
Cada vez con mayor frecuencia las siguientes solicitudes provienen de los clientes: “Lo queremos como Amazon RDS, pero más barato”; "Lo queremos como RDS, pero en todas partes, en cualquier infraestructura". Para implementar una solución administrada de este tipo en Kubernetes, analizamos el estado actual de los operadores más populares para PostgreSQL (Stolon, operadores de Crunchy Data y Zalando) y tomamos nuestra decisión.
Este artículo es nuestra experiencia tanto desde un punto de vista teórico (revisión de soluciones) como desde un punto de vista práctico (qué se eligió y qué salió de él). Pero primero, determinemos cuáles son los requisitos generales para un posible reemplazo de RDS ...
Que es RDS
Cuando la gente habla de RDS, en nuestra experiencia se refieren a un servicio DBMS administrado que:
- fácilmente personalizable;
- tiene la capacidad de trabajar con instantáneas y recuperarse de ellas (preferiblemente con soporte PITR );
- le permite crear topologías maestro-esclavo;
- tiene una rica lista de extensiones;
- proporciona auditoría y gestión de usuarios / accesos.
En general, los enfoques para la implementación de la tarea pueden ser muy diferentes, pero el camino con Ansible condicional no está cerca de nosotros. (Los colegas de 2GIS llegaron a una conclusión similar como resultado de su intento de crear una "herramienta para implementar rápidamente un clúster de conmutación por error basado en Postgres"). Los
operadores son el enfoque generalmente aceptado para resolver tales problemas en el ecosistema de Kubernetes. El departamento técnico de Flant ya ha contado más detalles sobre ellos en relación con las bases de datos que se ejecutan dentro de Kubernetes.distol, en uno de sus informes .
NB : Para crear rápidamente operadores simples, recomendamos prestar atención a nuestra utilidad shell-operator de código abierto . Usándolo, puede hacer esto sin conocimiento de Go, pero de formas más familiares para los administradores de sistemas: en Bash, Python, etc.
Hay varios operadores de K8 populares para PostgreSQL:
- Estolón;
- Operador PostgreSQL de Crunchy Data;
- Operador Zalando Postgres.
Echemos un vistazo más de cerca a ellos.
Selección de operador
Además de las importantes capacidades ya mencionadas anteriormente, nosotros, como ingenieros de operaciones de infraestructura en Kubernetes, también esperábamos lo siguiente de los operadores:
- implementar desde Git y desde recursos personalizados ;
- soporte de antiafinidad de vaina;
- instalación de afinidad de nodo o selector de nodo;
- establecer tolerancias;
- disponibilidad de oportunidades de tuning;
- tecnologías comprensibles e incluso comandos.
Sin entrar en detalles sobre cada uno de los puntos (pregunte en los comentarios si tiene alguna duda sobre ellos después de leer el artículo completo), observo en general que estos parámetros son necesarios para una descripción más sutil de la especialización de los nodos de clúster para poder ordenarlos para aplicaciones específicas. De esta manera podemos lograr el equilibrio óptimo entre rendimiento y costo.
Ahora para los propios operadores de PostgreSQL.
1. Estolón
Stolon de la empresa italiana Sorint.lab en el informe ya mencionado fue considerado como una especie de referencia entre los operadores de DBMS. Este es un proyecto bastante antiguo: su primer lanzamiento público tuvo lugar en noviembre de 2015 (!), Y el repositorio de GitHub cuenta con casi 3000 estrellas y más de 40 contribuyentes.
De hecho, Stolon es un gran ejemplo de arquitectura bien pensada:
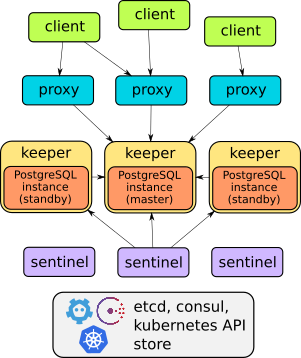
Los detalles del dispositivo de este operador se pueden encontrar en el informe o en la documentación del proyecto . En general, basta con decir que puede hacer todo lo descrito: failover, proxies para acceso transparente de clientes, respaldos ... Además, los proxies brindan acceso a través de un servicio de punto final, a diferencia de las otras dos soluciones que se analizan a continuación (tienen dos servicios para acceder base).
Sin embargo, Stolon no tiene recursos personalizados , por lo que no se puede implementar de tal manera que de manera fácil y rápida, "como pan caliente", cree instancias de DBMS en Kubernetes. La administración se lleva a cabo a través de la utilidad
stolonctl, la implementación, a través de Helm-chart, y la configuración del usuario se define en ConfigMap.
Por un lado, resulta que el operador no es muy operador (después de todo, no usa CRD). Pero, por otro lado, es un sistema flexible que le permite personalizar los recursos en K8 de la forma que desee.
Para resumir, para nosotros personalmente, no parecía óptimo crear un gráfico separado para cada base de datos. Por eso, comenzamos a buscar alternativas.
2. Operador PostgreSQL de Crunchy Data
El operador de Crunchy Data , una joven startup estadounidense, parecía una alternativa lógica. Su historia pública comienza con el primer lanzamiento en marzo de 2017, desde entonces, el repositorio de GitHub ha recibido poco menos de 1300 estrellas y más de 50 colaboradores. La última versión de septiembre se probó para funcionar con Kubernetes 1.15-1.18, OpenShift 3.11+ y 4.4+, GKE y VMware Enterprise PKS 1.3+.
La arquitectura del operador Crunchy Data PostgreSQL también cumple con los requisitos establecidos: la
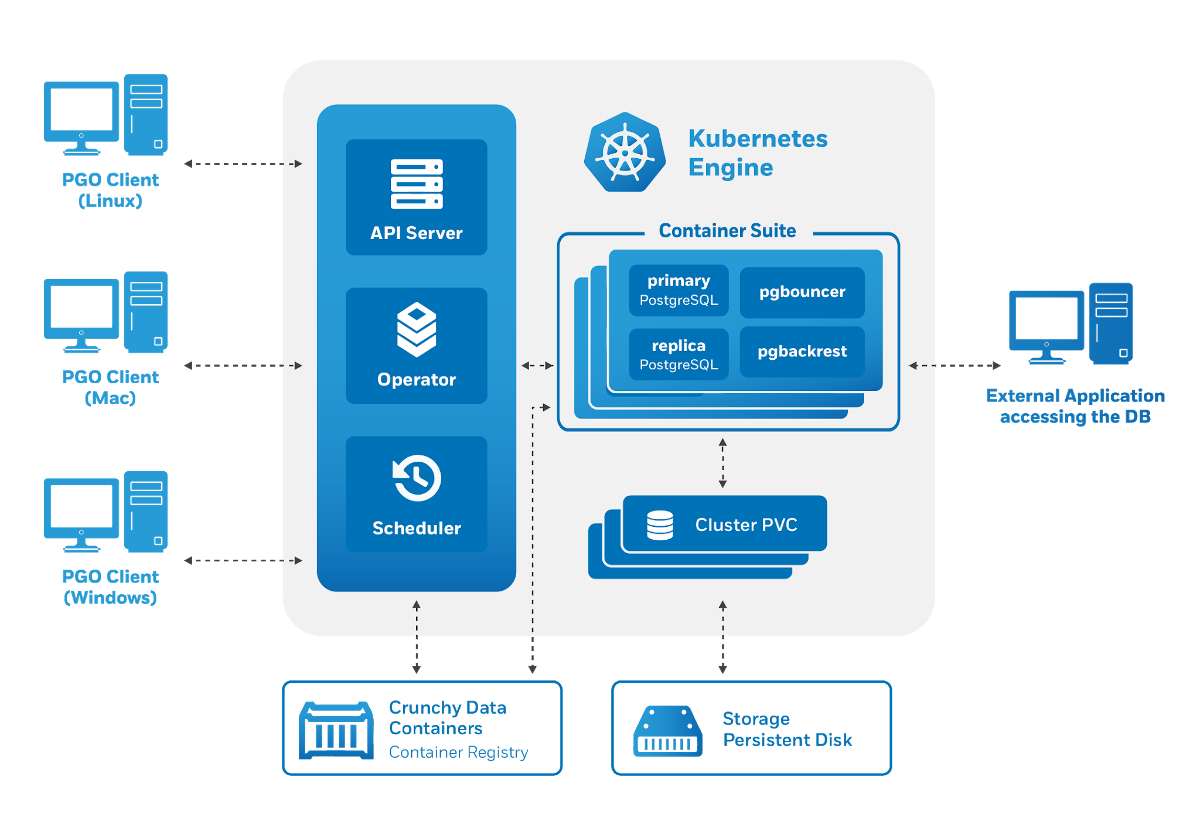
administración se realiza a través de una utilidad
pgo, pero a su vez genera recursos personalizados para Kubernetes. Por ello, el operador nos complació como usuarios potenciales:
- hay control a través de CRD;
- cómoda gestión de usuarios (también a través de CRD);
- integración con otros componentes de Crunchy Data Container Suite : una colección especializada de imágenes de contenedor para PostgreSQL y utilidades para trabajar con él (incluidas pgBackRest, pgAudit, extensiones contrib, etc.).
Sin embargo, los intentos de comenzar a usar el operador de Crunchy Data revelaron varios problemas:
- No había posibilidad de toleraciones, solo se proporciona nodeSelector.
- Los pods que creamos fueron parte de la implementación, aunque implementamos una aplicación con estado. A diferencia de StatefulSets, las implementaciones no pueden crear discos.
El último inconveniente lleva a momentos divertidos: en el entorno de prueba, fue posible ejecutar 3 réplicas con un disco de almacenamiento local , como resultado de lo cual el operador informó que 3 réplicas estaban funcionando (aunque este no fue el caso).
Otra característica de este operador es su integración prefabricada con varios sistemas auxiliares. Por ejemplo, es fácil instalar pgAdmin y pgBounce, y la documentación cubre Grafana y Prometheus preconfigurados. La versión reciente 4.5.0-beta1 señala por separado una integración mejorada con el proyecto pgMonitor , gracias a la cual el operador ofrece una visualización visual de las métricas de PgSQL listas para usar .
Sin embargo, la extraña elección de los recursos generados de Kubernetes nos llevó a buscar otra solución.
3. Operador Zalando Postgres
Conocemos los productos Zalando desde hace mucho tiempo: tenemos experiencia en el uso de Zalenium y, por supuesto, probamos Patroni , su popular solución HA para PostgreSQL. Uno de sus autores, Aleksey Klyukin, habló sobre el enfoque de la compañía para la creación de Postgres Operator en Postgres-Tuesday # 5 , y nos gustó.
Esta es la solución más reciente discutida en el artículo: el primer lanzamiento tuvo lugar en agosto de 2018. Sin embargo, a pesar de la pequeña cantidad de lanzamientos formales, el proyecto ha recorrido un largo camino, superando ya la popularidad de la solución de Crunchy Data con más de 1300 estrellas en GitHub y el número máximo de contribuyentes (más de 70).
Bajo el capó de este operador, se utilizan soluciones probadas en el tiempo:
- Patroni y Spilo por el control,
- WAL-E : para copias de seguridad,
- PgBouncer : como grupo de conexiones.
Así es como se presenta la arquitectura del operador de Zalando:
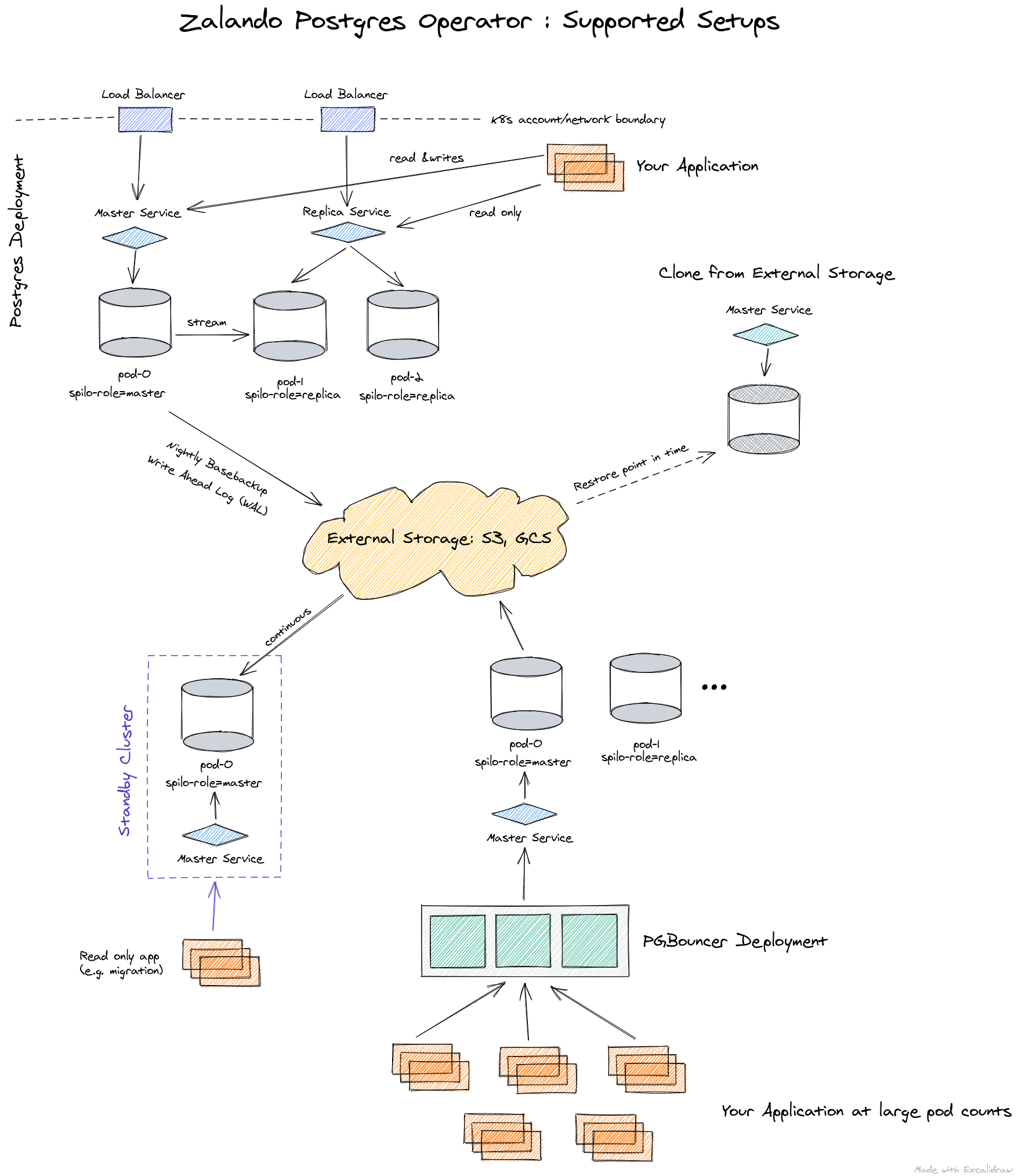
el operador está completamente administrado a través de Custom Resources, crea automáticamente un StatefulSet a partir de contenedores, que luego se puede personalizar agregando varios sidecars a los pods. Todo esto es una ventaja significativa en comparación con el operador de Crunchy Data.
Dado que fue la solución de Zalando la que elegimos entre las 3 opciones consideradas, a continuación se presentará una descripción más detallada de sus capacidades, junto con la práctica de aplicación.
Practique con el operador de Postgres de Zalando
Implementar un operador es muy simple: simplemente descargue la versión actual de GitHub y aplique los archivos YAML del directorio de manifiestos . Alternativamente, también puede usar OperatorHub .
Después de la instalación, debe preocuparse por configurar almacenamientos para registros y copias de seguridad . Se realiza a través de ConfigMap
postgres-operatoren el espacio de nombres donde instaló la declaración. Con los repositorios configurados, puede implementar su primer clúster de PostgreSQL.
Por ejemplo, nuestra implementación estándar se ve así:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
Este manifiesto despliega un clúster de 3 instancias con un sidecar en forma de postgres_exporter , del cual tomamos las métricas de la aplicación. Como puede ver, todo es muy simple y, si lo desea, puede crear literalmente un número ilimitado de clústeres.
Vale la pena prestar atención al panel de administración web : postgres-operator-ui . Viene con el operador y le permite crear y eliminar clusters, así como trabajar con copias de seguridad realizadas por el operador. Administración de copias de seguridad de
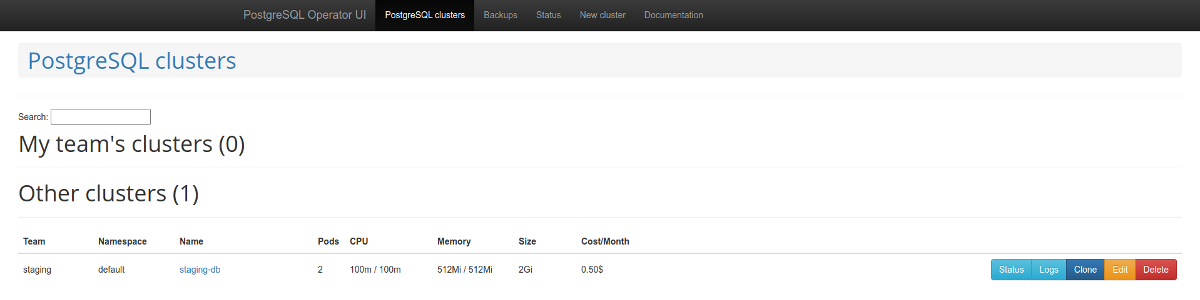
listas de clústeres de PostgreSQL Otra característica interesante es la compatibilidad con la API de Teams . Este mecanismo crea roles automáticamente en PostgreSQL
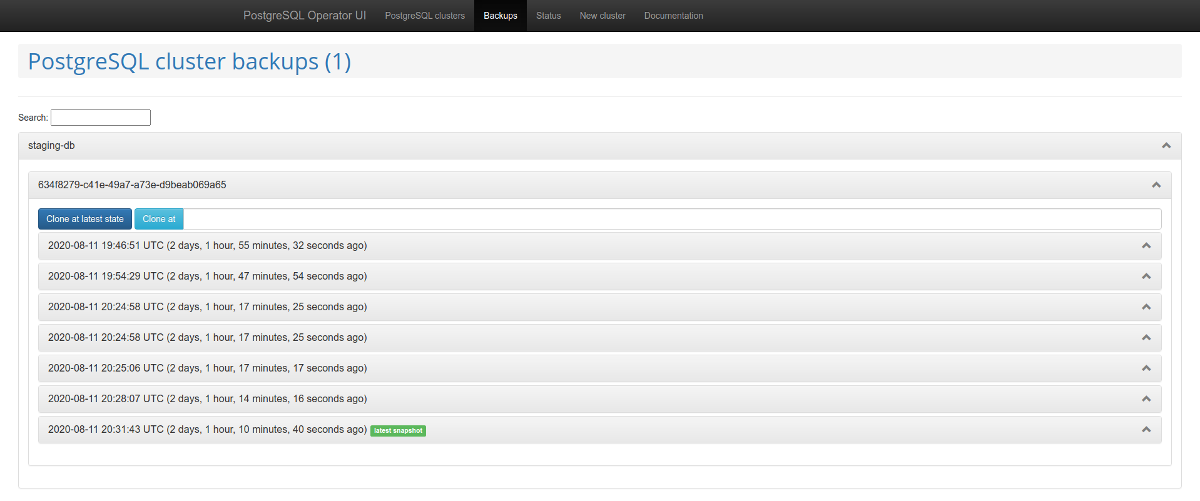
basado en la lista resultante de nombres de usuario. Después de eso, la API le permite devolver una lista de usuarios para los que se crean roles automáticamente.
Problemas y soluciones
Sin embargo, el uso del operador pronto reveló varias desventajas importantes:
- falta de soporte de nodeSelector;
- incapacidad para deshabilitar las copias de seguridad;
- cuando se utiliza la función de creación de base de datos, los privilegios predeterminados no aparecen;
- periódicamente no hay suficiente documentación o está desactualizada.
Afortunadamente, muchos de ellos se pueden resolver. Empecemos por el final: problemas con la documentación .
Lo más probable es que se encuentre con el hecho de que no siempre está claro cómo registrar una copia de seguridad y cómo conectar un depósito de copia de seguridad a la interfaz de usuario del operador. La documentación habla de esto de pasada, pero la descripción real está en el PR :
- necesitas hacer un secreto;
-
pod_environment_secret_nameCRD ConfigMap ( , ).
Sin embargo, resultó que actualmente esto es imposible. Es por eso que hemos creado nuestra propia versión del operador con algunos desarrollos adicionales de terceros. Consulte a continuación para obtener más detalles.
Si pasa los parámetros para la copia de seguridad al operador, es decir, las
wal_s3_bucketclaves de acceso en AWS S3, entonces hará una copia de seguridad de todo : no solo las bases en producción, sino también la puesta en escena. No nos convenía.
En la descripción de los parámetros para Spilo, que es el contenedor básico de Docker para PgSQL cuando se usa el operador, resultó que puede pasar el parámetro
WAL_S3_BUCKETvacío, deshabilitando así las copias de seguridad. Además, con gran alegría, se encontró un PR listo para usar , que inmediatamente aceptamos en nuestra bifurcación. Ahora es suficiente simplemente agregar el enableWALArchiving: falseclúster de PostgreSQL al recurso.
Sí, hubo una oportunidad de hacerlo de manera diferente al ejecutar 2 operadores: uno para la preparación (sin copias de seguridad) y el segundo para la producción. Pero así pudimos arreglárnoslas con uno.
Ok, aprendimos cómo transferir el acceso a las bases de datos para S3 y las copias de seguridad comenzaron a ingresar al almacenamiento. ¿Cómo hacer que las páginas de respaldo funcionen en la interfaz de usuario del operador?

En la interfaz de usuario del operador, debe agregar 3 variables:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
Después de eso, la administración de copias de seguridad estará disponible, lo que en nuestro caso simplificará el trabajo con la preparación, lo que le permitirá entregar porciones de producción allí sin scripts adicionales.
Trabajar con la API de Teams y las amplias oportunidades para crear bases y roles utilizando herramientas de operador fueron nombradas como otra ventaja. Sin embargo, los roles que se crearon no tenían derechos predeterminados . En consecuencia, un usuario con derechos de lectura no podría leer las nuevas tablas.
¿Porqué es eso? A pesar de que el código contiene los necesarios
GRANT, no siempre se utilizan. Hay 2 métodos: syncPreparedDatabasesy syncDatabases. B syncPreparedDatabases- a pesar de que preparedDatabases existe una condición en la sección defaultRolesydefaultUserspara crear roles, no se aplican los derechos predeterminados. Estamos en proceso de preparar un parche para que estos derechos se apliquen automáticamente.
Y el último momento de las mejoras que son relevantes para nosotros es un parche que agrega Node Affinity al StatefulSet creado. Nuestros clientes a menudo prefieren reducir costos mediante el uso de instancias puntuales y, claramente, no deberían alojar servicios de bases de datos. Este problema podría resolverse mediante tolerancias, pero la presencia de Node Affinity da mucha confianza.
¿Que pasó?
Como resultado de resolver los problemas anteriores, bifurcamos Postgres Operator de Zalando a nuestro repositorio , donde está construido con parches tan útiles. Y en aras de la conveniencia, también creamos una imagen de Docker .
Lista de relaciones públicas bifurcada:
- construir en Docker una imagen segura y ligera para el operador ;
- deshabilitar las copias de seguridad ;
- actualizar las versiones de recursos para las versiones actuales de k8s ;
- implementación de Node Affinity .
Sería fantástico si la comunidad apoyara a estos RP para que se incorporen a la próxima versión del operador (1.6).
¡Prima! Historia de éxito de la migración de producción
Si utiliza Patroni, la producción en vivo se puede migrar al operador con un tiempo de inactividad mínimo.
Spilo le permite crear clústeres en espera a través de almacenamientos S3 con Wal-E , cuando el registro binario de PgSQL se guarda primero en S3 y luego se descarga por la réplica. Pero, ¿qué pasa si no tiene Wal-E en su antigua infraestructura? La solución a este problema ya se ha propuesto en Habré.
La replicación lógica de PostgreSQL viene al rescate. Sin embargo, no entraremos en detalles sobre cómo crear publicaciones y suscripciones, porque ... nuestro plan ha fallado.
El caso es que la base de datos tenía varias tablas cargadas con millones de filas, que, además, se reponían y eliminaban constantemente. Suscripción simple con
copy_data, cuando una nueva réplica copia todo el contenido del maestro, simplemente no se mantuvo al día con el maestro. Copiar el contenido funcionó durante una semana, pero nunca alcanzó al maestro. Como resultado, un artículo de colegas de Avito ayudó a lidiar con el problema : puede transferir datos usando pg_dump. Describiré nuestra versión (ligeramente modificada) de este algoritmo.
La idea es que puede desactivar una suscripción vinculada a una ranura de replicación específica y luego fijar el número de transacción. Había réplicas para trabajos de producción. Esto es importante porque la réplica ayudará a crear un volcado coherente y continuará recibiendo cambios del maestro.
En los siguientes comandos que describen el proceso de migración, se utilizarán las siguientes notaciones de host:
- maestro - servidor de origen;
- replica1 : reproducción de transmisión en producción antigua;
- replica2 es una nueva réplica lógica.
Plan de migración
1. En el asistente, cree una suscripción a todas las tablas en el esquema de la
publicbase de datos dbname:
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2. Creemos una ranura de replicación en el maestro:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3. Detenga la replicación en la réplica anterior:
psql -h replica1 -c "select pg_wal_replay_pause();"
4. Obtenga el número de transacción del maestro:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5. Vierta la réplica antigua. Haremos esto en varios hilos, lo que ayudará a acelerar el proceso:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6. Cargue el volcado al nuevo servidor:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7. Después de descargar el volcado, puede iniciar la replicación en la réplica de transmisión:
psql -h replica1 -c "select pg_wal_replay_resume();"
7. Creemos una suscripción en una nueva réplica lógica:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8. Obtenga
oidsuscripciones:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9. Digamos que fue recibido
oid=1000. Apliquemos el número de transacción a la suscripción:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10. Comencemos la replicación:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11. Verifique el estado de la suscripción, la replicación debería funcionar:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12. Una vez iniciada la replicación y sincronizadas las bases de datos, puede cambiar.
13. Después de deshabilitar la replicación, debe corregir las secuencias. Esto está bien documentado en un artículo en wiki.postgresql.org .
Gracias a este plan, la transición se realizó con retrasos mínimos.
Conclusión
Los operadores de Kubernetes le permiten simplificar varias actividades reduciéndolas a la creación de recursos de K8. Sin embargo, habiendo logrado una automatización notable con su ayuda, vale la pena recordar que puede traer una serie de matices inesperados, así que elija sabiamente a sus operadores.
Después de revisar los tres operadores de Kubernetes más populares para PostgreSQL, optamos por un proyecto de Zalando. Y tuvimos que superar ciertas dificultades con él, pero el resultado fue realmente satisfactorio, así que planeamos expandir esta experiencia a otras instalaciones de PgSQL. Si tiene experiencia en el uso de soluciones similares, estaremos encantados de ver los detalles en los comentarios.
PD
Lea también en nuestro blog: