
WebAssembly (abreviado WASM) es una tecnología para ejecutar código binario precompilado en un navegador en el lado del cliente. Se introdujo por primera vez en 2015 y actualmente es compatible con la mayoría de los navegadores modernos.
Un caso de uso común es el preprocesamiento de datos del lado del cliente antes de enviar archivos al servidor. En este artículo, entenderemos cómo se hace esto.
Antes del comienzo
La arquitectura de WebAssembly y los pasos generales se describen con más detalle aquí y aquí . Repasaremos solo los hechos básicos.
Trabajar con WebAssembly comienza con el ensamblaje previo de los artefactos necesarios para ejecutar el código compilado en el lado del cliente. Hay dos de ellos: el archivo binario WASM en sí mismo y una capa de JavaScript a través de la cual puede llamar a los métodos exportados.
Un ejemplo del código C ++ más simple para compilación
#include <algorithm>
extern "C" {
int calculate_gcd(int a, int b) {
while (a != 0 && b != 0) {
a %= b;
std::swap(a, b);
}
return a + b;
}
}Para el ensamblaje se utiliza Emscripten que, además de la interfaz principal de dichos compiladores, contiene indicadores adicionales a través de los cuales se establecen la configuración de la máquina virtual y los métodos exportados. El lanzamiento más simple se ve así:
em++ main.cpp --std=c++17 -o gcd.html \
-s EXPORTED_FUNCTIONS='["_calculate_gcd"]' \
-s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]'Al especificar un archivo * .html como un objeto , le dice al compilador que cree un marcado html simple con una consola js también. Ahora, si iniciamos el servidor en los archivos recibidos, veremos esta consola con la capacidad de lanzar _calculate_gcd:
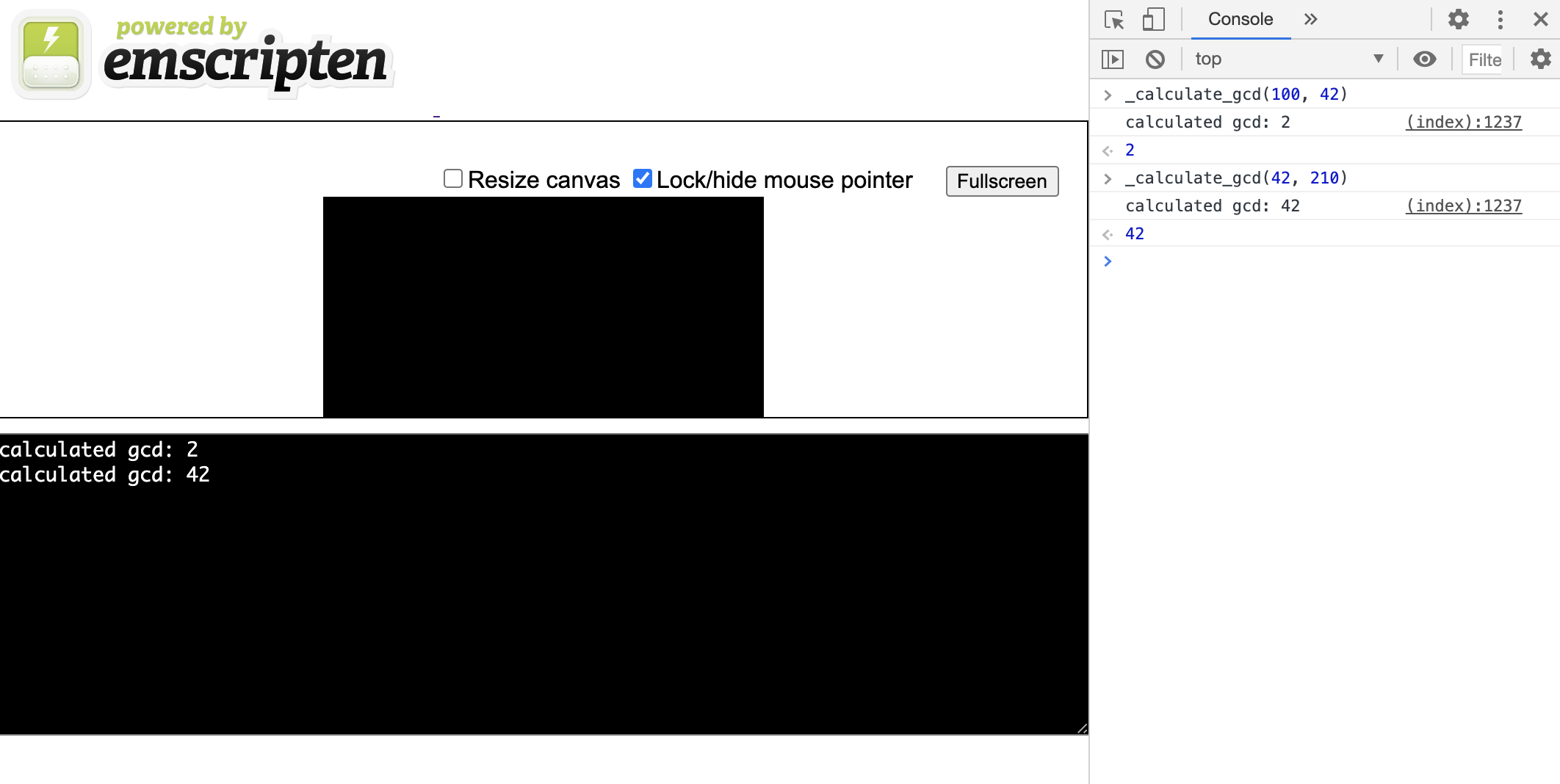
Procesamiento de datos
Analicémoslo usando un ejemplo simple de compresión lz4 usando una biblioteca escrita en C ++. Tenga en cuenta que los numerosos idiomas admitidos no terminan ahí.
A pesar de la simplicidad y algunos aspectos sintéticos del ejemplo, esta es una ilustración bastante útil de cómo trabajar con datos. Del mismo modo, puede realizar cualquier acción sobre ellos para la que el poder del cliente sea suficiente: preprocesamiento de imágenes antes de enviarlas al servidor, compresión de audio, conteo de varias estadísticas y mucho más.
El código completo se puede encontrar aquí.
Parte de C ++
Usamos una implementación lista para usar de lz4 . Entonces el archivo principal se verá muy lacónico:
#include "lz4.h"
extern "C" {
uint32_t compress_data(uint32_t* data, uint32_t data_size, uint32_t* result) {
uint32_t result_size = LZ4_compress(
(const char *)(data), (char*)(result), data_size);
return result_size;
}
uint32_t decompress_data(uint32_t* data, uint32_t data_size, uint32_t* result, uint32_t max_output_size) {
uint32_t result_size = LZ4_uncompress_unknownOutputSize(
(const char *)(data), (char*)(result), data_size, max_output_size);
return result_size;
}
}Como puede ver, simplemente declara funciones externas (usando la palabra clave extern ) que llaman internamente a los métodos correspondientes de la biblioteca con lz4.
En términos generales, en nuestro caso, el archivo es inútil: se puede usar de inmediato la interfaz nativa de lz4.h . Sin embargo, en proyectos más complejos (por ejemplo, combinar la funcionalidad de diferentes bibliotecas), es conveniente tener un punto de entrada común que enumere todas las funciones utilizadas.
A continuación, compilamos el código utilizando el compilador Emscripten ya mencionado :
em++ main.cpp lz4.c -o wasm_compressor.js \
-s EXPORTED_FUNCTIONS='["_compress_data","_decompress_data"]' \
-s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]' \
-s WASM=1 -s ALLOW_MEMORY_GROWTH=1El tamaño de los artefactos recibidos es alarmante:
$ du -hs wasm_compressor.*
112K wasm_compressor.js
108K wasm_compressor.wasm
Si abre la capa de archivo JS, puede ver algo como lo siguiente:

Contiene muchas cosas innecesarias: desde comentarios hasta funciones de servicio, la mayoría de las cuales no se utilizan. La situación se puede corregir agregando la bandera -O2, en el compilador de Emscripten, también incluye la optimización del código js.
Después de eso, el código js se ve mejor:

Codigo del cliente
Debe llamar al administrador del lado del cliente de alguna manera. En primer lugar, cargue el archivo proporcionado por el usuario mediante
FileReader, almacenaremos los datos en bruto en una primitiva Uint8Array:
var rawData = new Uint8Array(fileReader.result);A continuación, debe transferir los datos descargados a la máquina virtual. Para hacer esto, primero asignamos el número requerido de bytes usando el método _malloc, luego copiamos la matriz JS allí usando el método set. Por conveniencia, separemos esta lógica en la función arrayToWasmPtr (array):
function arrayToWasmPtr(array) {
var ptr = Module._malloc(array.length);
Module.HEAP8.set(array, ptr);
return ptr;
}Después de cargar los datos en la memoria de la máquina virtual, debe llamar de alguna manera a la función desde el procesamiento. Pero, ¿cómo encontrar esta función? El método cwrap nos ayudará - el primer argumento en él especifica el nombre de la función requerida, el segundo - el tipo de retorno y el tercero - una lista con argumentos de entrada.
compressDataFunction = Module.cwrap('compress_data', 'number', ['number', 'number', 'number']);Finalmente, debe devolver los bytes terminados de la máquina virtual. Para hacer esto, escribimos otra función que los copia en una matriz JS usando el método
subarray
function wasmPtrToArray(ptr, length) {
var array = new Int8Array(length);
array.set(Module.HEAP8.subarray(ptr, ptr + length));
return array;
}El script completo para procesar archivos entrantes está aquí . El marcado HTML que contiene el formulario de carga de archivos y los artefactos wasm se cargan aquí .
Salir
Puedes jugar con el prototipo aquí .
El resultado es una copia de seguridad funcional con WASM. De las desventajas: la implementación actual de la tecnología no permite liberar la memoria asignada en la máquina virtual. Esto crea una fuga implícita cuando se carga una gran cantidad de archivos en una sesión, pero se puede solucionar reutilizando la memoria existente en lugar de asignar una nueva.

