La tarea de construir plataformas de TI para la acumulación y análisis de datos, tarde o temprano surge para cualquier empresa cuyo negocio se base en un modelo de prestación de servicios cargados intelectualmente o en la creación de productos técnicamente complejos. La construcción de plataformas analíticas es una tarea difícil y que requiere mucho tiempo. Sin embargo, cualquier tarea se puede simplificar. En este artículo, quiero compartir mi experiencia en el uso de herramientas de bajo código para ayudarlo a crear soluciones analíticas. Esta experiencia se obtuvo durante la implementación de una serie de proyectos en la dirección de Big Data Solutions de la empresa Neoflex. Desde 2005, la dirección de Big Data Solutions de Neoflex se ha ocupado de los problemas de la construcción de depósitos de datos y lagos, resolviendo problemas de optimización de la velocidad de procesamiento de la información y trabajando en una metodología para gestionar la calidad de los datos.
Nadie podrá evitar la acumulación consciente de datos poco estructurados y / o muy estructurados. Quizás incluso si estamos hablando de una pequeña empresa. De hecho, al escalar un negocio, un emprendedor prometedor enfrentará los problemas de desarrollar un programa de lealtad, querrá analizar la efectividad de los puntos de venta, pensar en la publicidad dirigida y quedar desconcertado por la demanda de productos complementarios. Como primera aproximación, el problema se puede solucionar en la rodilla. Pero con el crecimiento de una empresa, llegar a una plataforma analítica sigue siendo inevitable.
Sin embargo, ¿en qué caso las tareas de análisis de datos pueden convertirse en tareas de la clase "Ciencia espacial"? Quizás, en ese momento cuando se trata de datos realmente grandes.
Para simplificar la tarea de Rocket Science, puedes comer el elefante pieza por pieza.
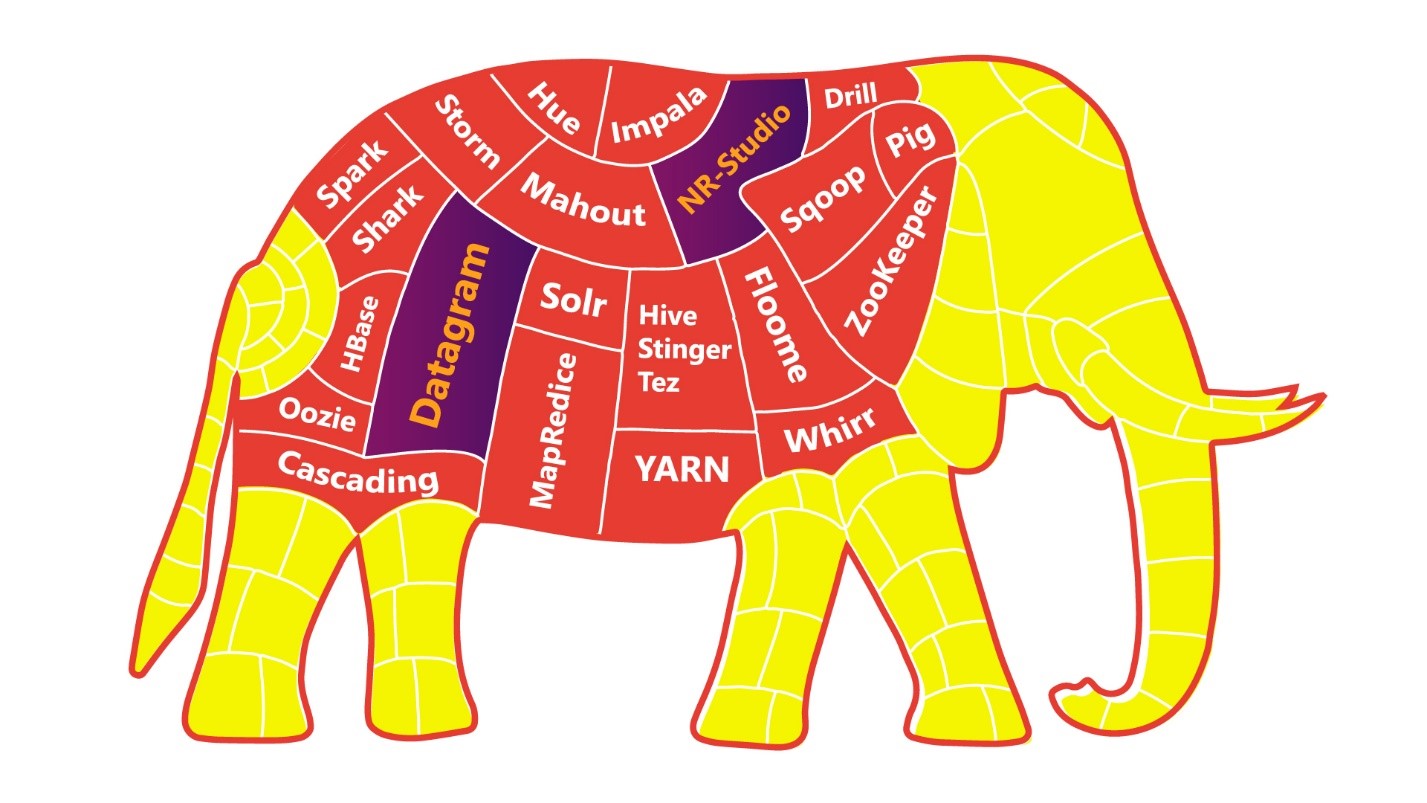
Cuanta más discreción y autonomía tengan sus aplicaciones / servicios / microservicios, más fácil será para usted, sus colegas y toda la empresa digerir un elefante.
Casi todos nuestros clientes llegaron a este postulado, reconstruyendo el panorama, basándose en las prácticas de ingeniería de los equipos de DevOps.
Pero incluso con una dieta "dividida, elefante", tenemos una buena probabilidad de "sobresaturación" del panorama de TI. En este punto, vale la pena detenerse, exhalar y mirar hacia la plataforma de ingeniería de código bajo .
Muchos desarrolladores se sienten intimidados por la perspectiva de un callejón sin salida en sus carreras cuando se alejan de la escritura directa de código para "arrastrar" flechas en interfaces UI de sistemas de código bajo. Pero la aparición de las máquinas herramienta no provocó la desaparición de los ingenieros, ¡sino que llevó su trabajo a un nuevo nivel!
Averigüemos por qué.
El análisis de datos en el campo de la logística, la industria de las telecomunicaciones, en el campo de la investigación de medios, el sector financiero, siempre está asociado con las siguientes preguntas:
- La velocidad del análisis automatizado;
- La capacidad de realizar experimentos sin afectar el flujo principal de producción de datos;
- La confiabilidad de los datos preparados;
- Seguimiento de cambios y control de versiones;
- Procedencia de datos, linaje de datos, CDC;
- Entrega rápida de nuevas funciones al entorno de producción;
- Y el proverbial: costo de desarrollo y soporte.
Es decir, los ingenieros tienen una gran cantidad de tareas de alto nivel, que se pueden realizar con suficiente eficiencia solo despejando sus mentes de las tareas de desarrollo de bajo nivel.
La evolución y la digitalización de los negocios se convirtieron en requisitos previos para la transición de los desarrolladores a un nuevo nivel. El valor del desarrollador también está cambiando: hay una escasez significativa de desarrolladores que puedan profundizar en los conceptos de una empresa automatizada.
Hagamos una analogía con los lenguajes de programación de bajo y alto nivel. La transición de lenguajes de bajo nivel a lenguajes de alto nivel es una transición de escribir "directivas directas en el lenguaje de hierro" hacia "directivas en el lenguaje de la gente". Es decir, agregar una capa de abstracción. En este caso, la transición a plataformas de código bajo de lenguajes de programación de alto nivel es una transición de "directivas en el lenguaje de las personas" a "directivas en el lenguaje de los negocios". Si hay desarrolladores que se entristecen por este hecho, entonces se entristecen, tal vez incluso desde el momento en que nació Java Script, que utiliza funciones de clasificación de matrices. Y estas funciones, por supuesto, tienen implementación de software bajo el capó por otros medios de la misma programación de alto nivel.
Por lo tanto, low-code es solo el surgimiento de otra capa de abstracción.
Experiencia aplicada de usar low-code
El tema de low-code es bastante amplio, pero ahora me gustaría hablar sobre la aplicación aplicada de "conceptos de low-code" en el ejemplo de uno de nuestros proyectos.
La división Big Data Solutions de Neoflex está más especializada en el sector financiero de las empresas, construyendo lagos de datos y almacenamiento y automatizando diversos informes. En este nicho, el uso de low-code se ha convertido durante mucho tiempo en un estándar. Otras herramientas de bajo código incluyen herramientas para organizar procesos ETL: Informatica Power Center, IBM Datastage, Pentaho Data Integration. O Oracle Apex, que actúa como un entorno para el desarrollo rápido de interfaces para acceder y editar datos. Sin embargo, el uso de herramientas de desarrollo de código bajo no siempre está asociado con la construcción de aplicaciones altamente específicas en una pila de tecnología comercial con una dependencia pronunciada del proveedor.
Con plataformas de código bajo, también puede organizar la orquestación de flujos de datos, crear plataformas de ciencia de datos o, por ejemplo, módulos de control de calidad de datos.
Uno de los ejemplos aplicados de la experiencia del uso de herramientas de desarrollo de código bajo es la colaboración entre Neoflex y Mediascope, uno de los líderes en el mercado de investigación de medios de Rusia. Uno de los objetivos comerciales de esta empresa es la producción de datos, a partir de los cuales anunciantes, sitios de Internet, canales de televisión, estaciones de radio, agencias de publicidad y marcas deciden comprar publicidad y planificar sus comunicaciones de marketing.

La investigación de medios es un área de negocios intensiva en tecnología. Reconocer secuencias de video, recopilar datos de dispositivos que analizan la visualización, medir la actividad en los recursos web: todo esto implica que una empresa tiene un gran personal de TI y una experiencia colosal en la creación de soluciones analíticas. Pero el crecimiento exponencial en la cantidad de información, el número y la variedad de sus fuentes hace que la industria de datos de TI progrese constantemente. La solución más simple para escalar la plataforma analítica que ya funciona Mediascope podría ser un aumento en el personal de TI. Pero una solución mucho más eficiente es acelerar el proceso de desarrollo. Uno de los pasos que llevan en esta dirección puede ser el uso de plataformas low-code.
En el momento del inicio del proyecto, la empresa ya contaba con una solución de producto en funcionamiento. Sin embargo, la implementación de la solución en MSSQL no pudo cumplir completamente con las expectativas para escalar la funcionalidad mientras se mantenía un costo de revisión aceptable.
La tarea que teníamos ante nosotros era realmente ambiciosa: Neoflex y Mediascope tuvieron que crear una solución industrial en menos de un año, siempre que el MVP se lanzara dentro del primer trimestre a partir de la fecha de inicio del trabajo.
Se eligió la pila de tecnología Hadoop como base para construir una nueva plataforma de datos basada en la computación de bajo código. HDFS se ha convertido en el estándar para el almacenamiento de datos utilizando archivos de parquet. Para acceder a los datos en la plataforma se utilizó Hive, en el que todos los escaparates disponibles se presentan como tablas externas. La carga de datos en el almacenamiento se implementó mediante Kafka y Apache NiFi.
La herramienta de código bajo en este concepto se utilizó para optimizar la tarea más laboriosa en la construcción de una plataforma analítica: la tarea de calcular datos.

Se eligió la herramienta Datagram de código bajo como el mecanismo principal para el mapeo de datos. Neoflex Datagram es una herramienta para diseñar transformaciones y flujos de datos.
Con esta herramienta, puede evitar escribir código Scala "a mano". El código Scala se genera automáticamente utilizando el enfoque de Arquitectura basada en modelos.
Una ventaja obvia de este enfoque es la aceleración del proceso de desarrollo. Sin embargo, además de la velocidad, también existen las siguientes ventajas:
- Ver contenido y estructura de fuentes / destinos;
- Seguimiento del origen de los objetos de flujo de datos a campos individuales (linaje);
- Ejecución parcial de transformaciones con visualización de resultados intermedios;
- Ver el código fuente y corregirlo antes de la ejecución;
- Validación automática de transformaciones;
- Carga automática de datos 1 en 1.
El umbral para ingresar soluciones de código bajo para generar transformaciones es bastante bajo: el desarrollador necesita conocer SQL y tener experiencia con herramientas ETL. Cabe señalar que los generadores de transformación controlados por código no son herramientas ETL en el sentido amplio de la palabra. Es posible que las herramientas de bajo código no tengan su propio entorno de ejecución de código. Es decir, el código generado se ejecutará en el entorno que estaba en el clúster incluso antes de la instalación de la solución de código bajo. Y esto es, quizás, otra ventaja en el karma de bajo código. Dado que, en paralelo con el comando low-code, puede funcionar un comando "clásico", que implementa la funcionalidad, por ejemplo, en código Scala puro. Llevar el trabajo de ambos equipos a producción será simple y sin problemas.
Quizás vale la pena señalar que, además del código bajo, también existen soluciones sin código. Y en su esencia son cosas diferentes. Low-code permite al desarrollador interferir con el código generado en mayor medida. En el caso de Datagram, es posible ver y editar el código Scala generado, sin código puede no brindar dicha oportunidad. Esta diferencia es muy significativa no solo en términos de flexibilidad de la solución, sino también en términos de comodidad y motivación en el trabajo de los ingenieros de datos.
Arquitectura de soluciones
Intentemos descubrir cómo ayuda exactamente una herramienta de código bajo a resolver el problema de optimizar la velocidad de desarrollo de la funcionalidad de cálculo de datos. Primero, echemos un vistazo a la arquitectura funcional del sistema. En este caso, un ejemplo es el modelo de producción de datos para la investigación de medios.

Las fuentes de datos en nuestro caso son muy heterogéneas y diversas:
- (-) — - , – , , . – . Data Lake , , , . , , ;
- ;
- web-, site-centric, user-centric . Data Lake research bar VPN.
- , - ;
- -.
La implementación tal cual de la carga desde los sistemas de origen en la etapa primaria de datos brutos se puede organizar de varias formas. Si se utiliza low-code para estos fines, es posible generar automáticamente scripts de arranque basados en metadatos. En este caso, no es necesario descender al nivel de desarrollo de las asignaciones de origen a destino. Para implementar la carga automática, necesitamos establecer una conexión con la fuente y luego definir en la interfaz de carga una lista de entidades a cargar. La creación de la estructura de directorios en HDFS será automática y corresponderá a la estructura de almacenamiento de datos en el sistema fuente.
Sin embargo, en el contexto de este proyecto, decidimos no aprovechar esta oportunidad de la plataforma low-code debido al hecho de que Mediascope ya ha comenzado a trabajar de forma independiente en la producción de un servicio similar en el enlace Nifi + Kafka.
Cabe señalar de inmediato que estas herramientas no son intercambiables, sino que se complementan entre sí. Nifi y Kafka son capaces de trabajar tanto en paquetes directos (Nifi -> Kafka) como en reversa (Kafka -> Nifi). Para la plataforma de investigación de medios, se utilizó el primer enlace.

En nuestro caso, necesitaba procesar varios tipos de datos de los sistemas de origen y enviarlos al corredor de Kafka. Al mismo tiempo, la dirección de mensajes a un tema específico de Kafka se llevó a cabo utilizando los procesadores PublishKafka Nifi. La orquestación y el mantenimiento de estas canalizaciones se realiza en una interfaz visual. La herramienta Nifi y el uso del paquete Nifi + Kafka también se pueden llamar un enfoque de desarrollo de código bajo, que tiene un umbral bajo para ingresar a las tecnologías de Big Data y acelera el proceso de desarrollo de aplicaciones.
La siguiente etapa en la implementación del proyecto fue la reducción al formato de una sola capa semántica de datos detallados. Si una entidad tiene atributos históricos, el cálculo se realiza en el contexto de la partición en cuestión. Si la entidad no es histórica, entonces es opcionalmente posible recalcular todo el contenido del objeto o negarse a recalcular este objeto en absoluto (debido a la ausencia de cambios). En esta etapa, se generan claves para todas las entidades. Las claves se guardan en los directorios de Hbase correspondientes a los objetos maestros, que contienen la correspondencia entre las claves de la plataforma analítica y las claves de los sistemas fuente. La consolidación de entidades atómicas se acompaña de un enriquecimiento con los resultados del cálculo preliminar de los datos analíticos. El marco para calcular los datos fue Spark.La funcionalidad descrita de convertir datos a una única semántica también se implementó sobre la base de mapeos de la herramienta de código bajo Datagram.
La arquitectura de destino requería proporcionar acceso a datos SQL para usuarios comerciales. Hive se utilizó para esta opción. Los objetos se registran en Hive automáticamente cuando la opción "Registr Hive Table" está habilitada en la herramienta de código bajo.

Control de flujo de pagos
Datagram tiene una interfaz para crear diseños de flujo de trabajo. Las asignaciones se pueden iniciar utilizando el programador Oozie. En la interfaz del desarrollador de streams, es posible crear esquemas en paralelo, secuencial o dependiendo de las condiciones especificadas para la ejecución de transformaciones de datos. Hay soporte para scripts de shell y programas java. También es posible utilizar el servidor Apache Livy. Apache Livy se utiliza para ejecutar aplicaciones directamente desde el entorno de desarrollo.
Si la empresa ya tiene su propio orquestador de procesos, es posible utilizar la API REST para incrustar asignaciones en una secuencia existente. Por ejemplo, tuvimos una experiencia bastante exitosa de incrustar mapeos de Scala en orquestadores escritos en PLSQL y Kotlin. La API REST de una herramienta de código bajo implica la presencia de operaciones tales como generar el año ejecutable basado en el diseño del mapeo, llamar al mapeo, llamar a la secuencia de mapeos y, por supuesto, pasar parámetros a la URL para lanzar los mapeos.
Junto con Oozie, es posible organizar un flujo de cálculo utilizando Airflow. Quizás no me detendré en la comparación de Oozie y Airflow durante mucho tiempo, pero simplemente diré que en el contexto del trabajo en un proyecto de investigación de medios, la elección recayó en Airflow. Los principales argumentos esta vez resultaron ser una comunidad más activa desarrollando el producto y una interfaz + API más desarrollada.
Airflow también es bueno porque usa el adorado Python para describir los procesos de cálculo. En general, no hay tantas plataformas de gestión de flujo de trabajo de código abierto. Lanzar y monitorear la ejecución de procesos (incluidos aquellos con un diagrama de Gantt) solo agrega puntos al karma de Airflow.
El formato del archivo de configuración para ejecutar asignaciones de soluciones de código bajo es spark-submit. Esto sucedió por dos razones. Primero, spark-submit le permite ejecutar el archivo jar directamente desde la consola. En segundo lugar, puede contener toda la información que necesita para configurar el flujo de trabajo (lo que facilita la escritura de scripts que forman el Dag).
El elemento más común del flujo de trabajo Airflow en nuestro caso es SparkSubmitOperator.
SparkSubmitOperator le permite ejecutar mapeos de datagramas empaquetados jar`niks con parámetros de entrada preformados para ellos.
Cabe mencionar que cada tarea de Airflow se ejecuta en un hilo independiente y no sabe nada sobre las otras tareas. En este sentido, la interacción entre tareas se realiza mediante operadores de control como DummyOperator o BranchPythonOperator.
En conjunto, el uso de la solución Datagram low-code junto con la universalización de los archivos de configuración (formando Dag) ha llevado a una aceleración y simplificación significativa del proceso de desarrollo de flujos de descarga de datos.
Cálculo de escaparate
Quizás la etapa más cargada de forma inteligente en la producción de datos analíticos es el paso de construcción del escaparate. En el contexto de uno de los flujos de datos de la empresa investigadora, en esta etapa se produce una conversión a una emisión de referencia, teniendo en cuenta la corrección por zonas horarias con referencia a la cuadrícula de emisión. También es posible ajustar para la red de transmisión local (noticias y publicidad local). Entre otras cosas, este paso desglosa los intervalos de visualización continuos de los productos multimedia basándose en el análisis de los intervalos de visualización. Inmediatamente, los valores de visualización se "ponderan" en función de la información sobre su importancia (cálculo del factor de corrección).

La validación de datos es un paso independiente en la preparación de mercados de datos. El algoritmo de validación utiliza varios modelos científicos matemáticos. Sin embargo, el uso de una plataforma de código bajo permite dividir un algoritmo complejo en una serie de asignaciones separadas visualmente legibles. Cada una de las asignaciones realiza una tarea limitada. Como resultado, es posible la depuración intermedia, el registro y la visualización de las etapas de preparación de datos.
Se decidió discretizar el algoritmo de validación en las siguientes sub-etapas:
- Trazar regresiones de las dependencias de ver una red de televisión en una región con ver todas las redes de la región durante 60 días.
- Cálculo de residuos studentizados (desviaciones de los valores reales de los predichos por el modelo de regresión) para todos los puntos de regresión y para el día calculado.
- Una muestra de pares de red-región anómalos, donde el resto estudentizado del día calculado excede la norma (especificada por la configuración de operación).
- Recálculo del residuo estudentizado corregido para pares anormales región-red para cada encuestado que vio la red en la región con la determinación de la contribución de este encuestado (el valor del cambio en el residuo estudentizado) al excluir a este encuestado de la muestra.
- Búsqueda de candidatos, cuya exclusión devuelve a la normalidad el saldo estudiantilizado del día de liquidación.
El ejemplo anterior confirma la hipótesis de que un ingeniero de datos debería tener demasiado en la cabeza de todos modos ... Y si esto es realmente un "ingeniero", no un "codificador", entonces el miedo a la degradación profesional al usar herramientas de código bajo finalmente debe retirarse.
¿Qué más puede hacer el código bajo?
El alcance de una herramienta de bajo código para procesar por lotes y transmitir datos sin escribir manualmente código Scala no termina ahí.
El uso de low-code en el desarrollo de datalakes ya se ha convertido en un estándar para nosotros. Quizás podamos decir que las soluciones en la pila de Hadoop siguen el camino del desarrollo del clásico DWH basado en RDBMS. Las herramientas de bajo código en la pila de Hadoop pueden resolver tanto las tareas de procesamiento de datos como las tareas de creación de interfaces de BI finales. Además, cabe señalar que BI puede significar no solo la representación de datos, sino también su edición por las fuerzas de los usuarios empresariales. A menudo usamos esta funcionalidad cuando construimos plataformas analíticas para el sector financiero.

Entre otras cosas, utilizando low-code y, en particular, Datagram, es posible resolver el problema de rastrear el origen de los objetos de flujo de datos con atomicidad a campos individuales (linaje). Para hacer esto, la herramienta low-code implementa una interfaz con Apache Atlas y Cloudera Navigator. De hecho, el desarrollador necesita registrar un conjunto de objetos en los diccionarios Atlas y hacer referencia a los objetos registrados al crear asignaciones. El mecanismo para rastrear el origen de los datos o analizar las dependencias de los objetos ahorra mucho tiempo si es necesario realizar mejoras en los algoritmos de cálculo. Por ejemplo, al elaborar estados financieros, esta función le permite sobrevivir más cómodamente al período de cambios legislativos. Después de todo, cuanto mejor comprendamos la dependencia entre formas en el contexto de los objetos de la capa detallada,menos encontraremos defectos "repentinos" y reduciremos el número de reprocesos.

Calidad de datos y código bajo
Otra tarea implementada por la herramienta low-code en el proyecto Mediascope es la tarea de la clase Data Quality. Una característica de la implementación de la tubería de verificación de datos para el proyecto de la empresa de investigación fue la falta de impacto en el rendimiento y la velocidad del flujo de datos principal. Se utilizó el conocido Apache Airflow para permitir la orquestación de la validación de datos por hilos independientes. A medida que estaba listo cada paso de la producción de datos, se lanzó en paralelo una parte separada del pipeline DQ.
Es una buena práctica monitorear la calidad de los datos desde su inicio en la plataforma de análisis. Teniendo información sobre los metadatos, podemos, desde el momento en que la información ingresa a la capa primaria, verificar si se cumplen las condiciones básicas, no nulas, restricciones, claves externas. Esta funcionalidad se implementa en base a mapeos generados automáticamente de la familia de calidad de datos en Datagram. En este caso, la generación de código también se basa en los metadatos del modelo. En el proyecto Mediascope, la interfaz se realizó con los metadatos del producto Enterprise Architect.
Al emparejar la herramienta de código bajo y Enterprise Architect, se generaron automáticamente las siguientes comprobaciones:
- Comprobación de la presencia de valores "nulos" en los campos con el modificador "no nulo";
- Comprobación de la presencia de duplicados de la clave principal;
- Validación de clave externa de entidad;
- Comprobación de la unicidad de una cadena frente a un conjunto de campos.
Para verificaciones de validez y disponibilidad de datos más sofisticadas, se creó un mapeo de Scala Expression que acepta un código de verificación externo Spark SQL preparado por analistas en Zeppelin.

Por supuesto, es necesario llegar a la generación automática de cheques de forma gradual. En el marco del proyecto descrito, este fue precedido por los siguientes pasos:
- DQ implementado en portátiles Zeppelin;
- DQ integrado en el mapeo;
- DQ en forma de mapeos masivos separados que contienen un conjunto completo de controles para una entidad en particular;
- Asignaciones DQ universales parametrizadas que aceptan metadatos e información de validación empresarial como entrada.
Quizás la principal ventaja de crear un servicio de controles parametrizados es la reducción en el tiempo de entrega de funcionalidad al entorno de producción. Los nuevos controles de calidad pueden eludir el patrón clásico de entregar código indirectamente a través de entornos de desarrollo y prueba:
- Todas las verificaciones de metadatos se generan automáticamente cuando el modelo cambia en EA;
- Las verificaciones de disponibilidad de datos (que determinan la presencia de cualquier dato en un momento determinado) se pueden generar basándose en un directorio que almacena el tiempo esperado de aparición del siguiente dato en el contexto de los objetos;
- Los analistas crean la validación de datos comerciales en los cuadernos Zeppelin. Desde donde van directamente a las tablas de configuración del módulo DQ en el entorno de producción.
No existen riesgos de envío directo de scripts a producción como tal. Incluso con un error de sintaxis, lo máximo que nos amenaza es no realizar una verificación, porque el flujo de cálculo de datos y el flujo de lanzamiento de controles de calidad están separados entre sí.
De hecho, el servicio DQ se ejecuta permanentemente en el entorno de producción y está listo para comenzar a funcionar cuando aparezca el siguiente dato.
En lugar de una conclusión
La ventaja de utilizar low-code es obvia. Los desarrolladores no necesitan desarrollar una aplicación desde cero. Un programador liberado de tareas adicionales da resultados más rápidamente. La velocidad, a su vez, libera un recurso adicional de tiempo para resolver problemas de optimización. Por tanto, en este caso, puede contar con una solución mejor y más rápida.
Por supuesto, el código bajo no es una panacea y la magia no sucederá por sí sola:
- La industria del código bajo está pasando por una etapa de "crecimiento" y hasta ahora no existen estándares industriales uniformes;
- Muchas soluciones low-code no son gratuitas y su compra debería ser un paso deliberado, que debería realizarse con plena confianza en los beneficios económicos de su uso;
- GIT / SVN. ;
- – , , « » low-code-.
- , low-code-. . / IT- .

Sin embargo, si conoce todas las deficiencias del sistema elegido y, sin embargo, los beneficios de su uso se encuentran en la mayoría dominante, vaya al código pequeño sin temor. Además, la transición a él es inevitable, como cualquier evolución es inevitable.
Si un desarrollador en una plataforma de código bajo puede hacer su trabajo más rápido que dos desarrolladores sin código bajo, esto le da a la empresa una ventaja en todos los aspectos. El umbral para ingresar a soluciones de bajo código es más bajo que en las tecnologías "tradicionales", y esto tiene un efecto positivo en el problema de la escasez de personal. Cuando se utilizan herramientas de bajo código, es posible acelerar la interacción entre equipos funcionales y tomar decisiones más rápidas sobre la corrección de la ruta de investigación de ciencia de datos elegida. Las plataformas de bajo nivel pueden impulsar la transformación digital de una organización, ya que las soluciones producidas pueden ser entendidas por especialistas no técnicos (en particular, los usuarios comerciales).
Si tiene una fecha límite ajustada, una lógica de negocios ocupada, una falta de experiencia tecnológica y necesita acelerar el tiempo de comercialización, el código bajo es una de las formas de satisfacer sus necesidades.
No se puede negar la importancia de las herramientas de desarrollo tradicionales, pero en muchos casos el uso de soluciones de bajo código es la mejor manera de mejorar la eficiencia de los problemas que se resuelven.