos que AMD introducirá hardware con algo así como núcleos tensores en el futuro. Entonces muchos dirán: “¡Pero no hay programas que funcionen con las GPU de AMD! ¿Cómo puedo usarlos? " Esto es principalmente un concepto erróneo. El software AMD que ejecuta ROCm ya está bien desarrollado y el soporte en PyTorch está bien organizado. Y aunque no he visto muchos informes sobre el trabajo de AMD GPU + PyTorch, todas las funciones del software están integradas allí. Aparentemente, puede elegir cualquier red y ejecutarla en una GPU AMD. Por lo tanto, AMD ya está bien desarrollado en esta área, y este problema está prácticamente resuelto.
Sin embargo, habiendo resuelto los problemas con el software y la falta de núcleos tensoriales, AMD se enfrenta a uno más: la falta de comunidad. Cuando se encuentra con un problema con las GPU de NVIDIA, puede buscar en Google una solución y encontrarla. Esto genera confianza en las GPU de NVIDIA. Está surgiendo una infraestructura para facilitar el uso de las GPU de NVIDIA (cualquier plataforma para GO funciona, cualquier tarea científica es compatible). Hay un montón de trucos y trucos que facilitan mucho el uso de las GPU NVIDIA (por ejemplo, apex). Se pueden encontrar programadores y expertos en GPU de NVIDIA debajo de cada arbusto, pero conozco muchos menos expertos en GPU de AMD.
En términos de la comunidad, la situación de AMD es similar a la de Julia vs Python. Julia tiene mucho potencial y muchos señalarán con razón que este lenguaje de programación es más adecuado para el trabajo científico. Sin embargo, Julia rara vez se usa en comparación con Python. Es solo que la comunidad de Python es muy grande. Hay toneladas de personas reunidas alrededor de paquetes poderosos como Numpy, SciPy y Pandas. Esta situación es similar a la de NVIDIA vs AMD.
Por lo tanto, es muy probable que AMD no se ponga al día con NVIDIA hasta que presente el equivalente a los núcleos tensoriales y una comunidad sólida construida alrededor de ROCm. AMD siempre tendrá su participación de mercado en subgrupos específicos (minería de criptomonedas, centros de datos). Pero NVIDIA probablemente mantendrá el monopolio durante otros dos años.
¿Cuándo es mejor utilizar los servicios en la nube y cuándo es una computadora con GPU dedicada?
Una simple regla general: si espera hacer GO durante más de un año, es más barato comprar una computadora con una GPU. De lo contrario, es mejor utilizar servicios en la nube, a menos que tenga una amplia experiencia en programación en la nube y desee aprovechar la posibilidad de escalar la cantidad de GPU a voluntad.
El punto de inflexión exacto en el que las GPU en la nube se vuelven más caras que su propia computadora depende en gran medida de los servicios utilizados. Es mejor calcularlo usted mismo. A continuación se muestra un cálculo de ejemplo para un servidor AWS V100 con un V100 y se compara con el costo de una computadora de escritorio con un RTX 3090, que tiene un rendimiento similar. Una PC RTX 3090 cuesta $ 2200 (2-GPU barebone + RTX 3090). Si está en los EE. UU., Agregue $ 0.12 por kWh de electricidad. Compare eso con $ 2.14 por hora por servidor en AWS.
Con un 15% de reciclaje por año, la computadora usa
(350 W (GPU) + 100 W (CPU)) * 0.15 (reciclaje) * 24 horas * 365 días = 591 kWh por año.
591 kWh por año dan $ 71 adicionales.
El punto de inflexión, cuando la computadora y la nube se comparan en precio al 15% de utilización, llega alrededor del día 300 ($ 2,311 vs $ 2,270):
$ 2,14 / h * 0,15 (reciclaje) * 24 horas * 300 días = $ 2,311
Si calcula, que sus modelos GO durarán más de 300 días, es mejor comprar una computadora que usar AWS.
Se pueden realizar cálculos similares para que cualquier servicio en la nube decida si usar su computadora o la nube.
Las cifras comunes para la utilización de la potencia informática son las siguientes:
- Computadora de doctorado: <15%;
- Clúster de GPU en PhD Slurm:> 35%
- Grupo de investigación corporativa en Slurm:> 60%.
En general, las tasas de reciclaje son más bajas en áreas donde pensar en ideas innovadoras es más importante que desarrollar soluciones prácticas. En algunas áreas, la tasa de utilización es menor (estudios de interpretabilidad), mientras que en otras es mucho mayor (traducción automática, modelado de idiomas). En general, el reciclaje de coches personales suele estar siempre sobrevalorado. Normalmente, la mayoría de los sistemas personales se reciclan entre un 5% y un 10%. Por lo tanto, recomiendo encarecidamente que los equipos de investigación y las empresas organicen clústeres de GPU en Slurm en lugar de escritorios separados.
Consejos para los que son demasiado perezosos para leer
Mejores GPU en general : RTX 3080 y RTX 3090.
GPU para evitar (como investigador) : tarjetas Tesla, Quadro, Founders Edition, Titan RTX, Titan V, Titan XP.
Buena relación rendimiento / precio, pero caro : RTX 3080.
Buena relación rendimiento / precio, más económico : RTX 3070, RTX 2060 Super.
Tengo poco dinero : compro tarjetas usadas. Jerarquía: RTX 2070 ($ 400), RTX 2060 ($ 300), GTX 1070 ($ 220), GTX 1070 Ti ($ 230), GTX 1650 Super ($ 190), GTX 980 Ti (6GB $ 150).
Casi no tengo dinero : muchas startups anuncian sus servicios en la nube. Use créditos gratis en las nubes, cámbielos en círculo hasta que pueda comprar una GPU.
Yo compito en competiciones de Kaggle: RTX 3070.
Estoy intentando ganar el concurso en visión artificial, preentrenamiento o traducción automática : 4 piezas RTX 3090. Pero espere hasta que los expertos confirmen que hay conjuntos con buena refrigeración y suficiente potencia.
Estoy aprendiendo el procesamiento del lenguaje natural : si no te gusta la traducción automática, el modelado de idiomas o el preaprendizaje, el RTX 3080 servirá.
Empecé a hacer GO y me metí realmente en ello : empieza con RTX 3070. Si no te aburres en 6-9 meses, vende y compra cuatro RTX 3080. Dependiendo de lo que elijas a continuación (startup, Kaggle, investigación, GO aplicado), años en tres, venda sus GPU y compre algo mejor (GPU RTX de próxima generación).
Quiero probar GO, pero no tengo intenciones serias : RTX 2060 Super será una excelente opción, sin embargo, puede requerir el reemplazo de la fuente de alimentación. Si tiene una ranura PCIe x16 en su placa base y la fuente de alimentación produce unos 300 vatios, entonces la GTX 1050 Ti será una excelente opción, ya que no requiere otras inversiones.
Clúster de GPU para simulación en paralelo con menos de 128 GPU : si se le permite comprar RTX para el clúster: 66% 8x RTX 3080 y 33% 8x RTX 3090 (solo si puede enfriar bien el ensamblaje). Si el enfriamiento no es suficiente, compre una GPU RTX 6000 al 33% u 8x Tesla A100. Si no puede comprar una GPU RTX, optaría por 8 nodos Supermicro A100 o 8 nodos RTX 6000.
Clúster de GPU para simulación en paralelo con más de 128 GPU: Piense en coches con 8 Tesla A100. Si necesita más de 512 GPU, considere el sistema DGX A100 SuperPOD.