
Hablemos de una red neuronal que utiliza el aprendizaje profundo y el aprendizaje por refuerzo para jugar a Snake. Encontrará el código en Github, análisis de errores, demostraciones de IA y experimentos en él debajo del corte.
Desde que vi el documental de Netflix sobre AlphaGo, me ha fascinado el aprendizaje por refuerzo. Tal aprendizaje es comparable al aprendizaje humano: ves algo, haces algo y tus acciones tienen consecuencias. Bueno o malo. Aprendes de las consecuencias y acciones correctas. El aprendizaje por refuerzo tiene muchas aplicaciones: conducción autónoma, robótica, comercio, juegos. Si está familiarizado con el aprendizaje por refuerzo, omita las dos secciones siguientes.
Aprendizaje reforzado
El principio es simple. El agente aprende mediante la interacción con el entorno. Elige una acción y recibe una respuesta del entorno en forma de estados (u observaciones) y recompensas. Este ciclo continúa de forma continua o hasta que se interrumpe. Entonces comienza un nuevo episodio. Esquemáticamente se ve así:

El objetivo del agente es obtener la mayor cantidad de recompensas por episodio. Al comienzo del entrenamiento, el agente examina el entorno: intenta diferentes acciones en el mismo estado. A medida que avanza el aprendizaje, el agente investiga cada vez menos. En cambio, elige la acción más gratificante basándose en su propia experiencia.
Aprendizaje por refuerzo profundo
El aprendizaje profundo utiliza redes neuronales para generar resultados a partir de entradas. Con solo una capa oculta, el aprendizaje profundo puede ampliar cualquier función. ¿Cómo funciona? Una red neuronal son capas con nodos. La primera capa es la capa de datos de entrada. La segunda capa oculta transforma los datos utilizando pesos y una función de activación. La última capa es la capa de pronóstico.

Como su nombre indica, el aprendizaje por refuerzo profundo es una combinación de aprendizaje profundo y aprendizaje por refuerzo. El agente aprende a predecir la mejor acción para un estado dado utilizando estados como entradas, valores para acciones como salidas y recompensas para ajustar los pesos en la dirección correcta. Escribamos una serpiente usando el aprendizaje por refuerzo profundo.

Definición de acciones, recompensas y condiciones
Para preparar el juego para el agente, formalizamos el problema. Definir acciones es fácil. El agente puede elegir la dirección: arriba, derecha, abajo o izquierda. Las recompensas y el estado del espacio son un poco más complejos. Hay muchas soluciones y una funcionará mejor y la otra peor. Describiré uno de ellos a continuación y probémoslo.
Si Snake recoge una manzana, su recompensa es de 10 puntos. Si la serpiente muere, reste 100 puntos del premio. Para ayudar al agente, agregue 1 punto cuando la Serpiente se acerque a la manzana y reste un punto cuando la Serpiente se aleje de la manzana.
El estado tiene muchas opciones. Puedes tomar las coordenadas de la Serpiente y la manzana o la dirección a la manzana. Es importante agregar la ubicación de los obstáculos, es decir, las paredes y el cuerpo de la Serpiente, para que el agente aprenda a sobrevivir. A continuación se muestra un resumen de acciones, condiciones y recompensas. Más adelante veremos cómo los ajustes de estado afectan el desempeño.

Crear entorno y agente
Al agregar métodos al programa Snake, creamos un entorno de aprendizaje reforzado. Los métodos son como sigue:
reset(self), step(self, action)y get_state(self). Además, es necesario calcular la recompensa en cada paso del agente. Échale un vistazo run_game(self).
El agente trabaja con la red Deep Q para encontrar la mejor acción. Parámetros del modelo a continuación:
# epsilon sets the level of exploration and decreases over time
params['epsilon'] = 1
params['gamma'] = .95
params['batch_size'] = 500
params['epsilon_min'] = .01
params['epsilon_decay'] = .995
params['learning_rate'] = 0.00025
params['layer_sizes'] = [128, 128, 128]
Si está interesado en ver el código, puede encontrarlo en GitHub .
Agente juega serpiente
Y ahora, ¡la pregunta clave! ¿Aprenderá el agente a jugar? Veamos cómo interactúa con el medio ambiente. A continuación se muestran los primeros juegos. El agente no entiende nada:

¡La primera manzana! Pero todavía parece que la red neuronal no sabe lo que está haciendo.

Encuentra la primera manzana ... y luego choca contra la pared. El comienzo del decimocuarto juego:

El agente aprende: su camino hacia la manzana no es el más corto, pero encuentra la manzana. A continuación se muestra el trigésimo juego:

Después de solo 30 juegos, Snake evita colisiones consigo mismo y encuentra un camino rápido hacia la manzana.
Juguemos con el espacio
Puede ser posible cambiar el espacio de estado y lograr un rendimiento similar o mejor. A continuación se muestran las posibles opciones.
- Sin direcciones: No le diga al agente las direcciones en las que se mueve la Serpiente.
- Estado con coordenadas: reemplace la posición de la manzana (arriba, derecha, abajo y / o izquierda) con las coordenadas de la manzana (x, y) y la serpiente (x, y). Los valores de coordenadas están en una escala de 0 a 1.
- Dirección 0 o 1 estado.
- Estado de solo muro: informa solo si hay un muro. Pero no se trata de dónde está el cuerpo: abajo, arriba, derecha o izquierda.

A continuación se muestran gráficos de rendimiento para diferentes estados:
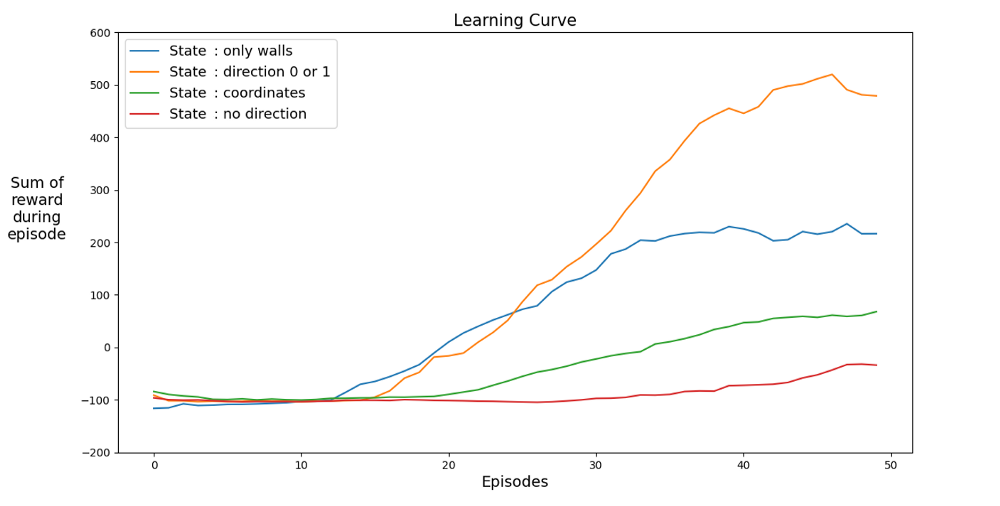
Busquemos un espacio que acelere el aprendizaje. El gráfico muestra los logros promedio de los últimos 12 juegos con diferentes estados.
Está claro que cuando el espacio de estados tiene direcciones, el agente aprende rápidamente, logrando los mejores resultados. Pero el espacio con coordenadas es mejor. Tal vez pueda lograr mejores resultados entrenando la red durante más tiempo. La razón del aprendizaje lento puede ser el número de estados posibles: 20⁴ * 2⁴ * 4 = 1,024,000. Recorrido de 20 x 20, 64 opciones de obstáculos y 4 opciones de rumbo actual. Para el espacio de la variante original, 3² * 2⁴ * 4 = 576. Esto es más de 1700 veces menos que 1.024.000 y, por supuesto, afecta el aprendizaje.
Juguemos con premios
¿Existe una mejor lógica de recompensa interna? Permítanme recordarles que la Serpiente se otorga así:

Primer error. Caminar en círculos
¿Qué pasa si cambia -1 a +1? Esto puede ralentizar la curva de aprendizaje, pero al final la Serpiente no muere. Y esto es muy importante para el juego. El agente aprende rápidamente a evitar la muerte.

En un intervalo de tiempo, el agente recibe un punto de supervivencia.
Segundo error. Golpear la pared
Cambiemos el número de puntos para pasar la manzana a -1. Establezcamos la recompensa por la propia manzana en 100 puntos. ¿Lo que sucederá? El agente recibe una penalización por cada movimiento, por lo que se mueve hacia la manzana lo más rápido posible. Puede suceder, pero hay otra opción.

La IA camina a lo largo de la pared más cercana para minimizar las pérdidas.
Experiencia
Solo necesitas 30 juegos. El secreto de la inteligencia artificial es la experiencia de juegos anteriores, que se tiene en cuenta para que la red neuronal aprenda más rápido. En cada paso regular, se realizan una serie de pasos de repetición (parámetro
batch_size). Esto funciona muy bien porque, para un par de acción y estado determinados, hay poca diferencia entre la recompensa y el siguiente estado.
Error número 3. Sin experiencia ¿Es la experiencia
realmente tan importante? Vamos a sacarlo. Y llévate la recompensa de 100 puntos por la manzana. A continuación se muestra un agente sin experiencia que ha jugado 2500 juegos.

Aunque el agente jugó 2500 (!) Juegos, no juega a la serpiente. El juego termina rápidamente. De lo contrario, 10,000 juegos habrían tomado días. Después de 3000 juegos solo tenemos 3 manzanas. Después de 10,000 juegos, las manzanas siguen siendo 3. ¿Es suerte o un resultado del aprendizaje?
De hecho, la experiencia ayuda mucho. Al menos una experiencia que tenga en cuenta recompensas y tipo de espacio. ¿Cuántas repeticiones necesitas por paso? La respuesta puede resultar sorprendente. Para responder a esta pregunta, juguemos con el parámetro batch_size. En el experimento original se estableció en 500. Resumen de resultados con diferentes experiencias:

200 juegos con diferente experiencia: 1 juego (sin experiencia), 2 y 4. Promedio de 20 juegos.
Incluso con experiencia en 2 juegos, el agente ya está aprendiendo a jugar. En el gráfico puede ver el impacto
batch_size, se logra el mismo rendimiento para 100 juegos si se usa 4 en lugar de 2. La solución en el artículo da el resultado. El agente aprende a jugar Snake y logra buenos resultados, recolectando de 40 a 60 manzanas en 50 juegos.
Un lector atento puede decir: el número máximo de manzanas en una serpiente es 399. ¿Por qué no gana la IA? La diferencia entre 60 y 399 es, de hecho, pequeña. Y esto es cierto. Y aquí hay un problema: la serpiente no evita las colisiones cuando retrocede.
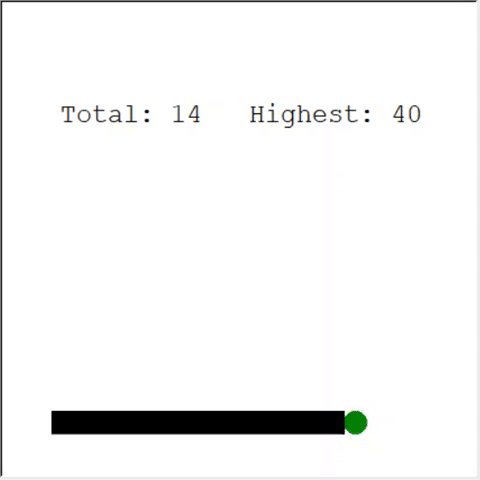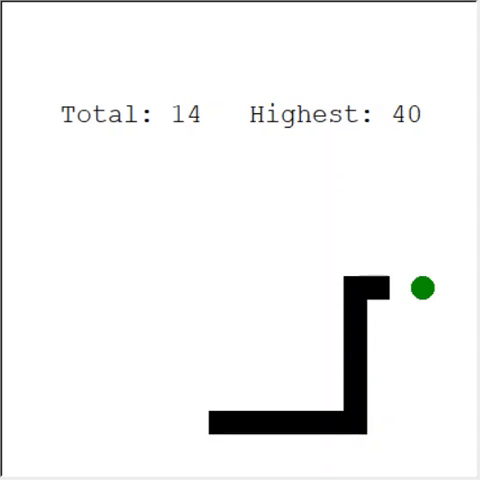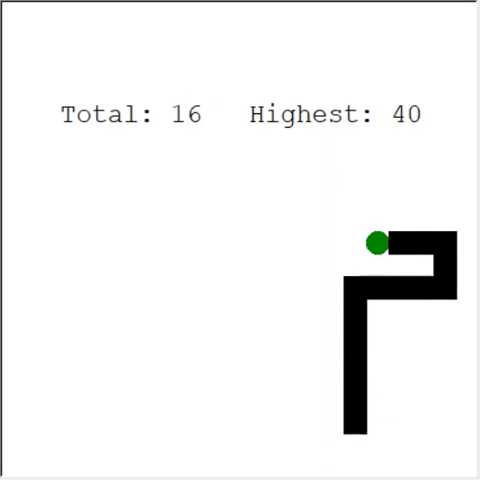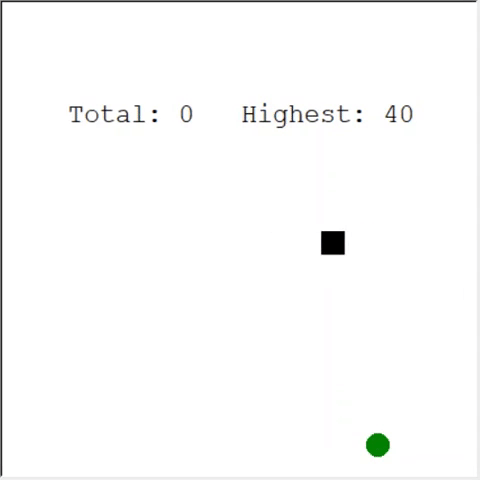
Una forma interesante de resolver el problema es utilizar CNN para el campo de juego. De esta manera, la IA puede ver todo el juego, no solo los obstáculos cercanos. Podrá reconocer los lugares que deben recorrer para ganar.
Bibliografía
[1] K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators (1989), Neural networks 2.5: 359–366
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
, Level Up , - SkillFactory:
- Machine Learning (12 )
- « Machine Learning Data Science» (20 )
- «Machine Learning Pro + Deep Learning» (20 )
- Data Science (12 )
E
- - (8 )
- - Data Analytics (5 )
- (6 )
- (18 )
- «Python -» (9 )
- DevOps (12 )
- Java- (18 )
- JavaScript (12 )
- UX- (9 )
- Web- (7 )
