Continúo mi historia sobre cómo hacer amigos de Exchange y ELK (comience aquí ). Permítame recordarle que esta combinación es capaz de manejar una gran cantidad de registros sin dudarlo. Esta vez hablaremos sobre cómo hacer que Exchange funcione con los componentes Logstash y Kibana.
Logstash en la pila ELK se utiliza para procesar de forma inteligente los registros y prepararlos para colocarlos en Elastic en forma de documentos, sobre cuya base es conveniente crear varias visualizaciones en Kibana.
Instalación
Consta de dos etapas:
- Instalación y configuración del paquete OpenJDK.
- Instalación y configuración del paquete Logstash.
Instalación y configuración del
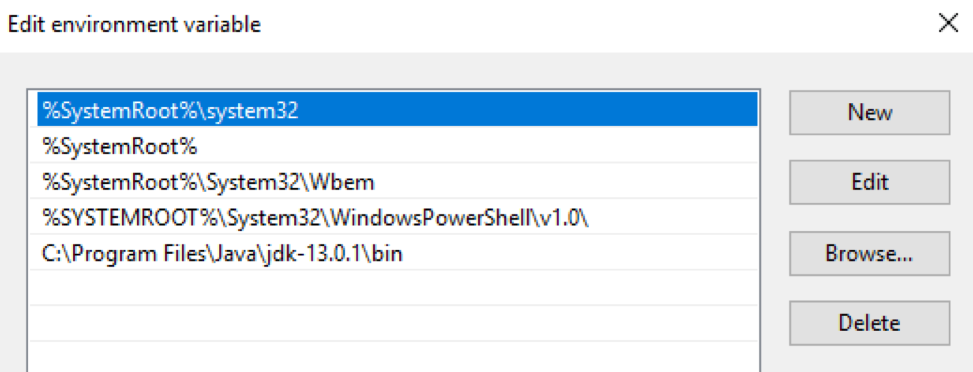
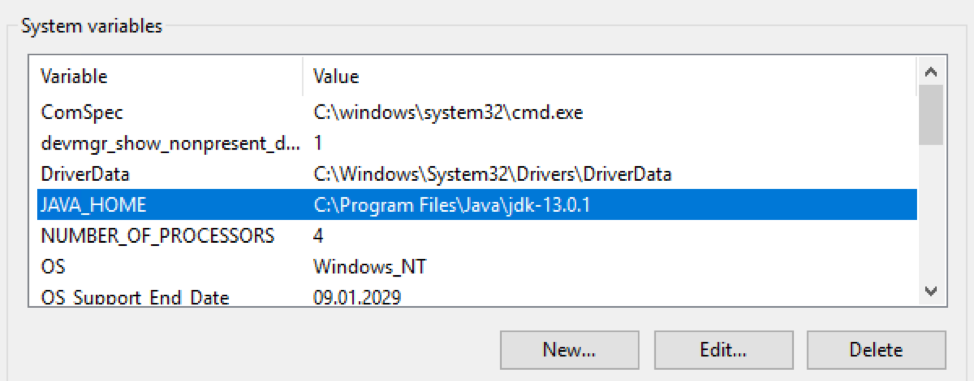
paquete OpenJDK El paquete OpenJDK debe descargarse y descomprimirse en un directorio específico. Luego, la ruta a este directorio debe ingresarse en las variables $ env: Path y $ env: JAVA_HOME del sistema operativo Windows:
Verifique la versión de Java:
PS C:\> java -version
openjdk version "13.0.1" 2019-10-15
OpenJDK Runtime Environment (build 13.0.1+9)
OpenJDK 64-Bit Server VM (build 13.0.1+9, mixed mode, sharing)
Instalación y configuración del paquete Logstash
Descargue el archivo de almacenamiento con la distribución de Logstash desde aquí . El archivo debe descomprimirse en la raíz del disco.
C:\Program FilesNo debe descomprimirlo en una carpeta , Logstash se negará a iniciarse normalmente. Luego, debe realizar jvm.optionscambios en el archivo que es responsable de asignar RAM para el proceso de Java. Recomiendo especificar la mitad de la RAM del servidor. Si tiene 16 GB de RAM a bordo, las claves predeterminadas son:
-Xms1g
-Xmx1g
debe ser reemplazado por:
-Xms8g
-Xmx8g
Además, es recomendable comentar la línea
-XX:+UseConcMarkSweepGC. Lea más sobre esto aquí . El siguiente paso es crear una configuración predeterminada en el archivo logstash.conf:
input {
stdin{}
}
filter {
}
output {
stdout {
codec => "rubydebug"
}
}
Con esta configuración, Logstash lee los datos de la consola, los pasa a través de un filtro vacío y los vuelve a imprimir en la consola. La aplicación de esta configuración probará la funcionalidad de Logstash. Para hacer esto, ejecútelo de forma interactiva:
PS C:\...\bin> .\logstash.bat -f .\logstash.conf
...
[2019-12-19T11:15:27,769][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2019-12-19T11:15:27,847][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2019-12-19T11:15:28,113][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Logstash se inició con éxito en el puerto 9600.
El paso final de la instalación es iniciar Logstash como un servicio de Windows. Esto se puede hacer, por ejemplo, usando el paquete NSSM :
PS C:\...\bin> .\nssm.exe install logstash
Service "logstash" installed successfully!
Tolerancia a fallos
El mecanismo de Colas persistentes garantiza la seguridad de los registros durante la transmisión desde el servidor de origen.
Como funciona
El diseño de las colas durante el procesamiento de registros: entrada → cola → filtro + salida.
El complemento de entrada recibe datos de la fuente de registro, los escribe en la cola y envía una confirmación de recepción de los datos a la fuente.
Los mensajes de la cola son procesados por Logstash, pasan el filtro y el complemento de salida. Al recibir la confirmación de la salida de envío de un registro, Logstash elimina el registro procesado de la cola. Si Logstash se detiene, todos los mensajes sin procesar y los mensajes para los que no se ha recibido confirmación de envío permanecen en la cola y Logstash continuará procesándolos la próxima vez que se inicie.
Personalización
Regulado por claves en el archivo
C:\Logstash\config\logstash.yml:
queue.type: (los valores posibles sonpersistedymemory (default)).path.queue: (ruta a la carpeta con archivos de cola, que se almacenan en C: \ Logstash \ queue de forma predeterminada).queue.page_capacity: (tamaño máximo de página de la cola, el valor predeterminado es 64 MB).queue.drain: (verdadero / falso: habilita / deshabilita la detención del procesamiento de la cola antes de apagar Logstash. No recomiendo encenderlo, porque esto afectará directamente la velocidad de apagado del servidor).queue.max_events: (número máximo de eventos en la cola, predeterminado - 0 (ilimitado)).queue.max_bytes: (tamaño máximo de la cola en bytes, el valor predeterminado es 1024 MB (1 GB)).
Si
queue.max_eventsse configuran y queue.max_bytes, los mensajes dejarán de recibirse en la cola cuando se alcance el valor de cualquiera de estas configuraciones. Lea más sobre las colas persistentes aquí .
Un ejemplo de la parte de logstash.yml responsable de configurar una cola:
queue.type: persisted
queue.max_bytes: 10gb
Personalización
La configuración de Logstash generalmente consta de tres partes, responsables de las diferentes fases del procesamiento de los registros entrantes: recepción (sección de entrada), análisis (sección de filtro) y envío a Elastic (sección de salida). A continuación, veremos más de cerca cada uno de ellos.
Entrada
La secuencia entrante con registros sin procesar se recibe de los agentes de filebeat. Es este complemento el que especificamos en la sección de entrada:
input {
beats {
port => 5044
}
}
Después de esta configuración, Logstash comienza a escuchar en el puerto 5044 y, cuando recibe registros, los procesa de acuerdo con la configuración en la sección de filtro. Si es necesario, puede ajustar el canal para recibir registros de filebit en SSL. Lea más sobre la configuración del complemento beats aquí .
Filtrar
Todos los registros de texto interesantes que Exchange genera para su procesamiento están en formato csv con los campos descritos en el propio archivo de registro. Para analizar registros csv, Logstash nos ofrece tres complementos: diseccionar , csv y grok. El primero es el más rápido , pero solo puede analizar los registros más simples.
Por ejemplo, dividirá el siguiente registro en dos (debido a la presencia de una coma dentro del campo), lo que hará que el registro se analice incorrectamente:
…,"MDB:GUID1, Mailbox:GUID2, Event:526545791, MessageClass:IPM.Note, CreationTime:2020-05-15T12:01:56.457Z, ClientType:MOMT, SubmissionAssistant:MailboxTransportSubmissionEmailAssistant",…
Se puede utilizar al analizar registros, por ejemplo, IIS. En este caso, la sección de filtro podría verse así:
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
}
}
}
La configuración de Logstash permite declaraciones condicionales , por lo que solo podemos enviar registros al complemento de disección que se hayan marcado con una etiqueta filebeat
IIS. Dentro del complemento, hacemos coincidir los valores del campo con sus nombres, eliminamos el campo original messageque contenía la entrada del registro y podemos agregar un campo arbitrario que, por ejemplo, contendrá el nombre de la aplicación de la que recopilamos los registros.
En el caso de los registros de seguimiento, es mejor usar el complemento csv, puede procesar correctamente campos complejos:
filter {
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
}
Dentro del complemento, hacemos coincidir los valores de campo con sus nombres, eliminamos el campo original
message(así como los campos tenant-idy schema-version) que contenía la entrada del registro, y podemos agregar un campo arbitrario que, por ejemplo, contendrá el nombre de la aplicación de la que recopilamos registros.
A la salida de la etapa de filtrado, obtendremos documentos en una primera aproximación, listos para renderizar en Kibana. Extrañaremos lo siguiente:
- Los campos numéricos se reconocerán como texto, evitando que se realicen operaciones en ellos. Es decir, los campos de
time-takenregistro de IIS, así como los campos de seguimientorecipient-county eltotal-bitesregistro. - La marca de tiempo del documento estándar contendrá el tiempo de procesamiento del registro, no el tiempo de grabación del lado del servidor.
- El campo
recipient-addressse verá como una sola construcción, lo que no permite el análisis con el conteo de los destinatarios de las cartas.
Ahora es el momento de agregar algo de magia al proceso de procesamiento de registros.
Conversión de campos numéricos
El complemento de disección tiene una opción
convert_datatypeque puede utilizar para convertir un campo de texto a formato digital. Por ejemplo, así:
dissect {
…
convert_datatype => { "time-taken" => "int" }
…
}
Vale la pena recordar que este método solo es adecuado si el campo definitivamente contendrá una cadena. La opción no procesa valores nulos de los campos y se lanza a una excepción.
Para el seguimiento de registros, conviene evitar un método similar, ya que el campo
recipient-county total-bitespuede estar en blanco. Es mejor usar el complemento mutate para convertir estos campos :
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
}
División de destinatario_dirección en destinatarios individuales
Esta tarea también se puede resolver usando el complemento mutate:
mutate {
split => ["recipient_address", ";"]
}
Cambiar la marca de tiempo
En el caso de los registros de seguimiento, la tarea es muy fácil de resolver mediante el complemento de fecha , que ayudará a escribir la
timestampfecha y la hora en el campo en el formato requerido del campo date-time:
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
En el caso de los registros de IIS, necesitaremos combinar los datos del campo
datey time, usando el complemento mutar, registrar la zona horaria que necesitamos y colocar esta marca de tiempo timestampusando el complemento de fecha:
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
Salida
La sección de salida se utiliza para enviar registros procesados al receptor de registros. En el caso de enviar directamente a Elastic, se utiliza el plugin elasticsearch , que especifica la dirección del servidor y la plantilla para el nombre del índice para enviar el documento generado:
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Configuración final
La configuración final se verá así:
input {
beats {
port => 5044
}
}
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
convert_datatype => { "time-taken" => "int" }
}
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
}
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
split => ["recipient_address", ";"]
}
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Enlaces útiles:
- ¿Cómo instalar OpenJDK 11 en Windows?
- Descarga Logstash
- Elastic usa la opción depricada UseConcMarkSweepGC # 36828
- NSSM
- Colas persistentes
- Complemento de entrada Beats
- Logstash Dude, ¿dónde está mi motosierra? Necesito diseccionar mis registros
- Complemento de filtro de disección
- Condicionales
- Complemento de filtro mutado
- Complemento de filtro de fecha
- Complemento de salida de Elasticsearch